如有错误,恳请指出
文章目录
paper:Feature Selective Anchor-Free Module for Single-Shot Object Detection
摘要:
paper中提出了一个anchor-free的特征选择构建模块,可以插入具有特征金字塔结构的单发检测器中。其可以解决两个基于anhcor的传统检测器的限制:1)启发式引导特征选择. 2)基于重叠的anchor采样
FSAF模块的一般概念是应用于多级anchor-free分支训练的在线特征选择。具体而言,anchor-free分支被附加到特征金字塔的每一层,允许在任意层以anchor-free方式进行盒子编码和解码。
在训练过程中,会动态地将每个实例分配到最合适的特征层。在推断过程时,FSAF模块可以通过并行输出预测来与基于anchor的分支联合工作。作者用anchor-free分支和在线特征选择策略的简单实现来实例化这个概念
1. Introduction
目标检测的一个挑战性问题是尺度变化。为了实现尺度不变形,一些SOTA目标检测算法会结合使用特征金字塔结构并行生成预测。其中,anchor被设计用于将所有可能对象(实例盒)的连续空间离散为有限数量的具有预定义位置、比例和纵横比的盒。这些实例框与覆盖面积(Iou)比较大的anchor相匹配。当与特征金字塔结合时,高层特征一般与比较大的anchor相关联,而底层特征一般与比较小的anchor相关联。这是因为高层特征提取的语义信息比较抽象,适合检测大面积的对象,而底层特征保留了丰富的细粒度细节信息,所以适合检测小面积的对象。
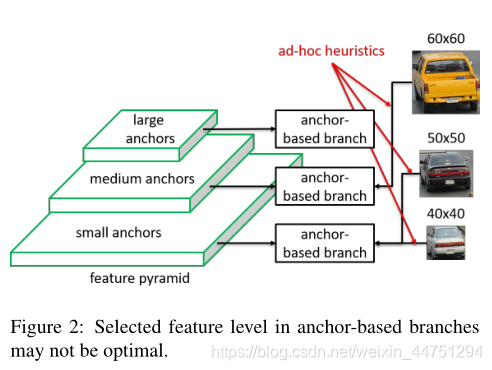
但是这样的设计会存在两个问题:
1)特征选择是探索性的。heuristic-guided feature selection
2)基于重叠的anchor采样。overlap-based anchor sampling
在训练期间,根据IoU重叠,每个对象实例总是匹配到最近的anchor。而通过人为定义的规则(如框的大小),anchor通常与某个具体确定的预测特征层相关联。因此,为每个实例对象选择的特征层完全基于即席试探法。举个例子,有两个小车的尺寸大小分别是50x50与60x60,可能会被分配到两个不同的预测特征层上。而还有一个小车,尺寸大小为40x40,可能却会被分配到与尺度为50x50的小车一个相同的预测特征层。如图1所示。
也就是说,anchor匹配机制本质上是启发式的。这导致了一个主要缺陷,即用于训练每个实例对象的所选特征层可能不是最佳的。
为了解决这个问题,作者提出了FSAF模块,同时解决这两个限制。动机是让每个实例自由选择最佳级别的特预测特征层来优化网络,因此在FSAF模块中不应该有anchor boxes来约束特征选择。所以,作者以anchor-free的方式对实例进行编码,以学习分类和回归的参数。
大概处理过程如图所示:
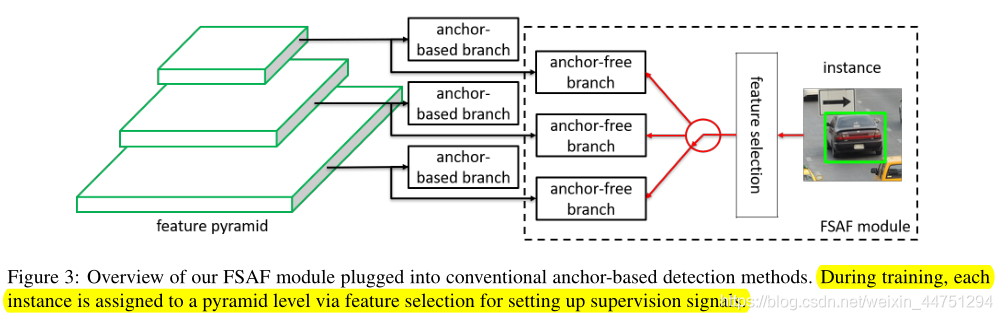
每一级特征金字塔都建立一个独立于anchor-based分支的anchor-free分支。类似于anchor-based分支,它由一个分类子网和一个回归子网组成(这两个子网在图中没有显示出来)。也就是每一层预测特征层都会分别通过anchor-based分支与anchor-free分支。其中,可以将实例对象分配给任意级别的anchor-free分支。
在训练过程中,作者会根据实例对象内容动态地为每个实例选择最合适的特征级别,而不仅仅是实例对象框的尺度大小。然后,选择好的特征级别会学会检测所分配到的实例对象。在推断过程中,FSAF模块可以独立运行,也可以与anchor-based分支联合运行。FSAF模块与主干网络无关,可以应用于具有特征金字塔结构的One-step检测器中。其中,anchor-free分支与在线特征选择的具体实现方式是可变的。作者使用了比较简单的FSAF模块,以降低计算成本。
2. FSAF Module
为了不失一般性,作者将FSAF模块加入到了retinanet中,并从一下内容说明了大致工作:
1)如何在网络中创建anchor-free分支(2.1)
2)如何为anchor-free分支生成监管信号(2.2)
3)如何为每个实例动态选择特征级别(2.3)
4)如何联合训练和测试anchor-free和anchor-based分支(2.4)
2.1 Network Architecture
带有FSAF模块的retinanet结构如图所示:
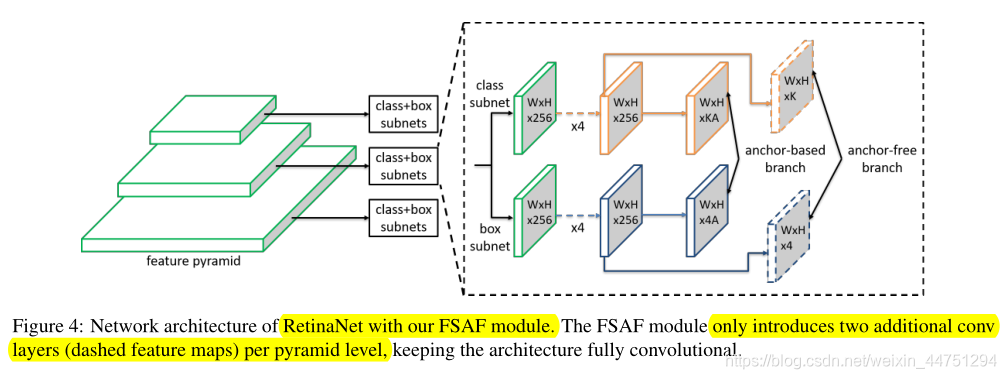
Retinanet网络的具体结构这里不再详述,可以参考我另外一篇笔记:目标检测算法——RetinaNet。为了简单起见,作者在这里只显示了三个级别。金字塔的每一层都用于检测不同比例的物体。与Retinanet类似每一层的预测特征层 P i P_{i} Pi会连接两个子网:分类子网与回归子网。分类子网会对特征图上的每一个特征点预测A个anchor,同时还对这A个anchor分别预测为K类(总共为K类)。而回归子网则是对非背景的anchor预测一个4D的边界框回归参数向量。(其实与Retinanet是一致的)
在Retinanet之上,FSAF模块在每个金字塔层只引入了两个额外的conv层,如图4中虚线特征图所示。这两层分别负责anchor-free分支中的分类和回归预测。其中,带有K个滤波器的3 × 3 conv层被附加到分类子网中的特征映射上,后跟sigmoid函数,与anchor-based分支中的函数并行。它预测K个对象类在每个空间位置的对象概率。类似地,带有四个过滤器的3×3 conv层被附加到回归子网中的特征映射上,后跟ReLU函数。它负责预测以anchor-free方式编码的边界框偏移量。
注意,这里的anchor-free分支是没有涉及anchor的概念的,对于的特征图上的每一个特征点,也就是类似于语义分割的概念,逐像素点进行预测K个类别,逐像素点进行预测4个边界框回归参数,所以称其为anhcor-free分支的预测。
至此,anchor-free分支与anchor-based分支在一个多任务中联合工作,共享每个金字塔级别的特征。
2.2 Ground-truth and Loss
给定一个对象实例,我们知道它的类标签 k k k和边界框坐标 b = [ x , y , w , h ] b = [x,y,w,h] b=[x,y,w,h],其中 ( x , y ) (x,y) (x,y)是框的中心, w , h w,h w,h分别是框的宽度和高度。在训练过程中,可以将这个对象实例指定给任意特征层 P l P_{l} Pl。
这里,将投影框( projected box) b p l = [ x p l , y p l , w p l , h p l ] b^{l}_{p} = [x^{l}_{p},y^{l}_{p},w^{l}_{p},h^{l}_{p}] bpl=[xpl,ypl,wpl,hpl]定义为边界框(bounding box)坐标 b = [ x , y , w , h ] b = [x,y,w,h] b=[x,y,w,h]在特征金字塔 P l P_{l} Pl上的投影,既 b p l = b / 2 l b^{l}_{p} = b/2^{l} bpl=b/2l。
同时,定义有效框(effective box) b e l = [ x e l , y e l , w e l , h e l ] b^{l}_{e} = [x^{l}_{e},y^{l}_{e},w^{l}_{e},h^{l}_{e}] bel=[xel,yel,wel,hel]与忽略框( ignoring box) b i l = [ x i l , y i l , w i l , h i l ] b^{l}_{i} = [x^{l}_{i},y^{l}_{i},w^{l}_{i},h^{l}_{i}] bil=[xil,yil,wil,hil]分别为由恒定比例因子 ϵ e \epsilon_{e} ϵe与 ϵ i \epsilon_{i} ϵi控制的投影框 b p l b^{l}_{p} bpl的比例区域。其对应关系如下:
x e l = x p l , y e l = y p l , w e l = ϵ e w p l , h e l = ϵ e h p l x i l = x p l , y i l = y p l , w i l = ϵ i w p l , h i l = ϵ i h p l x^{l}_{e} = x^{l}_{p},y^{l}_{e} = y^{l}_{p},w^{l}_{e} = \epsilon_{e}w^{l}_{p},h^{l}_{e} =\epsilon_{e} h^{l}_{p} \\ x^{l}_{i} = x^{l}_{p},y^{l}_{i} = y^{l}_{p},w^{l}_{i} = \epsilon_{i}w^{l}_{p},h^{l}_{i} =\epsilon_{i} h^{l}_{p} xel=xpl,yel=ypl,wel=ϵewpl,hel=ϵehplxil=xpl,yil=ypl,wil=ϵiwpl,hil=ϵihpl
其中:作者设置 ϵ e = 0.2 \epsilon_{e} = 0.2 ϵe=0.2与 ϵ i = 0.5 \epsilon_{i} = 0.5 ϵi=0.5。个人觉得可以理解为,其实忽略区域也包含了有效区域,就是比有效区域要稍微大一点。
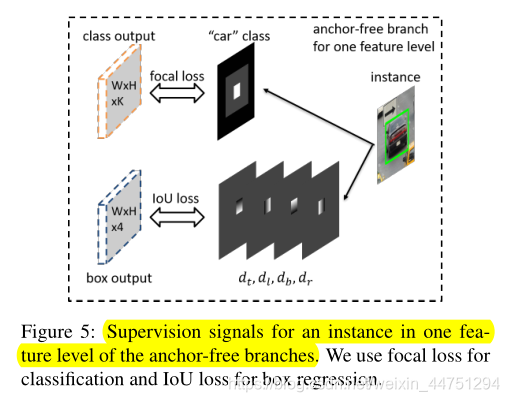
下面以一个汽车实例的ground-truth生成为例子,如图所示:
2.2.1 Classification Output
假设数据集中的K类对象,对于ground truth的分类输出来说就会有K个特征图,其中的每一个map都对应着K类中的某一类对象。而实例对象会在三个方向上影响了第k个ground truth的特征图。(个人觉得,其实理解为对逐像素点进行K分类,也就是每个像素点输出K维的vector。而在整体上看,这就相当于ground truth输出了K个特征图,每个channels对应的就是某一类的特征图)
三个方向影响如下:
1)有效框区域 b e l b^{l}_{e} bel是正样本区域(positive region),其对应于在‘car’这个类别对应的特征图中显示为白色框的填充区域。表示实例对象是存在的。
2)忽略框(ignoring box)中排除有效框(effective box)是忽略区域( b i l b^{l}_{i} bil - b e l b^{l}_{e} bel),显示为灰色区域。这个区域的梯度不会后向传播回网络。如果在相邻的特征层中 P l − 1 , P l + 1 P_{l-1},P_{l+1} Pl−1,Pl+1也存在忽略框(ignoring box),那么这同样属于忽略区域( ignoring regions)。
3)如果两个实例对象的有效框在一个特征层上重叠,则较小的实例对象具有更高的优先级。ground truth其余区域是用零填充的负样本区域(黑色区域),这表示没有实例对象。
图像中anchor-free分支的总分类损失是所有非忽略区域上focal loss的总和,然后由所有有效框区域内的像素总数进行归一化处理。
这里的非忽略区域可能一时间难以理解,根据我个人理解,这里其实作者就是将ground truth的特征图上划分为三个区域:白色区域为有效区域;灰色区域为忽略框排除有效框的区域,也称为忽略区域;其余的黑色区域就是其他剩余的负样本区域。由图5可以比较清晰的看出来。而anchor-free分支的总分类损失是所有非忽略区域上focal loss的总和,其实就表示为总分类损失 = 正样本区域(白色区域)损失 + 负样本区域(黑色区域)损失
2.2.2 Box Regression Output
回归输出的是ground-truth的4个与类无关的边界框偏移特征图,只对对应的有效区域 b e l b^{l}_{e} bel有影响,因为负样本区域与忽略区域不需要预测边界框。作者用一个4维的向量 d i , j l = [ d t i , j l , d l i , j l , d b i , j l , d r i , j l ] d^{l}_{i,j} = [d^{l}_{t_{i,j}},d^{l}_{l_{i,j}},d^{l}_{b_{i,j}},d^{l}_{r_{i,j}}] di,jl=[dti,jl,dli,jl,dbi,jl,dri,jl]来表示投影框 b p l b^{l}_{p} bpl,其中 d t l , d l l , d b l , d r l d^{l}_{t},d^{l}_{l},d^{l}_{b},d^{l}_{r} dtl,dll,dbl,drl分别表示当前像素位置 ( x , y ) (x,y) (x,y)与投影框 b p l b^{l}_{p} bpl顶部、左侧、底部和右侧边界之间的距离。然后,由预测投影框上的偏移距离应该为: [ d t i , j l , d l i , j l , d b i , j l , d r i , j l ] / S [d^{l}_{t_{i,j}},d^{l}_{l_{i,j}},d^{l}_{b_{i,j}},d^{l}_{r_{i,j}}]/S [dti,jl,dli,jl,dbi,jl,dri,jl]/S。(其中:S是一个归一化常数,根据经验选择S = 4.0,类似于缩放因子)。有效框外的位置是忽略梯度的灰色区域。采用IoU损耗进行优化。
图像的anchor-free分支的总回归损失是所有有效框区域的IoU损失的平均值。
其实,这里就是对特征图进行逐像素点进行预测回归参数,也就是对于4层特征图,每个特征图预测与投影框某一边的相对距离。然后对有效框区域中的全部特征点的边界框回归损失的平均值进行优化处理。
2.2.3 Inference
在推断过程中,从分类和回归输出中解码预测框是比较简单的。对于特征图上的每个像素位置 ( i , j ) (i,j) (i,j),假设预测的偏移是 [ O ^ t i , j , O ^ l i , j , O ^ b i , j , O ^ r i , j ] [\hat{O}_{t_{i,j}},\hat{O}_{l_{i,j}},\hat{O}_{b_{i,j}},\hat{O}_{r_{i,j}}] [O^ti,j,O^li,j,O^bi,j,O^ri,j],那么实际上在预测投影框上的预测偏移为: [ S O ^ t i , j , S O ^ l i , j , S O ^ b i , j , S O ^ r i , j ] [S\hat{O}_{t_{i,j}},S\hat{O}_{l_{i,j}},S\hat{O}_{b_{i,j}},S\hat{O}_{r_{i,j}}] [SO^ti,j,SO^li,j,SO^bi,j,SO^ri,j],也就是 [ O ^ t i , j , O ^ l i , j , O ^ b i , j , O ^ r i , j ] ⋅ S [\hat{O}_{t_{i,j}},\hat{O}_{l_{i,j}},\hat{O}_{b_{i,j}},\hat{O}_{r_{i,j}}]·S [O^ti,j,O^li,j,O^bi,j,O^ri,j]⋅S。所以,预测投影框的左上角和右下角分别是 ( i − S O ^ t i , j , j − S O ^ l i , j ) (i-S\hat{O}_{t_{i,j}},j-S\hat{O}_{l_{i,j}}) (i−SO^ti,j,j−SO^li,j)与 ( i + S O ^ b i , j , j + S O ^ r i , j ) (i+S\hat{O}_{b_{i,j}},j+S\hat{O}_{r_{i,j}}) (i+SO^bi,j,j+SO^ri,j)。然后进一步将投影框放大 2 l 2^{l} 2l倍,以获得图像平面中的最终框。盒子的置信度得分和类别可以由分类输出图上位置 ( i , j ) (i,j) (i,j)处的K维向量的最大得分和相应类别决定。
2.3 Online Feature Selection
anchor-free分支的设计允许我们使用任意金字塔层级 P l P_{l} Pl的特性来学习每个实例对象。为了找到最佳特征层级,FSAF模块基于实例内容选择最佳方案,而不是像anchor-based方法那样探索性地选择实例框的大小。
对于实例对象 I I I,定义其在预测特征层 P l P_{l} Pl上的分类损失与边界框回归损失分别为 L F L l ( l ) L^{l}_{FL}(l) LFLl(l)与 L I o U l ( l ) L^{l}_{IoU}(l) LIoUl(l)。这两个损失是通过对有效框盒区 b e l b^{l}_{e} bel上的focal loss与IoU损失进行平均来计算的。定义如下:
L F L l ( l ) = 1 N ( b e l ) ∑ i , j ∈ b e l F L ( l , i , j ) L I o U l ( l ) = 1 N ( b e l ) ∑ i , j ∈ b e l I o U ( l , i , j ) L^{l}_{FL}(l) = \frac{1}{N(b^{l}_{e})}\sum_{i,j∈b^{l}_{e}}FL(l,i,j) \\ L^{l}_{IoU}(l) = \frac{1}{N(b^{l}_{e})}\sum_{i,j∈b^{l}_{e}} IoU(l,i,j) LFLl(l)=N(bel)1i,j∈bel∑FL(l,i,j)LIoUl(l)=N(bel)1i,j∈bel∑IoU(l,i,j)
其中, N ( b e l ) N(b^{l}_{e}) N(bel)是有效框盒区 b e l b^{l}_{e} bel内的像素点个数。而 F L ( l , i , j ) FL(l,i,j) FL(l,i,j)与 I o U ( l , i , j ) IoU(l,i,j) IoU(l,i,j)分别是预测特征层 P l P_{l} Pl上位置 ( i , j ) (i,j) (i,j)出的焦点损失与IoU损失。
在线特征选择过程如图所示:

实例对象 I I I会在前向传播中通过所有的预测特征层,然后在所有的anchor-free分支中,使用上述损失公式来分别计算 L F L l ( l ) L^{l}_{FL}(l) LFLl(l)与 L I o U l ( l ) L^{l}_{IoU}(l) LIoUl(l)的总和。最后,选择产生最小损失总和的最佳金字塔层级 P l ∗ P_{l^{*}} Pl∗来学习这个实例对象。其中,可以通过优化公式表示这个处理过程:
l ∗ = arg min l ( L F L l ( l ) + L I o U l ( l ) ) l^{*} = \arg \min_{l}(L^{l}_{FL}(l) + L^{l}_{IoU}(l)) l∗=arglmin(LFLl(l)+LIoUl(l))
也就是使得 L F L l ( l ) L^{l}_{FL}(l) LFLl(l)+ L I o U l ( l ) L^{l}_{IoU}(l) LIoUl(l)的总损失最小的那一层预测特征层 l l l,就是所要的最佳预测特征层 l ∗ l^{*} l∗。
对于一个训练批次,特征会针对其相应分配的实例进行更新。一般来说,经过优化处理后的FSAF模块所选择的预测特征层应该是最佳的选择。这个经过挑选的损失形成了特征空间的下限。通过训练,可以进一步拉低这个下限。在推断过程中,我们不再需要选择特征,因为最适合的特征金字塔级别自然会输出一个比较高的置信度得分。
2.4 Joint Inference and Training
当FSAF模块与retinanet结合时,FSAF模块可以与anchor-based分支共同工作。作者保持anchor-based分支为原始分支,在训练和推理中所有超参数不变。
2.4.1 Inference
FSAF模块只是在全卷积retinanet结构中添加了几个卷积层,所以推理过程中仍然像通过前向传播图像一样简单。对于anchor-free分支,通过调节置信度阈值为0.05,对于每个预测特征层最多只挑选前1000个最高得分的特征点。而这些来自各个金字塔层级anchor-free分支中最高得分的预测特征点,将会与来自anchor-based分支的框预测合并,共同作为后处理阶段的anhcor输入。随后是进行阈值为0.5的非最大抑制抑制算法,产生最终检测。
所以,在我看来,作者提到的利用anchor-based分支与anchor-free分支进行联合训练的过程,其实就是各自挑选出置信度比较高的anchor或者是挑选出置信度比较高的特征点再通过4个边界框回归参数所得的anchor,一同作为最后的后处理算法的anhor输入而已。也正是如此,对于anchor-based分支与anchor-free分支两个分支,单独训练anchor-based分支就是类似于retinanet结构;而单独训练anchor-free就是类似于FCOS结构。从结果上看,联合训练的效果可能会好一点。
至此,FSAF算法流程已经大致清楚了。
2.4.2 Initialization
主干网络在ImageNet1k上进行了预训练,骨干网络的初始化与retinanet一致。对于FSAF模块中的conv图层,作者使用偏置对数 − log ( ( 1 π ) / π ) -\log((1π)/π) −log((1π)/π)和填充 σ = 0.01 σ = 0.01 σ=0.01的高斯权重初始化分类图层,其中π指定在训练开始时,每个像素位置输出π附近的对象分数。与retinanet一致,设置 π = 0.01 π = 0.01 π=0.01.所有盒子回归层都用偏置b初始化,高斯权重用 σ = 0.01 σ = 0.01 σ=0.01填充。作者在所有实验中使用 b = 0.1 b = 0.1 b=0.1。通过防止大的损失,初始化有助于在早期迭代中稳定网络学习。
总体上的模型结构初始化与retinanet初始化是类似的。
2.4.3 Optimization
当进行联合训练时,整个网络的损失是来自anchor-free分支和anchor-based分支的综合损失。假定, L a b L^{ab} Lab为最原始的retinanet的损失; L c l s a f L^{af}_{cls} Lclsaf与 L r e g a f L^{af}_{reg} Lregaf分别与anchor-free分支的总分类损失和回归损失。
所以在联合训练中,总的优化损失为:
L = L a b + λ ( L c l s a f + L r e g a f ) L = L^{ab} + λ(L^{af}_{cls} + L^{af}_{reg}) L=Lab+λ(Lclsaf+Lregaf)
其中λ控制anchor-free分支的权重因子,作者在所有实验中设置 λ = 0.5 λ = 0.5 λ=0.5
除非另有说明,所有模型都以0.01的初始学习率训练90k次迭代,在60k次迭代时除以10,在80k次迭代时再次除以10。水平图像翻转是唯一应用的数据增强。重量衰减为0.0001,动量为0.9
3. Result
-
在线特征选择的作用:
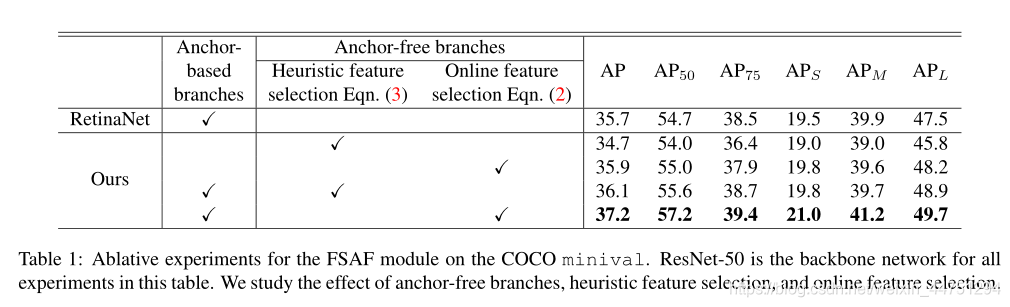
-
anchor-free分支与anchor-based分支联合训练的作用:
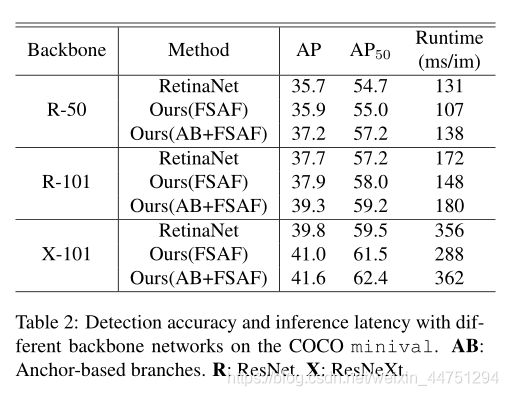
本质上来看,对于anchor-based分支与anchor-free分支两个分支,单独训练anchor-based分支就是类似于retinanet结构(所以实验结果是类似的,不过backbone为X-101时差别好像比较大,可能是在线特征选择模块带来的提升);而单独训练anchor-free就是类似于FCOS结构(也就是利用语义分割的想法作用在目标检测上,进行逐像素点的分类与边界回归预测) -
与其他sota算法的对比:
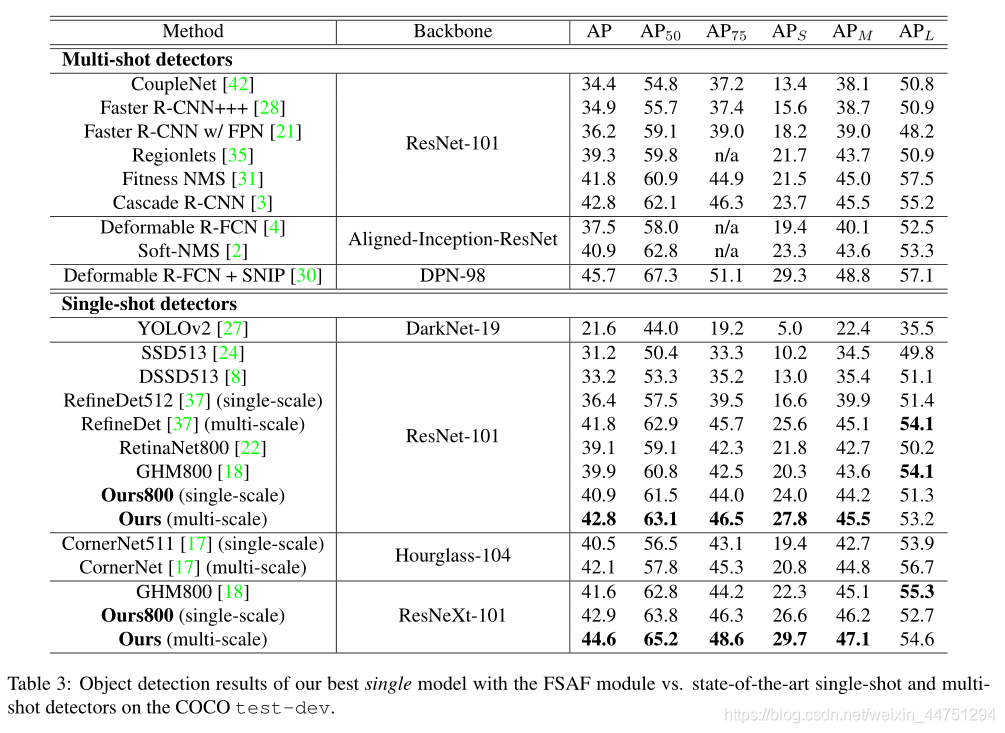
总结:
paper中提出的利用anchor-free分支进行在线特征层选择(Online Feature Selection)是一个提高检测性能的一个技巧,并且提出了一个类似语义分割的思想来进行目标检测。最后,通过anchor-free与anchor-based两个分支进行联合训练,可以进一步的提高检测性能。可以说,利用类似语义分割的思想来进行目标检测,这个想法与FCOS的比较一致的。关于FCOS的介绍可以查看链接:论文阅读笔记 | 目标检测算法——FCOS算法