
Hadoop集群伪分布模式的搭建
JunLeon——go big or go home
目录
说明:此模式是在单机模式的基础上配置的,hadoop的主目录为/opt/hadoop2.7.3,所有的操作都是在root用户执行的。
单机模式的搭建请查看上一篇:Hadoop学习——Hadoop单机模式的搭建(超详细)_JunLeon的博客-CSDN博客
1、配置免密登录
本机生成公钥、私钥和验证文件
ssh-keygen -t rsa将登录信息复制到验证文件
ssh-copy-id BigData01 # BigData01为主机名注意:进行免密登录需要安装ssh,上一篇已经安装ssh服务,此处跳过。
2、HDFS的配置、启动与停止
(配置文件均在hadoop的主目录下操作)
进入Hadoop主目录:cd /opt/hadoop-2.7.3
(1)配置hadoop-env.sh
vi etc/hadoop/hadoop-env.shhadoop-env.sh文件是配置hadoop环境的文件,需要文件25行修改java的路径。如下所示:

(2)配置core-site.xml
vi etc/hadoop/core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoopTmp/</value> </property> </configuration>参数说明:
fs.defaultFS:该参数是配置指定HDFS的通信地址。其值为hdfs://localhost:9000,9000为端口号,可根据情况修改,伪分布模式下主机名一般不需要修改。
hadoop.tmp.dir:该参数配置的是Hadoop临时目录,即指定Hadoop运行时产生文件的存储路径,其值可以自行设置,不能设置为/tmp(/tmp是Linux的临时目录)。
(3)配置hdfs-site.xml
vi etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>参数说明:
dfs.replication:该参数是配置HDFS系统的副本数,因为这里是伪分布模式,只有一个节点,所以设置为1。
(4)格式化HDFS
配置好HDFS文件系统后首次启动需要进行格式化,即执行名称节点NameNode的格式化。格式化是对分布式文件系统HDFS中的数据节点DataNode进行分块,统计所有分块后的初始元数据,并存储在NameNode中。
格式化命令:
hdfs namenode -format注意:格式化命令还可以使用 `
hadoop namenode -format`
出现上图即格式化成功!
格式化成功后,会在hadoop.tmp.dir配置的/opt/hadoopTmp/tmp目录生成目录dfs/name/current/,里面包含几个文件如下:
文件说明:
fsimage_0000000000000000000:此文件是NameNode元数据在内存存储满后,持久化保存的文件。
fsimage_0000000000000000000.md5:此文件是校验文件,用于校验fsimage的完整性。
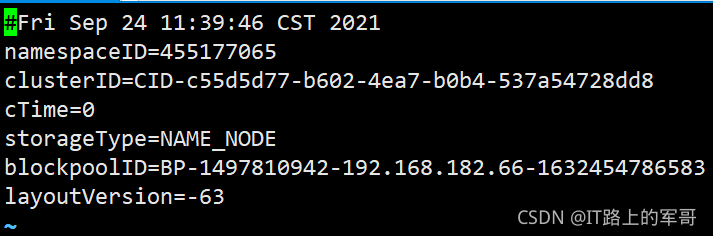
VERSION:此文件是保存该集群的信息,文件内容如下图所示:
namespaceID:NameNode唯一的ID
clusterID:集群ID,同一集群中NameNode和DataNode的集群是一致的。
blockpoolID:用于标识一个block pool,并且是跨集群的全局唯一。当一个新的Namespace被创建的时候(format过程的一部分)会创建并持久化一个唯一ID。在创建过程构建全局唯一的BlockPoolID比人为的配置更可靠一些。NN将BlockPoolID持久化到磁盘中,在后续的启动过程中,会再次load并使用。
注意:格式化时在Hadoop的临时目录tmp下只生成dfs/name目录,在首次启动HDFS时,会在tpm/dfds目录下生成data和namesecondary目录。

(5)HDFS的启动和停止
启动HDFS将启动NameNode、DataNode、SecondaryNameNode三个进程。
启动命令:
start-dfs.sh单独启动命令:
hadoop-daemon.sh start namenode #启动NameNode hadoop-daemon.sh start datanode #启动DataNode hadoop-daemon.sh start secondarynamenode #启动SecondaryNameNode注意:在前面已经配置hadoop的环境变量,故只需要输入
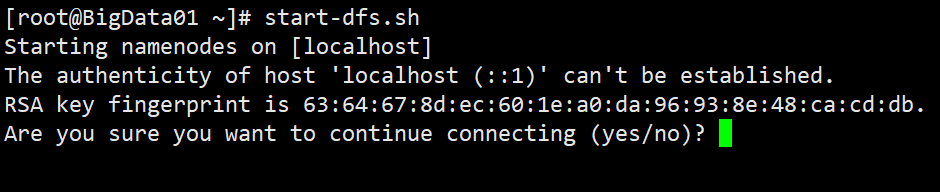
start-dfs.sh就可以启动,如果没有配置环境变量,则需要进入Hadoop主目录下的sbin执行./start-dfs.sh即可,如果出现以下图中的ssh提示,则输入yes,点击回车即可。
停止命令:
stop-dfs.sh单个停止命令:
hadoop-daemon.sh stop namenode #停止NameNode hadoop-daemon.sh stop datanode #停止DataNode hadoop-daemon.sh stop secondarynamenode #停止secondarynamenode注意:同样的如果没有配置环境变量,则需要进入Hadoop主目录下的sbin执行
./stop-dfs.sh才可以启动。
(6)验证(查看是否启动成功)
命令:
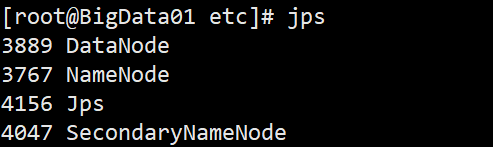
jps使用Oracle官方Java JDK中提供的jps命令,可以查看到有三个进程已经开启,分别是NameNode、DataNode、SecondaryNameNode。则表示启动HDFS成功!
注意:进程名称前面的数字是进程号,每个人查看到的进程号是不一样的。
3、YARN的配置、启动与停止
(配置文件均在hadoop的主目录下操作)
进入Hadoop主目录:cd /opt/hadoop-2.7.3
(1)配置yarn-site.xml
vi etc/hadoop/yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostsname</name> <value>BigData01</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>参数说明:
yarn.resourcemanager.hostsname:该参数是指定ResourceManager运行的节点,这里配置主机名。
yarn.nodemanager,aux-service:该参数是指定NodeManager启动时加载server的方式,即配置YARN的默认混选方式,选择MapReduce的默认混选算法mapreduce_shuffle。
(2)配置mapred-site.xml
该配置文件所在目录下只有
mapred-site.xml.template这个文件,需要将这个文件重命名或者复制一份为mapred-site.xmlcp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xmlvi etc/hadoop/mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>参数说明:
mapreduce.framework.name:该参数是指定MapReduce框架使用YARN方式,即指定MapReduce运行在YARN上。
(3)启动和停止YARN
启动YARN将启动ResourceManager和NodeManager两个守护进程。
启动命令:
start-yarn.sh单独启动命令:
yarn-daemon.sh start resourcemanager #启动ResourceManager yarn-daemon.sh start nodemanager #启动NodeManager停止命令:
stop-yarn.sh单独停止命令:
yarn-daemon.sh stop resourcemanager #停止ResourceManager yarn-daemon.sh stop nodemanager #停止NodeManager
(4)验证(查看是否启动成功)
命令:
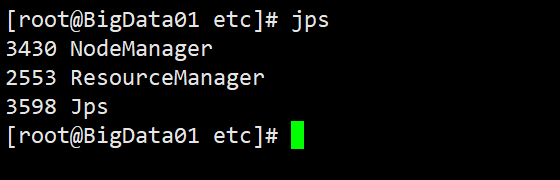
jps显示ResourceManager和NodeManager两个守护进程便启动成功。
4、同时启动或停止HDFS和YARN
上面讲了可以启动HDFS和YARN,是分别启动或停止,还可以同时开启HDFS和YARN。
启动命令:
start-all.sh停止命令:
stop-all.sh查看结果:
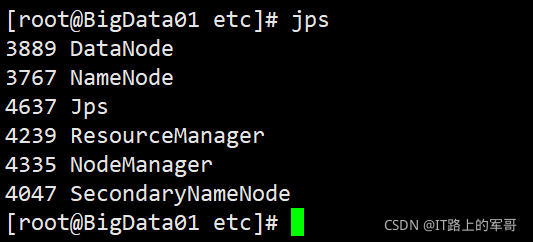
jps如果执行
start-all.sh启动后,HDFS和YARN的所有进程都会启动,同理使用stop-all.sh会将HDFS和YARN全部关闭。
4、Web端访问
关闭防火墙:
service iptables stop访问HDFS:50070
192.168.182.66:50070 #访问HDFS,50070是端口访问YARN:8088
192.168.182.66:8088 #访问YARN,8088是端口注意:根据自己配置的IP地址查看,必须关闭虚拟机里的防火墙,不然访问不了。
下一篇:Hadoop完全分布式模式搭建(超详细)
如果喜欢、对你有帮助,反手点赞+收藏,跟着军哥学知识……