(一)三维视线估计
gaze estimation gaze tracking
4.1 目标
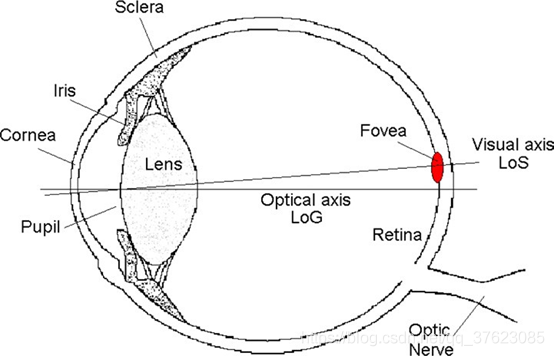
从眼睛图片或人脸图片中推导出人的视线方向,通常用pitch(垂直方向)和 yaw(水平方向)表示。
需要注意的是,在相机坐标系下,视线的方向不仅取决于眼睛的状态(眼珠位置,眼睛开合程度等),还取决于头部姿态(虽然眼睛相对头部是斜视,但在相机坐标系下,他看的是正前方)。
4.2 评价指标
在模型估计出 pitch 角和 yaw 角之后,可以计算出代表视线方向的三维向量,该向量与真实的方向向量(ground truth)之间的夹角即是 gaze 领域最常用的评价指标。
4.3 方法
1)基于几何的方法(Geometry Based Methods):检测眼睛的一些特征(例如眼角、瞳孔位置等关键点)并根据特征计算 gaze。
几何方法相对更准确,且对不同的 domain 表现稳定,然而这类方法对图片的质量和分辨率有很高的要求。

2)基于外观的方法(Appearance Based Methods):直接学习一个外观映射到 gaze 的模型。两类方法各有长短:
基于外观的方法对低分辨和高噪声的图像表现更好,但模型的训练需要大量数据,并且容易对 domain overfitting。
a)单/双眼视线估计
**[Appearance-based gaze estimation in the wild. In IEEE Conference on Computer Vision and Pattern Recognition ,CVPR2015]**提出并公开了 gaze 领域目前最常用的数据集之一:MPIIGaze。在 MPIIGaze 数据集上误差为 6.3 度。
https://www.cnblogs.com/kirito12138/p/11641085.html
1、人脸对齐与3D头部姿态判断:双眼的左右边界点与嘴巴的左边边界点共6个点,与人脸的基础3D模型对比,通过EPNP算法估计出人脸的3D旋转r,并将双眼标记点的中点,作为双眼的位置t。得到人脸的3D旋转估计与双眼位置
2、归一化:分别建立人脸坐标系与摄像机坐标系[https://blog.csdn.net/jiongjiongxia123/article/details/89153166]。主要通过透视变换,达到以下目标:
将摄像机视角从固定距离d正对双眼位置t;
将人脸坐标与摄像机坐标的x轴平行。
归一化后的到分辨率固定的眼部图像e与2维的头部转动角度向量h。这样的归一化将跨数据集测试变为可行。
3、使用CNN进行视线检测
**[MPIIGaze: Real-World Dataset and Deep Appearance-Based Gaze Estimation, TPAMI 2017]**在 MPIIGaze 数据集上误差为5.4 度
**[Appearance-based gaze estimation via evaluation- guided asymmetric regression, ECCV 2018]**基于双眼的非对称回归方法,充分利用双眼的互补信息 误差为5 度
b)基于语义信息的视线估计:使用额外的语义信息来帮助提升视线估计的精度。
**[Deep Pictorial Gaze Estimation. In European Conference on Computer Vision ,ECCV 2018]**基于眼睛图形表示的视线估计方法.误差为4.56 度
**[Deep multitask gaze estimation with a constrained landmark-gaze model,ECCVW 2018]**基于约束模型的视线估计方法 ,多任务学习的思想,即在估计 gaze 的同时检测眼睛关键点位置.
c)全脸视线估计
**[It’s Written All Over Your Face: Full-Face Appearance-Based Gaze Estimation,CVPRW 2018]**公开了全脸视线数据集 MPIIFaceGaze。该工作在 MPIIFaceGaze 数据集上取得了 4.8 度的精度。
https://www.cnblogs.com/kirito12138/p/11641085.html
**[Monocular free-head 3d gaze tracking with deep learning and geometry constraints ,ICCV 2017]**商汤提出了一个 gaze 的几何变换层,用于将 head pose(人脸支路学习得到)与人脸坐标系下的 gaze(眼睛支路学习得到)进行几何解析,得到最终相机坐标系下的 gaze。该工作在自己收集的数据集上取得了 4.3 度的误差。

d) 少量样本
[Unsupervised Representation Learning for Gaze Estimation, CVPR 2020],从无标签的数据中学习 gaze 表征。学习与真实值呈强线性关系的 gaze 表征。在实际使用时,仅需要极少量的标注样本(<=100),就可以得到有效可靠的视线估计模型。
4.4 三维视线估计(个性化问题)
大多数个性化估计方法都需要极少量的(<=9)个性化校准样本消除偏差:
1)差估计方法:
**[A differential approach for gaze estimation.2019]**差分网络。模型估计的不再是某一张图像的视线,而是两张图像的视线差值(pitch 角差值与 yaw 角差值)
**[Learning to personalize in appearance-based gaze tracking.2019]**为每一个人分配一个 6 维的参数向量作为校准参数。在训练过程中,校准参数与网络参数被共同学习优化。这样,视线的估计就被分为了两个部分,一个是与图像和视觉相关的分量,而另一个是与 ID 信息相关的分量。而在测试过程中,通过少量的校准样本(<=9)去学习校准参数(网络参数固定)。
2)模型微调方法:
**[Improving few-shot user-specific gaze adaptation via gaze redirection synthesis.2019]**使用校准样本对 person independent 模型进行 finetune(微调)。
4.5 头部姿态问题
1)基于特征拼接的方法
2)基于几何变换的方法
3)基于头部姿态隐式估计的方法_全脸视线估计方法
4.6 数据集
Eyediap 数据集 :利用深度摄像头标注 RGB 视频中的眼睛中心点位置和乒乓球位置。把这两个位置映射到深度摄像头记录的三维点云中,从而得到对应的三维位置坐标。这两个三维位置坐标相减后即得到视线方向。
MPIIGaze :利用 RGB 摄像头的公开参数,将 gaze 目标以及眼睛位置坐标(通过一个三维的 6 关键点模型得到)通过算法变换到相机坐标下,然后再计算 gaze 作为 ground truth。但是这种标注方法不仅操作复杂,而且并不准确。
MPIIGaze 与 MPIIFaceGaze 使用的是同一批数据,但并不是同一个数据集。MPIIGaze 数据集并不包含全脸图片;MPIIFaceGaze 的 ground truth 定义方式与 MPIIGaze 不同。

(二)注视点估计:
估算人双目视线聚焦的落点。其一般场景是估计人在一个二维平面上的注视点。这个二维平面可以是手机屏幕,pad 屏幕和电视屏幕等,而模型输入的图像则是这些设备的前置摄像头。
https://gazecapture.csail.mit.edu/
1)MIT:人脸主要提供头部姿态信息(head pose),而人脸位置主要提供眼睛位置信息。这里存在一定的信息冗余。
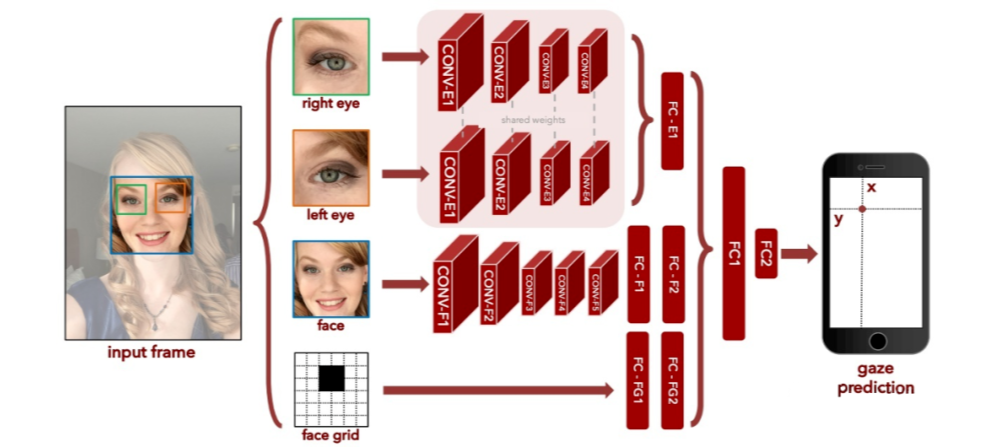
**[Eye Tracking for Everyone. CVPR 2016]**模型在 iPhone 上的误差是 1.71cm,在平板上的误差是 2.53cm;收集并公布了一个涵盖 1400 多人、240 多万样本的数据集,GazeCapture。
代码: https://github.com/CSAILVision/GazeCapture
数据集:https://gazecapture.csail.mit.edu/download.php
2)Google:将人脸和人脸位置这两个输入替换为四个眼角的位置坐标。眼角位置坐标不仅直接提供了眼睛位置信息,同时又暗含 head pose 信息(眼角间距越小,head pose越大,反之头部越正)。

[On-device few-shot personalization for real-time gaze estimation. ICCV 2019] 精简后的模型在 iPhone 上的误差为 1.78cm,在 Google Pixel 2 Phone 的处理速度达到 10ms/帧。
(三)眼球数据:
1)基于合成数据的方法
[1,2]使用计算机图形学的方法来合成眼睛样本。UnityEyes 数据集因其真实性及丰富的标签信息(关键点位置)已经是 gaze 领域十分重要的数据集。 [3] 中使用 UnityEyes 数据训练的简单的 k-NN 模型,可以在 MPIIGaze 上取得 9.95 度的精度。
[1] Rendering of Eyes for Eye-Shape Registration and Gaze Estimation. ICCV 2015
[2] Learning an appearance-based gaze estimator from one million synthesised images. ETRA 2016.
[3] Unsupervised Representation Learning for Gaze Estimation, CVPR 2020.
**[A hierarchical generative model for eye image synthesis and eye gaze estimation. CVPR 2018]**使用神经网络的方式来合成数据。图模型模块(HGSM)生成指定 gaze 数据相应的眼睛形状(由关键点表示),最后眼睛形状通过 GAN 合成眼睛图像。通过这种方式生成的眼睛图像自带 gaze 以及眼睛关键点这两个标签信息。使用该框架合成的数据来训练模型,可以在 MPIIGaze 真实数据集上取得 7.6 度的误差。
2) 基于Domain Adaptation的方法
SimGAN **[ Learning from simulated and unsupervised images through adversarial training, CVPR 2020]**通过一个 Refiner 网络将输入图像变换到另一个 domain 中。使用变换后的合成数据(UnityEyes)来训练模型,其在真实数据集上的误差可以缩小 3.4 度。
综述: https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/105400845