
Hadoop单机模式的搭建
JunLeon——go big or go home
前言:Hadoop集群有三种运行模式,即单机模式,伪分布模式、分布式模式。
单机模式:只有一个JVM进程数,只运行在一台机器上(作测试用);
伪分布模式:有多个JVM进程数,运行在同一台机器上;
分布式(完全分布式)模式:多个JVM进程数,运行在三台或三台以上的机器上。
说明:
以下进入Hadoop单机模式的搭建,是在root用户下进行,如果在普通用户下,要注意权限、环境变量等,记得使用sudo命令。
一、Hadoop单机模式的搭建
1、创建用户
useradd hadoop
passwd hadoop (直接输入两次密码即可)
注意:如果切换到普通用户,需要使用 su 命令,在root用户下给普通用户赋权。
2、网络配置、修改主机名、配置网络映射
具体配置请查看:Linux学习——linux网络配置、修改主机名、网络映射、远程连接工具XShell的使用(超详细)_JunLeon的博客-CSDN博客
网络配置文件 /etc/sysconfig/network-scripts/ifcfg-eth0
vi /etc/sysconfig/network-scripts/ifcfg-eth0注意:CentOS7和8里面,网络配置文件为:/etc/sysconfig/network-scripts/ifcfg-ens33
主机名配置文件 /etc/sysconfig/network,修改HOSTNAME=主机名
vi /etc/sysconfig/network将HOSTNAME=localhost.localdomain修改为HOSTNAME=BigData01
注意:CentOS7或8,主机名配置文件为:/etc/hostname,直接删除以前的,添加主机名
配置网络映射 /etc/hosts
vi /etc/hosts在最后一行添加 ip地址 主机名
例如:192.168.182.10 BigData01 # 192.168.182.10是IP地址,BigData01是主机名
重启网络服务:
service network restart
3、安装ssh服务
查看是否安装ssh
rpm -qa | grep ssh如果有openssh-clients、openssh-server,则不需要安装
如果没有,则需要安装,安装命令如下:
yum install -y openssh-clients openssh-server启动ssh服务
service sshd start|stop|restart|statusstart:开启、restart:重启、stop:关闭、status:状态,根据自己需要选择
4、防火墙的管理
service iptables start|stop|restart|status chkconfig iptables off # 永久关闭防火墙start:开启、restart:重启、stop:关闭、status:状态,根据自己需要选择
5、安装jdk
1 XShell 6或者secureCRT远程登录
XShell 6 的安装、使用请查看Linux学习——linux网络配置、修改主机名、网络映射、远程连接工具XShell的使用(超详细)_JunLeon的博客-CSDN博客
2 上传JDK到/opt目录下,Windows-->Linux
使用XShell 6里面的文件传输工具进行上传,左边选择Windows下的文件,右边是Linux的文件系统。
3 查看Linux是否安装java jdk
rpm -qa | grep java如果查询有其他java版本,则需要卸载
rpm -e --nodeps 包名4 解压上传的jdk,解压到/opt目录下
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt5 配置环境变量
vi /etc/profile在这个文件最后添加如下两行:
export JAVA_HOME=/opt/jdk1.8.0_161 export PATH=$JAVA_HOME/bin:$PATH6 使这个配置文件生效
source /etc/profile7 验证(查看java版本)
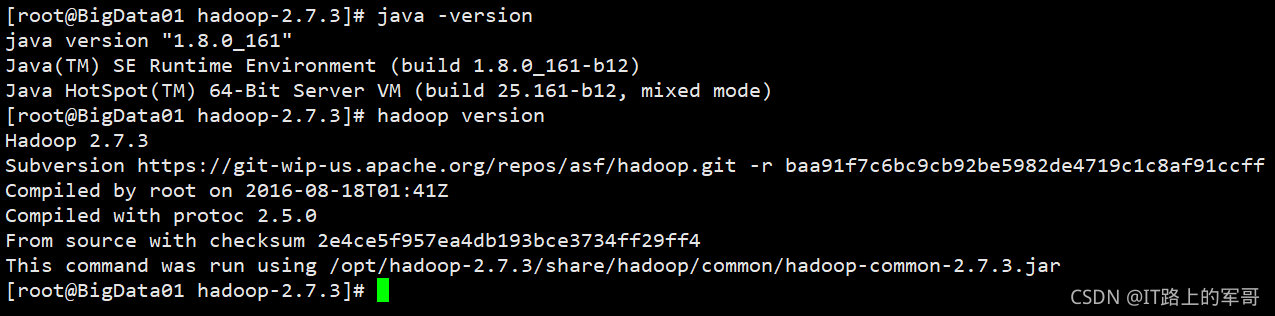
java -version

6、安装hadoop
1 上传hadoop安装包到Linux下的/opt目录
2 解压安装包到/opt目录
tar -zxvf hadoop-2.7.3.tar.gz -C /opt3 配置环境变量
vi /etc/profile在文件最后添加如下两行(在配置java的环境变量基础上添加hadoop路径)
export HADOOP_HOME=/opt/hadoop-2.7.3 export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH使配置文件生效
source /etc/profile4 验证(查看hadoop版本)
hadoop version如果看到以下信息,则安装成功
下一篇:Hadoop集群伪分布模式的搭建(超详细)
如果喜欢、对你有帮助,反手点赞+收藏,跟着军哥学知识……