何为自编码器
以下是来自TensorFlow实战-黄文坚这本书。


这里有一个自编码器的思想来源,就是说虽然图片,音频,视频千千万,但是往往“表达”他们的基本机构是少数的一些基本固定的结构。称为特征的稀疏表达。
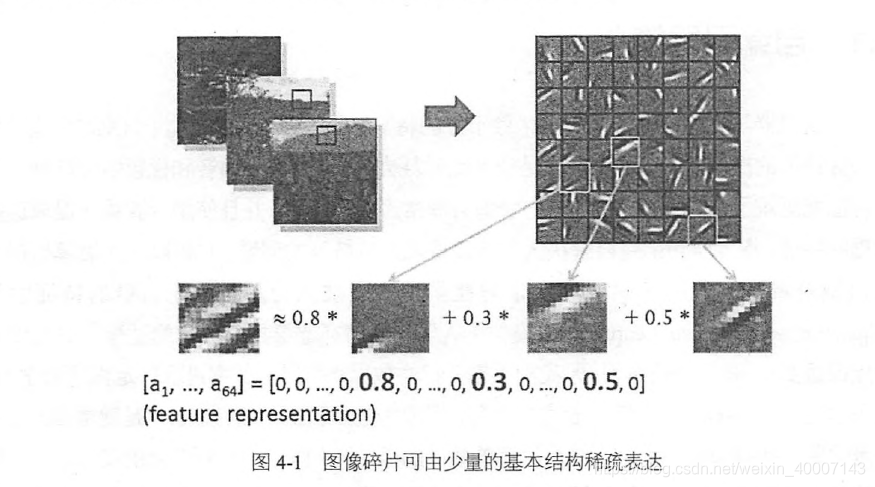


这里来解释一下,自编码器就是输入的图片不知道自己的基本结构是什么的。需要不断的训练来近似得到基本结构。怎么得到呢?就是把输出也设置为输入的原图像。使之不断的优化以得到最佳的基本结构。一般自编码器都是中间小,两头大的一个网络结构。因为中间的每一层表达的是“基本结构”。
如何实现
具体的实现形式有很多,比如简单的三层网络,深层网络,卷积网络等。
还可以把它应用到图像去噪上面去。这时把输入设置为加噪的图片,输出设置为未加燥的图片,自编码器依然要不断的学习以获得最佳的适合输出的基本结构。这是前面说的升级版了。
下面是自编码器应用于图像去噪的例子:(CNN)
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 加载数据集
minst = tf.keras.datasets.mnist
(x_train, _), (x_test, _) = minst.load_data()
# 设置数据格式
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train = x_train/255
x_test = x_test/255
x_train = np.reshape(x_train, (len(x_train), 28, 28, 1))
x_test = np.reshape(x_test, (len(x_test), 28, 28, 1))
# 加噪声
noise_factor = 0.5
x_train_noisy = x_train+noise_factor*np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test+noise_factor*np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
# 显示原始图像和加噪之后的图像
n = 20
plt.figure(figsize=(60, 12)) # 指定宽为20,高为4
for i in range(1, 10):
ax = plt.subplot(2, n/2, i) # 表示将设置为2行,n/2列,当前位置在i。
plt.imshow(x_train[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
ax = plt.subplot(2, n/2, 10+i)
plt.imshow(x_train_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
# 模型建立
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=16, kernel_size=(3, 3), padding="same", activation=tf.nn.relu, input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), padding="same"),
tf.keras.layers.Conv2D(filters=8, kernel_size=(3, 3), padding="same", activation=tf.nn.relu),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), padding="same"),
tf.keras.layers.Conv2D(filters=8, kernel_size=(3, 3), padding="same", activation=tf.nn.relu),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), padding="same"),
# encode 4,4,8
# let us decode
# 中间缩小到很小。。表达的是基本结构。
# 然后下面再给他还原回去。
tf.keras.layers.Conv2D(8, (3, 3), activation="relu", padding="same"),
tf.keras.layers.UpSampling2D((2, 2)),
tf.keras.layers.Conv2D(8, (3, 3), activation="relu", padding="same"),
tf.keras.layers.UpSampling2D((2, 2)),
tf.keras.layers.Conv2D(16, (3, 3), activation="relu"),
tf.keras.layers.UpSampling2D((2, 2)),
tf.keras.layers.Conv2D(1, (3, 3), activation="sigmoid", padding="same"),
])
learning_rate = 0.001
# 优化器
adam_optimizer = tf.keras.optimizers.Adam(learning_rate)
model.compile(optimizer=adam_optimizer, loss=tf.keras.losses.binary_crossentropy)
model.fit(x_train_noisy, x_train,
epochs=50, batch_size=128,
shuffle=True,
validation_data=(x_test_noisy, x_test),
)
decoded_imgs = model.predict(x_test_noisy)
n = 10
plt.figure(figsize=(20, 4))
for i in range(1, n):
# display original
ax = plt.subplot(2, n, i)
plt.imshow(x_test_noisy[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display reconstruction
ax = plt.subplot(2, n, i + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
效果:50轮,loss为0.12左右。


