上一阶段的学习
超详细大数据学习之Hadoop HA 高可用安装(一)
https://blog.csdn.net/qq_44500635/article/details/106796553
六、安装zookeeper
这里我们需要先下载好zookeeper在自己的电脑里,在node02,03,04家目录下创建software文件夹
mkdir software
用Xftp把zookeeper放在node02的software目录下
[root@node02 software]# ll
total 17288
-rw-r--r-- 1 root root 17699306 Jun 17 18:55 zookeeper-3.4.6.tar.gz
这里可以看到我们已经传输好了
1、解压安装zookeeper
tar xf zookeeper-3.4.6.tar.gz -C /opt/ll
解压完成
[root@node02 software]# tar xf zookeeper-3.4.6.tar.gz -C /opt/ll
[root@node02 ~]# cd /opt/ll
[root@node02 ll]# ll
total 179300
drwxr-xr-x 10 root root 4096 Jun 17 17:18 hadoop-2.6.5
-rw-r--r-- 1 root root 183594876 Jun 17 17:19 hadoop-2.6.5.tar.gz
drwxr-xr-x 10 1000 1000 4096 Feb 20 2014 zookeeper-3.4.6
2、修改zookeeper的配置文件
cd /opt/ldy/zookeeper-3.4.6/conf
给zoo_sample.cfg改名
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
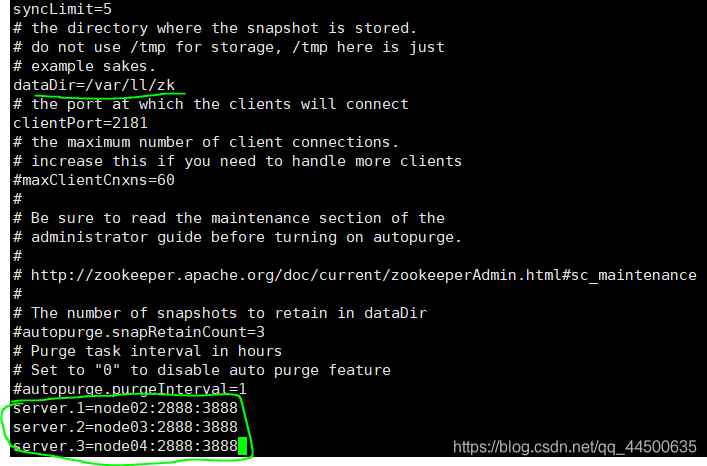
改dataDir=/var/ll/zk
并在末尾追加
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
其中2888主从通信端口,3888是当主挂断后进行选举机制的端口
cd /opt/ll/zookeeper-3.4.6/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
修改的地方
dataDir=/var/ll/zk
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
修改完成后的截图
3、把zookeeper分发node03、node04
cd /opt/ll
scp -r zookeeper-3.4.6/ node03:`pwd`
scp -r zookeeper-3.4.6/ node04:`pwd`
这里会要求输入密码,分发结束后
并用cd /opt/ll检查下看分发成功没
[root@node03 ~]# cd /opt/ll
[root@node03 ll]# ll
total 179300
drwxr-xr-x 10 root root 4096 Jun 17 17:22 hadoop-2.6.5
-rw-r--r-- 1 root root 183594876 Jun 17 17:22 hadoop-2.6.5.tar.gz
drwxr-xr-x 10 root root 4096 Jun 17 19:06 zookeeper-3.4.6
4、给node02、node03、node04创建刚配置文件里的路径
mkdir -p /var/ll/zk
对node02来说:
echo 1 > /var/ll/zk/myid
cat /var/ll/zk/myid
[root@node02 ~]# mkdir -p /var/ll/zk
[root@node02 ~]# echo 1 > /var/ll/zk/myid
[root@node02 ~]# cat /var/ll/zk/myid
1
对node03来说:
echo 2 > /var/ll/zk/myid
cat /var/ll/zk/myid
[root@node03 ~]# mkdir -p /var/ll/zk
[root@node03 ~]# echo 2 > /var/ll/zk/myid
[root@node03 ~]# cat /var/ll/zk/myid
2
对node04来说:
echo 3 > /var/ll/zk/myid
cat /var/ll/zk/myid
[root@node04 ~]# mkdir -p /var/ll/zk
[root@node04 ~]# echo 3 > /var/ll/zk/myid
[root@node04 ~]# cat /var/ll/zk/myid
3
给每台机子配置其编号(必须是阿拉伯数字)
5、在/etc/profile里面配置
[root@node02 ~]# cd /opt/ll
[root@node02 ll]# vi /etc/profile
添加路径和环境变量
export ZOOKEEPER_HOME=/opt/ll/zookeeper-3.4.6
export PATH=$PATH:/usr/java/jdk1.7.0_67/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin
6、然后在把/etc/profile分发到其他node03、node04
scp /etc/profile node03:/etc
scp /etc/profile node04:/etc
这里后要求输入密码
[root@node02 ll]# scp /etc/profile node03:/etc
root@node03's password:
profile 100% 2020 2.0KB/s 00:00
[root@node02 ll]# scp /etc/profile node04:/etc
root@node04's password:
profile 100% 2020 2.0KB/s 00:00
分发完成后
在node02、03、04里source /etc/profile,这步千万别忘
验证source这句是否完成,输入zkCli.s,按Tab可以把名字补全zkCli.sh
source /etc/profile
7、启动zookeeper
全部会话:zkServer.sh start
zkServer.sh start
接着用zkServer.sh status查看每个zookeeper节点的状态
[root@node02 ll]# cd
[root@node02 ~]# zkServer.sh start
JMX enabled by default
Using config: /opt/ll/zookeeper-3.4.6/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
注意:如果启动不起来,请把/etc/profile里的JAVA_HOME改
成绝对路径
vi /etc/profile

七、启动journalnode
Why启动journalnode?
为了使两台namenode间完成数据同步
在01、02、03三台机子上分别把journalnode启动起来
hadoop-daemon.sh start journalnode
用jps检查下进程启起来了没
node01
[root@node01 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-journalnode-node01
.out[root@node01 ~]# jps
2391 JournalNode
2437 Jps
node02
[root@node02 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-journalnode-node02
.out[root@node02 ~]# jps
1668 JournalNode
1701 Jps
1629 QuorumPeerMain
node03
[root@node03 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-journalnode-node03
.out[root@node03 ~]# jps
1525 QuorumPeerMain
1596 Jps
1563 JournalNode
八、namenode的格式化及启动配置
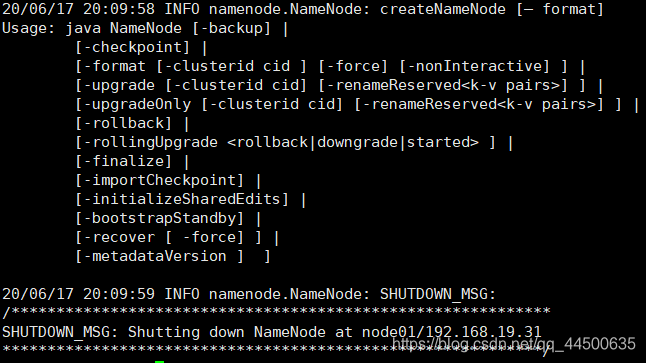
1、格式化node01的namenode
在node01上执行hdfs namenode –format
另一台namenode不用执行,否则clusterID变了,找不到集群了。
hdfs namenode –format
部分截图
2、启动node01的namenode
hadoop-daemon.sh start namenode
[root@node01 ~]# hadoop-daemon.sh start namenode
starting namenode, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-namenode-node01.out
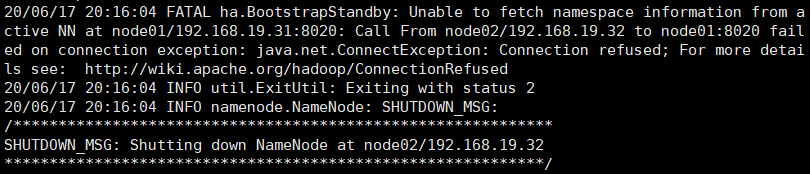
3、在没有格式化的node02上进行数据同步
hdfs namenode -bootstrapStandby
部分截图
4、格式化zkfc
回到node01,执行命令hdfs zkfc -formatZK
hdfs zkfc -formatZK
在node02上用zkCli.sh打开zookeeper客户端,并在zookeeper客户端执行命令ls /,看其中是否有hadoop-ha这一项。
(双击红色地方,弹出node02的副客户机)
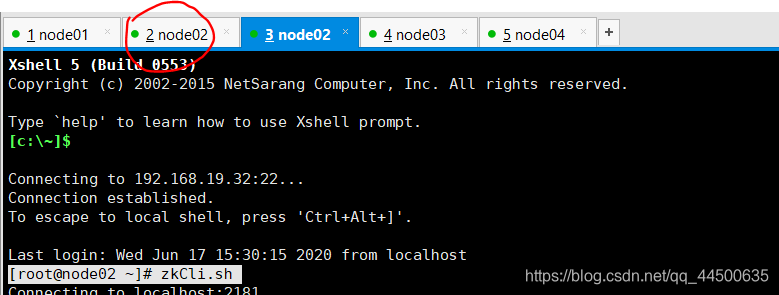
[root@node02 ~]# zkCli.sh
部分显示
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0] ls /
[hadoop-ha, zookeeper]
[zk: localhost:2181(CONNECTED) 1]
九、启动hdfs集群
1、在node03上启动hdfs集群:
start-dfs.sh
start-dfs.sh
注意:如果那个节点没起来到hadoop目录下去看那个node的日志文件log
[root@node01 ~]# start-dfs.sh
Starting namenodes on [node01 node02]
node02: starting namenode, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-namenode-node02.out
node01: starting namenode, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-namenode-node01.out
node04: starting datanode, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-datanode-node04.out
node03: starting datanode, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-datanode-node03.out
node02: starting datanode, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-datanode-node02.out
Starting journal nodes [node01 node02 node03]
node01: starting journalnode, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-journalnode-node01.out
node03: starting journalnode, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-journalnode-node03.out
node02: starting journalnode, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-journalnode-node02.out
Starting ZK Failover Controllers on NN hosts [node01 node02]
node02: starting zkfc, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-zkfc-node02.out
node01: starting zkfc, logging to /opt/ll/hadoop-2.6.5/logs/hadoop-root-zkfc-node01.out
然后全部会话jps看一下都起来些什么进程
node01
[root@node01 ~]# jps
2391 JournalNode
3007 NameNode
2920 DFSZKFailoverController
3040 Jps
node02
[root@node02 ~]# jps
1668 JournalNode
1629 QuorumPeerMain
1938 DFSZKFailoverController
1871 DataNode
2044 NameNode
2077 Jps
node03
[root@node03 ~]# jps
1729 QuorumPeerMain
1779 DataNode
1924 Jps
1861 JournalNode
node04
[root@node04 ~]# jps
1748 Jps
1676 DataNode
1622 QuorumPeerMain
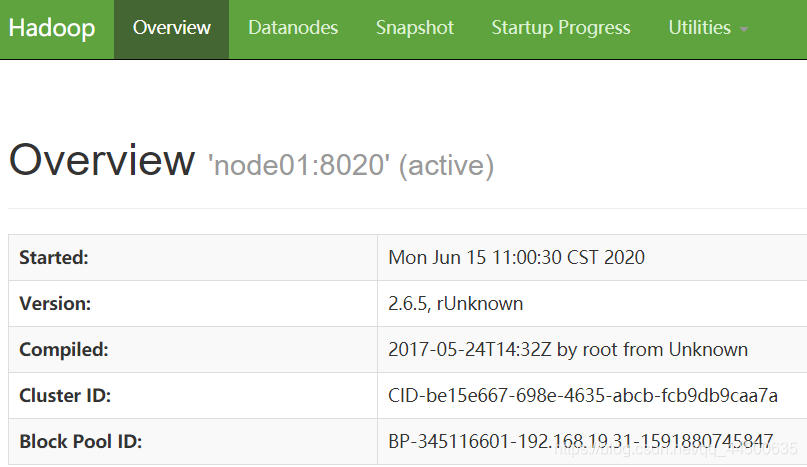
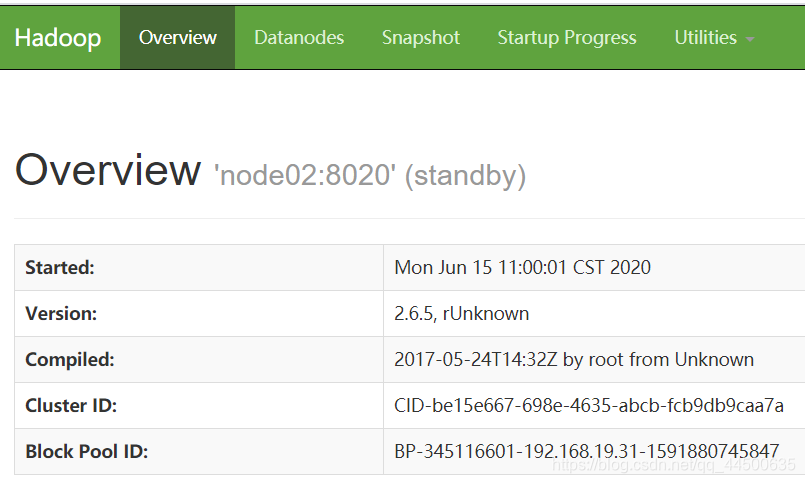
2、用浏览器访问node01、node02
用浏览器访问node01:50070和node02:50070
(这里需要一个active和一个standby)
关闭集群命令:stop-dfs.sh
stop-dfs.sh
关闭zookeeper命令:zkServer.sh stop
zkServer.sh stop
注意:你下一次启动hdfs集群的时候还需要用hadoop-daemon.sh start journalnode命令启动journalnode吗?
不需要
只要start-dfs.sh就可以了。我们之前启动journalnode是为了同步两个namenode之间的信息。(为了防止报错,我们一般先启动zookeeper,再启动集群)
十、为MapReduce做准备
1、把mapred-site.xml.template留个备份,并且改下名字
cp mapred-site.xml.template mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
在mapred-site.xml里添加如下property
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
2、在yarn-site.xml里添加如下property
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node03</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node04</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
3、xml文件的分发
把mapred-site.xml和yarn-site.xml 分发到node02、03、04
scp mapred-site.xml yarn-site.xml node02:`pwd`
scp mapred-site.xml yarn-site.xml node03:`pwd`
scp mapred-site.xml yarn-site.xml node04:`pwd`
[root@node01 ~]# cd /opt/ll/hadoop-2.6.5/etc/hadoop
[root@node01 hadoop]# scp mapred-site.xml yarn-site.xml node02:`pwd`
mapred-site.xml 100% 865 0.8KB/s 00:00
yarn-site.xml 100% 1434 1.4KB/s 00:00
[root@node01 hadoop]# scp mapred-site.xml yarn-site.xml node03:`pwd`
mapred-site.xml 100% 865 0.8KB/s 00:00
yarn-site.xml 100% 1434 1.4KB/s 00:00
[root@node01 hadoop]# scp mapred-site.xml yarn-site.xml node04:`pwd`
mapred-site.xml 100% 865 0.8KB/s 00:00
yarn-site.xml 100% 1434 1.4KB/s 00:00
4、node03、node04之间互相免秘钥
由于node03和node04都是resourcemanager,所以它俩应该相互免密钥 ——————node03上免密钥登录node04:
在node03的.ssh目录下生成密钥
ssh-keygen -t dsa -P '' -f ./id_dsa
并追加到自己authorized_keys
cat id_dsa.pub >> authorized_keys
用ssh localhost验证看是否需要密码,别忘了exit
将node03 的公钥分发到node04
scp id_dsa.pub node04:`pwd`/node03.pub
在node04的.ssh目录下,追加node03.pub
cat node03.pub >> authorized_keys
在node03上ssh node04,看是否免密钥
——————node04上免密钥登录node03:
在node04的.ssh目录下生成密钥
ssh-keygen -t dsa -P '' -f ./id_dsa
并追加到自己authorized_keys
cat id_dsa.pub >> authorized_keys
用ssh localhost验证看是否需要密码,别忘了exit
将node04 的公钥分发到node03
scp id_dsa.pub node03:`pwd`/node04.pub
在node03的.ssh目录下,追加node04.pub
cat node04.pub >> authorized_keys
在node04上ssh node03,看是否免密钥
(和之前的node01与node02之间免秘钥同理)
5、检查jps
1.启动zookeeper,全部会话zkServer.sh start
zkServer.sh start
2.在node01上启动hdfs,start-dfs.sh
start-dfs.sh
3.在node01上启动yarn,start-yarn.sh
start-yarn.sh
4.在node03、04上分别启动resourcemanager,
yarn-daemon.sh start resourcemanager
5.全部会话jps,看进程全不全
node01
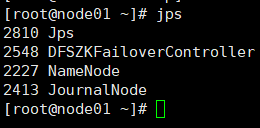
node02
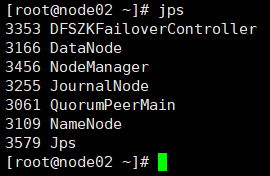
node03
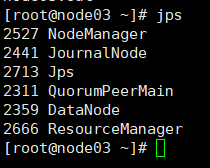
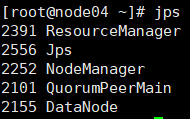
node04
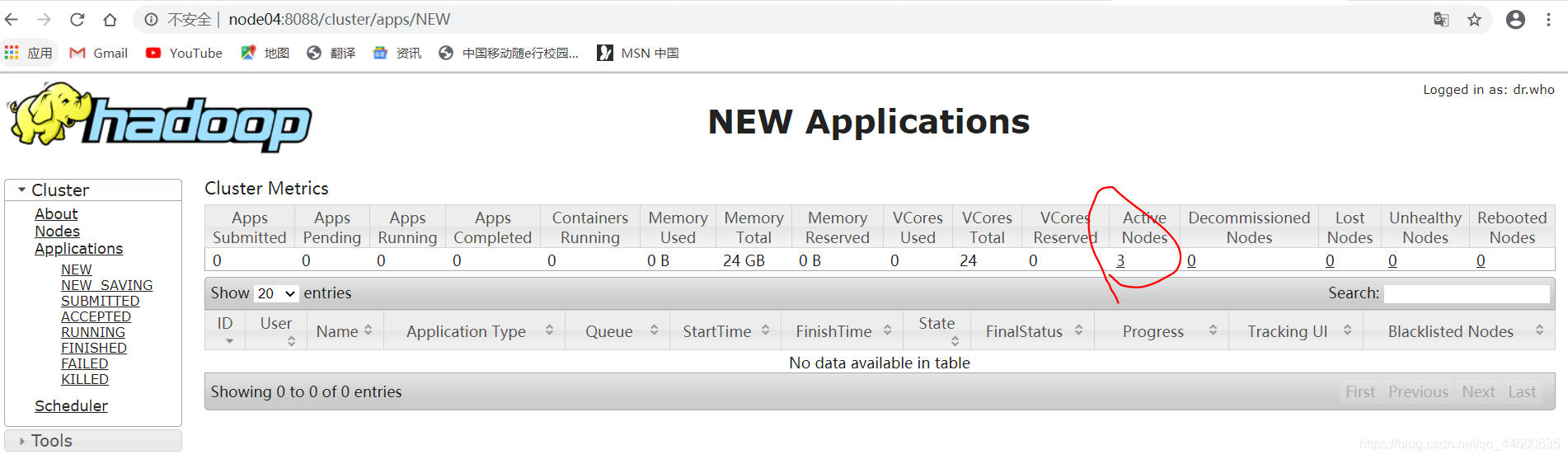
6、在浏览器访问node03:8088,查看resourcemanager管理的内容
7、跑一个wordcount试试
- cd /opt/ll/hadoop-2.6.5/share/hadoop/mapreduce
cd /opt/ll/hadoop-2.6.5/share/hadoop/mapreduce
- 在hdfs里建立输入目录和输出目录
hdfs dfs -mkdir -p /data/in
hdfs dfs -mkdir -p /data/out
hdfs dfs -mkdir -p /data/in
hdfs dfs -mkdir -p /data/out
- 将要统计数据的文件上传到输入目录并查看
hdfs dfs -put ~/500miles.txt /data/in
hdfs dfs -ls /data/in
hdfs dfs -put ~/500miles.txt /data/in
hdfs dfs -ls /data/in
- 运行wordcount(注意:此时的/data/out必须是空目录
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/in /data/out/result
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /data/in /data/out/result

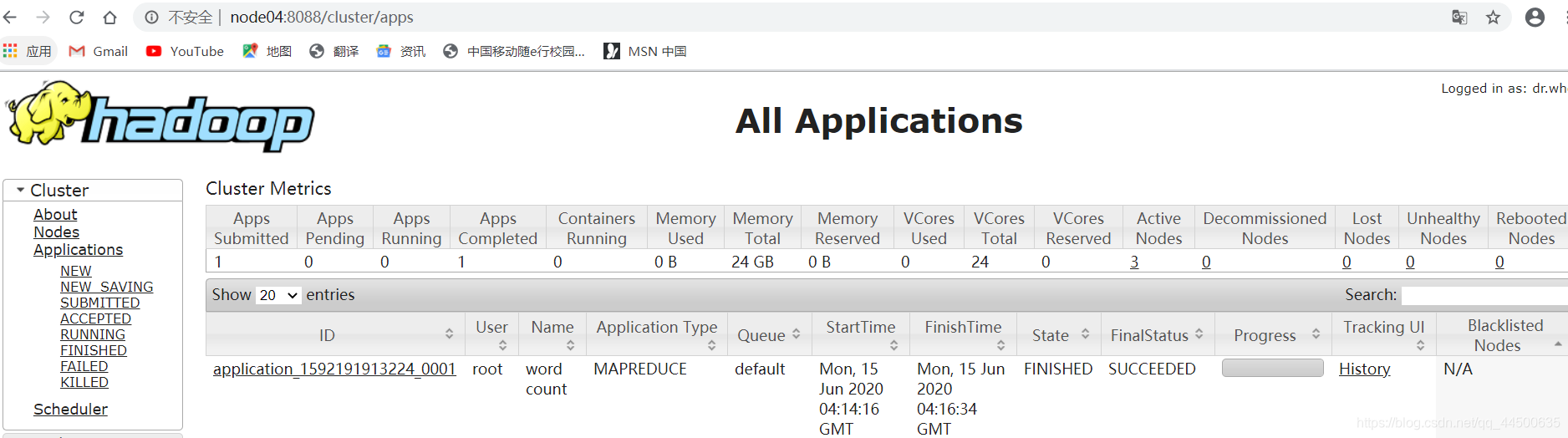
5. 查看运行结果
hdfs dfs -ls /data/out/result
hdfs dfs -cat /data/out/result/part-r-00000
hdfs dfs -ls /data/out/result
hdfs dfs -cat /data/out/result/part-r-00000
[root@node01 mapreduce]# hdfs dfs -ls /data/out/result
Found 2 items
-rw-r--r-- 1 root supergroup 0 2020-06-12 12:41 /data/out/
result/_SUCCESS-rw-r--r-- 1 root supergroup 261 2020-06-12 12:41 /data/out/
result/part-r-00000[root@node01 mapreduce]# hdfs dfs -cat /data/out/result/part-r-00000
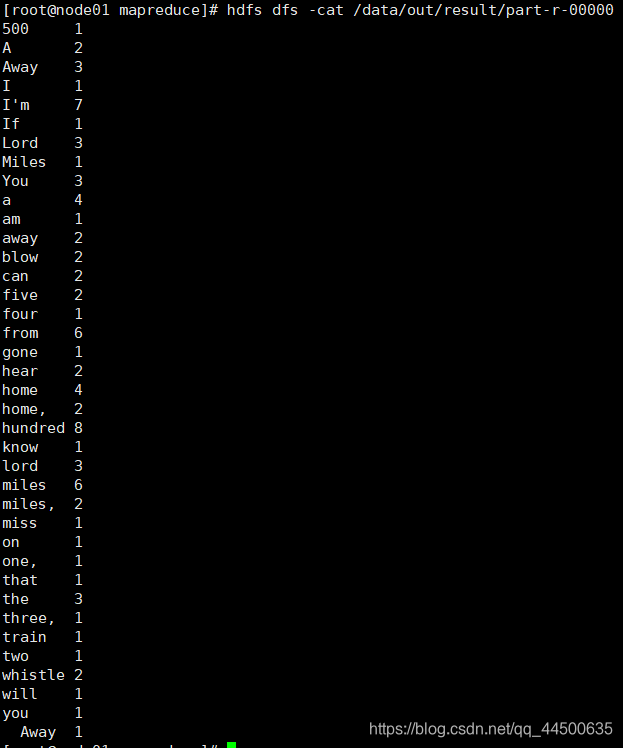
8、关闭集群:
node01: stop-dfs.sh
stop-dfs.sh
node01: stop-yarn.sh (停止nodemanager)
stop-yarn.sh
node03,node04: yarn-daemon.sh stop resourcemanager
yarn-daemon.sh stop resourcemanager
Node02、03、04:zkServer.sh stop
zkServer.sh stop
到这里我们的hadoop HA 高可用安装终于结束了
坚持就是胜利哟!
希望大家安装一路绿灯!✿✿ヽ(°▽°)ノ✿
✿✿ヽ(°▽°)ノ✿✿✿ヽ(°▽°)ノ✿✿✿ヽ(°▽°)ノ✿