preliminary
#bootstrap sampling
#GCN(Random walk)
对于对称拉普拉斯中使用的度矩阵D的逆平方根,我的理解:
首先,直接用D的逆去乘邻接矩阵,肯定是可以的,就是做了行归一化。而原文中使用的D的逆平方根的话…实际算下来,可能是要让对称位置的值尽可能相似吧(至少分母上是完全一致的)。而作者给出的解释是:
dynamics get more interesting when we use a symmetric normalization
(动力学上更有趣???)
#概率统计(皮尔逊系数、显著性检验、置信区间)
#KNN
度量:
L0范数:向量中非0的元素的个数
L1范数:向量中各个元素绝对值之和(曼哈顿距离)
L2范数:欧式距离
#word2vec
#glove
#random walk
前言
低维的word embedding被用作“性别刻板印象(gender stereotypes)”的研究,比如:比起"she",“engineer"更加接近于"he”。该方法有两大问题:
- 【模型不足】这些word embedding方法大多基于共现信息训练,不完整
- 【评估不足】之前的测试的单词范围局限
本文的贡献:
- List item
word association
数据集
使用了SWOWEN数据集:首先创建一个cue池,对于每一个参加者,随机抽取cue池中的单词w1,参加者展开联想得w2,得到cue-response pair:w1-w2。如果w2不在cue池,则加入cue池。
经过预处理之后,得到12217cues,3665100responses(1个cue对应多个responses,多个responses还有可能是相同的单词),83863participants。
图的初始化
邻接矩阵:12217个nodes,1283047条边,边的权重=cue-response pair出现的次数。得到邻接矩阵 S ∈ R ∣ V ∣ × ∣ V ∣ S∈R^{|V|×|V|} S∈R∣V∣×∣V∣。对邻接矩阵做拉普拉斯对称归一化:
T = D − 1 / 2 S D − 1 / 2 T=D^{-1/2}SD^{-1/2} T=D−1/2SD−1/2
D = d i a g i ( ∑ j = 1 N S i j ) D=diag_i(\sum_{j=1}^{N}S_{ij}) D=diagi(j=1∑NSij)
特征矩阵:特征矩阵 P ∈ R ∣ V ∣ × 2 P∈R^{|V|×2} P∈R∣V∣×2, P ( i , ) = ( b m i , b f i ) P_{(i,)}=(b_{m_{i}}, b_{f_{i}}) P(i,)=(bmi,bfi),表示第i个单词分别带有的男性(masculine)和女性(feminine)的信息量。两两选择一些男性特征词-女性特征词的pair(如boy-girl),对男性特征词对应的向量置为(1,0),女性特征词对应所对应的向量置为(0,1),其它单词初始化为(0,0)。
图的迭代(stereotypes propagation)
P t + 1 = α T P t + ( 1 − α ) P 0 P_{t+1}=αTP_t+(1-α)P_0 Pt+1=αTPt+(1−α)P0
其中,α控制了初始信息和新信息的比例,没有迭代,直接根据 P t + 1 = P t P_{t+1}=P_t Pt+1=Pt近似求解:
P ∗ = ( 1 − α ) ( I − α T ) − 1 P 0 P^*=(1-α)(I-αT)^{-1}P_0 P∗=(1−α)(I−αT)−1P0
计算gender bias score(法1)
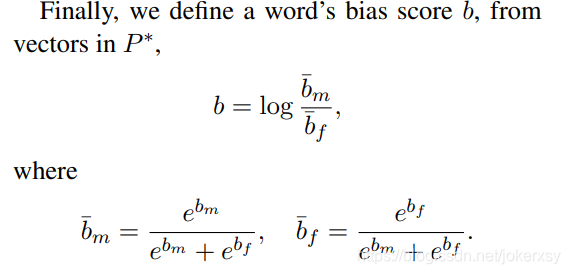
b就等于bm-bf?
下文还引用了两种不同的计算score的方法:

这两种方法(法2、法3)不仅仅是计算score的方式不同,它们采用的word embedding不是简单的(1,0)或(0,0),而是用了word2vec。
各种实验分析
与真实数据的比较
几种指标:
- γ(皮尔逊系数):-1到1之间,描述两个变量的线性关系
- p(显著性水平):?
- d(效应值):两个均值?(means)之间的标准化差异
使用了法2、法3、法1,进行了两个实验:
- score与census data 和 human judgements进行相关性分析
- 具有不同性别倾向的单词的score进行效应置分析
得到的结论:
- 法1更好
- census data(书面) 和 human judgements(人脑) 之间有很大差异
男女性特征词选择的影响
一个指标:
- 置信区间:要求一个单词bias score均值的置信区间。通过抽样,得到一组bias score,计算其样本方差、样本均值,构造一个满足标准正态分布的统计量(且包含总体均值),去求置信区间。
也计算了法1和census data 和 human judgements的皮尔逊系数的置信区间。
得到的结论:
- 男女性特征词的选择影响不大
stereotypes propagation变种的影响
变种一:采用random walk的变种
变种二:采用不同的α值
得到的结论:
- random walk算法的选择影响也不大
- α增大,皮尔逊系数稳定上升,趋向于1,效果最好
不同的图初始化策略的影响
假设本文“图的初始化”部分中为策略1,策略2、3如下:
使用word2vec的词向量,使用词的相似度作为图中边的度量:
- 策略2(local):对于每一个单词,连接k(105)个最相似的邻词。( G l o c a l G^{local} Glocal)
- 策略3(global):计算所有word pair的相似度,连接e(1235178)个最相似的。( G g l o b a l G^{global} Gglobal)
得到的结论:
- 使用别的图的初始化策略,效果很差
进一步探索为什么:
首先介绍了一种图,叫做small world graph,主要有三个性质:
- 图中任意两个结点之间的距离与log|V|成正比
- 图中结点的度满足幂律分布(绝大多数度掌握在少数结点手里)
- 图中的大部分结点都连接到了个别中心词,导致clustering coefficient很大
- 这种图的信息传播速度很快
而分析策略1、策略2和策略3,得到的结论:
- 所有策略的L(结点平均最短距离)、D(结点最长最短距离)的很小
- 所有策略clustering coefficient很大
- 策略1中,度很少的结点几乎没有(无头),且个别度特别大的结点(长尾),这和较小的L值,都可能导致了该策略信息的快速传播
策略1、2、3的图中体现出的不同特性的连边
主要有四种特性的连边:
- semantic priming:语义相似的单词,如:really-actually
- neighborhood effects:拼写、读音相似的单词
- frequency effects:一些中心词往往是很常见的词,而体现在本文提出的方法中,中心词往往带有很浓的性别特性,这是在策略23中所没有的。
- co-occurrence:共现,如:birth-day
结论:
- 策略1中这四种边都有
使用提出的方法作为benchmark,分析一些“de-bias”的方法的效果
主要的分析思路:首先引入两个de-bias的方法,分别是Hard-Debias(后处理)和Gn-Glove(训练),这两种方法应该都用了预训练的词向量,只知道后者用的是Glove。
由于是使用了pretrained word embedding,所以采用了"计算gender bias score(法1)"中的法2、法3,来计算的bias score。分别计算两个de-bias的方法使用前后,得到的bias score,和本文提出的方法得到的bias score的皮尔逊系数。
如果:
- 使用前很相关,使用后不相关,则de-bias方法好
- 使用前很相关,使用后依然很相关,则de-bias方法差
得到的结论:
- Hard-Debias > Gn-Glove