如有错误,恳请指出。
文章目录
paper:Deformable Convolutional Networks
摘要:
卷积神经网络由于其构建模块中固定的几何结构,本质上受限于模型几何变换。为了提高卷积神经网络的转换建模能力,作者提出了两个模块:可变形卷积(deformable convolution)和可变形RoI池(deformable RoI pooling)。这两个模块均基于用额外的偏移来增加模块中的空间采样位置以及从目标任务中学习偏移的思想,而不需要额外的监督。
第一次证明了在深度神经网络中学习密集空间变换(dense spatial transformation)对于复杂的视觉任务是有效的
1. Introduction
视觉识别中的一个关键挑战是如何适应对象比例、姿态、视点和零件变形中的几何变化或模型几何变换。一般有两种方法实现:
1)建立具有足够期望变化的训练数据集。这通常通过增加现有的数据样本来实现,例如通过仿射变换。但是训练成本昂贵而且模型参数庞大。
2)使用变换不变(transformation-invariant)的特征和算法。比如比较有名的SIFT(尺度不变特征变换)便是这一类的代表算法。
但以上的方法有两个缺点:
1)几何变换被假定为固定的和已知的,这些先验知识被用来扩充数据,设计特征和算法。为此,这个假设阻止了对具有未知几何变换的新任务的推广,从而导致这些几何变换可能没有被正确建模。
2)对于不变特征和算法进行手动设计,对于过于复杂的变换可能是困难的或不可行的。
卷积神经网络本质上局限于模拟大型未知转换。局限性源于CNN模块的固定几何结构:卷积单元在固定位置对输入特征图进行采样;池化层以固定比率降低特征矩阵分辨率;RoI(感兴趣区域)池化层将RoI分成固定的空间箱(spatial bins)等。缺乏处理几何变换的内部机制。
这种内部机制的缺乏会导致一些问题,举个例子。同一个CNN层中所有激活单元的感受野大小是相同的,但是这是不可取的。因为不同的位置可能对应于具有不同尺度或变形的对象,所以尺度或感受野大小的自适应确定对于具有精细定位的视觉识别是渴望的。
对于这些问题,作者提出了两个模块提高CNNs对几何变换建模的能力。
-
deformable convolution(可变形卷积)
将2D偏移量添加到标准卷积中的常规网格采样位置,使得采样网格能够自由变形。通过额外的卷积层,从前面的特征映射中学习偏移。因此,变形采用局部、密集和自适应的方式取决于输入特征。

-
deformable RoI pooling(可变形RoI池化)
为先前RoI池化的常规库(bin)分区中的每个库位置(bin partition)增加了一个偏移量。类似地,偏移是从前面的特征图和感兴趣区域中学习的,从而能够对具有不同形状的对象进行自适应部件定位(adaptive part localization)。
2. Deformable Convolutional Networks
2.1 Deformable Convolution
2D卷积由两个步骤组成:
1)在输入特征图 x x x上使用规则网格 R R R进行采样。
2)把这些采样点乘不同权重 w w w后相加。
网格R定义感受野大小和扩张程度,比如内核大小为3x3,扩张程度为1的网格R可以表示为:
R = { ( − 1 , − 1 ) , ( − 1 , 0 ) , … , ( 0 , 1 ) , ( 1 , 1 ) } R = \{(-1,-1),(-1,0),\dots,(0,1),(1,1)\} R={
(−1,−1),(−1,0),…,(0,1),(1,1)}
对于输出特征图上的每个位置 P 0 P_{0} P0,其卷积表达式为:
y ( P 0 ) = ∑ p n ∈ R w ( p n ) ⋅ x ( p 0 + p n ) y(P_{0}) = \sum_{p_{n}\in R}w(p_{n})·x(p_{0}+p_{n}) y(P0)=pn∈R∑w(pn)⋅x(p0+pn)
其中, p n p_{n} pn表示为枚举 R R R的位置。也就是,如果使用3x3的卷积核进行卷积操作,将网格上的每个位置 p 0 + p n p_{0}+p_{n} p0+pn与对应位置的权重 w w w点乘后累加即可。
在可变性卷积操作中,由于所进行的卷积网格不再是规律排列,而是有另外的卷积操作预测位置,所以会在原来的排列位置中进行偏移 { ∆ p n ∣ n = 1 , … , N } \{∆p_{n} |n=1,\dots,N \} {
∆pn∣n=1,…,N},其中 N = ∣ R ∣ N = |R| N=∣R∣,这里只是用来表示有多少个对应位置而已,所以使用绝对值。所以,在可变卷积中,对于输出特征图上的每个位置 P 0 P_{0} P0,其卷积表达式为:
y ( P 0 ) = ∑ p n ∈ R w ( p n ) ⋅ x ( p 0 + p n + ∆ p n ) y(P_{0}) = \sum_{p_{n}\in R}w(p_{n})·x(p_{0}+p_{n}+∆p_{n}) y(P0)=pn∈R∑w(pn)⋅x(p0+pn+∆pn)
则现在由标准卷积中的采样位置 p n p_{n} pn变为了不规则偏移的采样位置 p n + ∆ p n p_{n}+∆p_{n} pn+∆pn,而由于偏移量 ∆ p n ∆p_{n} ∆pn一般为小数,使用双线性插值进行处理。(把小数坐标分解到相邻的四个整数坐标点来计算结果)
具体操作如图所示:
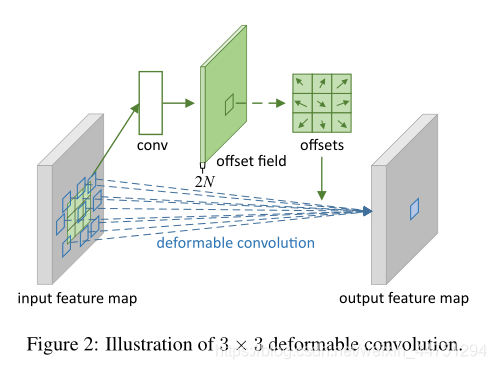
首先对输入特征层进行一个普通的3x3卷积处理得到偏移域(offset field)。偏移域特征图具有与输入特征图相同的空间分辨率,channels维度2N对应于N个2D(xy两个方向)偏移。其中的N是原输入特征图上所具有的N个channels,也就是输入输出channels保持不变,这里xy两个channels分别对输出特征图上的一个channels进行偏移。确定采样点后就通过与相对应的权重w点乘相加得到输出特征图上该点最终值。
前面也提到过,由于这里xy两个方向所训练出来的偏移量一般来说是一个小数,那么为了得到这个点所对应的数值,会采用双线性插值的方法,从最近的四个邻近坐标点中计算得到该偏移点的数值,公式如下:
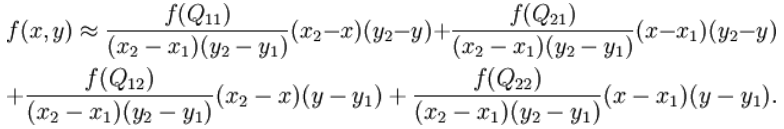
具体推理过程见:双线性插值原理
2.2 Deformable RoI Poolingb
所有基于区域提议(RPN)的对象检测方法都使用RoI池话处理,将任意大小的输入矩形区域转换为固定大小的特征图。
对于输入特征图 x x x,RoI的大小为 w × h w \times h w×h,左上角顶点为 p 0 p_{0} p0,RoI Pooling将RoI切分成 k × k k \times k k×k个区域,得到输出特征图 y y y。对于特征图 y y y的每一个格子 ( x , y ) (x,y) (x,y),都有:
y ( i , j ) = ∑ p ∈ b i n ( i , j ) x ( p 0 + p ) / n i j y(i,j) = \sum_{p ∈bin(i,j)}x(p_{0}+p)/n_{ij} y(i,j)=p∈bin(i,j)∑x(p0+p)/nij
其中, n i j n_{ij} nij表示每个格子中的像素数,也就是将每个格子内的特征点值去平均作为整个网格的数值。
同样的,在可变性RoI池化操作中,由于所进行的RoI池化不再是规律排列,而是有另外的RoI池化操作预测位置,所以会在原来的排列位置中进行偏移 { ∆ p i j ∣ 0 ≤ i , j < k } \{∆p_{ij} |0≤i,j<k \} {
∆pij∣0≤i,j<k},所以上式会变成:
y ( i , j ) = ∑ p ∈ b i n ( i , j ) x ( p 0 + p + ∆ p i j ) / n i j y(i,j) = \sum_{p ∈bin(i,j)}x(p_{0}+p+∆p_{ij})/n_{ij} y(i,j)=p∈bin(i,j)∑x(p0+p+∆pij)/nij
同样的,偏移量 ∆ p i j ∆p_{ij} ∆pij一般为小数,需要使用双线性插值进行处理。
具体操作如图所示:
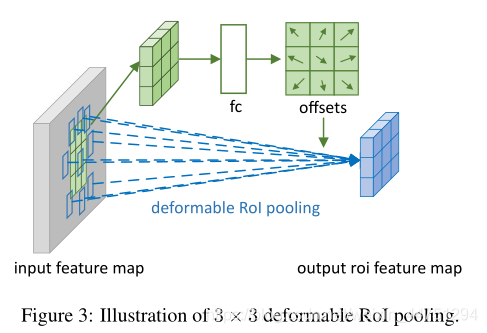
首先,将输入特征图经过一个普通的RoI池化操作,得到kxk网格大小的特征图,之后在此特征图上通过一个全连接层得到归一化偏移 ∆ p ^ i j ∆\hat{p}_{ij} ∆p^ij,再通过公式转化为 ∆ p i j ∆p_{ij} ∆pij,既 ∆ p i j = γ ⋅ ∆ p ^ i j ○ ( w , h ) ∆p_{ij} = γ·∆\hat{p}_{ij}○(w,h) ∆pij=γ⋅∆p^ij○(w,h),其中 γ = 0.1 γ=0.1 γ=0.1, ○ ○ ○表示点积操作。得到的这个偏移域特征图重新作用于RoI池化,即可得到RoI池化。
当时看这个部分的时候觉得有些突兀,明明RoI池化会将特征层转化为固定尺寸的区域。其实,我个人觉得,这个部分与上述的可变性卷积操作是类似的。这里同样是使用了一个普通的RoI池化操作,进行一些列处理后得到了一个偏移域特征图,然后重新作用于原来的 w × H w \times H w×H的RoI。只不过这里不再是规律的逐行逐列对每个格子进行池化,而是对于格子进行偏移后再池化处理。
2.3 Postion﹣Sensitive RoI Pooling
除此之外,论文还提出一种PS RoI池化(Postion﹣Sensitive RoI Pooling)。不同于上述可变形RoI池化中的全连接过程,这里使用全卷积替换。
具体操作如图所示:
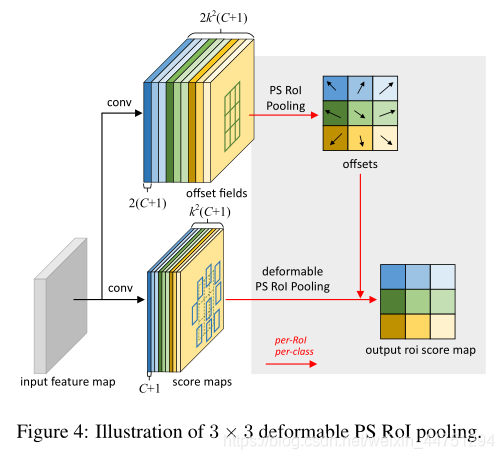
首先,对于原来的特征图来说,原本是将输入特征图上的RoI区域分成 k × k k\times k k×k个bin。而在这里,则是将输入特征图进行卷积操作,分别得到一个channels为 k 2 ( C + 1 ) k^{2}(C+1) k2(C+1)的得分图(score maps)和一个channels为 2 k 2 ( C + 1 ) 2k^{2}(C+1) 2k2(C+1)的偏移域(offset fields),这两个特征矩阵的宽高是与输入特征矩阵相同的。其中,得分图的channels中, k × k k \times k k×k分别表示的是每一个网格, C C C表示的检测对象的类别数目,1表示背景。而在偏移域中的2表示xy两个方向的偏移。
也就是说,在PS RoI池化中,对于RoI的每一个网格都独自占一个通道形成一层得分图,然后其对于的偏移量占两个通道。offset fields得到的偏移是归一化后的偏移,需要通过和deformable RoI pooling中一样的变换方式得到 ∆ p i j ∆p_{ij} ∆pij,然后对每层得分图进行偏移池化处理。最后处理完的结果就对应着最后输出的一个网格。所以其包含了位置信息。
原文论述为:

3. Understanding Deformable ConvNets
当可变形卷积叠加时,复合变形的效果是深远的。如图所示:
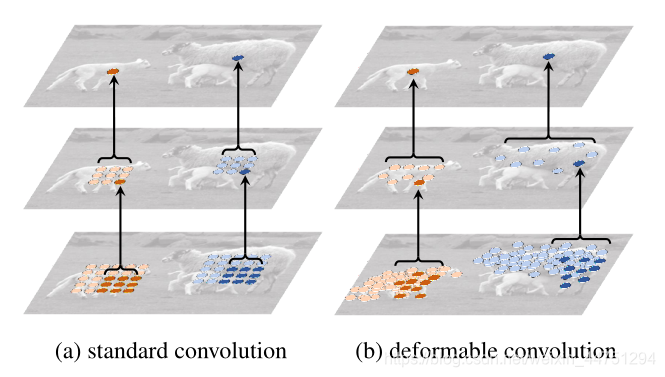
ps:a是标准卷积的固定感受野,b是可变形卷积的适应性感受野。
感受野和标准卷积中的采样位置在整个顶部特征图上是固定的(左)。在可变形卷积中,它们根据对象的比例和形状进行自适应调整(右)。

4. Result
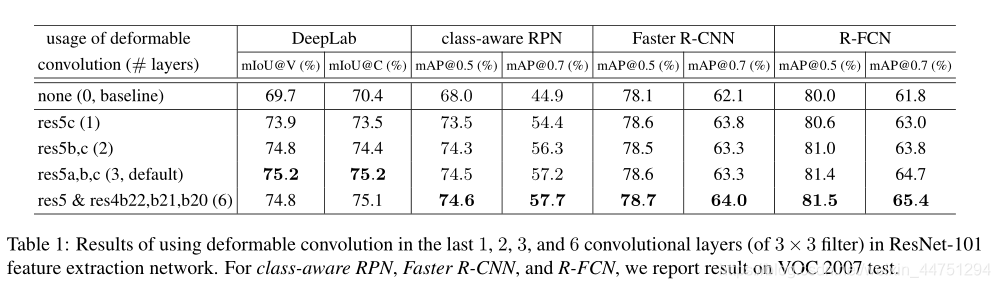
- 实验证明使用3层可变型卷积层的效果最好:
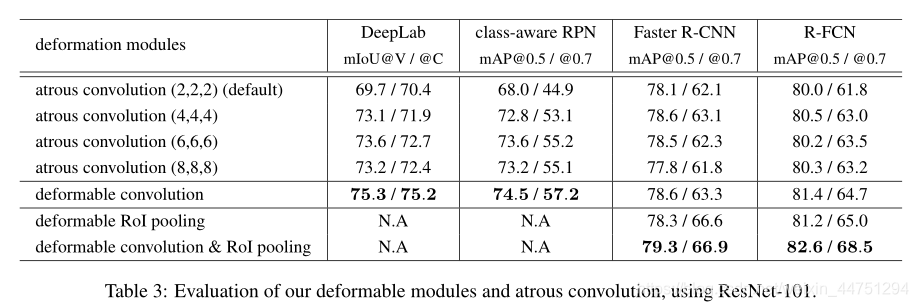
- 两个可变形模块的效果评估:
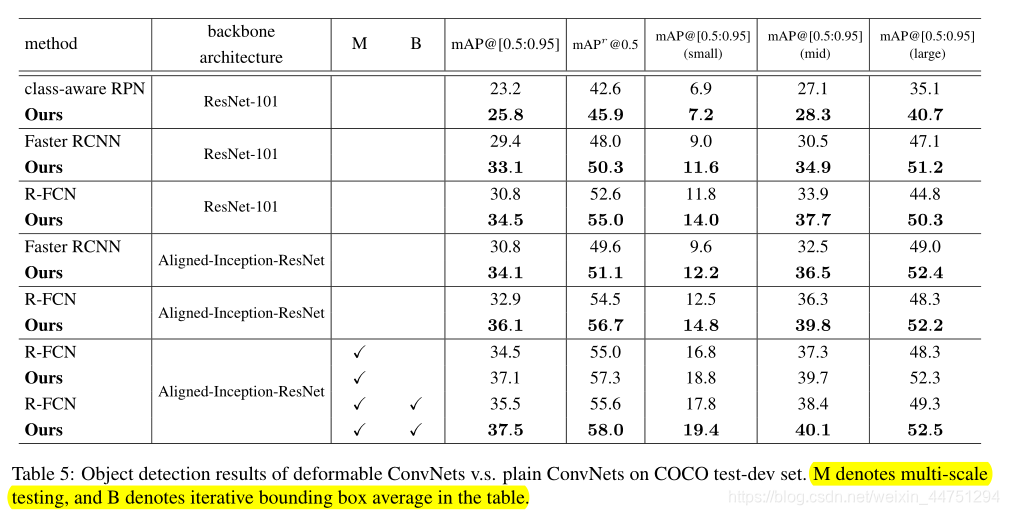
- 结合经典模型带来的提升对比:
总结:
创新性得提出了两种可变形模块——可变形卷积与RoI池化操作,证明了在CNNs中学习密集空间变换对于复杂的视觉任务是可行有效的。