原理回顾
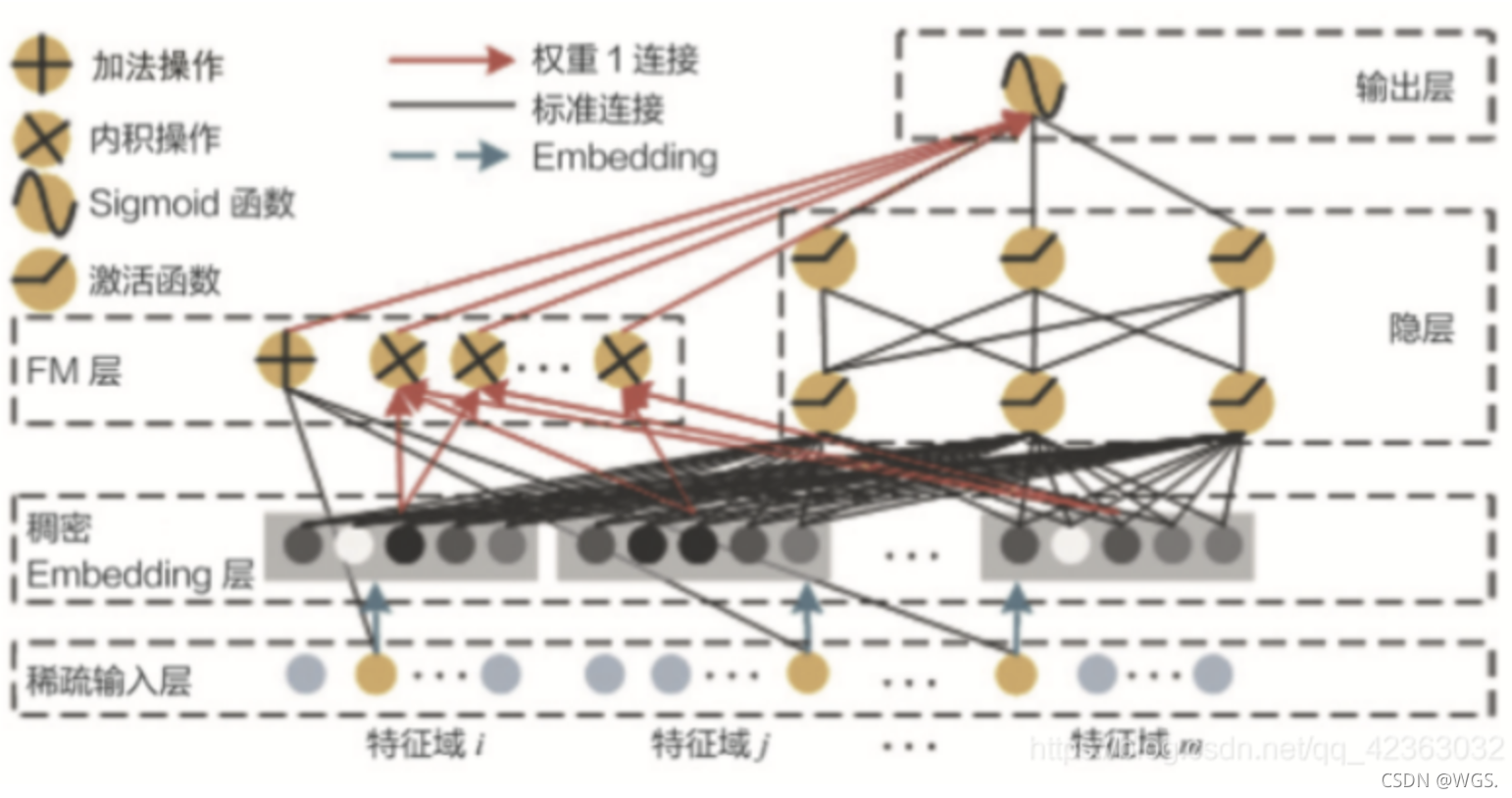
- 左边用 FM 替换了 Wide&Deep 左边 的 Wide 部分,加强了浅层网络部分特征组合的能力
- 右边的部分跟 Wide&Deep 的 Deep 部分一样,主要利用 多层神经网络进行所有特征的深层处理
- 最后的输出层是把 FM 部分的输出和 Deep 部分的输出综合起来,产生最 后的预估结果。这就是 DeepFM 的结构
详细请见这篇文章:
https://blog.csdn.net/qq_42363032/article/details/113696907
基于tf2.0组网DeepFM
import sys, time
import numpy as np
import pandas as pd
from tensorflow.keras.layers import *
import tensorflow.keras.backend as K
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.utils import plot_model
from tensorflow.keras.callbacks import *
from tensorflow.keras.layers import *
from tensorflow.keras.optimizers import *
from tensorflow.python.keras.models import save_model, load_model
from tensorflow.keras.models import model_from_yaml
from sklearn.preprocessing import LabelEncoder
from sklearn.utils import shuffle
from sklearn.metrics import f1_score, accuracy_score, roc_curve, precision_score, recall_score, roc_auc_score
from toolsnn import *
class myDeepFM():
def __init__(self, data):
self.cols = data.columns.values
# 定义特征组
self.dense_feats = [f for f in self.cols if f[0] == "I"]
self.sparse_feats = [f for f in self.cols if f[0] == "C"]
''' 处理dense特征 '''
def process_dense_feats(self, data, feats):
d = data.copy()
d = d[feats].fillna(0.0)
for f in feats:
d[f] = d[f].apply(lambda x: np.log(x + 1) if x > -1 else -1)
return d
''' 处理sparse特征 '''
def process_sparse_feats(self, data, feats):
d = data.copy()
d = d[feats].fillna("-1")
for f in feats:
label_encoder = LabelEncoder()
d[f] = label_encoder.fit_transform(d[f])
return d
''' 一阶特征 '''
def first_order_features(self):
# 构造 dense 特征的输入
dense_inputs = []
for f in self.dense_feats:
_input = Input([1], name=f)
dense_inputs.append(_input)
# 将输入拼接到一起,方便连接 Dense 层
concat_dense_inputs = Concatenate(axis=1)(dense_inputs) # ?, 13,13是稠密特征维度
# 然后连上输出为1个单元的全连接层,表示对 dense 变量的加权求和
fst_order_dense_layer = Dense(1)(concat_dense_inputs) # ?, 1
# 构造 sparse 特征的输入,这里单独对每一个 sparse 特征构造输入,目的是方便后面构造二阶组合特征
sparse_inputs = []
for f in self.sparse_feats:
_input = Input([1], name=f)
sparse_inputs.append(_input)
sparse_1d_embed = []
for i, _input in enumerate(sparse_inputs):
f = self.sparse_feats[i]
voc_size = total_data[f].nunique()
# 使用 l2 正则化防止过拟合
reg = tf.keras.regularizers.l2(0.5)
_embed = Embedding(voc_size, 1, embeddings_regularizer=reg)(_input)
# 由于 Embedding 的结果是二维的,因此如果需要在 Embedding 之后加入 Dense 层,则需要先连接上 Flatten 层
_embed = Flatten()(_embed)
sparse_1d_embed.append(_embed)
# 对每个 embedding lookup 的结果 wi 求和
fst_order_sparse_layer = Add()(sparse_1d_embed)
# Linear部分合并
linear_part = Add()([fst_order_dense_layer, fst_order_sparse_layer])
return dense_inputs, sparse_inputs, linear_part
''' 二阶特征 '''
def second_order_features(self, sparse_inputs):
# embedding size
k = 8
# 只考虑sparse的二阶交叉
sparse_kd_embed = []
for i, _input in enumerate(sparse_inputs):
f = self.sparse_feats[i]
voc_size = total_data[f].nunique()
reg = tf.keras.regularizers.l2(0.7)
_embed = Embedding(voc_size, k, embeddings_regularizer=reg)(_input)
sparse_kd_embed.append(_embed)
# 1.将所有sparse的embedding拼接起来,得到 (n, k)的矩阵,其中n为特征数,k为embedding大小
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed) # ?, n, k
# 2.先求和再平方
sum_kd_embed = Lambda(lambda x: K.sum(x, axis=1))(concat_sparse_kd_embed) # ?, k
square_sum_kd_embed = Multiply()([sum_kd_embed, sum_kd_embed]) # ?, k
# 3.先平方再求和
square_kd_embed = Multiply()([concat_sparse_kd_embed, concat_sparse_kd_embed]) # ?, n, k
sum_square_kd_embed = Lambda(lambda x: K.sum(x, axis=1))(square_kd_embed) # ?, k
# 4.相减除以2
sub = Subtract()([square_sum_kd_embed, sum_square_kd_embed]) # ?, k
sub = Lambda(lambda x: x * 0.5)(sub) # ?, k
snd_order_sparse_layer = Lambda(lambda x: K.sum(x, axis=1, keepdims=True))(sub) # ?, 1
return concat_sparse_kd_embed, snd_order_sparse_layer
''' DNN部分 '''
def dnn(self, concat_sparse_kd_embed):
flatten_sparse_embed = Flatten()(concat_sparse_kd_embed) # ?, n*k
fc_layer = Dropout(0.5)(Dense(256, activation='relu')(flatten_sparse_embed)) # ?, 256
fc_layer = Dropout(0.3)(Dense(256, activation='relu')(fc_layer)) # ?, 256
fc_layer = Dropout(0.1)(Dense(256, activation='relu')(fc_layer)) # ?, 256
fc_layer = Dropout(0.1)(Dense(128, activation='relu')(fc_layer)) # ?, 256
fc_layer = Dropout(0.1)(Dense(32, activation='relu')(fc_layer)) # ?, 256
fc_layer_output = Dense(1)(fc_layer) # ?, 1
return fc_layer_output
''' 输出结果 '''
def outRes(self, linear_part, snd_order_sparse_layer, fc_layer_output):
output_layer = Add()([linear_part, snd_order_sparse_layer, fc_layer_output])
output_layer = Activation("sigmoid")(output_layer)
return output_layer
''' 编译模型 '''
def compile_model(self, dense_inputs, sparse_inputs, output_layer):
model = Model(dense_inputs + sparse_inputs, output_layer)
# model.summary()
mNadam = Adam(lr=1e-4, beta_1=0.98, beta_2=0.999)
model.compile(optimizer=mNadam,
loss="binary_crossentropy",
metrics=['Precision', 'Recall', tf.keras.metrics.AUC(name='auc')])
return model
def GeneratorRandomPatchs(train_x, train_y, batch_size):
totl, col = np.array(train_x).shape # (39, 500000) 特征数、样本数
# 保证 steps_per_epoch * epoch 批次的数据够
while True:
for index in range(0, col, batch_size):
xs, ys = [], []
for t in range(totl):
xs.append(train_x[t][index: index + batch_size])
ys.append(train_y[0][index: index + batch_size])
yield (xs, ys)
if __name__ == '__main__':
data = pd.read_csv('../../data/criteo_sampled_data.csv')
# data = pd.read_csv(sys.argv[1])
# data = shuffle(data)
print(data.shape)
print(list(data.columns))
deepFMmodel = myDeepFM(data)
# 特征处理
data_dense = deepFMmodel.process_dense_feats(data, deepFMmodel.dense_feats)
data_sparse = deepFMmodel.process_sparse_feats(data, deepFMmodel.sparse_feats)
print('dense count:', len(deepFMmodel.dense_feats))
print('spare count:', len(deepFMmodel.sparse_feats))
total_data = pd.concat([data_dense, data_sparse], axis=1)
total_data['label'] = data['label']
print(total_data.head(3))
# 一阶特征
dense_inputs, sparse_inputs, linear_part = deepFMmodel.first_order_features()
# 二阶特征
concat_sparse_kd_embed, snd_order_sparse_layer = deepFMmodel.second_order_features(sparse_inputs)
# DNN部分
fc_layer_output = deepFMmodel.dnn(concat_sparse_kd_embed)
# 输出结果
output_layer = deepFMmodel.outRes(linear_part, snd_order_sparse_layer, fc_layer_output)
# 编译模型
model = deepFMmodel.compile_model(dense_inputs, sparse_inputs, output_layer)
# 训练
train_data = total_data.loc[:500000 - 1]
valid_data = total_data.loc[500000:]
print('train_data len: ', len(train_data))
print('validation_data len: ', len(valid_data))
train_dense_x = [train_data[f].values for f in deepFMmodel.dense_feats]
train_sparse_x = [train_data[f].values for f in deepFMmodel.sparse_feats]
train_x = train_dense_x + train_sparse_x
train_y = [train_data['label'].values]
val_dense_x = [valid_data[f].values for f in deepFMmodel.dense_feats]
val_sparse_x = [valid_data[f].values for f in deepFMmodel.sparse_feats]
val_x = val_dense_x + val_sparse_x
val_y = [valid_data['label'].values]
print(train_x)
print(train_y)
# exit()
# model.fit(train_x, train_y,
# batch_size=64, epochs=5, verbose=2,
# validation_data=(val_x, val_y),
# use_multiprocessing=True, workers=4)
batch_size = 2048
model.fit_generator(
GeneratorRandomPatchs(train_x, train_y, batch_size),
validation_data=(val_x, val_y),
steps_per_epoch=len(train_data) // batch_size,
epochs=5,
verbose=2,
shuffle=True,
)
# path = '/ad_ctr/data/deepFMmodel-10-27.h5'
path = '../../data/my_deepFMmodel-10-27.h5'
model.save(path)
print(' 模型保存完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
modelnew = tf.keras.models.load_model(path)
y_pre = modelnew.predict(x=val_x, batch_size=256,)
print(type(y_pre))
print(y_pre.shape)
y = val_y[0]
y_pre = [int(i) for i in y_pre]
print(' ', set(y_pre))
f1 = f1_score(y, y_pre)
auc = roc_auc_score(y, y_pre)
acc = accuracy_score(y, y_pre)
print(' 精确率: %.5f' % (precision_score(y, y_pre)))
print(' 召回率: %.5f' % (recall_score(y, y_pre)))
print(' F1: %.5f' % (f1))
print(' AUC: %.5f' % (auc))
print(' 准确率: %.5f' % (acc))
accDealWith(y, y_pre)
print(' 全量评估完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
print('==============================')
print()
print()
print()
基于deepctr实现DeepFM
import os, warnings, time, sys
import pickle
import matplotlib.pyplot as plt
import pandas as pd, numpy as np
from sklearn.utils import shuffle
from sklearn.metrics import f1_score, accuracy_score, roc_curve, precision_score, recall_score, roc_auc_score
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, MinMaxScaler, OneHotEncoder
from deepctr.models import DeepFM, xDeepFM, MLR, DeepFEFM, DIN, AFM
from deepctr.feature_column import SparseFeat, DenseFeat, get_feature_names
from deepctr.layers import custom_objects
from tensorflow.python.keras.models import save_model, load_model
from tensorflow.keras.models import model_from_yaml
import tensorflow as tf
from tensorflow.python.ops import array_ops
import tensorflow.keras.backend as K
from sklearn import datasets
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
from keras.models import model_from_json
from tensorflow.keras.callbacks import *
from tensorflow.keras.models import *
from tensorflow.keras.layers import *
from tensorflow.keras.optimizers import *
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import one_hot
from keras.layers.embeddings import Embedding
from toolsnn import *
def train_deepFM2():
print('DeepFM 模型训练开始 ', time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time.time())))
start_time_start = time.time()
# pdtrain:正样本数:565485,负样本数:1133910,正负样本比: 1 : 2.0052
# pdtest:正样本数:565485,负样本数:1134505,正负样本比: 1 : 2.0063
# pdeval_full:正样本数:46,负样本数:8253,正负样本比: 1 : 179.413
pdtrain = pd.read_csv(train_path_ascii)
pdtest = pd.read_csv(test_path_ascii)
data = pd.concat([pdtrain, pdtest[pdtest['y'] == 0]], axis=0, ignore_index=True)
data = data.drop(['WilsonClickRate_all', 'WilsonClickRate_yesterday', 'WilsonAd_clickRate_all',
'WilsonAd_clickRate_yesterday'], axis=1)
# 将 `用户id`、`广告id`、`用户设备`、`多牛广告位id` 用ASCII数值化,转为embedding: 利用卷积原理,将每个字符的ascii码相加作为字符串的数值
data['suuid'] = data['suuid'].apply(lambda x: sum([ord(i) for i in x]))
data['advertisement'] = data['advertisement'].apply(lambda x: sum([ord(i) for i in x]))
# data['position'] = data['position'].apply(lambda x: sum([ord(i) for i in x])) # 多牛广告位id本身就是float类型,直接embedding
data['user_modelMake'] = data['user_modelMake'].apply(lambda x: sum([ord(i) for i in x]))
# double -> float
data = transformDF(data, ['reserve_price', 'reserve_price_cpc', 'clickRate_all', 'clickRate_yesterday', 'ad_clickRate_yesterday'], float)
''' 特征处理 '''
global sparsecols, densecols
# 稀疏-onehot
sparsecols = ['hour', 'advert_place', 'province_id', 'port_type', 'user_osID', 'is_holidays', 'is_being',
'is_outflow', 'advertiser', 'ad_from', 'payment']
# ascii embedding
sparse_ascii = ['suuid', 'advertisement', 'position', 'user_modelMake']
# 稠密-归一化
densecols = ['W', 'H', 'reserve_price', 'reserve_price_cpc', 'is_rest_click', 'clickPerHour_yesterday',
'display_nums_all', 'click_nums_all', 'display_nums_yesterday', 'click_nums_yesterday',
'ad_display_all', 'ad_click_all', 'ad_display_yesterday', 'ad_click_yesterday']
# 稠密-点击率
ratecols = ['WHrate', 'clickRate_all', 'clickRate_yesterday', 'ad_clickRate_yesterday']
global namesoh
namesoh = {
}
for sparse in sparsecols:
onehot = OneHotEncoder()
arrays = onehot.fit_transform(np.array(data[sparse]).reshape(-1, 1))
# 将onehot后的稀疏矩阵拼回原来的df
arrays = arrays.toarray()
names = [sparse + '_' + str(n) for n in range(len(arrays[0]))]
namesoh[sparse] = names
data = pd.concat([data, pd.DataFrame(arrays, columns=names)], axis=1)
data = data.drop([sparse], axis=1)
# 保存编码规则
with open(feature_encode_path.format(sparse) + '.pkl', 'wb') as f:
pickle.dump(onehot, f)
# print(' {} onehot完成'.format(sparse))
print(' onehot完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
for dense in densecols:
mms = MinMaxScaler(feature_range=(0, 1))
data[dense] = mms.fit_transform(np.array(data[dense]).reshape(-1, 1))
with open(feature_encode_path.format(dense) + '.pkl', 'wb') as f:
pickle.dump(mms, f)
# print(' {} 归一化完成'.format(dense))
print(' 归一化完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
print(' columns: ', len(list(data.columns)))
''' 训练集、测试集、验证集划分 '''
train_data, test_data = getRata2(data, num=1)
_, val_data = train_test_split(test_data, test_size=0.2, random_state=1, shuffle=True)
train_data = shuffle(train_data)
test_data = shuffle(test_data)
val_data = shuffle(val_data)
negBpow(train_data, '训练集')
negBpow(val_data, '验证集')
negBpow(test_data, '测试集')
print(' train_data shape: ', train_data.shape)
print(' val_data shape: ', val_data.shape)
print(' test_data shape: ', test_data.shape)
''' 一阶特征 '''
sparse_features = []
for value in namesoh.values():
for v in value:
sparse_features.append(v)
dense_features = densecols + ratecols
''' 二阶特征 '''
sparse_feature_columns1 = [SparseFeat(feat, vocabulary_size=int(train_data[feat].max() + 1), embedding_dim=4)
for i, feat in enumerate(sparse_features)]
sparse_feature_columns2 = [SparseFeat(feat, vocabulary_size=int(train_data[feat].max() + 1), embedding_dim=4)
for i, feat in enumerate(sparse_ascii)]
sparse_feature_columns = sparse_feature_columns1 + sparse_feature_columns2
dense_feature_columns = [DenseFeat(feat, 1)
for feat in dense_features]
print(' sparse_features count: ', len(sparse_features))
print(' dense_features count: ', len(dense_features))
''' DNN '''
dnn_feature_columns = sparse_feature_columns + dense_feature_columns
''' FM '''
linear_feature_columns = sparse_feature_columns + dense_feature_columns
global feature_names
feature_names = get_feature_names(linear_feature_columns + dnn_feature_columns)
print(' feature_names: ', feature_names)
''' feed input '''
train_x = {
name: train_data[name].values for name in feature_names}
test_x = {
name: test_data[name].values for name in feature_names}
val_x = {
name: val_data[name].values for name in feature_names}
train_y = train_data[['y']].values
test_y = test_data[['y']].values
val_y = val_data[['y']].values
print(' 数据处理完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
# print(' train_model_input: ', train_x)
# print(' val_model_input: ', val_x)
# print('train_y: ', train_y, train_y.shape)
deep = DeepFM(linear_feature_columns, dnn_feature_columns,
dnn_hidden_units=(256, 128, 64, 32, 1),
l2_reg_linear=0.01, l2_reg_embedding=0.01,
dnn_dropout=0.2,
dnn_activation='relu', dnn_use_bn=True, task='binary')
mNadam = Adam(lr=1e-4, beta_1=0.95, beta_2=0.96)
deep.compile(optimizer=mNadam, loss='binary_crossentropy',
metrics=['AUC', 'Precision', 'Recall'])
print(' 组网完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
print(' 训练开始 ', time.strftime("%H:%M:%S", time.localtime(time.time())))
start_time = time.time()
''' 训练 '''
# 早停止:验证集精确率上升幅度小于min_delta,训练停止
earlystop_callback = EarlyStopping(
monitor='val_precision', min_delta=0.001, mode='max',
verbose=2, patience=3)
generator_flag = False # fit
# generator_flag = True # fit_generator
if not generator_flag:
history = deep.fit(
train_x, train_y, validation_data=(val_x, val_y),
batch_size=2000,
epochs=3000,
verbose=2,
shuffle=True,
# callbacks=[earlystop_callback]
)
else:
batch_size = 2000
train_nums = len(train_data)
history = deep.fit_generator(
GeneratorRandomPatchs(train_x, train_y, batch_size, train_nums, feature_names),
validation_data=(val_x, val_y),
steps_per_epoch=train_nums // batch_size,
epochs=3000,
verbose=2,
shuffle=True,
# callbacks=[earlystop_callback]
)
end_time = time.time()
print(' 训练完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
print((' 训练运行时间: {:.0f}分 {:.0f}秒'.format((end_time - start_time) // 60, (end_time - start_time) % 60)))
# 模型保存成yaml文件
save_model(deep, save_path)
print(' 模型保存完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
# 训练可视化
visualization(history, saveflag=True, showflag=False, path1=loss_plt_path.format('loss_auc.jpg'), path2=loss_plt_path.format('precision_recall.jpg'))
# 测试集评估
scores = deep.evaluate(test_x, test_y, verbose=0)
print(' %s: %.4f' % (deep.metrics_names[0], scores[0]))
print(' %s: %.4f' % (deep.metrics_names[1], scores[1]))
print(' %s: %.4f' % (deep.metrics_names[2], scores[2]))
print(' %s: %.4f' % (deep.metrics_names[3], scores[3]))
print(' %s: %.4f' % ('F1', (2*scores[2]*scores[3])/(scores[2]+scores[3])))
print(' 验证集再评估完成', time.strftime("%H:%M:%S", time.localtime(time.time())))
# 全量评估
full_evaluate2()
end_time_end = time.time()
print(('DeepFM 模型训练运行时间: {:.0f}分 {:.0f}秒'.format((end_time_end - start_time_start) // 60, (end_time_end - start_time_start) % 60)))
print(('{:.0f}小时'.format((end_time_end - start_time_start) // 60 / 60)))