六、与学习相关的技巧
参数的更新
最优化(optimization):寻找最优参数(使损失函数值尽可能小)的问题。
1.SGD
随机梯度下降法(Stochastic Gradient Descent):沿梯度方向更新参数,并重复这个步骤多次从而逐渐靠近最优参数。
W ← W − η ∂ L ∂ W W←W-\eta\frac{\partial L}{\partial W} W←W−η∂W∂L
class GCD:
def __init__(self,lr=0.01):
self.lr=lr
def update(self,params,,grads):
for key in params.keys():
params[key]-=self.lr * grads[key]
network=TwoLayerNet(...)
optimizer=SGD()
for i in range(10000):
...
x_batch,t_batch=get_mini_batch(...)
grads=network.gradient(x_batch,t_batch)
params=network.params
optimizer.update(params,grads)
但是我们之前提到过,SGD不一定会指向最小值处。
缺点:
- 选择适当的学习率困难,若选择太小,收敛速度会很慢;若选择太大,则损失函数的值将在极小值附近震荡,甚至偏离。
- 高度非凸的损失函数中,如何避免陷入局部次优解、被困在鞍点。
- 当梯度不均匀时,参数移动路径易出现“之”字形移动现象,学习效率低下。

f ( x , y ) = 1 20 x 2 + y 2 f(x,y)=\frac{1}{20}x^2+y^2 f(x,y)=201x2+y2 的形状非均向(向x轴方向延伸的"碗状"函数,y轴方向坡度大,x轴小,梯度在很多地方并没有指向最小值 (0,0) 处),SGD的搜索路径就会非常低效。
2.Momentum
Momentum即动量,新变量 v v v 表示在梯度方向受力,在这个力的作用下,物体的速度逐渐增大。可以更快的朝x轴方向靠近,减弱“之”字形的变动程度。
v ← α v − η ∂ L ∂ W v←\alpha v-\eta\frac{\partial L}{\partial W} v←αv−η∂W∂L
W ← W + v W←W+v W←W+v
另一种表达:

相较于SGD优化器,增加了 α v \alpha v αv项,积累了之前梯度指数级衰减的平均。
优点:若当前时刻的梯度与历史时刻梯度方向相似,参数更新趋势则会在当前时刻加强;若相反,则会削弱参数当前的更新趋势。

虽然x轴方向上受到的力非常小,但是一直在同一方向上受力,所以朝同一个方向会有一定的加速;反过来,虽然y轴方向上收到的力很大,但是交互的受到正方向和反方向的力,它们会相互抵消,所以y轴方向上的速度不稳定。因此和SGD相比可以更快地朝x轴方向靠近,减弱“之”字形的变动程度。
# Momentum SGD
class Momentum:
def __init__(self,lr=0.01,momentum=0.9):
self.lr=lr
self.momentum=momentum
self.v=None
def update(self,params,grads):
if self.v is None:
self.v={
}
for key, val in params.items():
self.v[key]=np.zeros_like(val)
# 第一次调用update,v会以字典型变量的形式保存与参数结构相同的数据
for key in params.keys():
self.v[key]=self.momentum*self.v[key] - self.lr*grads[key]
params[key]+=self.v[key]
3.AdaGrad(Adaptive Gradient)
h ← h + ∂ L ∂ W ∗ ∂ L ∂ W ( 矩 阵 乘 法 ) h←h+\frac{\partial L}{\partial W}*\frac{\partial L}{\partial W}\ \ (矩阵乘法) h←h+∂W∂L∗∂W∂L (矩阵乘法)
W ← W − η 1 h ∂ L ∂ W W←W-\eta \frac{1}{\sqrt{h}}\frac{\partial L}{\partial W} W←W−ηh1∂W∂L
另一种表达:



class AdaGrad:
def __init__(self,lr=0.01):
self.lr=lr
self.h=None
def update(self,params,grads):
if self.h is None:
self.h={
}
for key,val in params.items():
self.h[key]=np.zeros_like(val)
for key in params.keys():
self.h[key]+=grads[key]*grads[key]
params[key]-=self.lr*grads[key]/(np.sqrt(self.h[key])+1e-7)
4.Adam
A d a m = M o m e n t u m + A d a G r a d Adam=Momentum+AdaGrad Adam=Momentum+AdaGrad

class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self,lr=0.001,beta1=0.9,beta2=0.999):
self.lr=lr
self.beta1=beta1
self.beta2=beta2
self.iter=0
self.m=None
self.v=None
def update(self,params,grads):
if self.m is None:
self.m,self.v={
},{
}
for key, val in params.items():
self.m[key]=np.zeros_like(val)
self.v[key]=np.zeros_like(val)
self.iter+=1
lr_t=self.lr*np.sqrt(1.0-self.beta2**self.iter)/(1.0-self.beta1**self.iter)
for key in params.keys():
#self.m[key]=self.beta1*self.m[key]+(1-self.beta1)*grads[key]
#self.v[key]=self.beta2*self.v[key]+(1-self.beta2)*(grads[key]**2)
self.m[key]+=(1-self.beta1)*(grads[key]-self.m[key])
self.v[key]+=(1-self.beta2)*(grads[key]**2-self.v[key])
params[key]-=lr_t*self.m[key]/(np.sqrt(self.v[key])+1e-7)
#unbias_m+=(1-self.beta1)*(grads[key]-self.m[key]) # correct bias
#unbisa_b+=(1-self.beta2)*(grads[key]*grads[key]-self.v[key]) # correct bias
#params[key]+=self.lr*unbias_m/(np.sqrt(unbisa_b)+1e-7)
权重的初始值
Batch Normalization
强制调整激活值分度的广度
优点:
1.可以增加学习率,使学习快速进行
2.不那么依赖初始化值
3.抑制过拟合
正则化
超参数的验证
详见博客
七、卷积神经网络

全连接:相邻层所有神经元之间都有连接,输出数量可以任意决定,Affine层实现了全连接。
全连接层存在的问题:数据的形状被忽视了。输入数据是图像时,图像通常是高、常、通道方向的三维形状。但全连接层输入时,需要将三维数据拉平为一维数据。
图像的三维形状中会含有重要的空间信息,eg.空间上邻近的像素为相似的值、RGB的各个通道间分别有紧密的关联性、相距较远的像素间没有什么关联。
卷积层
在卷积神经网络(CNN)中,卷积层的输入输出数据称为特征图。对应的,卷积层的输入数据称为输入特征图,输出数据称为输出特征图。
相较于全连接神经网络,卷积神经网络有两个比较大的特点:
(1)卷积网络有至少一个卷积层,用来提取特征。
(2)卷积网络的卷积层通过权值共享的方式进行工作,大大减少权值的数量,使得在训练中在达到同样识别率的情况下收敛速度明显快于全连接网络。
卷积运算
卷积运算:随着窗口的滑动,滤波器对输入图像进行取样,或者称为特征提取的过程。

将各个位置上滤波器元素和输入的对应元素相乘,然后求和,将结果保存在对应输出位置。(乘积累加运算)
填充:向输入数据周围填入固定数据(例如0)。主要是为了调整输出的大小,如果只是一味的缩小空间,会导致某个时刻输出大小为1,无法再进行卷积运算。

填充可以使得卷积运算在保持空间大小不变的情况下将数据传给下一层。
步幅:应用滤波器的位置间隔。

增大步幅后,输出大小会变小。而增大填充后,输出大小会变大。
设输出大小为(H,W),滤波器大小为(FH,FW),输出大小为(OH,OW),填充为P,步幅为S,此时输出大小计算公式:
O H = H + 2 P − F H S + 1 OH=\frac{H+2P-FH}{S}+1 OH=SH+2P−FH+1
O W = W + 2 P − F W S + 1 OW=\frac{W+2P-FW}{S}+1 OW=SW+2P−FW+1
注意:设定的值要能够除尽,输出大小无法除尽是,需要报错。深度学习框架不同,处理方式不同,有的也会采取向最近整数四舍五入。
eg.输入大小 (4,4),填充: 1,步幅: 1;滤波器大小 (3,3)
O H = 4 + 2 ∗ 1 − 3 1 + 1 = 4 OH=\frac{4+2*1-3}{1}+1=4 OH=14+2∗1−3+1=4
O W = 4 + 2 ∗ 1 − 3 1 + 1 = 4 OW=\frac{4+2*1-3}{1}+1=4 OW=14+2∗1−3+1=4
三维数据的卷积运算
图像是3维数据,除了高、长方向之外,还需要处理通道方向。当通道方向上有多个特征图时,会按通道进行输入数据和滤波器的卷积运算,并将结果相加,最后加上偏置,从而得到输出。
例如,处理三维彩色RGB图像时,其包含有R、G、B三个通道,每个通道都需要对应一个滤波器,经过卷积运算后结果对应相加,再加上偏置信项,最终输出一个通道的特征图。若想要输入n个通道的特征图,则需要n组类似结构。

需要注意的是输入数据和滤波器的通道数要是相同的值,滤波器的大小可以设定为任意值,但是各通道的滤波器大小要全部相同。

C是通道数,FN是滤波器个数,以下为基于多个滤波器的卷积运算例子:

批处理
神经网络的处理中进行了将输入数据打包的批处理。通过批处理,能够实现处理的高效化和学习时对mini-batch的对应。

池化层 (非必需)
池化:缩小高、长方向上的空间运算。
池化层常用的数据处理有两种:
- Max池化:计算目标区域的最大值。
- Average池化:计算目标区域的平均值。

一般池化的窗口和步幅会设定成相同的值,图像识别领域主要使用max池化。
池化层的特征:
- 没有要学习的参数
池化层和卷积层不同,没有要学习的参数。池化只是从目标区域中取最大值(或者平均值),所以不存在要学习的参数。 - 通道数不发生变化
经过池化运算,输入数据和输出数据的通道数不会发生变化,计算是按通道独立进行的。

- 对微小的位置变化具有鲁棒性(健壮)
输入数据发生微小偏差时,池化仍会返回相同的结果。因此,池化对输入数据的微小偏差具有鲁棒性。

池化层的功能:
- 它又进行了一次特征提取,能够减小下一层数据处理量。
- 由于这个特征的提取,能够有更大的可能性进一步获取更为抽象的信息,从而
防止过拟合,或者说提高一定的泛化性。 - 对输入数据的变化有鲁棒性,体现在图形的少量平移、旋转以及放等变化。
卷积层和池化层的实现
CNN中各层传递的数据是4维数据,eg.(10,1,28,28)表示10个高为28、长为28、通道数为1的数据。
import numpy as np
x=np.random.rand(10,1,28,28)
print(x.shape) # (10, 1, 28, 28)
print(x[0].shape) # 第一个数据的形状 (1, 28, 28)
print(x[1].shape) # 第二个数据的形状 (1, 28, 28)
print(x[9].shape) # 第十个数据的形状 (1, 28, 28)
基于im2col的展开

- input_data : 由(数据量, 通道, 高, 长)的4维数组构成的输入数据
- filter_h : 滤波器的高
- filter_w : 滤波器的长
- stride : 步幅
- pad : 填充
def im2col(input_data,filter_h,filter_w,stride=1,pad=0):
N,C,H,W=input_data.shape
out_h=(H+2*pad-filter_h)//stride + 1
out_w=(W+2*pad-filter_w)//stride + 1
img=np.pad(input_data,[(0,0),(0,0),(pad,pad),(pad,pad)],'constant')
col=np.zeros((N,C,filter_h,filter_w,out_h,out_w))
for y in range(filter_h):
y_max=y+stride*out_h
for x in range(filter_w):
x_max=x+stride*out_w
col[:,:,y,x,:,:]=img[:,:,y:y_max:stride,x:x_max:stride]
col=col.transpose(0,4,5,1,2,3).reshape(N*out_h*out_w,-1)
return col # 二维数组
卷积层的实现
class Convolution:
def __init__(self,W,b,stride=1,pad=0):
self.W=W
self.b=b
self.stride=stride
self.pad=pad
# 中间数据(backward时使用)
self.x=None
self.col=None
self.col_W=None
# 权重和偏置参数的梯度
self.dW=None
self.db=None
def forward(self, x):
FN,C,FH,FW=self.W.shape
N,C,H,W=x.shape
out_h=1+int((H+2*self.pad-FH)/self.stride)
out_w=1+int((W+2*self.pad-FW)/self.stride)
# 展开输入数据,并用reshape将滤波器展开成二维数组,再矩阵相乘
col=im2col(x,FH,FW,self.stride,self.pad)
col_W=self.W.reshape(FN,-1).T # 自动计算-1维上的元素个数
out=np.dot(col,col_W)+self.b
out=out.reshape(N,out_h,out_w,-1).transpose(0,3,1,2)
# transpose可以更改多维数据轴的位置
self.x=x
self.col=col
self.col_W=col_W
return out
def backward(self,dout):
FN,C,FH,FW=self.W.shape
dout=dout.transpose(0,2,3,1).reshape(-1,FN)
self.db=np.sum(dout, axis=0)
self.dW=np.dot(self.col.T, dout)
self.dW=self.dW.transpose(1, 0).reshape(FN, C, FH, FW)
dcol=np.dot(dout, self.col_W.T)
dx=col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
return dx
反向传播和Affine的操作一样,但是注意在进行反向传播的时候,要进行im2col的逆处理。
def col2im(col,input_shape,filter_h,filter_w,stride=1,pad=0):
N, C, H, W = input_shape
out_h = (H + 2*pad - filter_h)//stride + 1
out_w = (W + 2*pad - filter_w)//stride + 1
col = col.reshape(N, out_h, out_w, C, filter_h, filter_w).transpose(0, 3, 4, 5, 1, 2)
img = np.zeros((N, C, H + 2*pad + stride - 1, W + 2*pad + stride - 1))
for y in range(filter_h):
y_max=y+stride*out_h
for x in range(filter_w):
x_max = x + stride*out_w
img[:, :,y:y_max:stride,x:x_max:stride]+=col[:, :, y, x, :, :]
return img[:,:,pad:H+pad,pad:W+pad]
池化层的实现


像这样展开之后,只需对展开的矩阵求各行的最大值,并转换为合适的形状即可。
class Pooling:
def __init__(self,pool_h,pool_w,stride=1,pad=0):
self.pool_h=pool_h
self.pool_w=pool_w
self.stride=stride
self.pad=pad
self.x=None
self.arg_max=None
def forward(self,x):
N,C,H,W=x.shape
out_h=int(1+(H-self.pool_h)/self.stride)
out_w=int(1+(W-self.pool_w)/self.stride)
# 展开
col=im2col(x,self.pool_h,self.pool_w,self.stride,self.pad)
col=col.reshape(-1,self.pool_h*self.pool_w)
# 取max
arg_max=np.argmax(col,axis=1)
out=np.max(col,axis=1) # 再输入的第一维的各个轴方向上取最大值
# 转换
out=out.reshape(N,out_h,out_w,C).transpose(0,3,1,2)
self.x=x
self.arg_max=arg_max
return out
def backward(self,dout):
dout=dout.transpose(0,2,3,1)
pool_size=self.pool_h*self.pool_w
dmax=np.zeros((dout.size,pool_size))
dmax[np.arange(self.arg_max.size),self.arg_max.flatten()]=dout.flatten()
dmax=dmax.reshape(dout.shape+(pool_size,))
dcol=dmax.reshape(dmax.shape[0]*dmax.shape[1]*dmax.shape[2],-1)
dx=col2im(dcol,self.x.shape,self.pool_h,self.pool_w,self.stride,self.pad)
return dx
反向传播层可以参考ReLU层中实现的取max的反向传播过程。
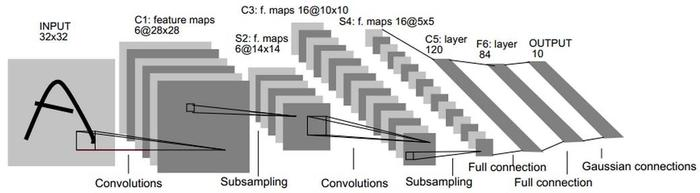
LeNet
1998年最早被提出的CNN,是进行手写数字识别的神经网络,有卷积层和池化层(抽选元素的子采样层),最后通过全连接层输出结果。激活函数使用sigmoid函数,使用subsampling来缩小中间数据的大小(现在的CNN中常用max池化)。
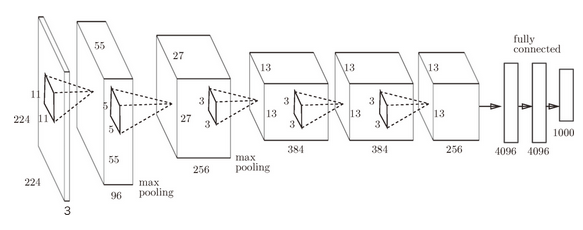
AlexNet
2012年提出的AlexNet和LeNet在网络结构上几乎差不多,但是在以下细节上有所区别:
- 激活函数使用ReLU
- 使用进行局部正规化的LRN层(Local Response Normalization)
- 使用Dropout
擅长大规模并行计算的GPU的应用以及大数据推动了CNN的发展。
八、深度学习
加深了层的网络可以用更少的参数达到同等水平(或者更强)的表现力。

通过加深层,可以减少学习数据,从而高效地进行学习。通过加深网络,就可以分层次地分解需要学习的问题。
深度学习历史
ImageNet
ImageNet 是一个计算机视觉系统识别项目, 是目前世界上图像识别最大的数据库。
VGG
GoogLeNet
ResNet
快捷结构:跳过了输入数据的卷积层,将输入x合计到输出中。
