1. 简介
人脸关键点检测也称为人脸对齐,目的是自动定位一组预定义的人脸基准点(比如眼角点、嘴角点)。作为一系列人脸应用的基础,如人脸识别和验证,以及脸部变形和人脸编辑。这个问题一直以来都受到视觉界的高度关注,在过去的几年里,我们的产品取得了很大的进步。然而,开发一种实用的人脸关键点检测器仍然具有挑战性,因为检测精度,处理速度和模型大小都应该考虑。
在现实世界条件下,获得完美的面孔几乎是不可能的。换句话说,人脸经常是出现在控制不足甚至没有约束的环境中。在不同的照明条件下,它的外表有各种各样的姿势、表情和形状,有时还有部分遮挡。下图提供了这样的几个例子。此外,有足够的训练数据用于数据驱动方法也是模型性能的关键。在综合考虑不同条件下,捕捉多个人脸可能是可行的,但这种收集方式会变得不切实际,特别是当需要大规范的数据来训练深度模型时。在这种情况下,我们经常会遇到不平衡的数据分布。本文介绍的这个人脸检测算法PFLD《PFLD: A Practical Facial Landmark Detector》总结了有关人脸关键点检测精度的问题,分为三个挑战(考虑实际使用时,还有一个额外的挑战!)。

-
局部变化:表情、局部特殊光照、部分遮挡,导致一部分关键点偏离了正常的位置,或者不可见了;
-
全局变化:人脸姿态、成像质量;
-
数据不均衡:在人脸数据里面,数据不均衡体现在,大部分是正脸数据,侧脸很少,所以对侧脸、大角度的人脸不太准;
-
模型效率:在 CNN 的解决方案中,模型效率主要由 backbone 网络决定。
2. 网络结构
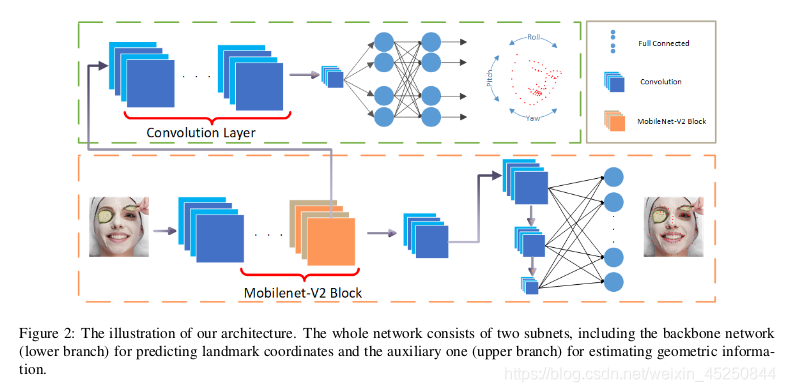
黄色曲线包围的是主网络,用于预测特征点的位置;
绿色曲线包围的部分为辅助子网络,在训练时预测人脸姿态(主要包括三个姿态角,,有文献表明给网络加这个辅助任务可以提高定位精度,具体参考原论文),这部分在测试时不需要。
backbone 网络是 bottleneck,用MobileNet块代替了传统的卷积运算。通过这样做,我们的backbone的计算量大大减少,从而加快了速度。此外,可以根据用户需求通过调整MobileNets的width参数来压缩我们的网络,从而使模型更小,更快。
姿态角的计算方法:
- 预先定义一个标准人脸(在一堆正面人脸上取平均值),在人脸主平面上固定11个关键点作为所有训练人脸的参考;
- 使用对应的11个关键点和估计旋转矩阵的参考矩阵;
- 由旋转矩阵计算欧拉角。
网络结构细节如下:

3. 损失函数
在深度学习中,数据不平衡是另一个经常限制准确检测性能的问题。例如,训练集可能包含大量正面,而缺少那些姿势较大的面孔。如果没有额外的技巧,几乎可以肯定的是,由这样的训练集训练的模型不能很好地处理大型姿势情况。在这种情况下,“平均”惩罚每个样本将使其不平等。为了解决这个问题,我们主张对训练样本数量少进行大的惩罚,而不是对样本数量多的进行惩罚。

M为样本个数,N为特征点个数,Yn为不同的权重,|| * ||为特征点的距离度量(L1或L2距离)。(以Y代替公式里的希腊字母)
进一步细化 Y n Y_n Yn:
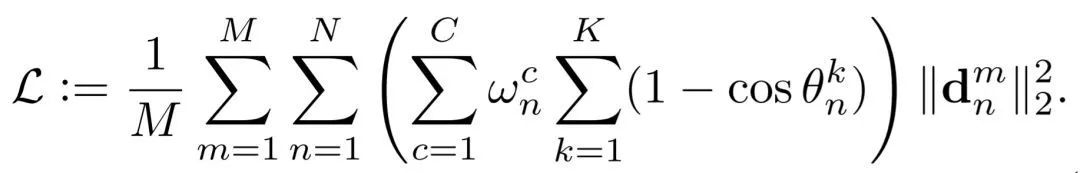
其中:
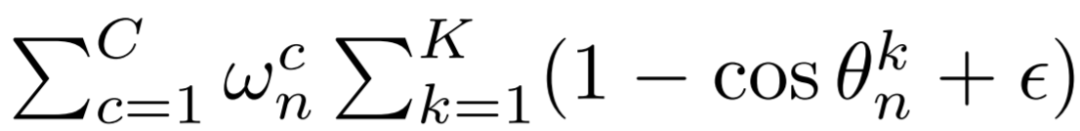
即为最终的样本权重。
K=3,这一项代表着人脸姿态估计的三个维度,即yaw, pitch, roll 角度,由计算公式可知角度越高,权重越大。
C为不同的人脸类别数,作者将人脸分成多个类别,比如侧脸、正脸、抬头、低头、表情、遮挡等,w为与类别对应的给定权重,如果某类别样本少则给定权重大。
4. 测试结果
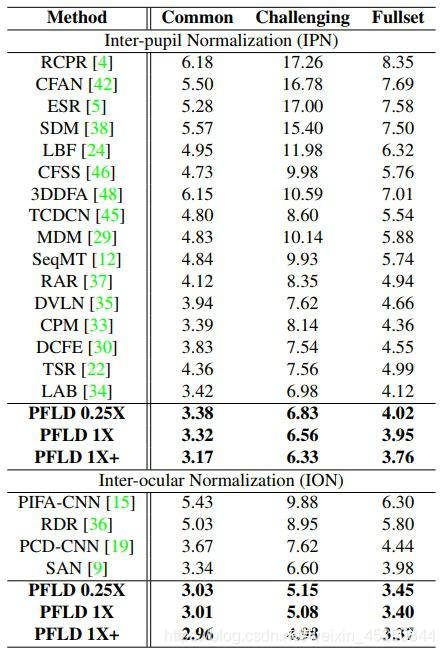
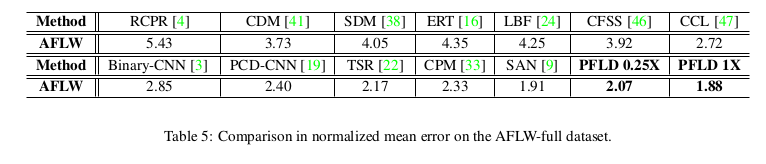
检测精度对比如下面的表所示
下面来看一下算法处理速度和模型大小,图中C代表i7-6700K CPU,G代表1080 Ti GPU,G*代表Titan X GPU,A代表移动平台Qualcomm ARM 845处理器。

其中PFLD 1X是标准网络,PFLD 0.25X是MobileNet blocks width 参数设为0.25的压缩网络,PFLD 1X+是在WFLW数据集上预训练的网络。
下图是该算法在AFLW数据集上与其他算法的精度比较:
消融实验方面作者仅仅分析了损失函数带来的影响,结果如下表所示。

5. PFLD优化
5.1 GhostNet
这里简单介绍一下GhostNet,因为优化过程中会使用到GhostNet提出的GhostModule,而且正是GhostModule,PFLD的效率有了一个质的提升。
《GhostNet: More Features from Cheap Operations》是2020年3月华为、北大为了提升CNN在嵌入式设备的运行效率而提出的算法。其中提出的GhostModule,巧妙地将PointWise Convolution和DepthWise Convolution结合起来,在达到相同通道输出的前提下,有效地减少运算量。虽然上面提到的Inverted Residual Block同样也是PointWise Convolution和DepthWise Convolution的结合体,但是两者将它们的结合方式有所不同,而正是GhostModule的巧妙结合,让网络的计算量得到减少。
其实按照个人的理解,GhostModule可以一句话概况为:输入的Tensor先做PointWise Convolution,再做DepthWise Convolution,最后将PointWise Convolution和DepthWise Convolution的结果按channel的维度进行拼接,作为最终的输出。大道至简,操作并不复杂,但却大大减少了运算量。
5.2 PFLD网络结构优化
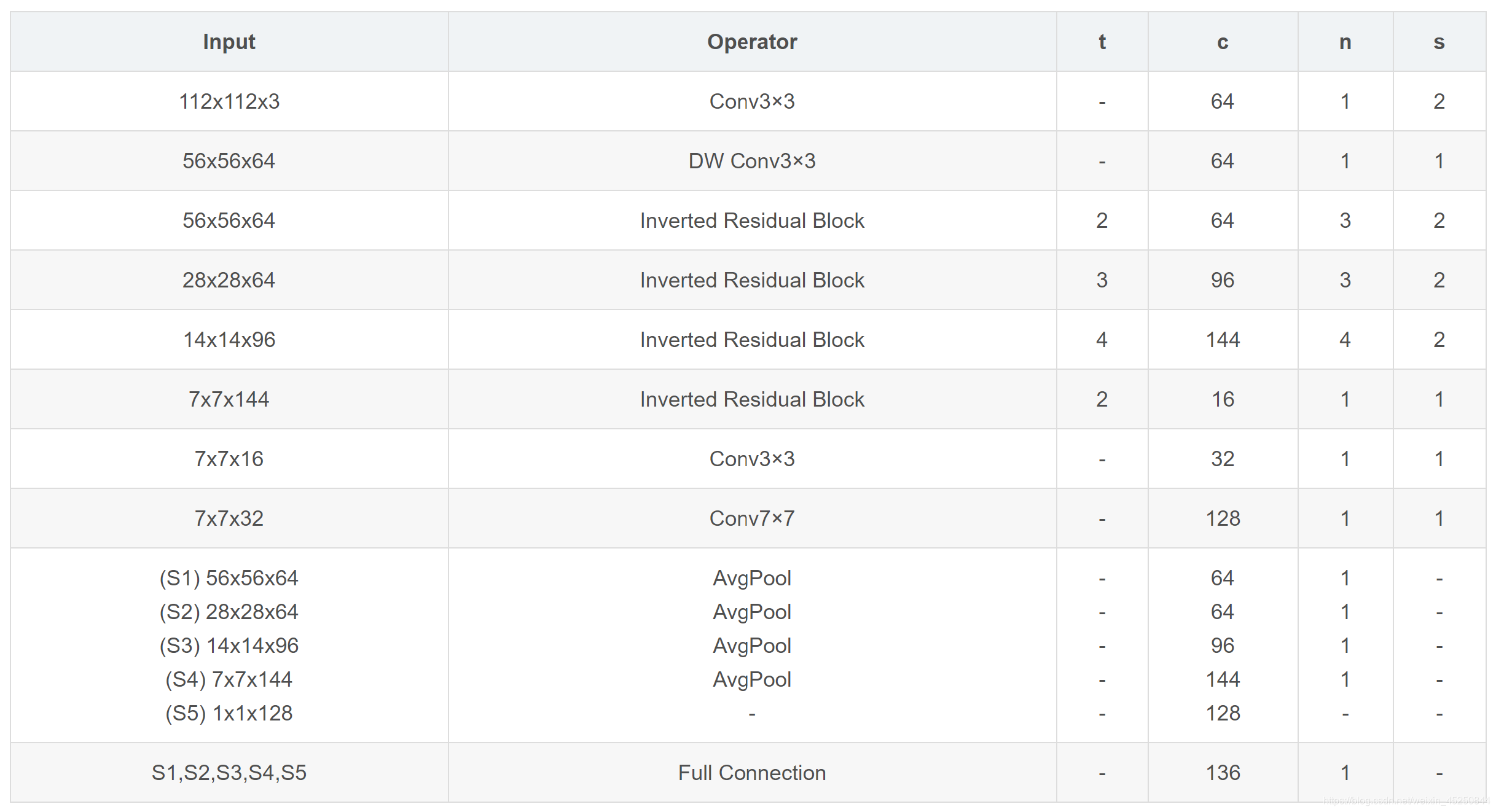
5.2.1 1 调整PFLD网络结构,并增加多尺度全连层的数目(保持网络速度不变,尽可能提升网络精度)
对PFLD的基础网络进行调整,没有用NAS等技术,凭借经验和不断尝试尽量找出性能较好的网络结构,如果大家找到更好的网络结构,也欢迎大家分享出来。
此外,PFLD论文中提到 “To enlarge the receptive field and better catch the global structure on faces, a multi-scale fully-connected (MS-FC) layer is added for precisely localizing landmarks in images”,大概意思是为了增大感受野和更好地获取人脸的全局结构,多尺度全连层的嵌入,可以准确地定位人脸关键点。论文作者认为,多尺度全连层是为了提升网络的定位精度而加入的,因此在优化过程中,增加了多尺度全连层的数目,以提高网络的定位精度。
初步优化的网络结构如下:
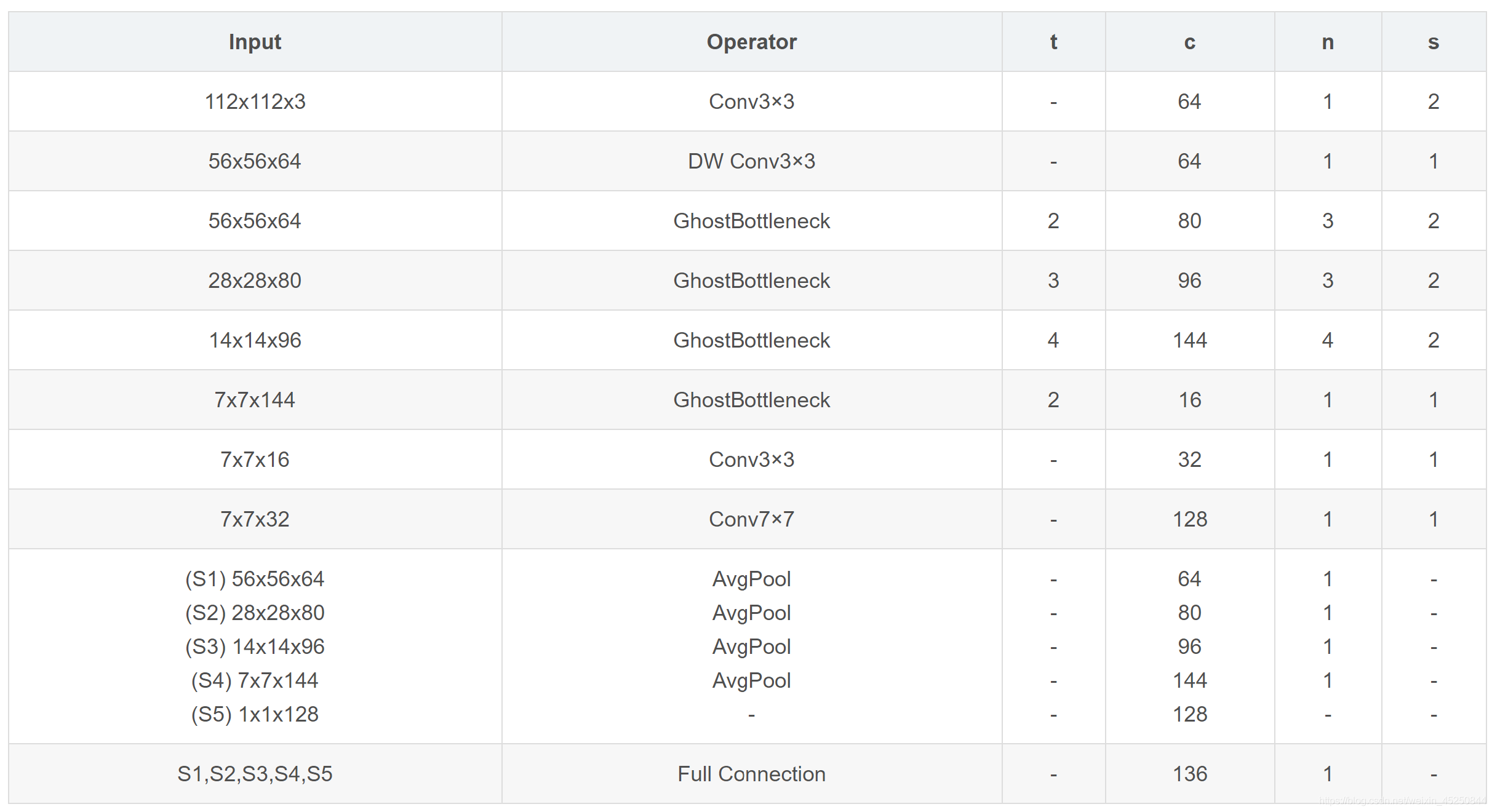
5.2.2 将Inverted Residual Block替换成GhostModule,并细调网络结构(保持网络精度不变,提升网络速度)
由于GhostModule的轻量化,将PFLD的Inverted Residual Block全部替换成GhostModule,并继续细调网络结构,最终优化的网络结构如下表:
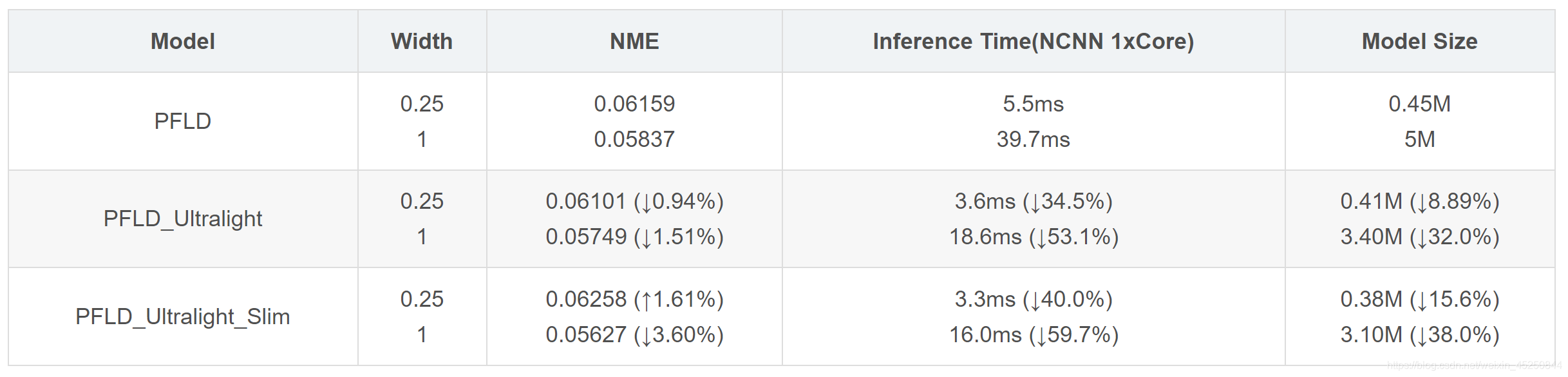
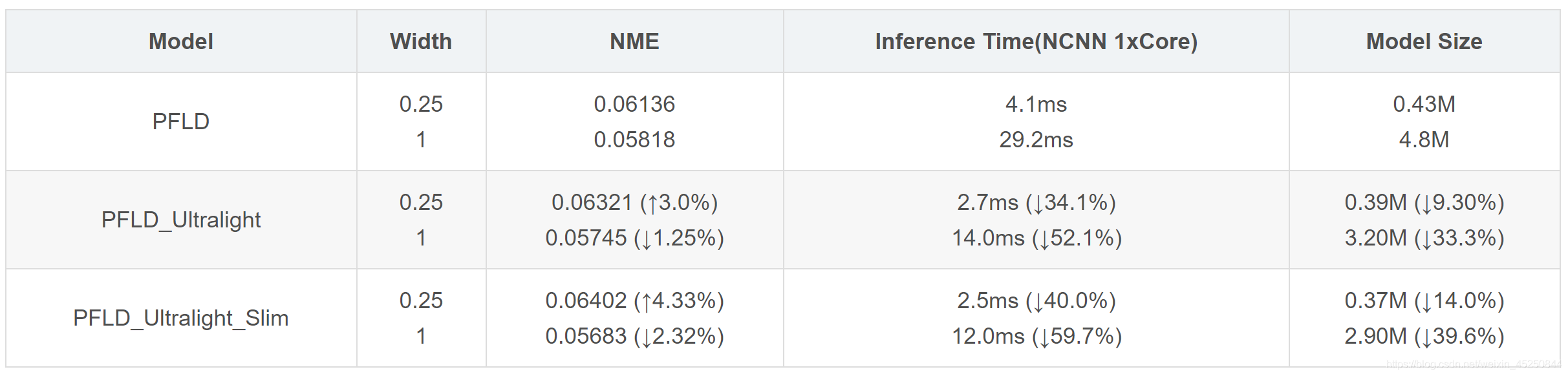
5.3 优化后的测试结果
WFLW测试结果
输入大小为112x112
输入大小为96x96
参考代码:PFLD_UltraLight