如有错误,恳请指出。
paper:Soft Anchor-Point Object Detection
摘要:
目前anchor-free目标检测算法取得了比较大的进步,anchor-free算法可以分为两种:一种是关键点检测(keypoint detection),eg:cornernet检测左上角与右下角,centernet检测中心点与4条边,都属于这种。另外一种是锚点检测(anchor-point detection),用语义分割的思想作用在目标检测任务上,逐像素点进行分类回归,eg:FSAF,FCOS算法均属于这一种。一般来说,anchor-free的这两种算法都是各有优点,处于速度-精度权衡的相对边缘。锚点检测的速度会快一点,而关键点检测的精度会高一点。
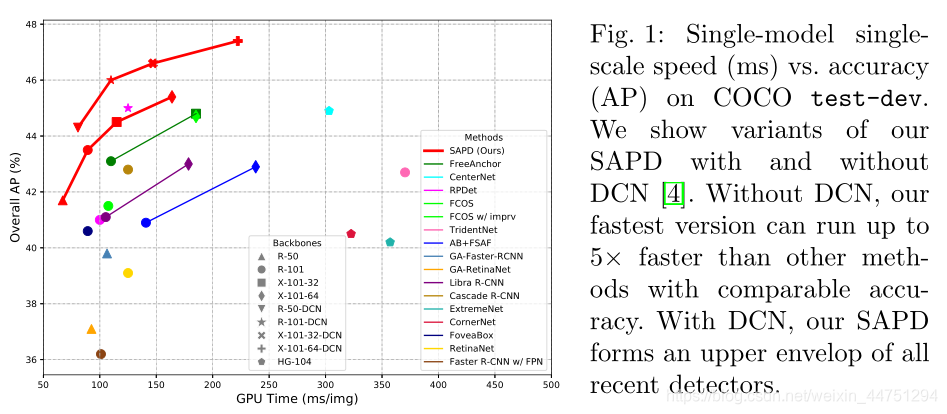
paper的想法就是,在保持锚点检测速度优势的同时,将精度也提高至优于关键点检测的水平,提出了SAPD算法。所以SAPD算法在那是是出于综合考虑速度与精度最好的算法,优于那是最先进的anchor-based和anchor-free的检测器。
回到问题上,对于同样是anchor-free算法,如何解决锚点检测的精度不如关键点检测高。作者从锚点检测的角度定位出主要的问题是锚点检测存在大量的无效训练(ineffective training)。作者的一个见解是:锚点(anchor points)应该作为一个组在特征金字塔的一个预测特征层及跨越特征金字塔的多个预测特征层中进行联合优化。
为此,作者提出了一种简单而有效的训练策略,使用软加权锚点(soft-weighted anchor points)和软选择金字塔层次(soft-selected pyramid levels),分别解决每个金字塔层级内的错误注意问题和在所有金字塔层级之间的特征选择问题。
1. Introduction
anchor-free目标检测算法不依赖与anchor boxes,预测是以point(s)-to-box的方式生成,相比于传统的anchor-based算法,anchor-free检测具有一些优点:
1)不需要手动设置anchor的超参数
2)预测子网结构比较简单
3)较少的训练内容成本
在FCOS与FSAF这两篇论文中也有介绍过,anchor-free检测器一般可以划分为两类:锚点检测和关键点检测。
锚点检测器,将对象边界框编码和解码为具有相应点到边界距离的锚点,其中锚点是金字塔特征地图上的像素,并且它们在它们的位置与特征相关联,就像锚点框一样。
关键点检测器,使用高分辨率特征图和重复的自下而上与自上而下的推理来预测边界框的关键点的位置,例如拐角、中心或极值点,并将这些关键点分组以形成框。
与关键点检测器相比,锚点检测器有几个优点:
1)网络结构更简单
2)训练和推理速度更快
3)受益于特征金字塔扩展的潜力
4)灵活的预测特征层级选择选择
然而,在相同的测试图像尺度下,它们不能像基于关键点的方法那样精确,也就是关键点检测器的精确度一般比锚点检测器要高。为此,作者提出了SAPD算法,使得锚点检测能够在速度与精度上都要比关键点检测要好。为了实现这一点,作者从锚点的角度来阐述检测问题,并将无效训练确定为阻碍锚点检测器在特征金字塔级别内和跨特征金字塔级别探索更多网络能力潜力的主要障碍。
作者也提出,传统的训练策略有两个被忽略的问题,即每个金字塔层级内的错误注意(false attention)和所有金字塔层次上的特征选择(这个层级选择FSAF也提出了一个在线特征选择的思想)。
- 问题一:每个金字塔层级内的错误注意
对于同一金字塔层次上的锚点,在训练中受到错误注意的锚点,在推理过程中会产生置信度高但定位不良的检测,压制一些定位准确但得分较低的锚点。这可能会混淆后处理步骤,因为在非最大抑制中,高分检测通常比低分检测具有更高的优先级,从而导致在严格的IoU阈值下AP得分较低。 - 问题二:所有金字塔层次上的特征选择
对于跨不同金字塔层级的相同空间位置的锚点,它们的关联特征是相似的,但是它们对网络损失的贡献程度是在没有仔细考虑的情况下决定的。当前的方法基于特定的探索式方法进行选择,例如实例对象尺度大小,并且通常限于每个实例对象在一个预测特征层上。这可能会浪费了一些性能更加的特征层。
这些问题促使作者提出了一种新的训练策略,采用了两种软化的优化技术,即软加权锚点(soft-weighted anchor points)和软选择金字塔层次(soft-selected pyramid levels)。
- soft-weighted anchor points
对于同一金字塔层次上的锚点,作者通过根据它们与实例对象的几何关系重新加权它们对网络损失的贡献来减少错误注意。作者认为,越靠近实例对象边界,锚点就越难因特征未对准而精确定位对象,它们对网络损耗的贡献就越小。 - soft-selected pyramid levels
作者通过其金字塔级别的实例依赖“参与”程度来重新加权锚点,进而实现了一个轻量级的特征选择网络来学习给定对象实例的每级“参与”程度。特征选择网络与检测器联合优化,不参与检测器推断。软特征选择是为单阶段无锚方法设计的,可以动态选择多个具有差异化的金字塔级别。
作者还提出,通过soft-weighting方法比FCOS提出的“center-ness”方法更加有效。之前在训练阶段做软加权的工作有:focal loss,consistent loss,这些方法重塑分类损失,但独立处理所有样本。而作者提出的soft-weighting方法更加直接与全面,重塑了分类和回归损失的组合,并考虑对分布在特征金字塔层级内部和之间的一组锚点进行联合加权。
最后的结果显示SAPD提高了FSAF模型的基准。其中,没有DCN结构的快速型优于最好的关键点检测器,DCN的精确变体形成了速度/精度折衷的上限。
2. Soft Anchor-Point Detector
2.1 Detection Formulation with Anchor Points
在最近的锚点检测器中,都或多或少的将带有额外卷积层的检测头附加到特征金字塔的多个级别。作者从网络架构、监管目标和损失函数方面介绍锚点检测器的一般概念。
2.1.1 Network architecture
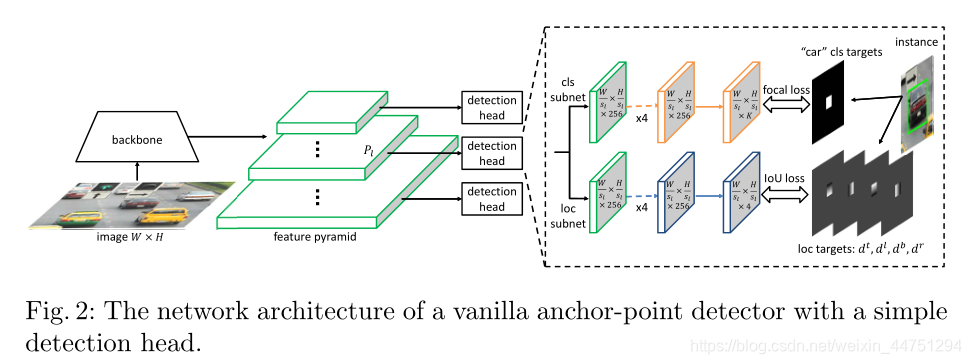
如图所示,锚点检测网络由主干、特征金字塔和每个金字塔预测特征层的一个检测头组成,采用完全卷积的方式。金字塔级别表示为 P l P_{l} Pl,其中 l l l表示级别编号,它的分辨率为输入图像大小 W × H W \times H W×H的 1 / s l 1/s_{l} 1/sl。其中, s l s_{l} sl是特征步幅, s l = 2 l s_{l} = 2^{l} sl=2l。 l l l的典型范围是3到7。
检测头有两个特定于任务的子网,即分类子网和定位子网。它们都有五个3x3 conv层。分类子网为K个对象类别中的每一个预测对象在每个锚点位置的概率。如果锚点位置概率是正的,则定位子网预测从每个锚点到附近实例对象边界的四个方向距离。
2.1.2 Supervision targets
首先定义锚点的概念。锚点 p l i j p_{l_{ij}} plij是预测特征层 P l P_{l} Pl上位于 ( i , j ) (i,j) (i,j)处的像素点,其中 i = 0 , 1 , … , W / s l − 1 i = 0,1,\dots,W/s_{l}-1 i=0,1,…,W/sl−1, j = 0 , 1 , … , H / s l − 1 j = 0,1,\dots,H/s_{l}-1 j=0,1,…,H/sl−1。对于每一个锚点(像素点) p l i j p_{l_{ij}} plij都具有对应的图像空间位置 ( X l i j , Y l i j ) (X_{l_{ij}},Y_{l_{ij}}) (Xlij,Ylij),其中 X l i j = s l ( i + 0.5 ) X_{l_{ij}} = s_{l}(i+0.5) Xlij=sl(i+0.5), Y l i j = s l ( j + 0.5 ) Y_{l_{ij}} = s_{l}(j+0.5) Ylij=sl(j+0.5)。接下来,定义ground-truth的实例对象框为 B = ( c , x , y , w , h ) B = (c,x,y,w,h) B=(c,x,y,w,h),其中 c c c是类id, ( x , y ) (x,y) (x,y)是盒子中心, w , h w,h w,h分别是盒子宽度和高度。定义 B v B_{v} Bv是 B B B的一个收缩边界盒, B v = ( c , x , y , ϵ w , ϵ h ) B_{v} = (c,x,y,\epsilon w,\epsilon h) Bv=(c,x,y,ϵw,ϵh),其中 ϵ \epsilon ϵ为收缩因子。当且仅当某个实例对象 B B B被分配预测特征层 P l P_{l} Pl,且像素点 p l i j p_{lij} plij的图像空间位置 ( X l i j , Y l i j ) (X_{l_{ij}},Y_{l_{ij}}) (Xlij,Ylij)在 B v B_{v} Bv的内部时,这个锚点 p l i j p_{lij} plij是正的,否则是负的。对于一个正的锚点,其分类目标为 c c c,定位目标计算为从锚点到实例对象框 B B B的左、上、右、下边界的归一化距离 d = ( d l , d t , d r , d b ) d = (d^{l},d^{t},d^{r},d^{b}) d=(dl,dt,dr,db),具体的计算公式为:
d l = 1 z s l [ X l i j − ( x − w / 2 ) ] d t = 1 z s l [ Y l i j − ( y − h / 2 ) ] d r = 1 z s l [ ( x + w / 2 ) − X l i j ] d b = 1 z s l [ ( y + h / 2 ) − Y l i j ] (1) \begin{aligned} d^{l} &= \frac{1}{zs_{l}}[X_{l_{ij}} - (x - w/2)] \\ d^{t} &= \frac{1}{zs_{l}}[Y_{l_{ij}} - (y - h/2)] \\ d^{r} &= \frac{1}{zs_{l}}[(x + w/2) - X_{l_{ij}}] \\ d^{b} &= \frac{1}{zs_{l}}[(y + h/2) - Y_{l_{ij}}] \tag{1} \end{aligned} dldtdrdb=zsl1[Xlij−(x−w/2)]=zsl1[Ylij−(y−h/2)]=zsl1[(x+w/2)−Xlij]=zsl1[(y+h/2)−Ylij](1)
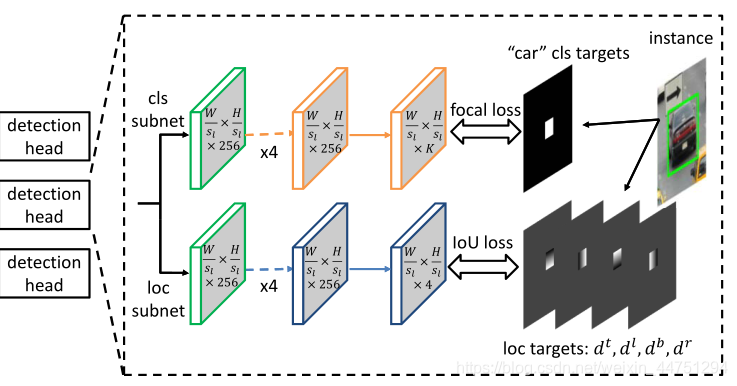
其中z是归一化标量。对于负锚点,其分类目标为背景(c = 0),定位目标设置为空,因为不需要学习。为此,为每一个锚点 p l i j p_{l_{ij}} plij都设置了一个分类目标 c l i j c_{l_{ij}} clij和一个定位目标 d l i j d_{l_{ij}} dlij,如图所示。
2.1.3 Loss functions
给定体系结构和锚点的定义,对于每个锚点 p l i j p_{l_{ij}} plij,网络生成一个K维分类输出 c ^ l i j \hat{c}_{l_{ij}} c^lij和一个4维定位输出 d ^ l i j \hat{d}_{l_{ij}} d^lij。分类子网的训练采用聚焦损失(focal loss),以克服正负锚点之间极端的类不平衡。IoU损失用于回归子网的训练。每个锚点损失 L l i j L_{l_{ij}} Llij计算公式为:
L l i j = { l F L ( c ^ l i j , c l i j ) + l I o U ( d ^ l i j , d l i j ) , p l i j ∈ p + l F L ( c ^ l i j , c l i j ) , p l i j ∈ p − (2) L_{l_{ij}} = \begin{cases} l_{FL}(\hat{c}_{l_{ij}},c_{l_{ij}}) + l_{IoU}(\hat{d}_{l_{ij}},d_{l_{ij}}),& \text{$p_{l_{ij}}∈p^{+}$}\\ l_{FL}(\hat{c}_{l_{ij}},c_{l_{ij}}),& \text{$p_{l_{ij}}∈p^{-}$} \tag{2} \end{cases} Llij={
lFL(c^lij,clij)+lIoU(d^lij,dlij),lFL(c^lij,clij),plij∈p+plij∈p−(2)
其中 p + p^{+} p+和 p − p^{-} p−分别是正锚点和负锚点的集合。
整个网络的损失是所有锚点损失的总和除以正锚点的数量,计算公式如下:
L = 1 N p + ∑ l ∑ i j L l i j (3) L = \frac{1}{N_{p^{+}}}\sum_{l}\sum_{ij}L_{l_{ij}} \tag{3} L=Np+1l∑ij∑Llij(3)
2.2 Soft-Weighted Anchor Points
2.2.1 False attention
在传统的训练策略下,作者观察到在推理过程中,一些锚点会生成定位不佳但置信度较高的检测框,从而抑制定位较精确但置信度较低的检测框。结果,非最大抑制(NMS)倾向于保持定位不良的检测,导致在严格的IoU阈值下的低AP,如图所示:

出现这个问题的原因是,在公式(3)中,传统的训练策略独立的对待每一个锚点,也就是这些锚点受到了同等的关注。但是,对于ground-truth的收缩盒 B v B_{v} Bv中的一组锚点来说,它们的空间位置和相关特征是不相同的,也就是说他们回归到ground-truth B B B的能力是不一样的。
作者认为,位于实例对象边界附近的锚点没有与实例对齐的特征。它们的特征往往会被实例对象之外的内容所伤害,因为它们的接受域包含了太多来自背景的信息,导致精确定位的表示能力下降。因为,位于实例对象中心点附近的锚点应该比位于实例对象边界上的锚点具有更强大的特征表示能力,所以更多的关注应该放在这些具有强大特征表示的锚点上,减少对其他的错误关注。而正是由于这个原因,作者提出了一个ground-truth的收缩盒子 B v B_{v} Bv。
这个思想,在FSAF中对预测特征层划分了三个区域:正样本区域(白色区域),忽略区域(灰色区域),负样本区域(黑色区域)的思想是类似的。我们关注的首要目标,应该是位于ground-truth中心点附近的锚点,也就是FASF中的白色区域。
2.2.2 Solution
解决上述问题的一个基本思想是为每个锚点的损失 L l i j L_{lij} Llij分配一个关注权重 w l i j w_{lij} wlij,对于每个正锚点,权重取决于其图像空间位置和相应实例对象边界之间的距离。越靠近边界,锚点的权重越低。如图所示:
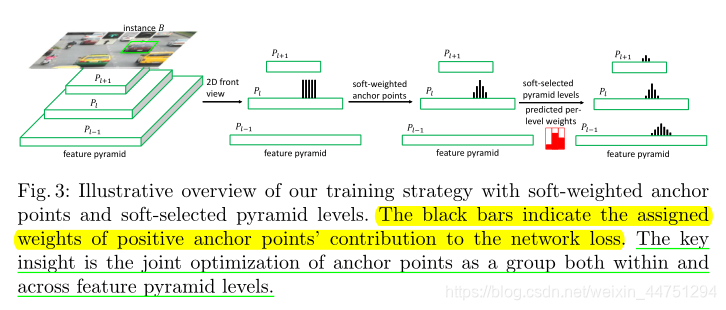
因此,靠近边界的锚点受到的关注较少,网络更多地关注中心周围的锚点。对于负锚点,它们保持传统的设置不变,因为它们不涉及定位回归问题,即它们的权重都设置为1。(因为与权重为1的相乘,数值保持不变)所以,关注权重 w l i j w_{lij} wlij可以定义为:
w l i j = { f ( p l i j , B ) , ∃ B , p l i j ∈ B v 1 , otherwise (4) w_{lij} = \begin{cases} f(p_{lij},B),& \text{$\exists B,p_{lij} \in B_{v}$} \\ 1,& \text{otherwise} \tag{4} \end{cases} wlij={
f(plij,B),1,∃B,plij∈Bvotherwise(4)
其中 f f f是反映离实例对象 B B B的边界有多近的函数。距离越近,注意力越低。作者使用中心函数的广义版本来实例化函数 f f f:
f ( p l i j , B ) = [ min ( d l i j l , d l i j r ) min ( d l i j t , d l i j b ) max ( d l i j l , d l i j r ) max ( d l i j t , d l i j b ) ] η f(p_{lij},B) = [\frac{\min(d^{l}_{lij},d^{r}_{lij})\min(d^{t}_{lij},d^{b}_{lij})}{\max(d^{l}_{lij},d^{r}_{lij})\max(d^{t}_{lij},d^{b}_{lij})}]^{\eta} f(plij,B)=[max(dlijl,dlijr)max(dlijt,dlijb)min(dlijl,dlijr)min(dlijt,dlijb)]η
其中 η η η控制着递减的陡度。
2.3 Soft-Selected Pyramid Levels
2.3.1 Feature selection
作者通过查看特征金字塔的属性来解决特征选择问题。不同金字塔级别的特征图彼此有些相似,尤其是相邻级别。如图所示:

事实证明,如果在某个区域激活了一个级别的特征,相邻级别的相同区域也可能以类似的样式激活,但是相似性随着层次的远离而减弱。这意味着来自多个金字塔级别的特征可以一起参与特定实例的检测,但是来自不同级别的参与程度应该有些不同。
基于以上分析,作者提出了特征层选择的两个原则:
1)选择应该与特征响应的模式相关,而不是一些特定的启发式。与实例相关的损失(instance-dependent loss)可以很好地反映金字塔级别是否适合检测某些实例。(FSAF中有类似想法)
2)应该允许来自预测特征层的特征图参与每个实例对象的训练和测试,并且每个预测特征层都应该做出不同的贡献。 FoveaBox中表面,将实例分配到多个要素级别可以在一定程度上提高性能。但是分配过多的级别反而会严重影响性能。
因此,解决方案在于为每个实例重新加权金字塔级别。换句话说,根据特征响应为每个金字塔级别分配一个权重,使选择变得柔和。这也可以看作是将实例的一部分分配给一个级别。
2.3.2 Solution
作者提议训练一个特征选择网络来预测软特征选择的权重,来解决决定每个金字塔等级的权重问题。
网络的输入是从所有金字塔层次提取的依赖于实例的特征响应。这是通过将RoIAlign层应用于每个金字塔特征,然后进行concat拼接来实现的,其中RoI是实例对象的ground-truth box。然后,提取的特征通过特征选择网络输出概率分布向量,使用概率作为软特征选择的权重。如图所示:
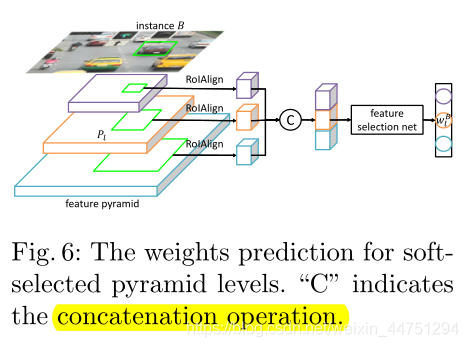
特征选择网络有多种架构设计。为了简单起见,我们给出了一个轻量级的实例化。它由三个没有填充的3 × 3 conv层和一个带有softmax的全连接层组成,每个层后面都有ReLU函数。完整结构如图表格所示:
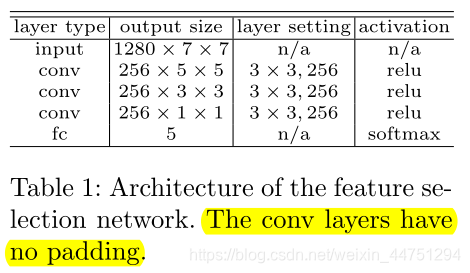
特征选择网络与检测器联合训练,其中使用交叉熵损失用于优化。最后的结果是一个独热编码向量,用来指示哪一层金字塔级别具有FSAF模块中定义的最小损失。可以看见,最后的全连接层输出大小为5,使用softmax就可以知道其中概率最大的那一层。
至此,每个实例对象 B B B通过特征选择网络与每层权重 w l B w^{B}_{l} wlB相关联。将每个实例对象 B B B分配给概率最高的 k k k个预测特征层,也就是top k个特征层级,在训练期间具有 k k k个最小的实例相关损失。等式(4)被扩充为:
w l i j = { w l B f ( p l i j , B ) , ∃ B , p l i j ∈ B v 1 , otherwise (5) w_{lij} = \begin{cases} w^{B}_{l}f(p_{lij},B),& \text{$\exists B,p_{lij} \in B_{v}$} \\ 1,& \text{otherwise} \tag{5} \end{cases} wlij={
wlBf(plij,B),1,∃B,plij∈Bvotherwise(5)
整个模型的总损失是锚点损失加上来自特征选择网络的分类损失(Lselecte-net)的加权和,定义如下:
L = 1 ∑ p l i j ∈ p + w l i j ∑ l i j w l i j L l i j + λ L s e l e c t e − n e t (6) L = \frac{1}{\sum_{p_{lij}\in p^{+}}w_{lij}}\sum_{lij}w_{lij}L_{lij} + \lambda L_{selecte-net} \tag{6} L=∑plij∈p+wlij1lij∑wlijLlij+λLselecte−net(6)
其中 λ λ λ是控制用于特征选择的分类损失比例的超参数。这里的 L s e l e c t e − n e t L_{selecte-net} Lselecte−net在文章中没有具体的说明,不过大致的意思可以理解。
3. Result
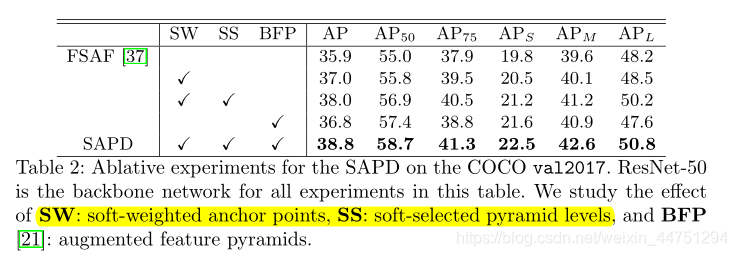
- 软加权与软选择的作用:
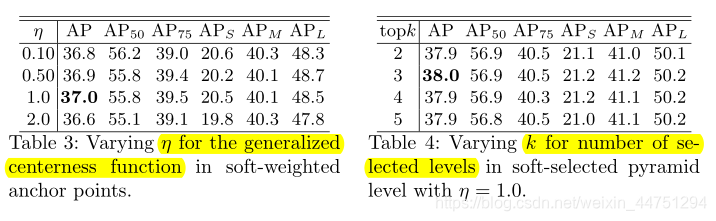
- 广义中心函数的 η η η与预测特征层数 k k k的选择所带来影响:
- backbone的选择:
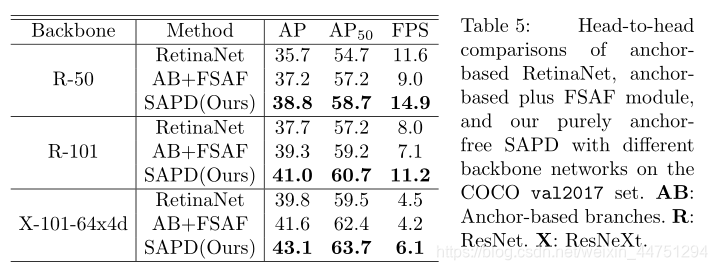
- 与SOTA的对比:
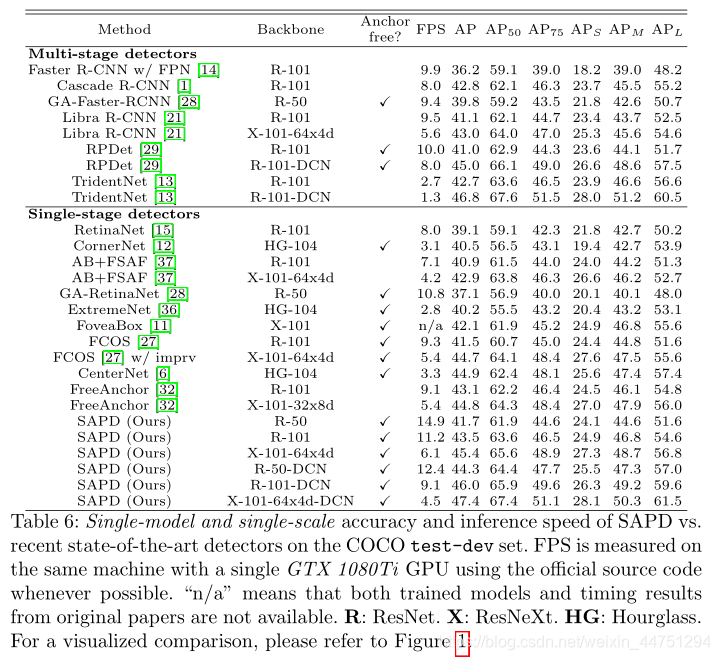
总结:
延续结合了FCOS的“center-ness”及FSAF的"online feature select"的思想,SAPD算法提出了软加权与软选择的改进版方法。相较于FCOS的“center-ness”,SAPD中直接按离实例对象的中心距离进行优化;而相较与FSAF的"online feature select",SAPD将软加权于此步相结合,融合了一个特征选择网络更进一步的利用交叉熵损失选择了top k个预测特征层进行联合使用。
基于这两点创新,SAPD算法首次实现将基于锚点检测的anchor-free算法在精度与速度均优于关键点检测算法。
附录:
关于FCOS与的FSAF介绍可以查看链接:
论文阅读笔记 | 目标检测算法——FCOS算法
论文阅读笔记 | 目标检测算法——FSAF算法