plotly绘图基础篇
手动反爬虫,禁止转载:原博地址 https://blog.csdn.net/lys_828/article/details/119516045(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 Plotly简介与安装
第一章通过Matplotlib绘制的图形基本上都是静态的图片或者由静态的图片组成的动态图,缺失一些使用者的交互体验,而Plotly是图形可视化的 Python 包,它提供了一种高度交互式界面,便于大家做出各种有吸引力的统计图表
安装的方式和之前Matplotlib安装的方式一致,由于这个包不是Anaconda自带的包,需要通过命令行进行安装,安装结果如下(如果已经安装成功,再执行红框的的语句,就会显示条件已经满足的提示)

2 Plotly简单绘图入门
这一部分对比Matplotlib绘图的区别,以及介绍绘图的逻辑步骤。直接通过代码输出的结果进行查看两者的直观感受
通过Matplotlib绘图:
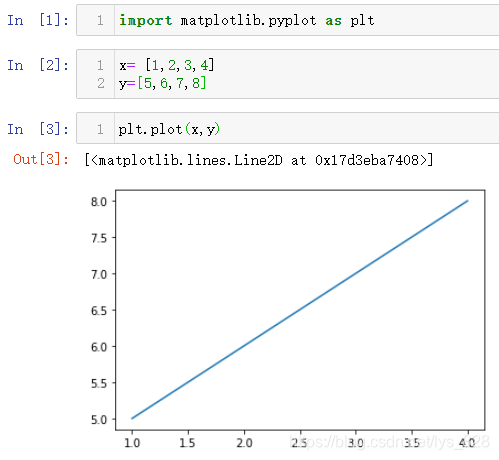
通过plotly绘制图形:(红框的代码在绘图之前作为默认模块进行载入即可,由于是交互式的图像,需要进行请求一些js内容以及初始化设置,绘图的模式会分为内嵌交互模式iplot()和网页交互模式plot())
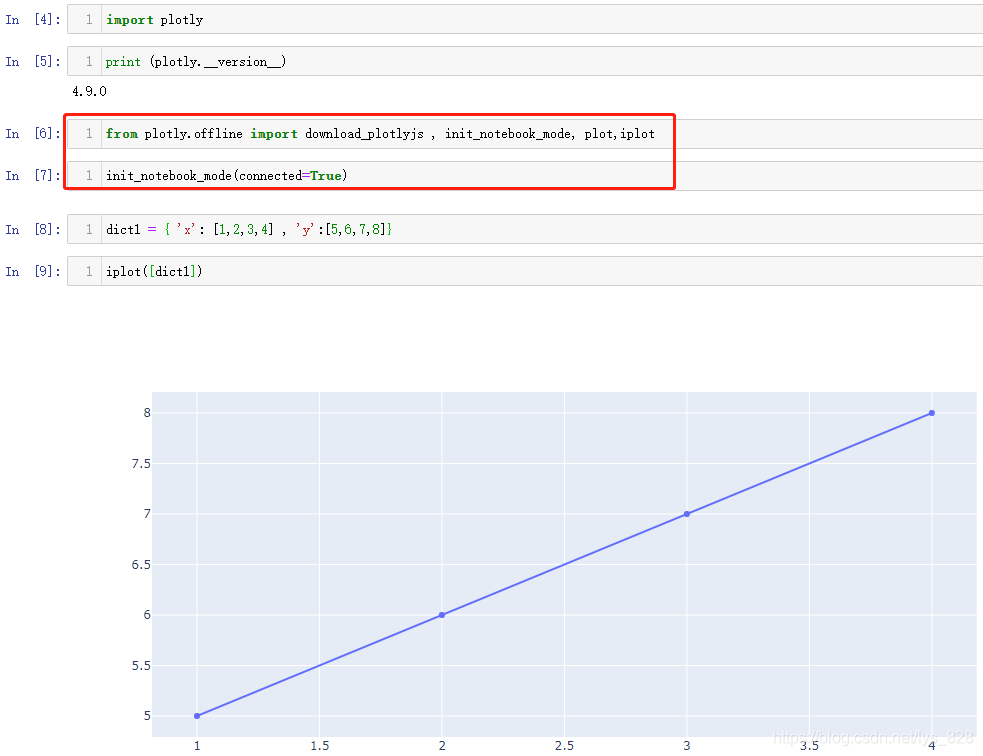
对比上方两个图像,使用Matplotlib绘图的过程很干脆简洁,直接给定两个列表,然后plt.plot()图像就绘制出来了。而Plotly绘图需要先加载一下js的内容和进行初始化配置以及导入出图的模式,然后才是给定数据且这个数据是字典数据类型,最后再放入中括号中进行iplot()或者plot()绘图显示
iplot()绘制的结果是内嵌在notebook中的图像,如果网络波动不稳定会需要加载一会后才显示。而且重新打开notebook文件后,原来执行过的iplot()操作绘制的图形都需要重新运行一次才会再显示,否则就是空白(使用Matplotlib绘图重新打开notebook文件后代码不需要重新运行,图片依然在文件中显示)
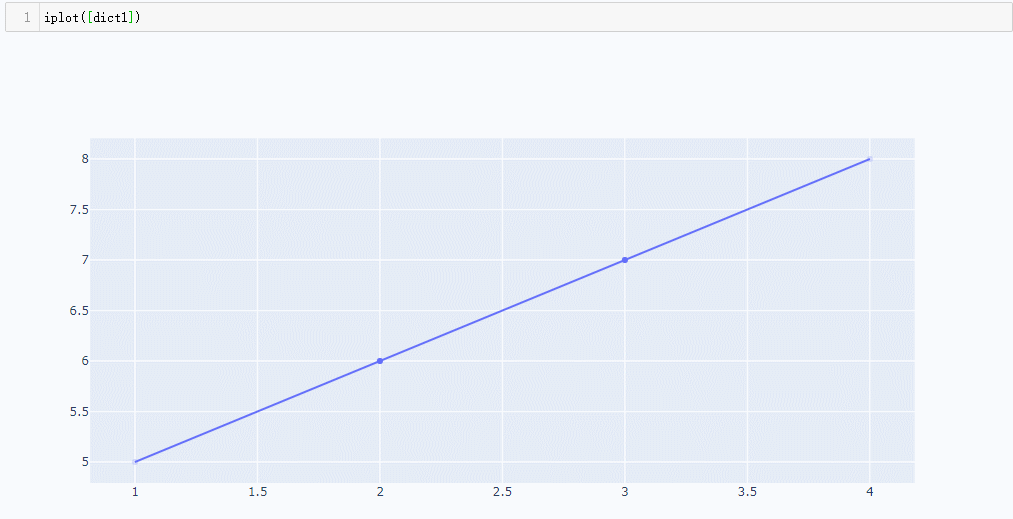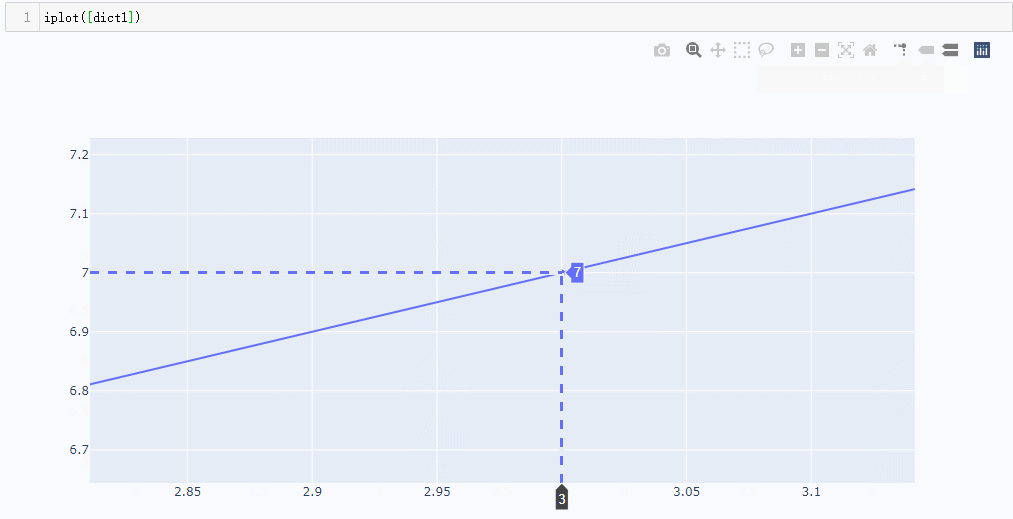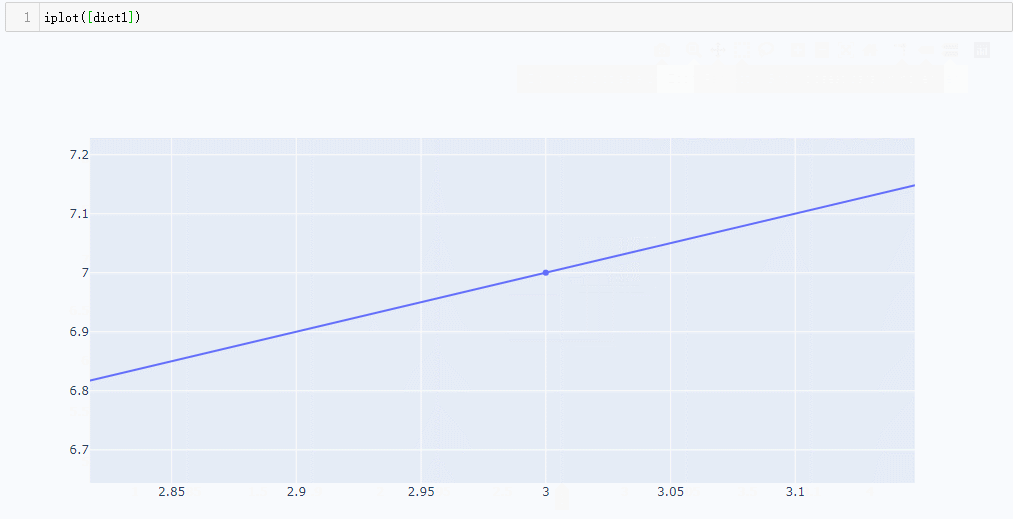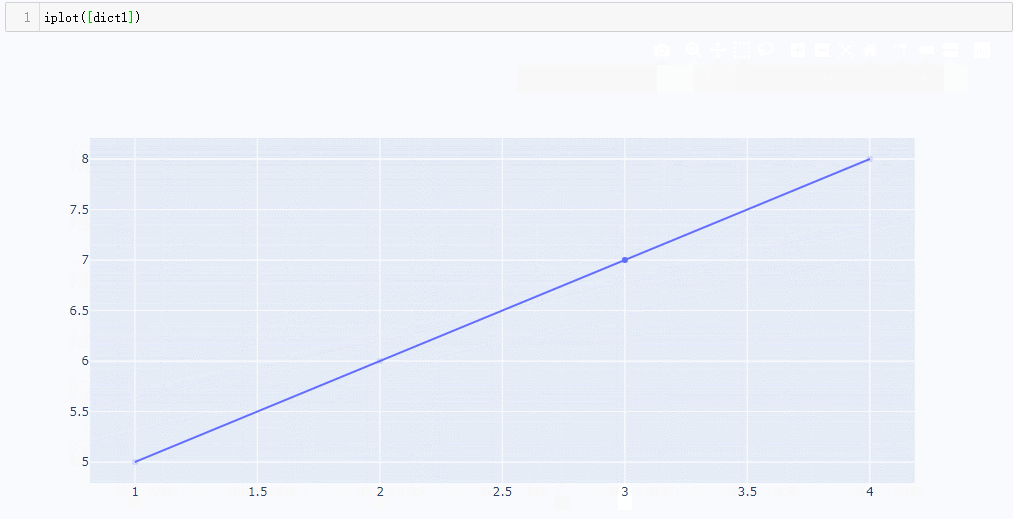
使用plot()方法出图,属于网页交互模式绘制图像,会自动生成一个html网页,并且执行这行代码后会自动打开生成的这个html网页
生成的网页图像如下(该网页默认就是和执行代码的这个文件属于同路径下,而且由于是离线的网页,所以生成之后就可以永久查看,即便是没有网络,图片中的信息依据可以正常加载,这也是区别在线模式的地方)
观察Plotly绘图的过程,无论是iplot()还是plot()方法,最终传入的数据类型都是中括号中包含字典的方式,中括号的输入不是很麻烦,但是中间字典数据的转化就存在一定的问题,列表转字典如果手动操作的话还是有点麻烦甚至不适应,为了仿照Matplotlib绘图模式,Plotly中提供了一个构造器帮我们完成,代码指令为:import plotly.graph_objs as go,将绘制所需要的数据放置在这个构造器再放在中括号中即可
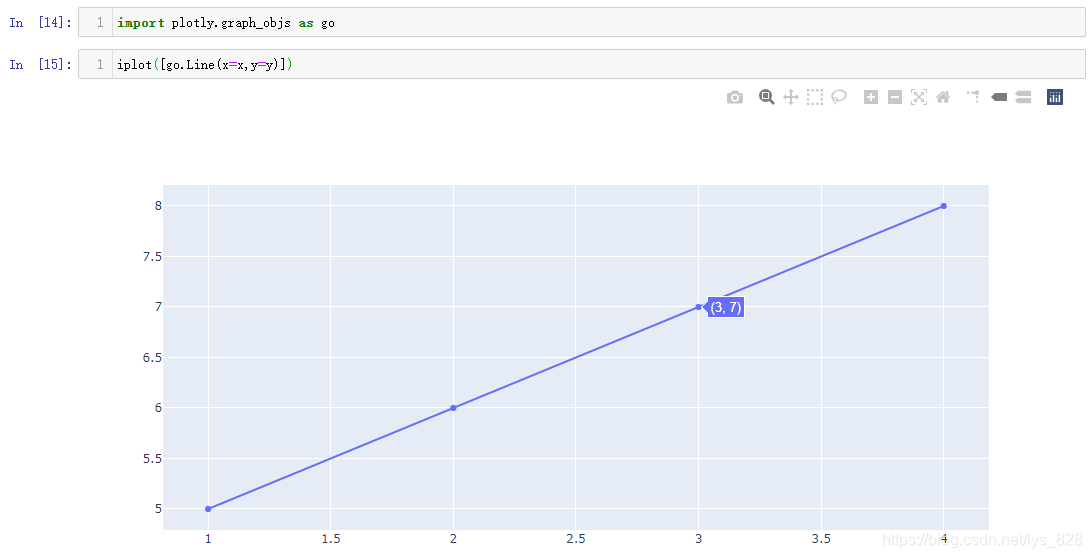
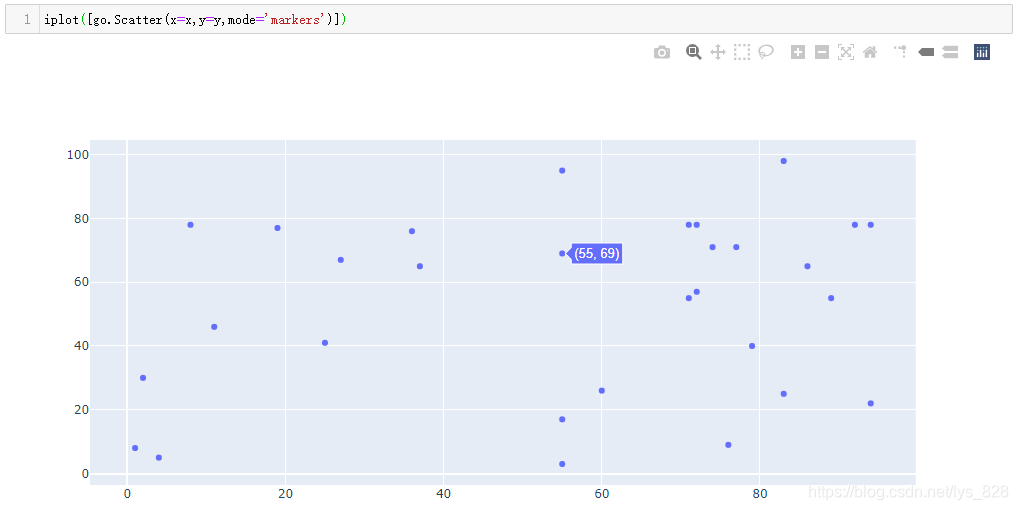
比如使用此方法再绘制一个散点图

输出结果为:(mode = 'markers'表示散点图中没有线条,否则默认不指定就是绘制直线了)
以上就是关于Plotly绘制图形的两种方式,一种直接给定字典样式数据,另一种通过加载go构造器的方式进行自动转化,后者会在之后的绘图中频繁用到,这样符合绘图的习惯
3 Plotly绘制散点图和饼图
上一部分介绍了Plotly绘制图形的过程,这里归纳概括为五个步骤:
- (1)创建数据
- (2)把数据放入
go对象 - (3)创建一个
trace变量存放go对象 - (4)用
fig变量产生一个列表,可以存放超过一个以上的go对象( 可选 ) - (5)
iplot进行绘制(如果网络不稳定可以使用plot)
严格按照归纳的五个步骤进行散点图的绘制,并加上部分绘图的参数,代码如下
import plotly.graph_objs as go
from plotly.offline import download_plotlyjs , init_notebook_mode ,plot ,iplot
init_notebook_mode(connected=True)
import numpy as np
#第一步:创建数据
n = 1000
x= np.random.randn(n)
y= np.random.randn(n)
#第二步:把数据放入go对象
go.Scatter(x=x ,y=y,mode='markers',marker=dict(color='red',size=8))
#第三步:创建一个data变量存放go对象
trace = go.Scatter(x=x ,y=y,mode='markers',marker=dict(color='red',size=8))
fig = [trace]
#第四五步:将fig放在列表中进行iplot绘制
iplot(fig)
输出结果如下:(要添加绘图参数的设置是在第二步,除了数据放入go对象中,相关的绘图参数也要放在里面)

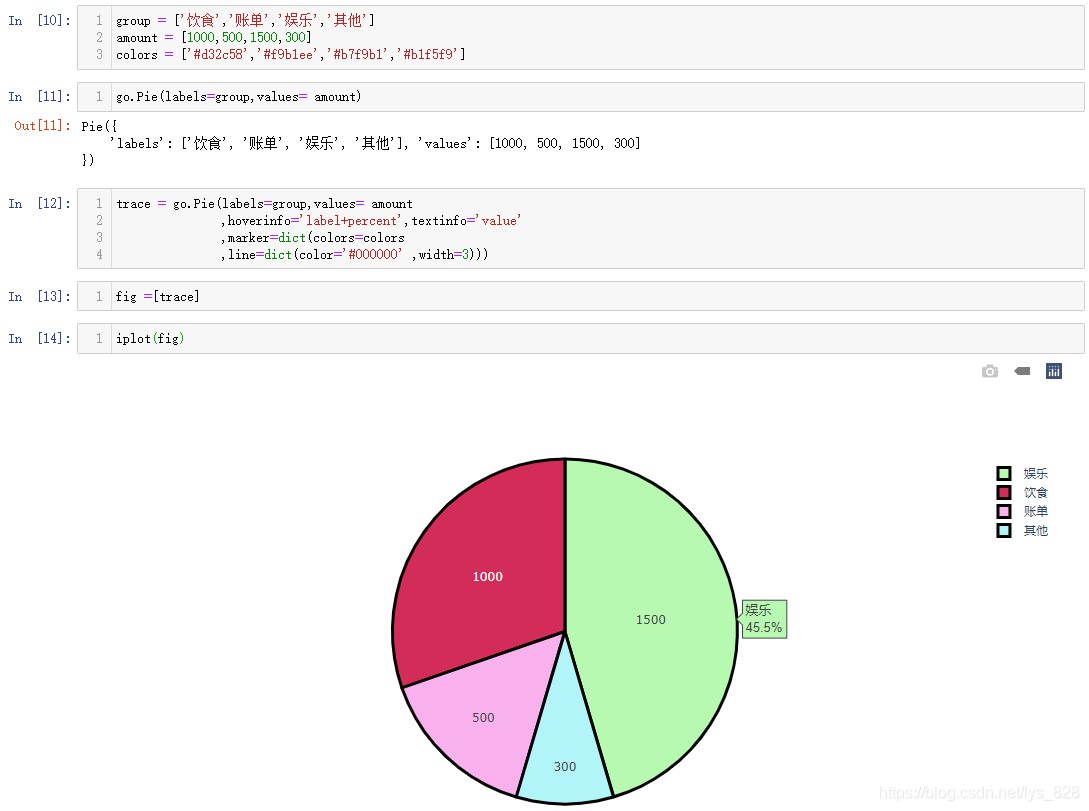
同理绘制饼图,测试数据不再使用随机数生成,而是自己指定一个简单的数据,具体的代码如下
#第一步:创建数据
group = ['饮食','账单','娱乐','其他']
amount = [1000,500,1500,300]
colors = ['#d32c58','#f9b1ee','#b7f9b1','#b1f5f9']
#第二步:把数据放入go对象
go.Pie(labels=group,values= amount)
#第三步:创建一个data变量存放go对象
trace = go.Pie(labels=group,values= amount
,hoverinfo='label+percent',textinfo='value'
,marker=dict(colors=colors
,line=dict(color='#000000' ,width=3)))
#第四步:将变量放在列表中
fig =[trace]
#第五步:直接把fig传递到iplot函数汇总
iplot(fig)
输出结果如下:(第四五步为啥归纳的时候要分开,其实就是为了强调在传入参数的时候不要忘记了中括号。在绘制饼图时候有两个参数是之前没有接触到的,因为是交互式图形,会有鼠标放置时候的信息显示,因此hoverinfo参数就是控制鼠标悬停时显示的内容,比如这里只显示标签和百分比信息,还有一个扇形内部的文本标记可以使用textinfo参数控制,这里指定的就是显示数据值。其它的参数设置在之前的Matplotlib绘图中都有介绍)
4 Plotly绘图流程详细梳理
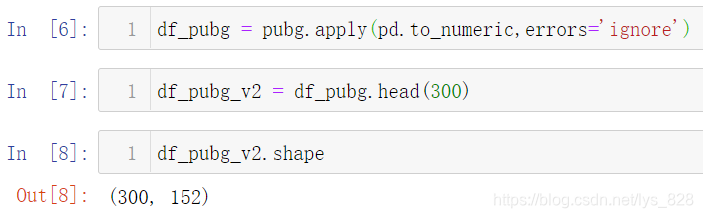
测试数据为kaggle网站上关于吃鸡“PUBG”数据集,共有87898行, 152字段,绘图只需要用到其中的部分字段,导入绘图模块以及测试数据
from plotly.offline import download_plotlyjs , init_notebook_mode,plot ,iplot
import plotly.graph_objs as go
import pandas as pd
init_notebook_mode(connected=True)
pubg = pd.read_csv('PUBG.csv')
pubg.head()
pubg.shape
输出结果如下:(字段中除了玩家姓名之外,全是数值数据)

为了方便后续数据的处理,将所有字段都转化为数字,如果不是数值字段忽略即可,代码指令:pd.to_numeric(error='ignore'),使用apply应用在data变量上,第一个参数只需要写函数名称,第二个变量写参数。然后由于数据量太多,绘制图形不方便,所以先提取300数据进行测试,如下
假定要查看玩家单人游戏的场次和赢的场次之间的关系,由于都是数值数据,首先会绘制散点图进行观察
#数据准备好了,直接第三步开始,将对应的字段放在x和y对应的位置
trace = go.Scatter(x= df_pubg_v2.solo_RoundsPlayed , y= df_pubg_v2.solo_Wins,name = 'Round Won' , mode = 'markers')
#第四步
fig = [trace]
#第五步
iplot(fig)
输出结果如下:(细心点可以留意设置了name参数,但是发现最终的图像中并没有显示)
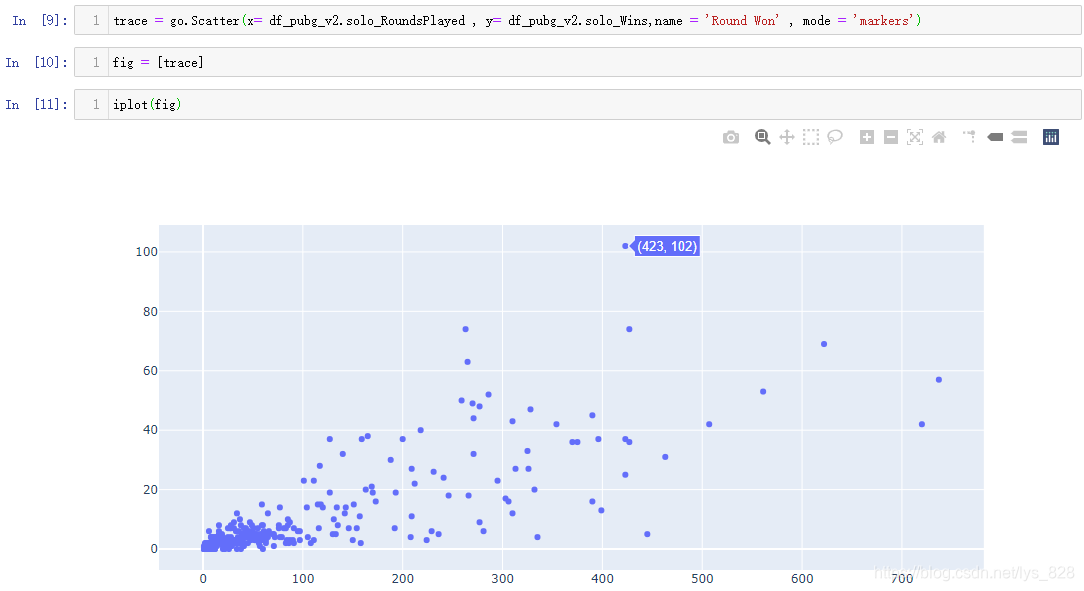
首先看一下name参数的说明文档介绍,也就是设置图像的名称之后是作为图例来显示,类似之前Matplotlib绘图的label参数,即便指定了,还是需要执行plt.legend()指令让图例标签显示出来

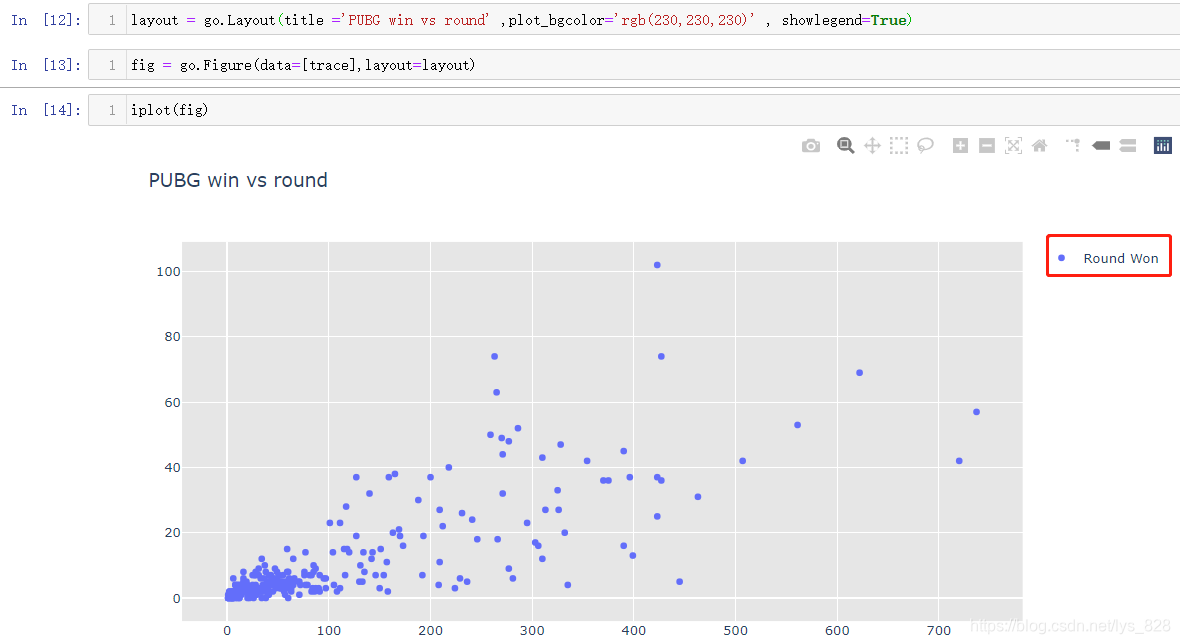
那么问题就来了,plotly中如何显示legend图例?这里就涉及到绘图第四步的内容,单独把fig = [trace]作为一步就是因为这个fig是一个列表,中间可以多个内容,除了图像之外,还可以放置布局相关的参数配置,比如这个图例,代码指令:layout = go.Layout(title ='PUBG win vs round' ,plot_bgcolor='rgb(230,230,230)' , showlegend=True),然后将这个布局layout放置在fig列表中,输出结果如下
此外绘制图像的列表中还可以再次添加图形,比如绘制横向堆叠图,使用玩家的姓名,玩家场次和赢的场次三个字段绘制
#为了体现横轴堆叠图的效果,数量就选取15份
df_pubg_v3 = df_pubg.head(15)
#创建两个条形图
trace1 = go.Bar(x = df_pubg_v3.player_name , y= df_pubg_v3.solo_RoundsPlayed,name ='Rounds Played')
trace2 = go.Bar(x = df_pubg_v3.player_name , y= df_pubg_v3.solo_Wins,name ='Rounds Won')
#将两个条形图都放置在列表赋值给data变量,然后加载刚刚设置的布局
fig = go.Figure(data=[trace1,trace2],layout=layout)
#最后直接绘制图像
iplot(fig)
输出结果为:(至此就发现前面梳理步骤的完整过程每一步都很重要,这样绘制图形的逻辑就很清晰了,第二步有时候是为了确认数据正常加载到go对象中,额可以直接核对数据内容)

进一步将绘图的过程用流程图示展现,如下
5 Plotly绘制密度图和三维散点图
5.1 绘制2D密度图
还是使用吃鸡的数据集,探究一下玩家的存活时间与赢的场次之间的关系。不过这次绘制的密度图是在图形工厂下面的模块中。导入指令:import plotly.figure_factory as ff,具体实现的方式和之前介绍的不一致,相较比较简单
#取5000条数据进行测试
df_pubg_v4 = df_pubg.head(5000)
#导入绘图的模块并创建数据
import plotly.figure_factory as ff
x = df_pubg_v4.solo_Wins
y = df_pubg_v4.solo_TimeSurvived
#将x,y数据传入绘图函数中
fig =ff.create_2d_density(x ,y)
#在线显示密度图
iplot(fig)
输出结果如下:(绘制2D密度图的方式和之间Matplotlib绘图类似,直接调用函数后传入对应的x,y参数即可,由于是plotly需要指定显示的模式,就多了最后的一步)
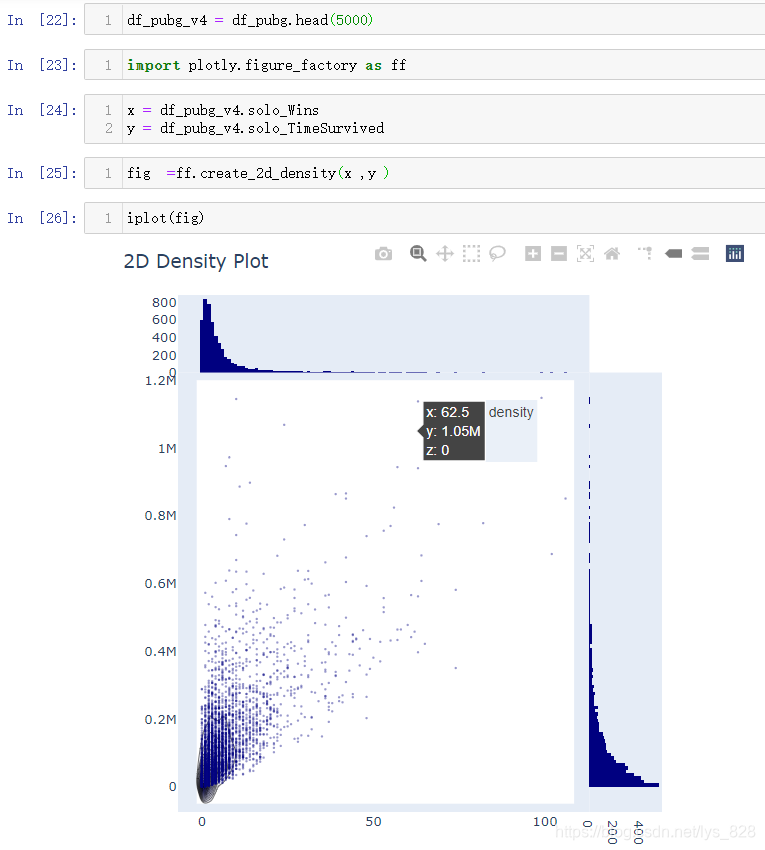
2D密度图属于统计类图表,通过x轴右侧和y轴上侧的直方图,可以看出数据主图的分布区间和对应的频数,而中间的散点就是x与y结合的结果,具体的含义理解为玩家赢的次数少生存时间少是普遍的现象,只有很少的一部分是生存时间长而且赢的场次还多的数据
5.2 绘制3D散点图
可能对于这种2D的图形没有办法让人直观的理解,就有了直接绘制三维散点图的需求,将玩家的游戏场次也作为一个字段加到图形中构成三维,绘制的代码指令为:go.Scatter3d(),通过go构造器来进行绘制,故严格遵守前面梳理的过程
#绘制的散点梳理不宜过多,选取100条数据进行绘制
df_new_pubg = df_pubg.head(100)
#创建数据
x =df_new_pubg.solo_Wins
y = df_new_pubg.solo_TimeSurvived
z = df_new_pubg.solo_RoundsPlayed
#创建go对象并赋值为trace对象
trace1 = go.Scatter3d(
x=x,
y=y,
z=z ,
mode='markers',
marker=dict(
size=12,
color = z,
colorscale='Viridis',
opacity=0.8 ,showscale=True
)
)
#添加layout布局
layout = go.Layout(margin=dict(
l=0,
r=0,
t=0,
b=0
))
# 将图像和布局都放置在Figure中
fig = go.Figure(data=data , layout=layout)
iplot(fig)
输出结果如下:(结果就是玩家次数少,赢的场次少,而且生存时间短是普遍现象,毕竟大神很少)
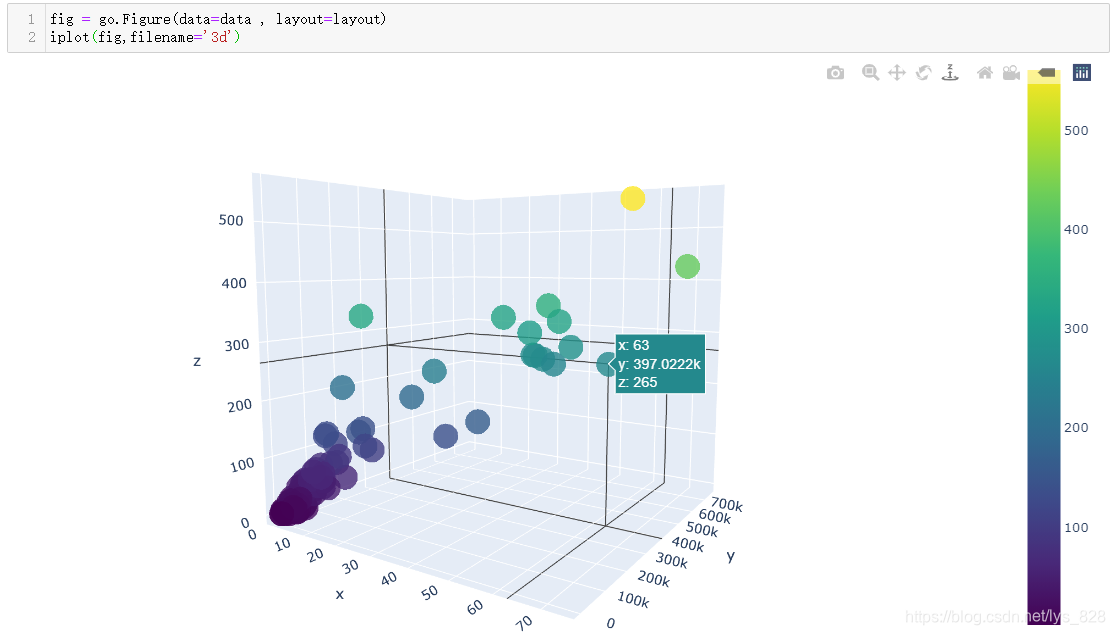
6 Plotly在线编辑绘图
iplot()进行内嵌交互图形绘制,同时也可以借助plotly提供了一个在线的编辑绘制图形的网址,将绘制的图形自动上传至该网址,前提是需要进行网址的注册登录并拿到api的钥匙。该网址为:chart-studio官网
进入网址后点击右上角的Sign Up按钮,弹出如下的界面,按照提示的要求进行相应信息的注册,接下来就按照提示的指引完成注册即可
注册成功后,原来网页右上方的注册按钮变成了个人中心,点击下拉的符号后弹出的界面选择第三项Settings

跳转页面后选择API Keys选项,里面就对应着用户名和API钥匙,这里点击Genrate Key就会自动更新API密匙
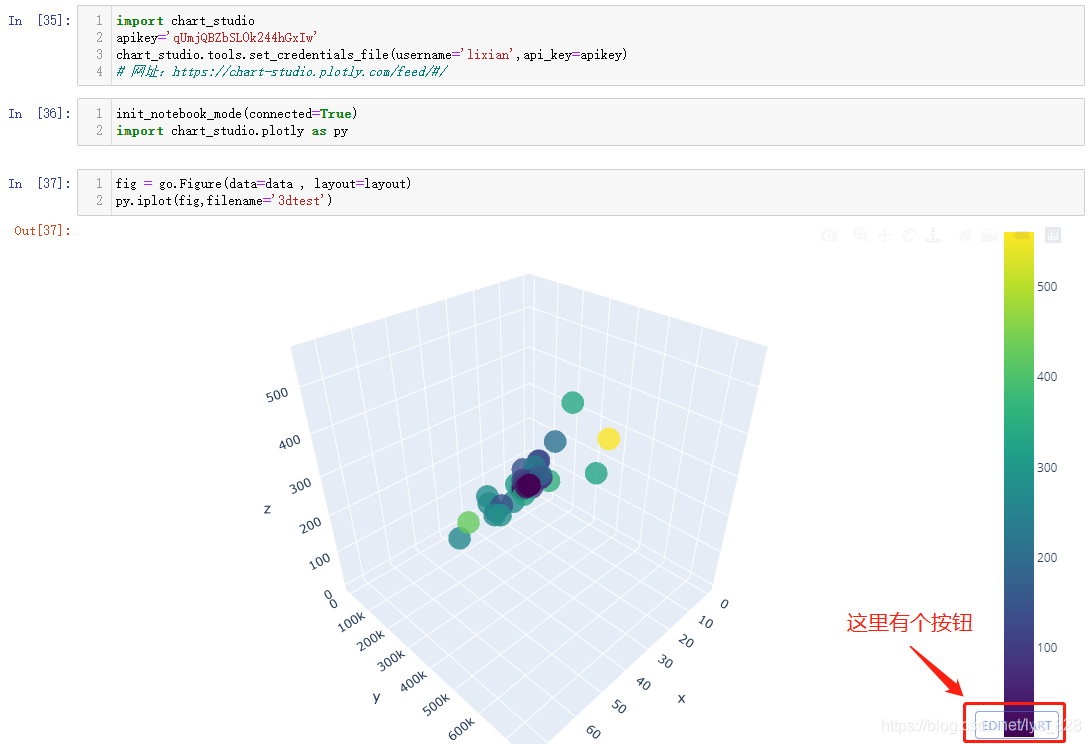
接下来就是在notebook中连接chart-studio进行绘制图像,操作代码如下
import chart_studio
apikey='qUmjQBZbSL0k244hGxIw'
chart_studio.tools.set_credentials_file(username='lixian',api_key=apikey)
init_notebook_mode(connected=True)
import chart_studio.plotly as py
fig = go.Figure(data=data , layout=layout)
py.iplot(fig,filename='3dtest')
输出结果如下:(前四行的代码固定格式不需要改动,只要把注册完毕后自己的用户名和密匙填到对应的位置即可,我这里的密匙在演示结束后已经进行更新,目前已经失效,剩下的三行代码与原来不同就是就导入了一个chart_studio.plotly模块,iplot()前面加上这个模块名即可,最后生成的图形中右下角有个明显的EDIT CHART按钮)
注意最后一行代码的filename参数在图中没有显示出来,但是点击EDIT CHART后,跳转到chart-studio网址,上传到网址上的文件名称就是filename参数指定的内容,如下(通过在线生成的图片如果和自己的账号连接后,之后图片都会自动上传至My Files选项下,并且图片的排序方式是按照时间的顺序进行显示,最近生成的图片在最前面)
将鼠标放置在生成的图片文件上面,就会显示两个按钮,一个是Editor(在线编辑),另一个是Viewer(查看文件)
如果点击Editor,会进入图片编辑器,可以在表格区域对原来的数据进行修改,左侧的菜单栏可以对图形进行微调,以及保存分享等操作,右下角是图形同步显示的区域,数据或者参数修改之后可以在这部分区域看到实时的图形效果
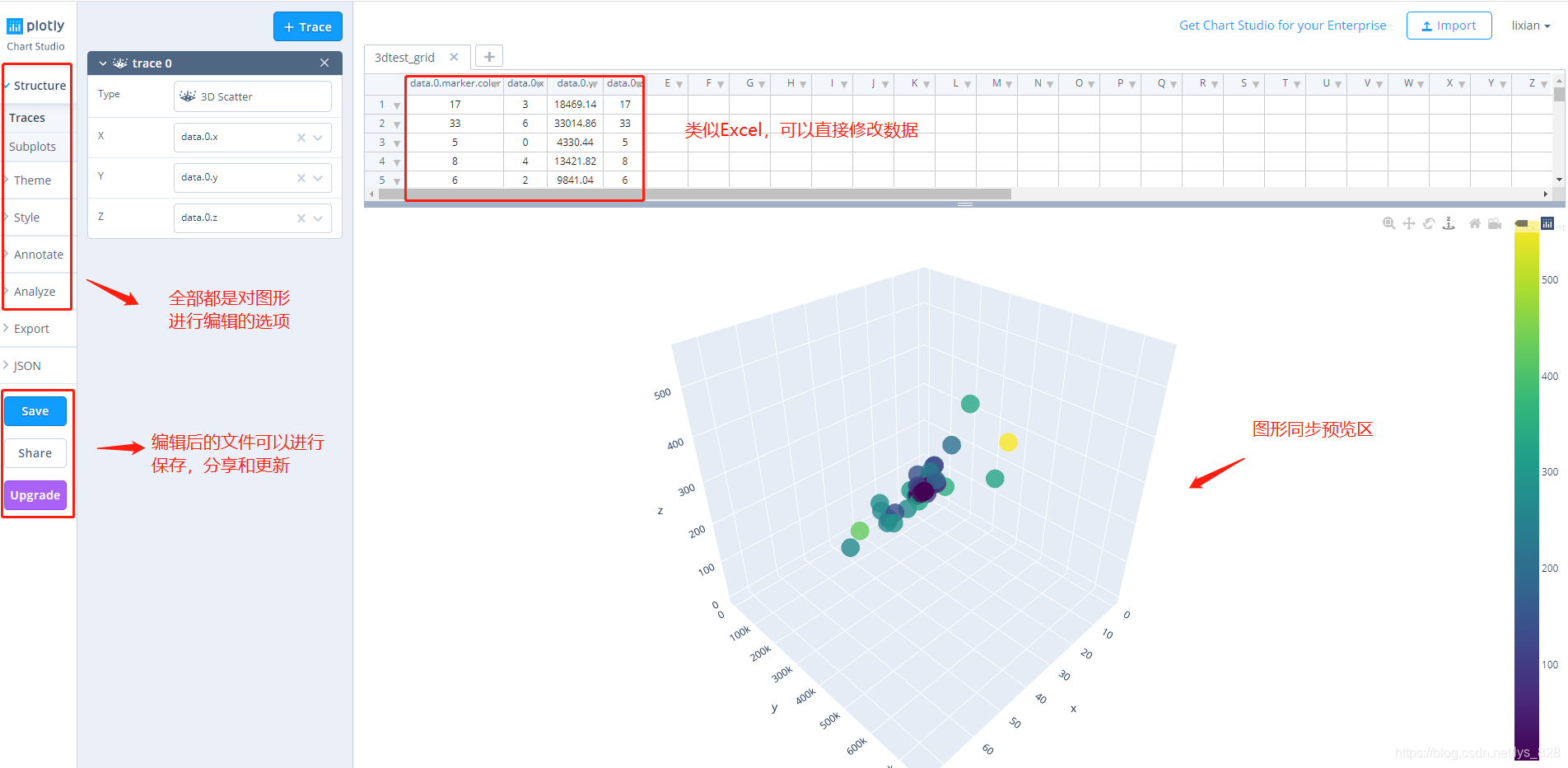
这个除了编辑已有的图片外,直接可以新图片的绘制,只要把数据上传至表格区域内调整左侧的参数各种图形均可以绘制,如下

如果点击的是Viewer,会进入图片查看器,默认是第一个Plot选项,显示图形,剩下的就是显示绘图的原始数据,pyhton/R的代码以及别人关注的历史
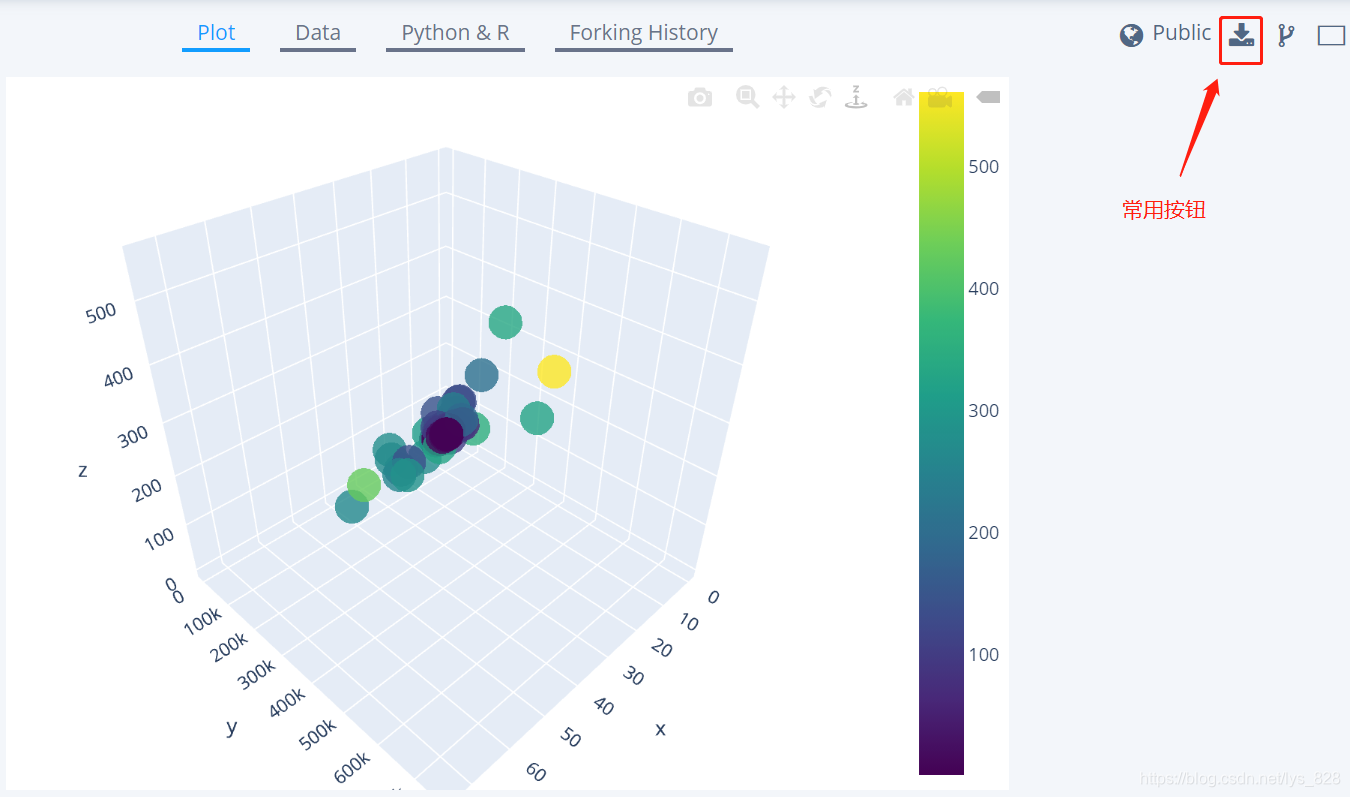
网页的右上方有几个按钮,其中最常用的就是下载按钮,可以根据需要进行不同格式文件的下载,比如通过Plotly绘制的一张图片可以供选择的格式如下(深色的按钮对应类型格式均表示可以下载)
7 Plotly绘制金融数据图
7.1 离线模式和在线模式绘图差异
在绘制实时金融数据图之前,对plotly的离线模式和在线模式进行对比归纳总结。导入必要模块和测试数据,测试数据是使用之前的Apple的股价数据,操作如下
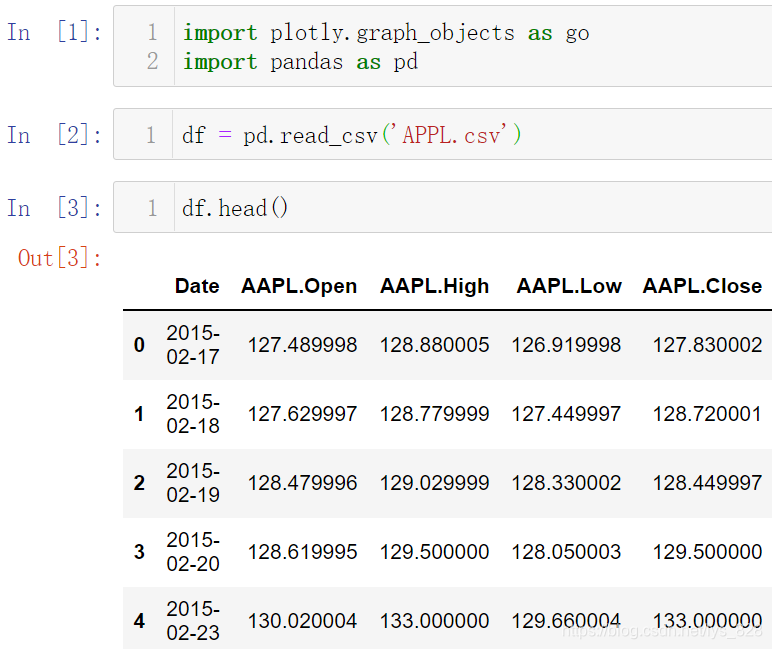
假如使用日期和收盘价进行绘制图形,两者前期提都得使用go构造器来放置数据
trace01 = go.Scatter(
x=df.Date,
y=df['AAPL.Close'],
)
不同点就在于通过连接chart_studio在线的模式绘制图形需要导入一个模块即可,然后使用这个模块调用iplot()
然后离线方式绘制的代码中需要导入四个模块,代码如下(经过前面的介绍,离线模式里面的iplot()是相对于本地模式来讲的,绘制的图形内嵌在notebook中,且每次查看的时候都需要重新运行才能显示出来,与网络的加载有着密切的关系。chart_studio下的iplot()的在线模式,是在绘制图像的同时并将图像上传至网站上进行备份)
7.2 绘制时间滑动条
利用特斯拉的股票数据进行绘制图形,已经加载过绘图和读取数据的模块,这里就直接读取文件并查看数据的前5条,如下
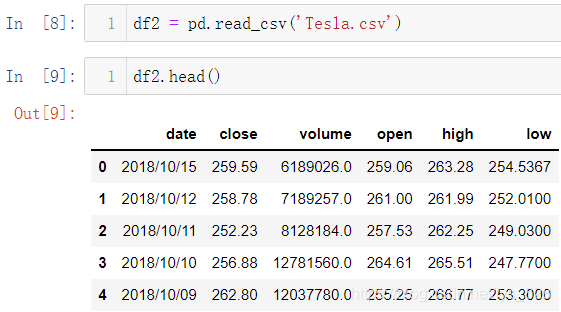
股票数据图的绘制其实就是波动的折线,而这种图像直接通过go.Scatter()方法绘制,前面已经介绍过了绘制散点图,要求使用里面的mode参数,如果不指定就是默认直线连接
trace_a = go.Scatter(
x = df2.date,
y = df2.high,
name = "Tesla High",
line = dict(color = '#17BECF'),
opacity =0.8
)
py.iplot([trace_a])
输出结果如下:(里面的opacity参数就是等同Matplotlib绘图中的alpha参数,都是指定绘制线条的透明度)
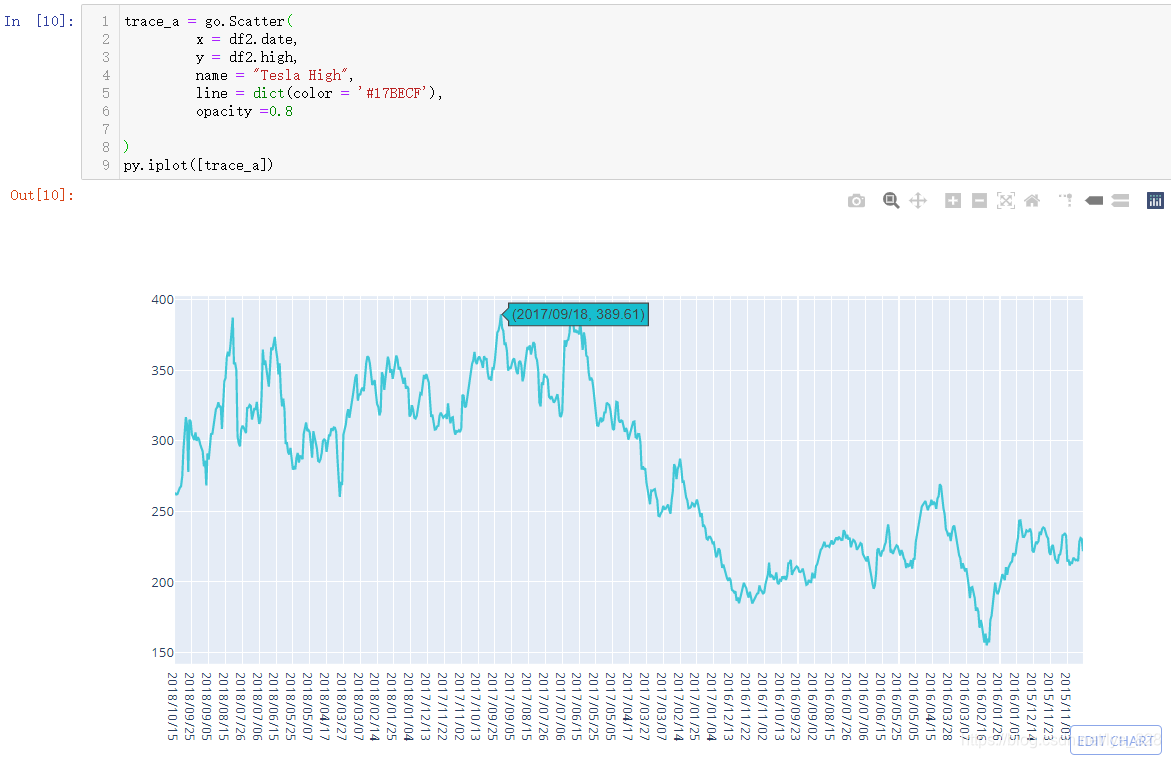
甚至在一条变化图线的基础上再添加两条图线分别代表着当日股价的最高点和最低点,同时对绘制的图像进行布局设置
trace_b = go.Scatter(
x = df2.date,
y = df2.low,
name = "Tesla Low",
line = dict(color = '#7f7f7f'),
opacity =0.8
)
trace_c = go.Scatter(
x = df2.date,
y = df2.close,
name = "Tesla Close",
line = dict(color = '#7f1f7f'),
opacity =0.8
)
layout = dict(title = "Tesla stock High vs Low")
data = [ trace_a,trace_b,trace_c]
fig = dict(data=data,layout=layout)
# fig = go.Figure(data=data,layout=layout)
iplot(fig)
输出结果如下:(iplot()括号中除了使用go.Figure()传递的对象,直接也可以传递一个字典)
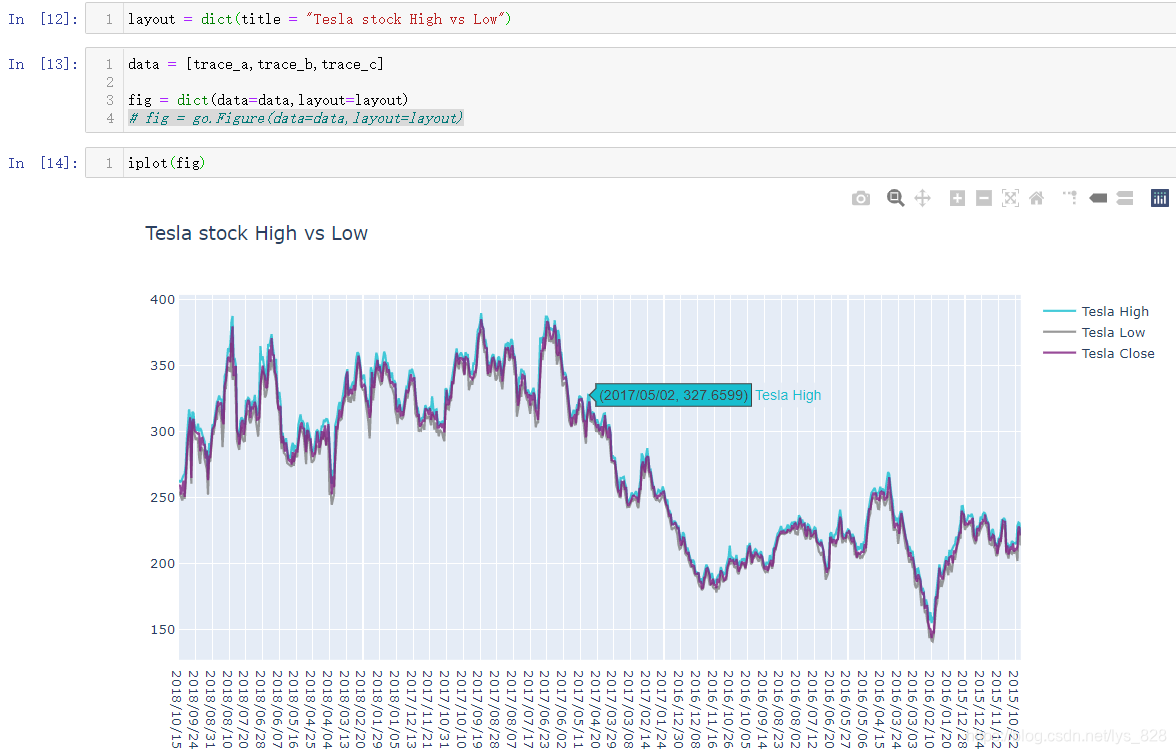
在查看时序数据中由于存在变化的范围,经常看见可以拖动的时间滑条,使用plotly也可以进行绘制,具体步骤分为四步:
- (1)导入绘制的模块:
import plotly.express as px - (2)绘制变化的折线:
fig = px.line(df2 , x='date',y='close') - (3)更新x轴信息添加范围变化条:
fig.update_xaxes(rangeslider_visible=True) - (4)显示最终图片:
fig.show()
输出结果为:(随着下端两侧的拖动条变化,上方网格范围内的线条也会发生对应的变化)
7.3 添加时间转换器按钮
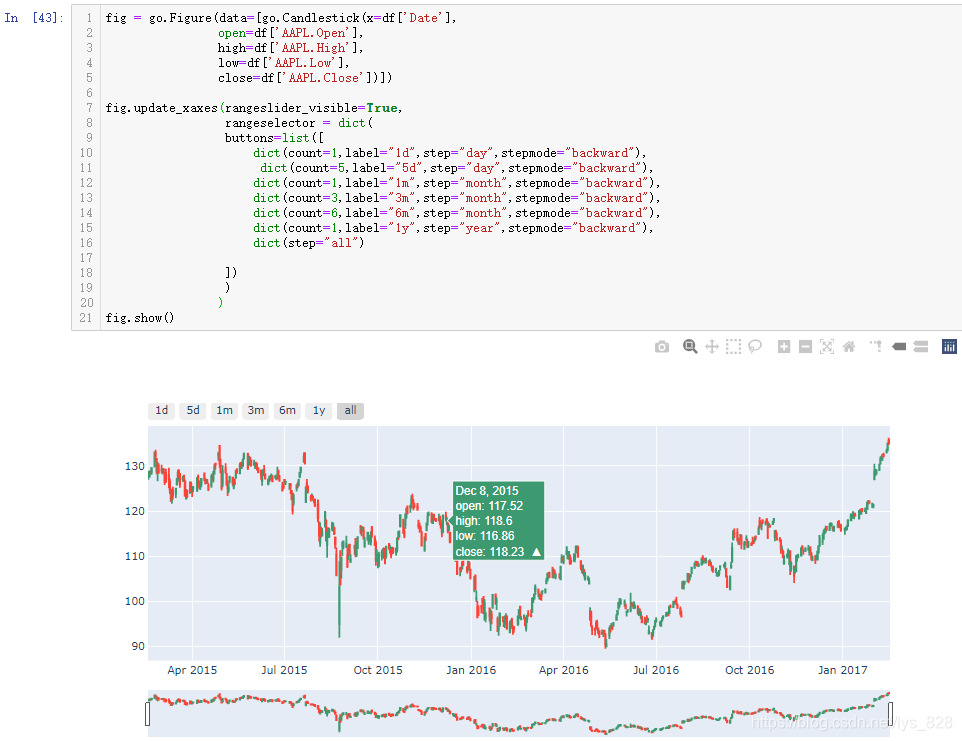
除了添加手动拖动的时间滑条外,也可以增加固定时间的转换器,这需要使用到 rangeselector参数,具体赋值要求为字典,对应的键就是切换器对应的按钮button,然后值就是要进行切换的时间点
fig = px.line(df, x='Date', y='AAPL.High', title='Time Series with Rangeslider')
fig.update_xaxes(rangeslider_visible=True,
rangeselector = dict(
buttons=list([
dict(count=1,label="1d",step="day",stepmode="backward"),
dict(count=5,label="5d",step="day",stepmode="backward"),
dict(count=1,label="1m",step="month",stepmode="backward"),
dict(count=3,label="3m",step="month",stepmode="backward"),
dict(count=6,label="6m",step="month",stepmode="backward"),
dict(count=1,label="1y",step="year",stepmode="backward"),
dict(step="all")
])
)
)
fig.show()
输出结果如下:(会在原来图像的左上方添加固定时间的转换器,点击后就可以锁定指定的时间,count和step参数结合就是指定时间长度,然后label参数就是添加按钮上面标签信息)
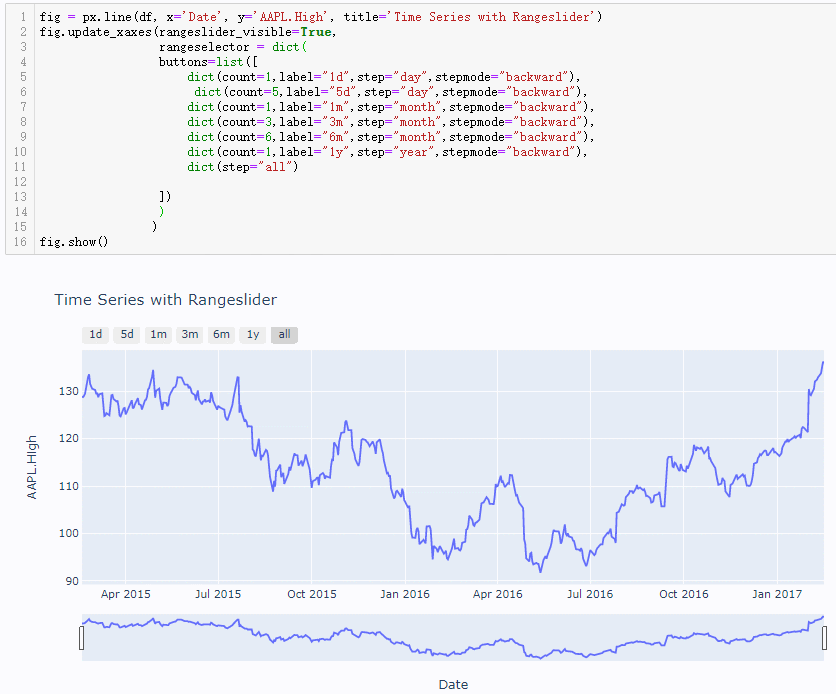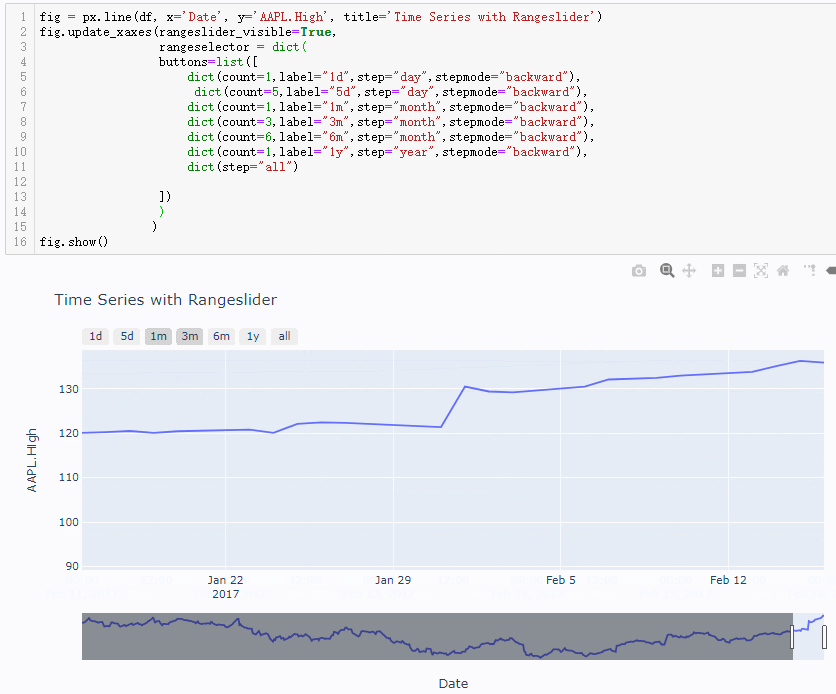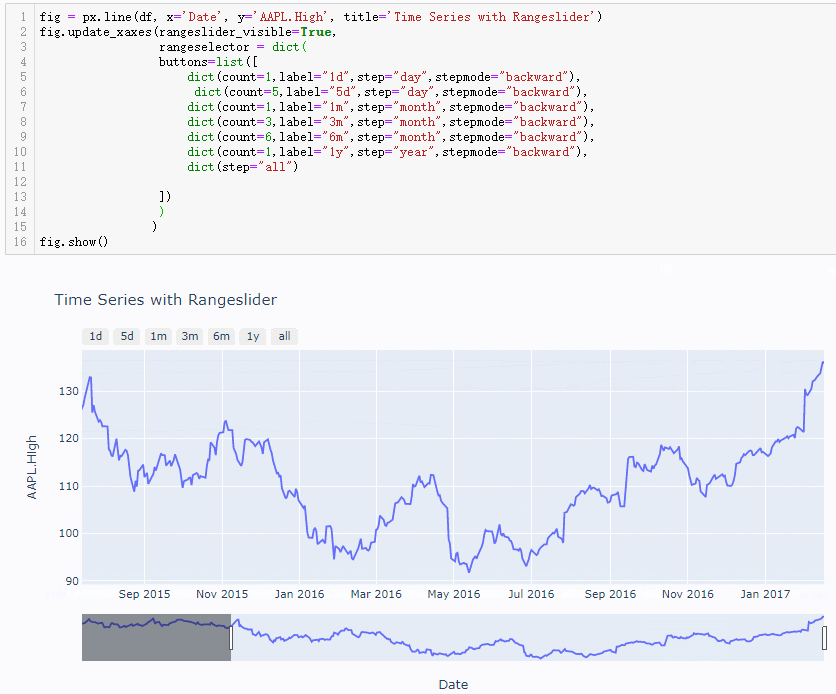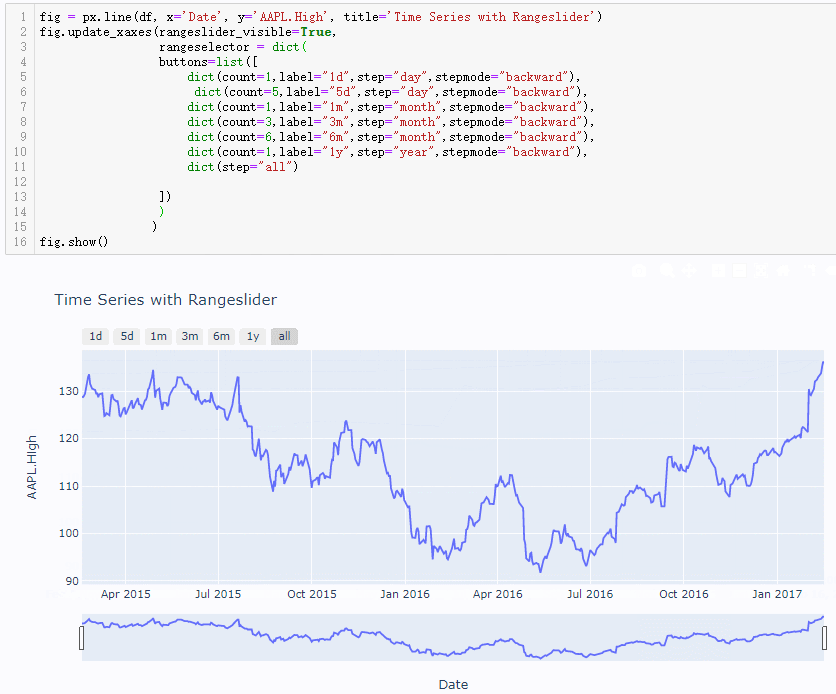
接下来就是一种很重要的知识点,日后经常使用可以提高编程效率,就是试错法。上面代码中还有一个参数没有提及stepmode,参看说明文档如下,其中没有关于这个参数的使用说明,甚至连rangeselector参数的使用说明都没有
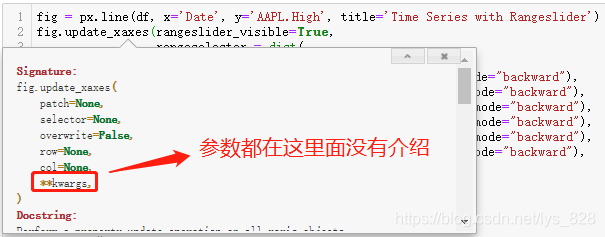
此时最快捷的方式不是去百度翻各种帖子或者是直接找官方更详细的说明文档,这时候应该用一下试错的方式,既然这个参数赋值了backward,那么对应是不是应该有一个选项是forward与之对应?就按照这种猜想进行试错,输出结果如下(输出结果报错,但是报错是有价值的,告诉了我们这个参数具体什么意思以及可以使用的赋值对象)
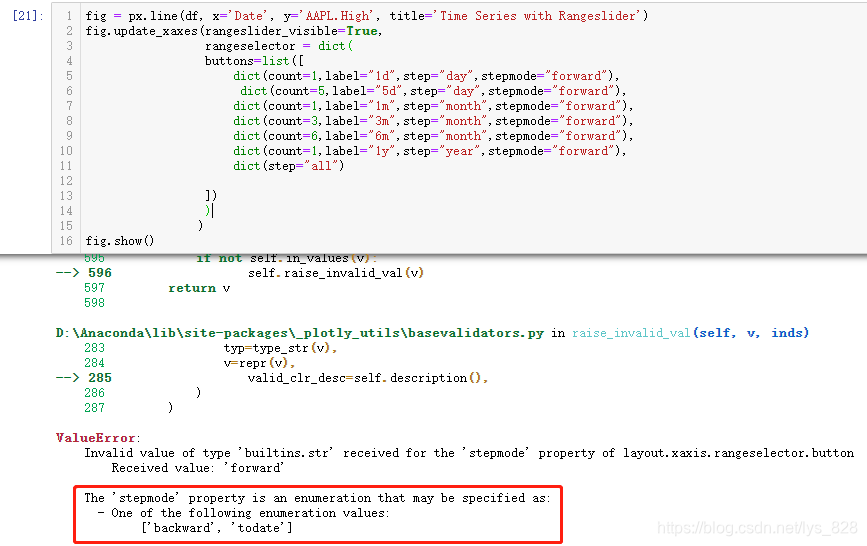
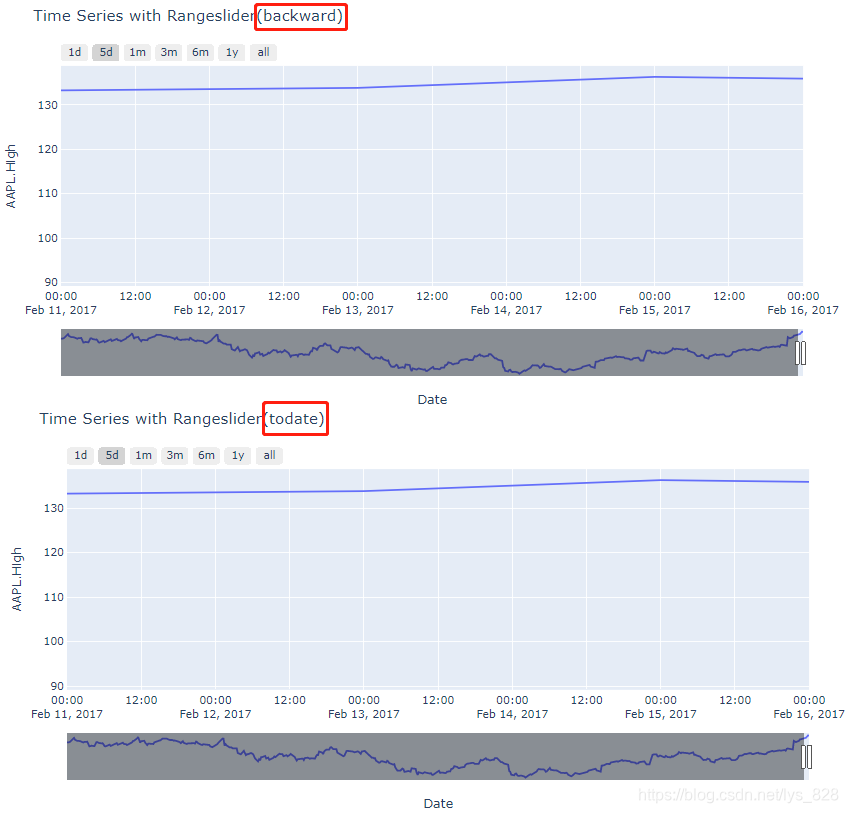
The 'stepmode' property is an enumeration直接翻译过来就是一个计数器(枚举器),具体如何枚举的?就有两种方式分别对应backward,todate。两个赋值对象的差别最直观的方式就是进行绘图,看一下出图的不同,然后根据内容显示的不同就知道这个复制对象的具体含义
对于1d和5d两个图形都是保持一致(以5d为例做出对比图)
在后面的几个时间转换器中差别就体现出来了(比如以1m和1y为例,3m,6m两个参数的差别也是同理)
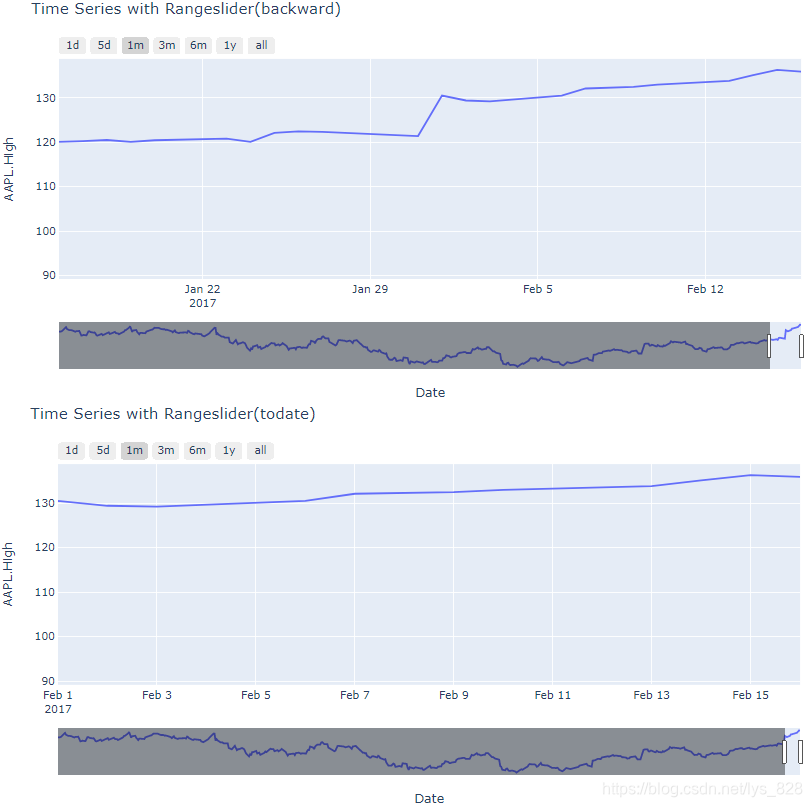
注意对比上图关于指定1m的区间两者下方的滑动条范围以及图像左右两侧的时间标记,backward参数绘图中时间跨度是1个月完整的天数,但是todate参数绘图时间跨度只会到指定时间的当前月份的第一天,而不是一个完整的天数,比如这里数据最后一条的时间是2017年2月16,前者1m转换器的区间是[2017-1-16,2017-2-16],后者1m转换器的区间是[2017-2-1,2017-2-16]。由此两个参数对应的枚举方式的差别也就体现出来了,那么在用1y转换器出的图形进行验证,如下(前者输出的时间区间为[2016-2-16,2017-2-16],后者者输出的时间区间为[2017-1-1,2017-2-16],验证无误)
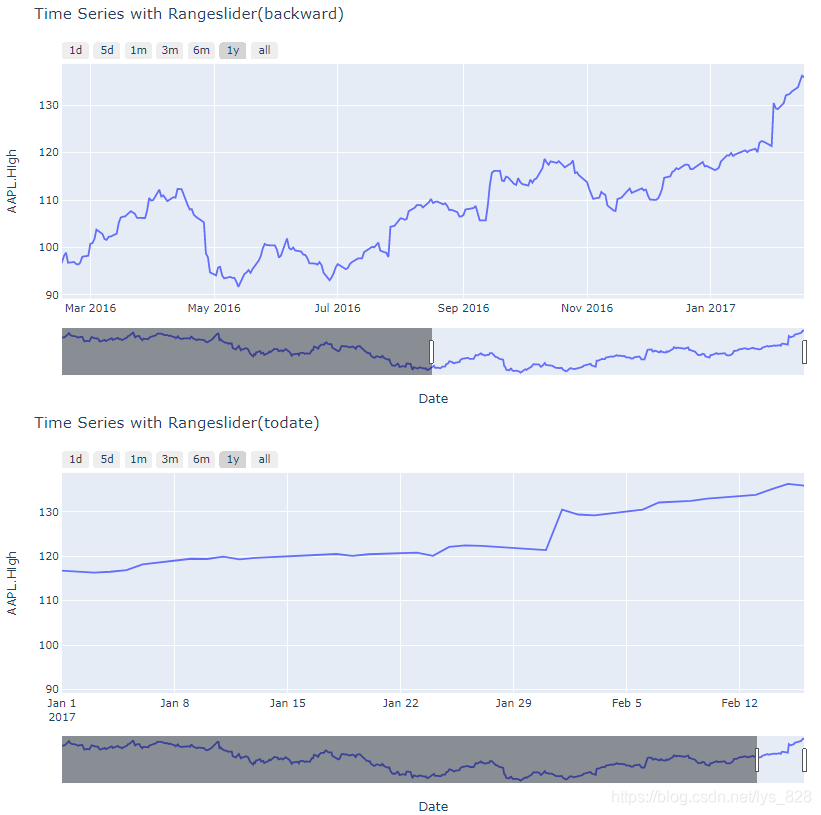
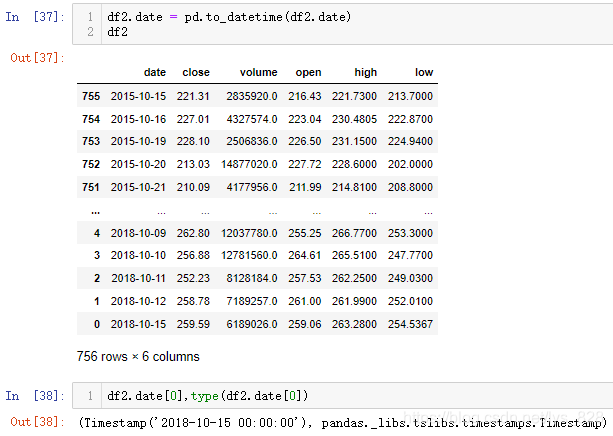
至此关于试错法的运用收获良多,也通过出图对比了两者之间的差别,此外绘制这个图形对应时间数据的格式是有要求的,经过测试发现只有datetime数据类型或者是xxxx-xx-xx字符串数据的时间是可以生成转换器,否则最后达不到效果
比如不使用Apple的股价数据,而是使用特斯拉的股价数据,两者都是有时间字段的数据,前者df的时间字段符合xxxx-xx-xx字符串数据的时间,但是df2中的时间字段不符合
那么直接使用df2的数据进行绘制,看看效果图(最终是没有出现转换器的按钮)
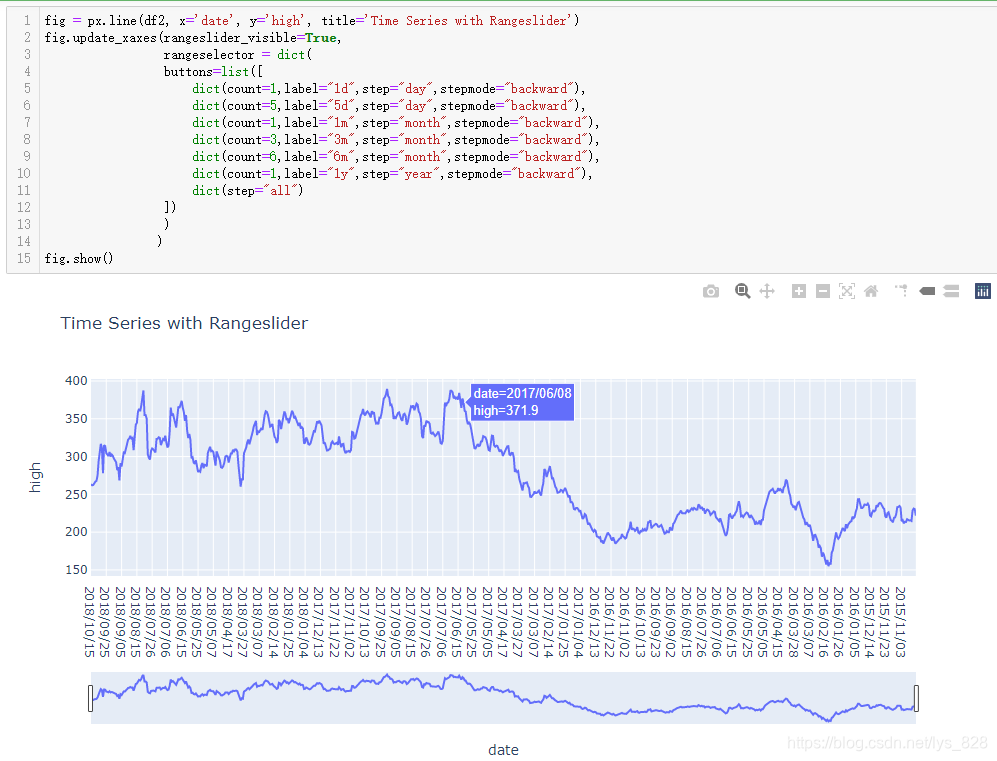
可能细心点的同学注意到了x轴的时间区间范围是反了,会不会是这个原因导致的,可以尝试把df2按照时间字段反序后再进行绘制,真是个好想法,这样严格的对比测试才能真正的找出问题所在
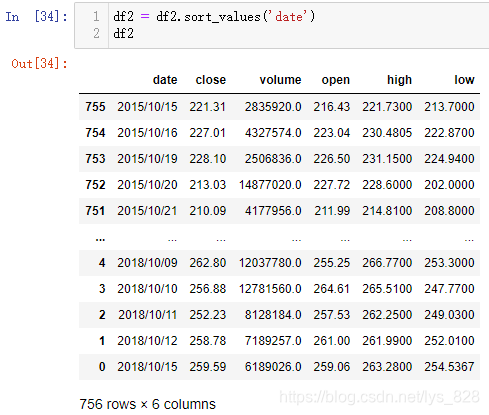
已经将时间顺序进行反序,然后再进行图像的绘制,最后的输出结果中仍然没有转换器的按钮(时间字段的数据类型还是字符串没有进行数据类型的转化)
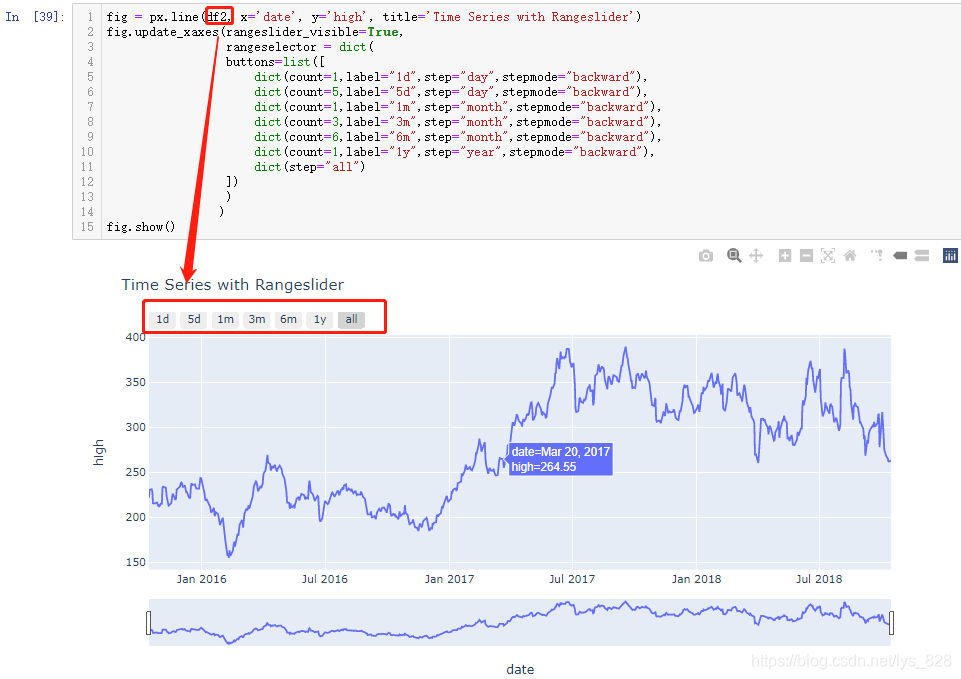
接下来就是见证奇迹的时刻,将df2时间字段的数据类型转化为datetime数据类型
绘制的图像如下:(由此关于添加时间转换器按钮部分全部的坑以及相对应细节全部介绍完毕)
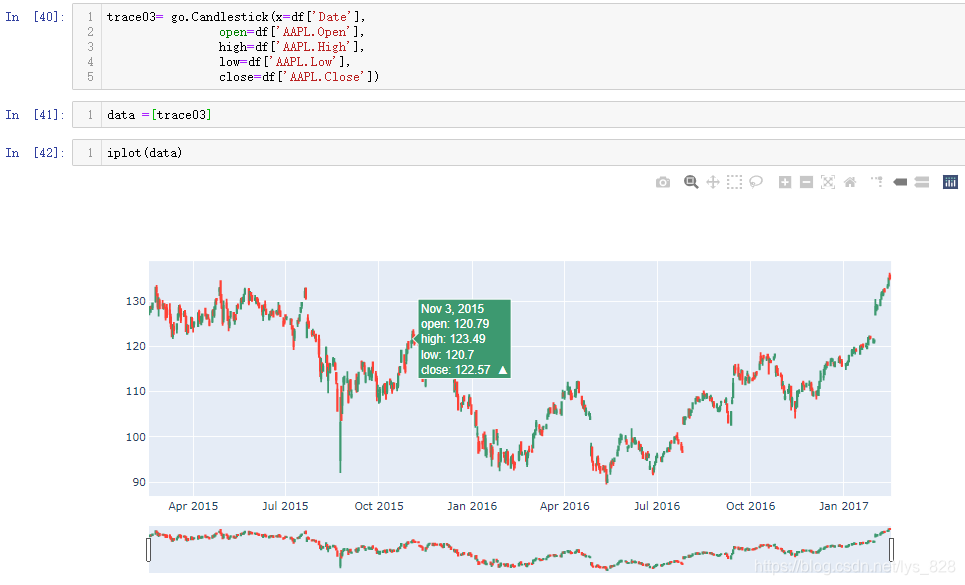
7.4 绘制蜡烛图
核心代码:go.Candlestick()
此函数中需要传入五个参数,可对比蜡烛图进行理解
x代表着时间open代表开盘价close代表收盘价high代表最高点low代表最低点
由于绘图的函数是使用go构造器,数据已经创建了,就按照剩下的第三、四、五步完成即可(最终的图形默认就讲时间的滑动条绘制出来了)
如果要添加时间转换器按钮,可以将原来的代码直接复制粘贴过来即可,都不用进行修改,运行结果如下
7.5 使用cufflinks模块绘制金融指标图
这个模块属于第三方库,可以直接在notebook中进行安装,单元cell中直接输入pip install cufflinks回车即可,程序会自动安装,如果已经安装成功后再执行这条语句输出如下
7.5.1 绘制趋势图
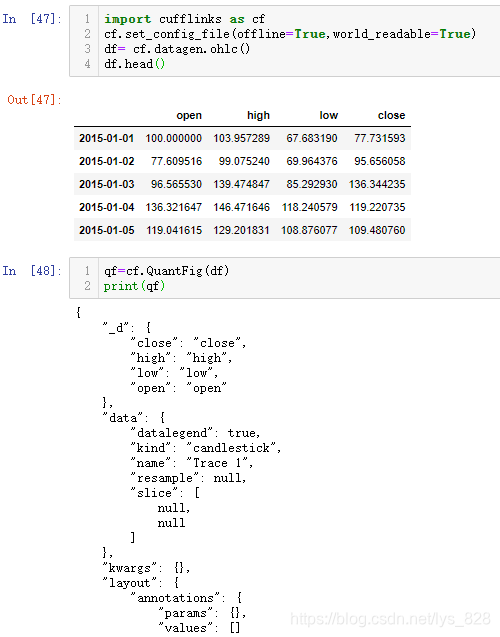
需要导入模块和加载数据后构建QuantFig函数对象,其中前两行作为默认代码导入,会自动加载相应的配置文件信息。模块自带的有测试数据,可以直接读取。将df通过QuantFig函数处理后会自动转化为字典数据格式,有些类似前面的go构造器
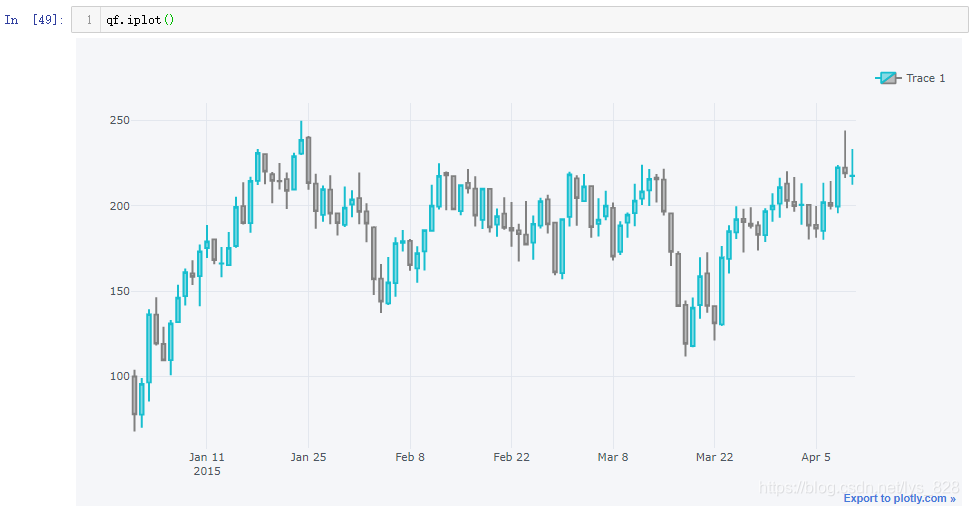
然后就可以直接进行绘图,代码指令为:qf.iplot()
7.5.2 绘制MACD指标图
核心代码:qf.add_macd()
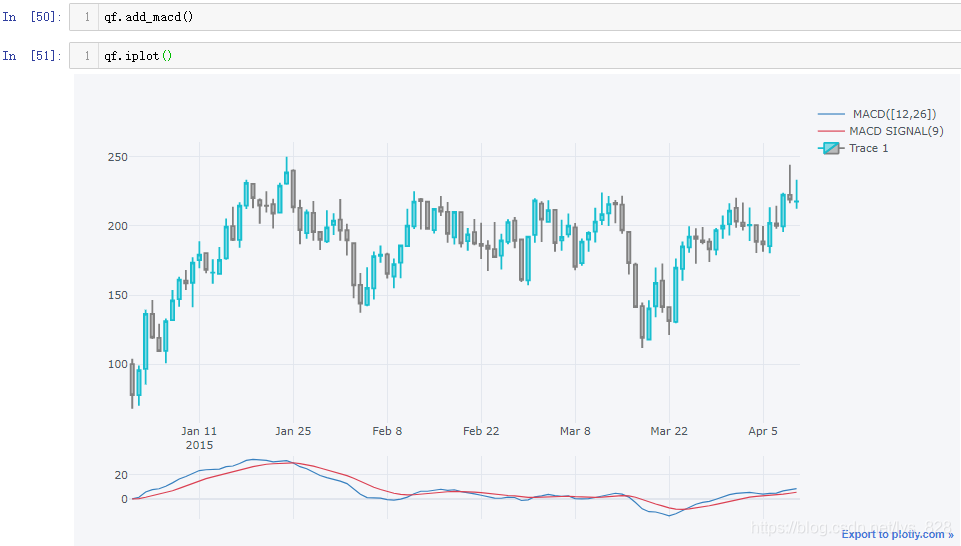
7.5.3 绘图布林带指标图
核心代码:qf.add_bollinger_bands()
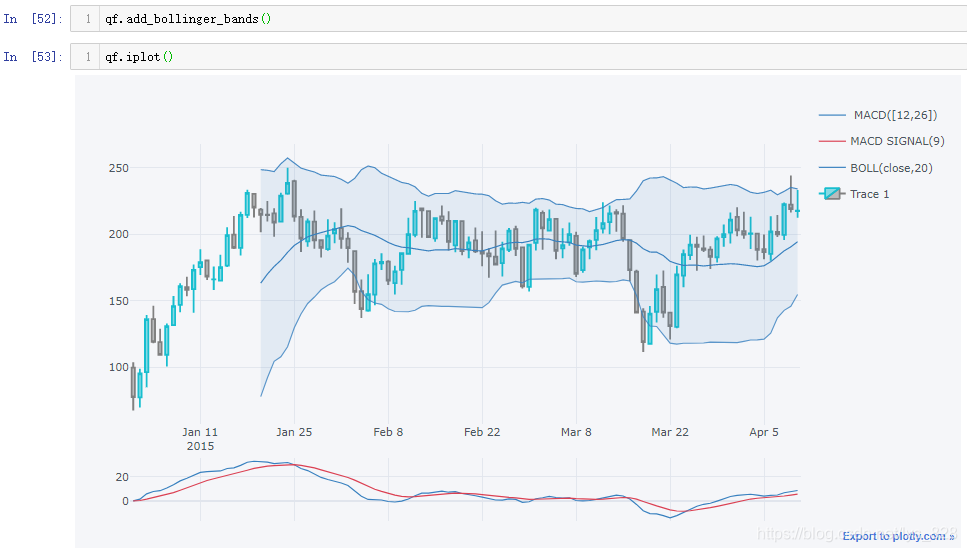
7.5.4 绘制RSI指标图
核心代码:qf.add_rsi(6,80)

8 Plotly绘制热力图和高级散点图
之前绘制的图形都是使用plotly.offline,plotly.figure_factory以及chart_studio.plotly模块进行绘制,此部分绘制的图形都是使用plotly.express模块进行绘制,使用此模块绘制的图形和plotly.offline中的iplot函数出图是一样的都是内嵌交互图片,只在运行后显示在notebook,如果再次打开notebook需要重新加载运行,且图像不会上传至网站
8.1 使用heatmap功能绘制热力图
核心代码:px.density_heatmap()
导入绘图库和测试数据
import pandas as pd
import seaborn as sns
import plotly.express as px
flights = sns.load_dataset('flights')
flights.head()
输出结果如下:(sns.load_dataset('flights')这条语句执行会经过一段时间在网上自动下载文件,如果下载不成功也可以手动进行下载)
使用热力图可以表示三个维度上的信息,刚好导入的数据集中有三个字段,比如可探究每年每月的乘客的数量情况
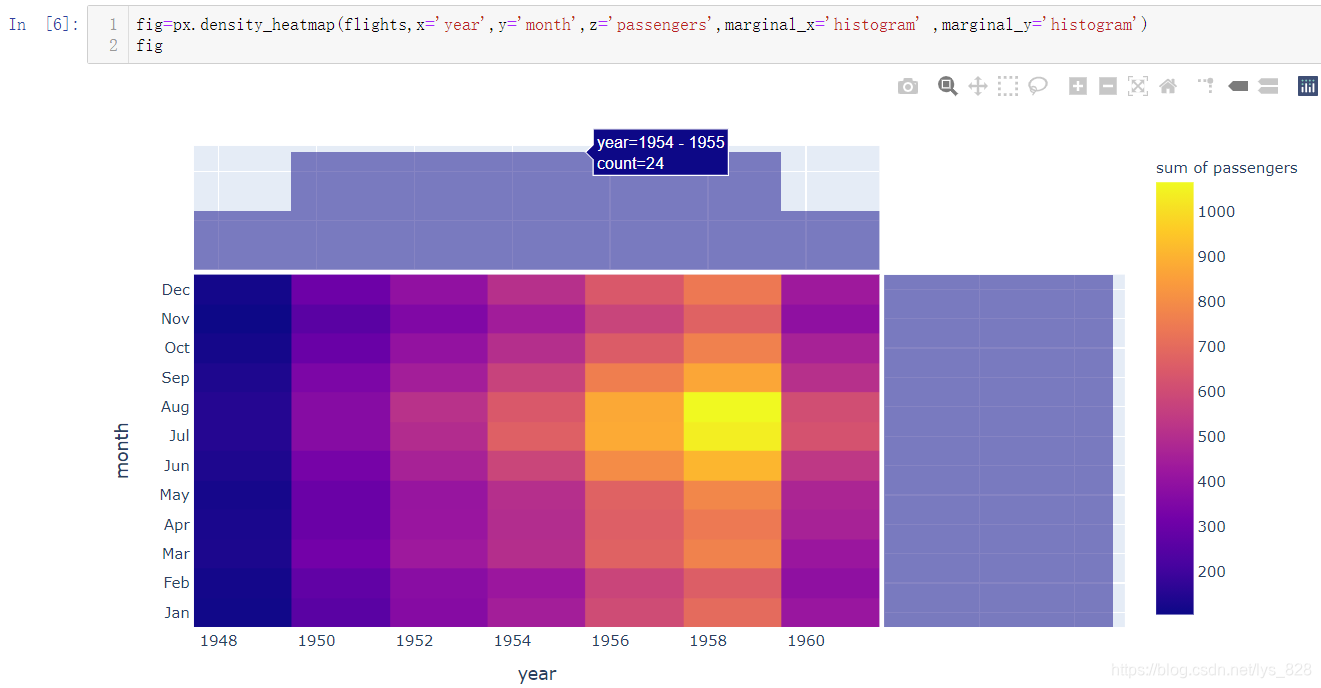
fig=px.density_heatmap(flights,x='year',y='month',z='passengers')
fig
输出结果如下:(第一个参数就是读取的df,剩下的参数就是指定要探究的三个维度,系统会在右侧生成颜色条)
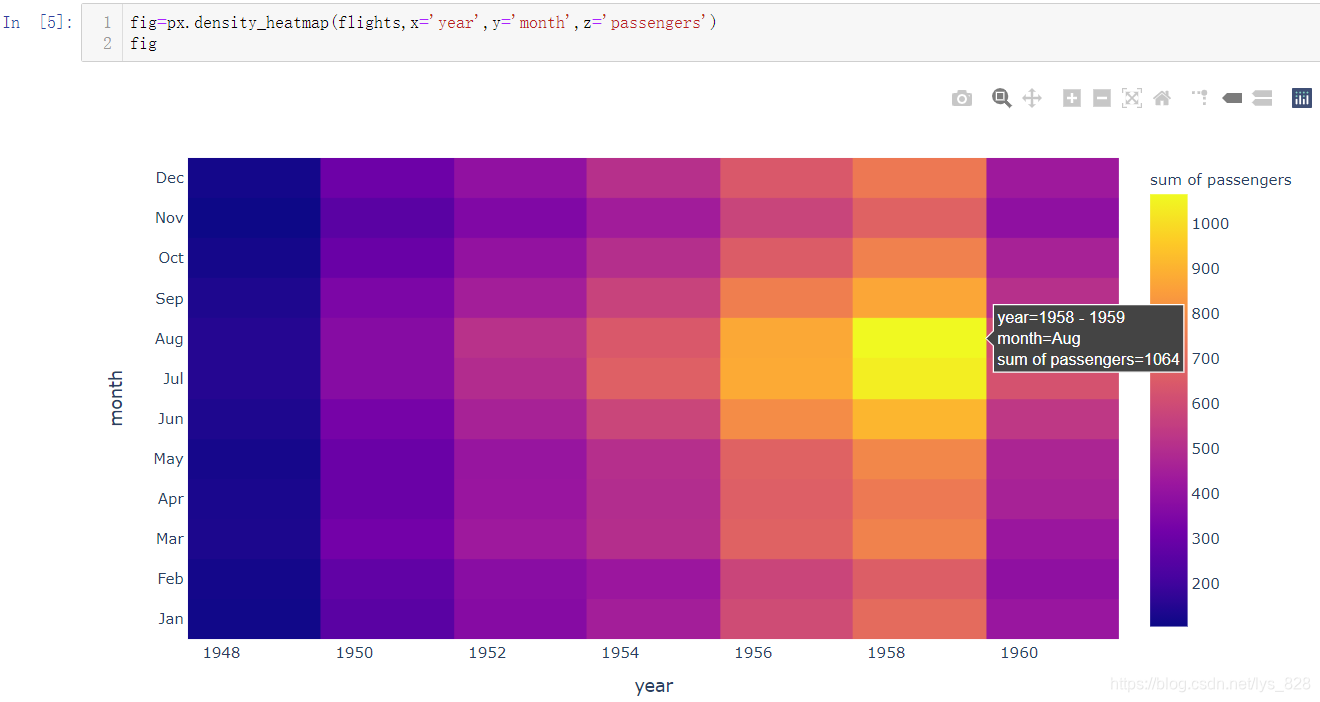
热力图只用2D图像就表现出三维的信息,而且视觉冲击力很大,在论文中使用很能吸引注意力。更进一步,该图的两侧还可以和之前绘制2D密度图一样,放置统计图表,只需要设置两个参数marginal_x='histogram' ,marginal_y='histogram',输出结果如下:
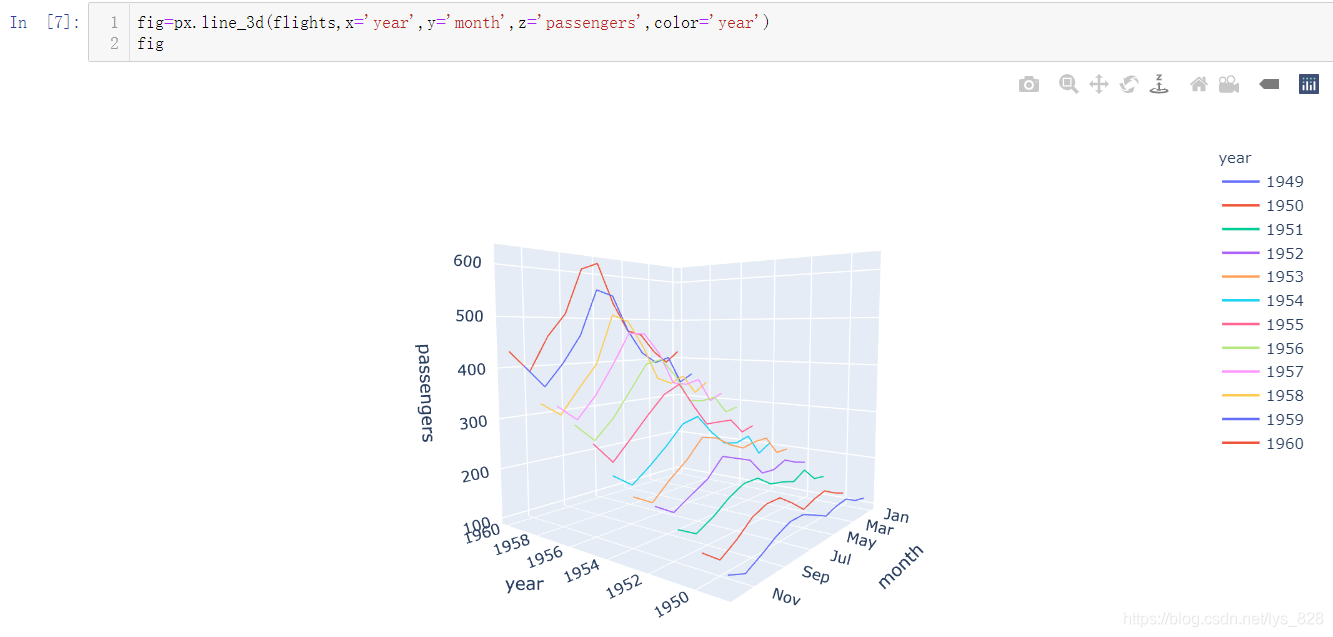
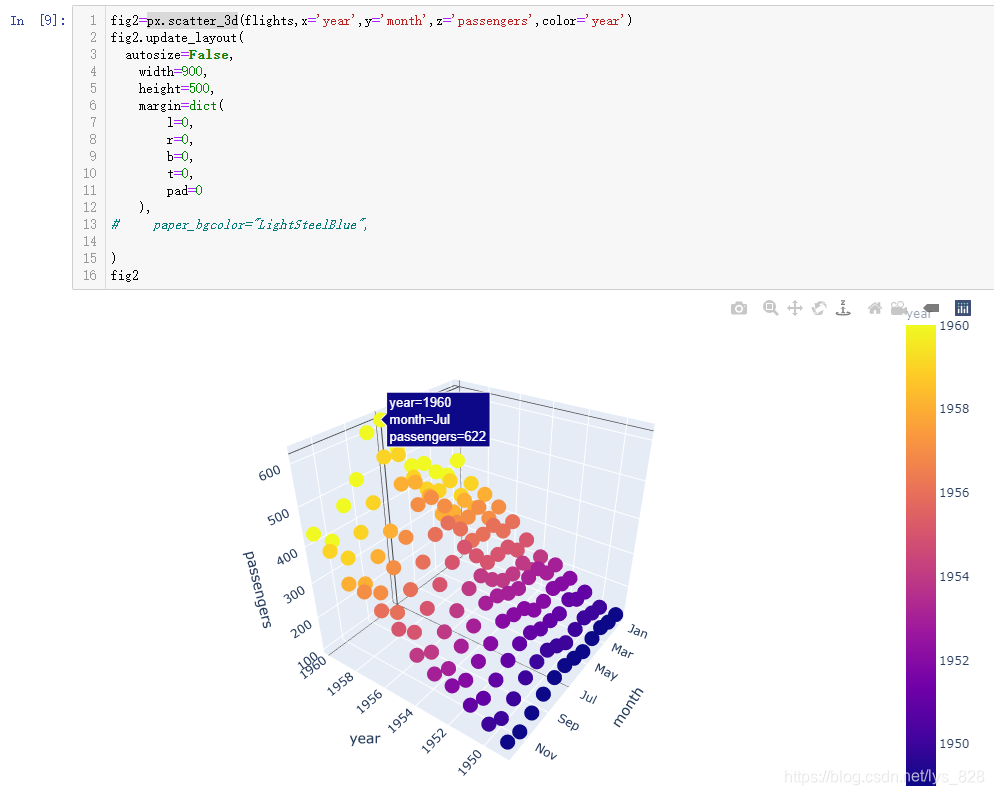
除了使用2D热力图表示三维信息外,也可以直接使用三维折线图进行展示。代码指令:px.line_3d(flights,x='year',y='month',z='passengers',color='year')
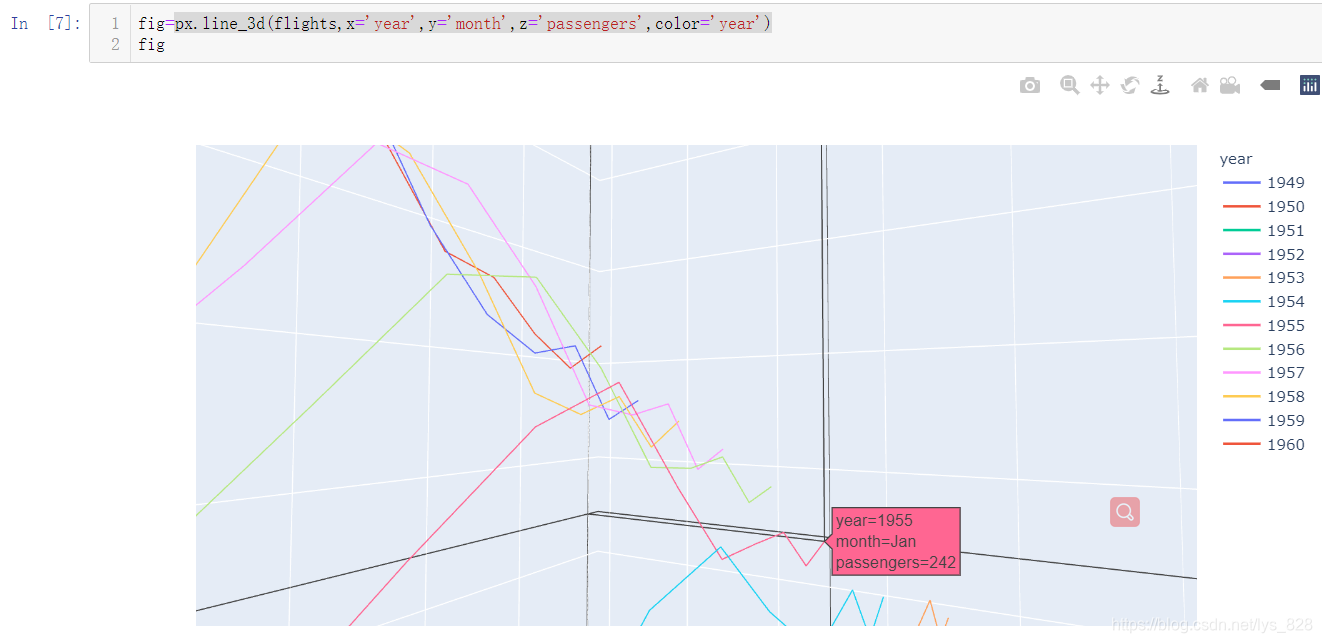
需要注意如果将图形进行放大,可以发现图像是在一个画框中,可以设置布局,将画框变的大一些,如下输出的是默认的画框大小
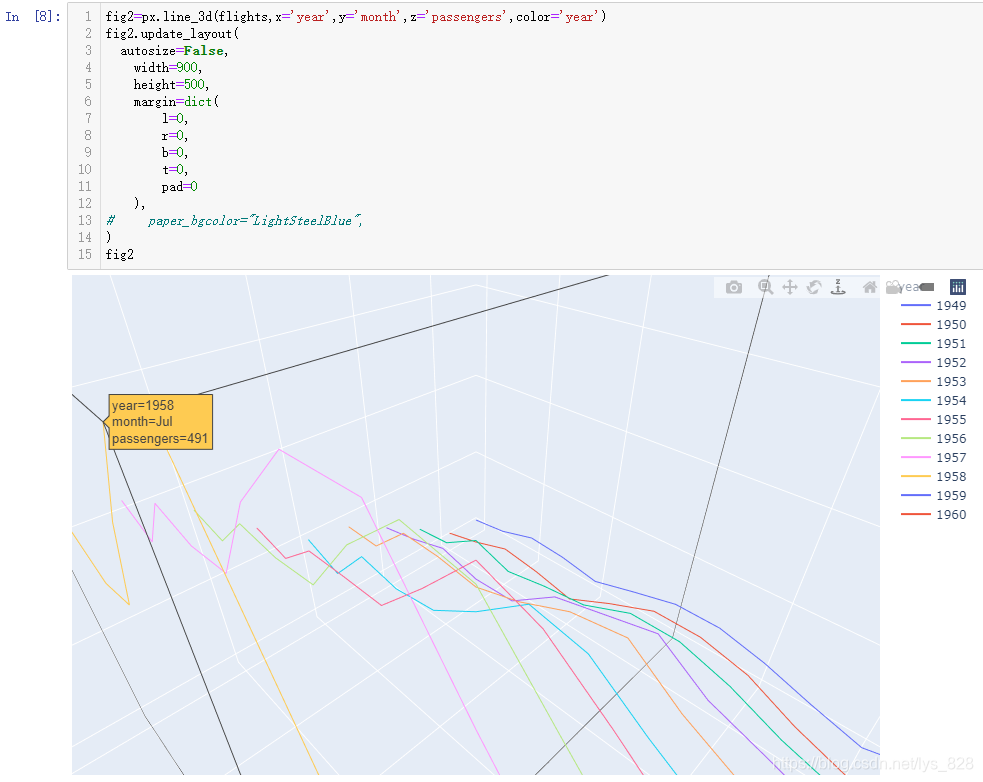
设置边框布局的代码指令为:fig2.update_layout(),具体的参数赋值如下,取消自动尺寸,自定义宽高,还有边界填充均设置为0,这样最终出的图就是最大的尺寸
fig2=px.line_3d(flights,x='year',y='month',z='passengers',color='year')
fig2.update_layout(
autosize=False,
width=900,
height=500,
margin=dict(
l=0,
r=0,
b=0,
t=0,
pad=0
),
# paper_bgcolor="LightSteelBlue",
)
fig2
输出结果如下:(对比上图,图形的窗口布局就较大了)
8.2 使用scatter绘制散点图
核心代码:px.scatter_3d()
和上图的代码基本一致,只需要换一下函数的名称即可,就是结果将折线变成了点,效果来说会好看一些
8.3 使用scatter_matrix绘制散点矩阵
核心代码:px.scatter_matrix()
除了直接利用三个字段放置在三个坐标轴上,也可以实现三个字段中任选两个进行排列组合,最后生成散点矩阵, A 3 2 + 3 = 3 ∗ 2 + 3 = 9 A_{3}^{2} + 3 = 3*2 +3 = 9 A32+3=3∗2+3=9,一种有九种组合,对应六个图形。绘图的代码很简单,只需要将df传递进去,为了强调视觉冲击感可以添加颜色的参数
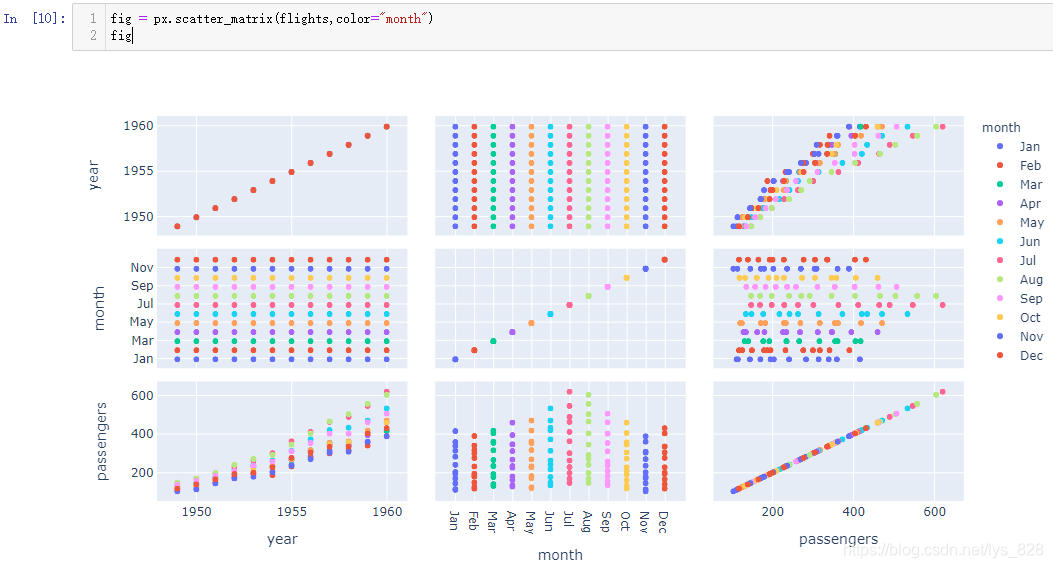
由于上方的测试数据df中刚好是3个字段,那么就会自动就对这3个字段进行绘制散点矩阵,如果数据的字段过多,就需要指定一下要比较的字段。以Iris花卉例子(后续机器学习还会经常打交道,这里就是使用这份数据,之后在详细介绍)
散点矩阵默认绘制的图形个数为: A m 2 + m A_{m}^{2} + m Am2+m。Iris花卉数据中一共是6个字段,要是默认以全部字段绘制散点矩阵,最终出现的图形就是 A 6 2 + 6 = 6 ∗ 5 + 6 = 36 A_{6}^{2} +6= 6*5+6 = 36 A62+6=6∗5+6=36个,事实输出也是如此
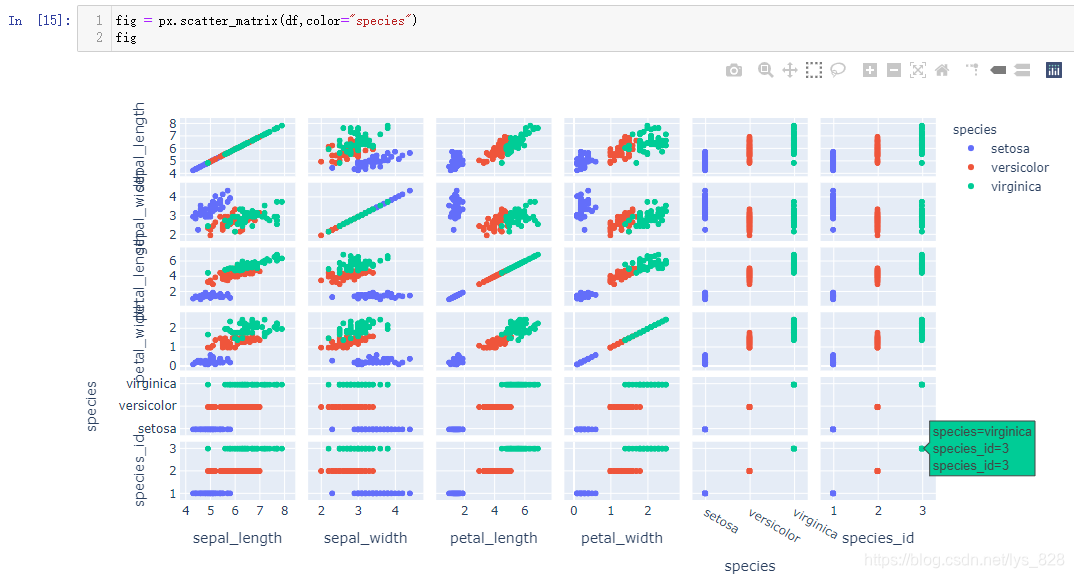
因此应该有针对性的进行字段的两两对比,想要对前4个字段的两两比较,需要使用到一个dimensions参数,指定一个列表,把要对比的字段的名称添加到列表中。需要注意一点,对称线上的图形不用看,只需要看对称线上下的一侧图像就可以了(因为上下是90对称,xy轴互换绘制的图像)
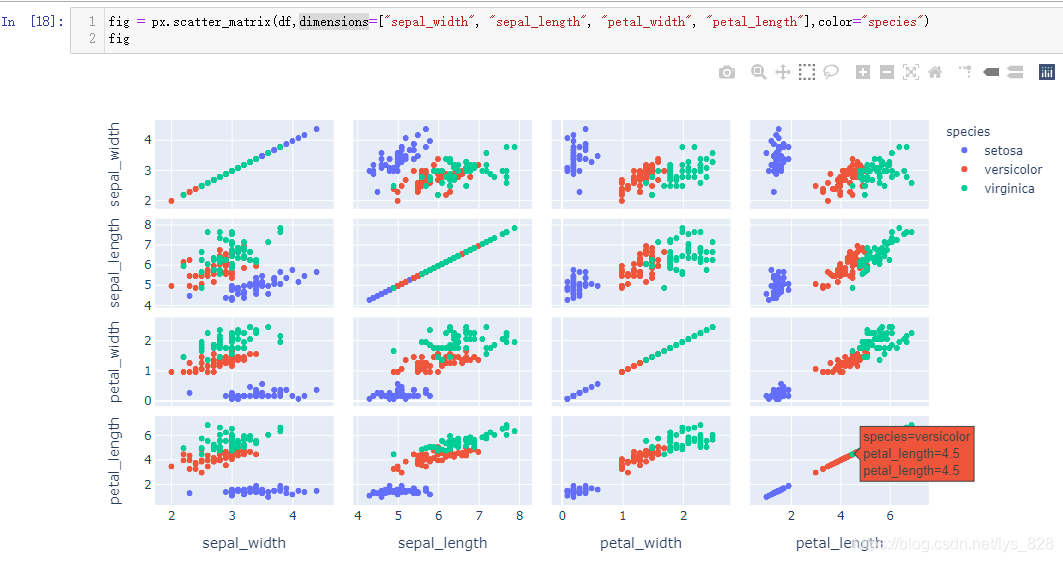
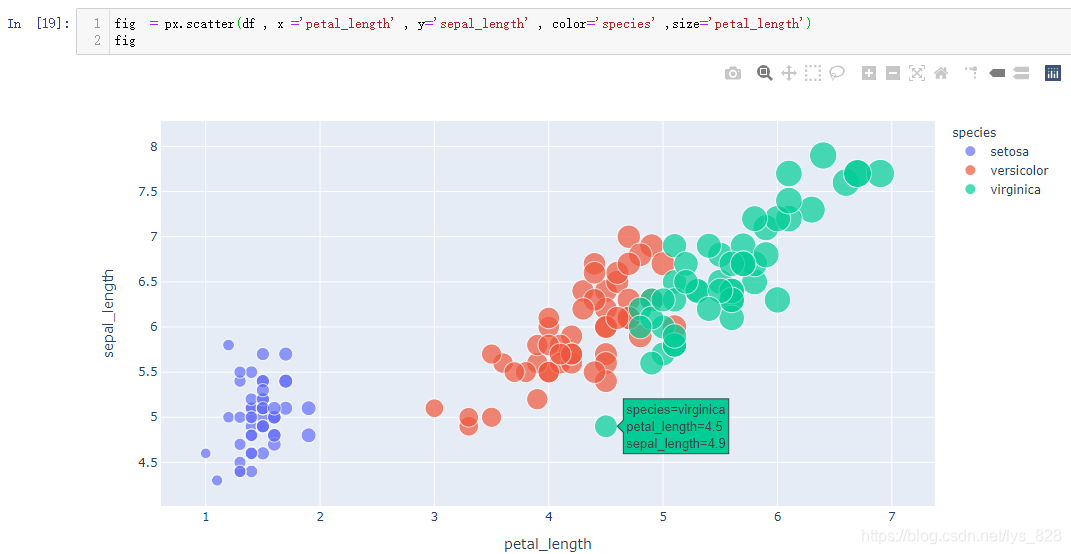
如果要更进一步查看具体某一个散点图,也可以使用当前模块下的scatter函数进行绘制
fig = px.scatter(df , x ='petal_length' , y='sepal_length' , color='species' ,size='petal_length')
fig
输出结果如下:(这个模块的绘图和Matplotlib的逻辑类似了)
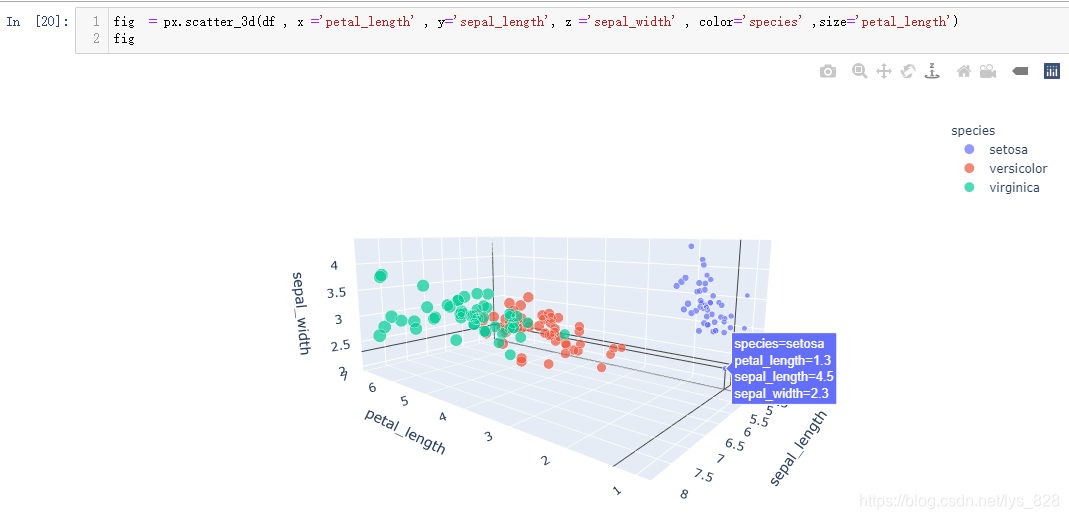
同时该模块也支持三维散点图,只需要将函数名进行修改后再添加一个字段维度即可
8.4 使用scatter_geo绘制地理散点图
核心代码:px.scatter_geo()
使用此方法的思想就是之前pandas中的merge匹配的思想,首先要求给出的数据中必须要有一个公共的字段,且这个字段的地理信息字段,比如国家的简写,中国China对应CHN。
读取测试数据:2007年全球gdp数据
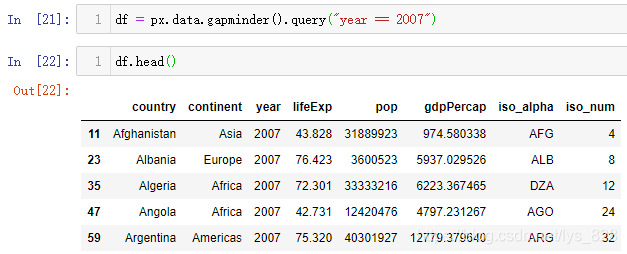
直接给出绘制的代码,结合图形和代码进行参数的理解
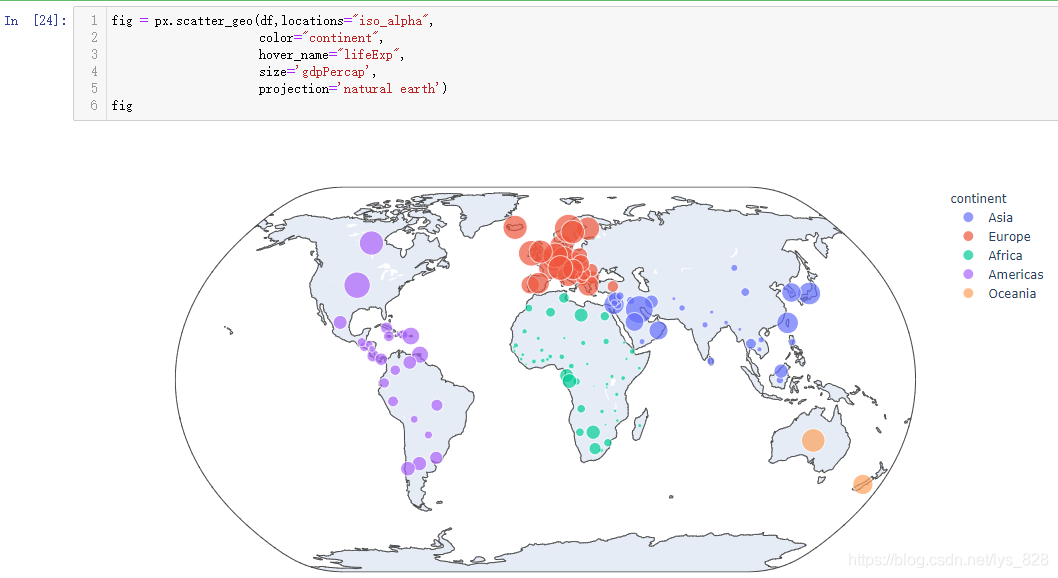
其中df就是给定的数据,location参数就是要指定的合并依据的地理信息字段,color和size参数用的多了就习惯了,hover_name就是交互时提示框显示的信息,就差最后一个参数project,这里就可以使用试错法,不知道这个参数到底应该怎么赋值,可以随便写一个或者猜一个单词
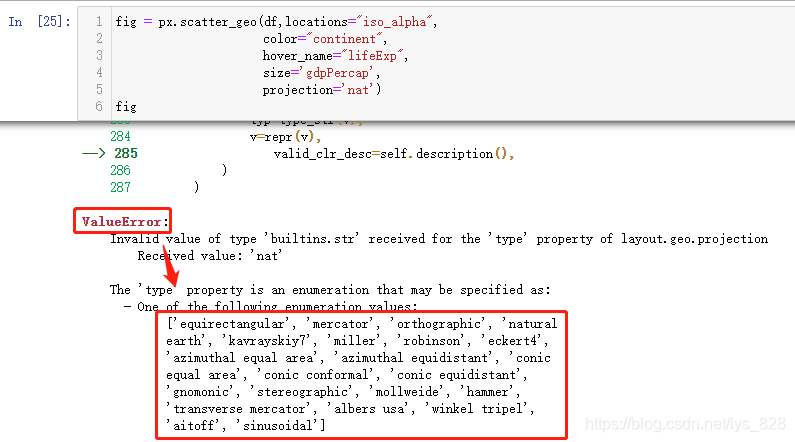
无巧不成书呀,这就是和之前进行stepmode参数测试的时候一样的结果。所以关于这部分赋值的内容不需要进行记忆,直接通过试错法运行结果就会有提醒,然后把提醒的内容复制粘贴到参数对应的位置,再次运行即可,比如选择一个equirectangular赋值对象,输出结果如下(由此可以发现这个参数是控制地图的展示样式,可以多测试一个赋值对象,根据自己的喜欢选择对应赋值对象)

至此关于plotly绘制图形的基础篇就介绍完毕,接下来介绍进阶篇,使用plotly进行地图和动态数据的绘制。完结,撒花✿✿ヽ(°▽°)ノ✿