BERT流程图
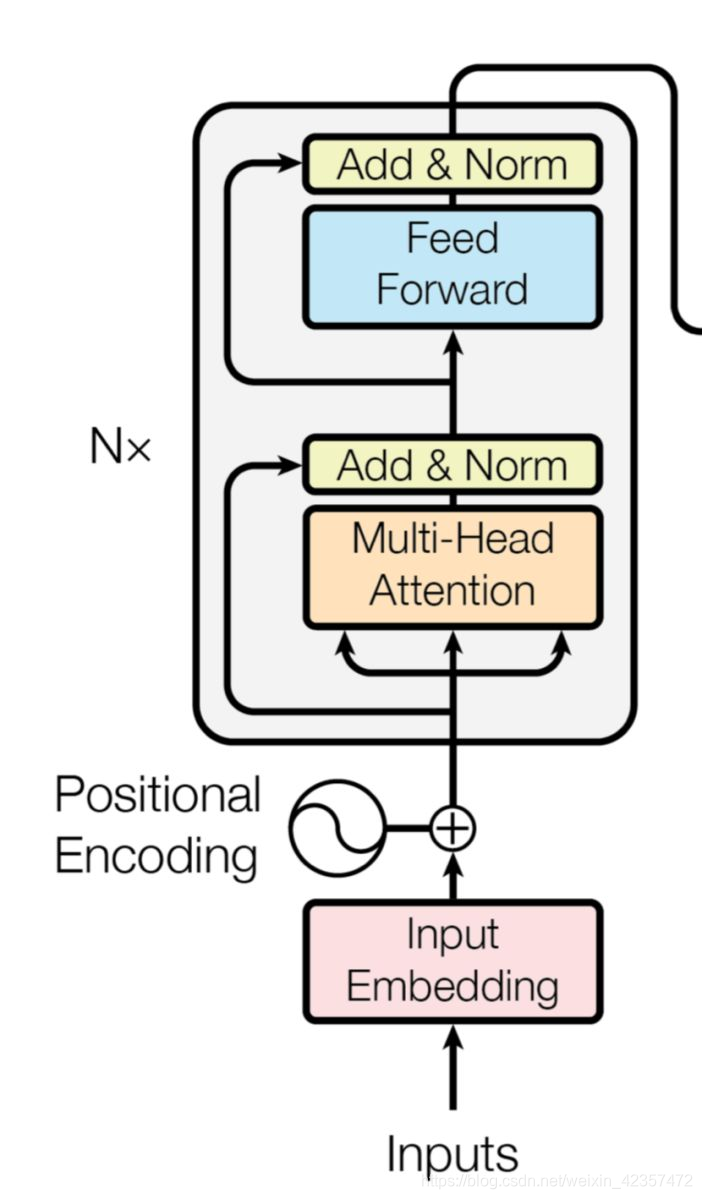
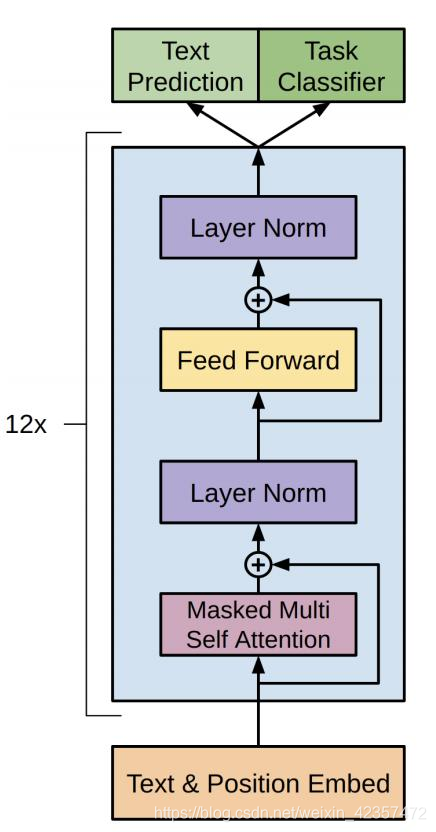
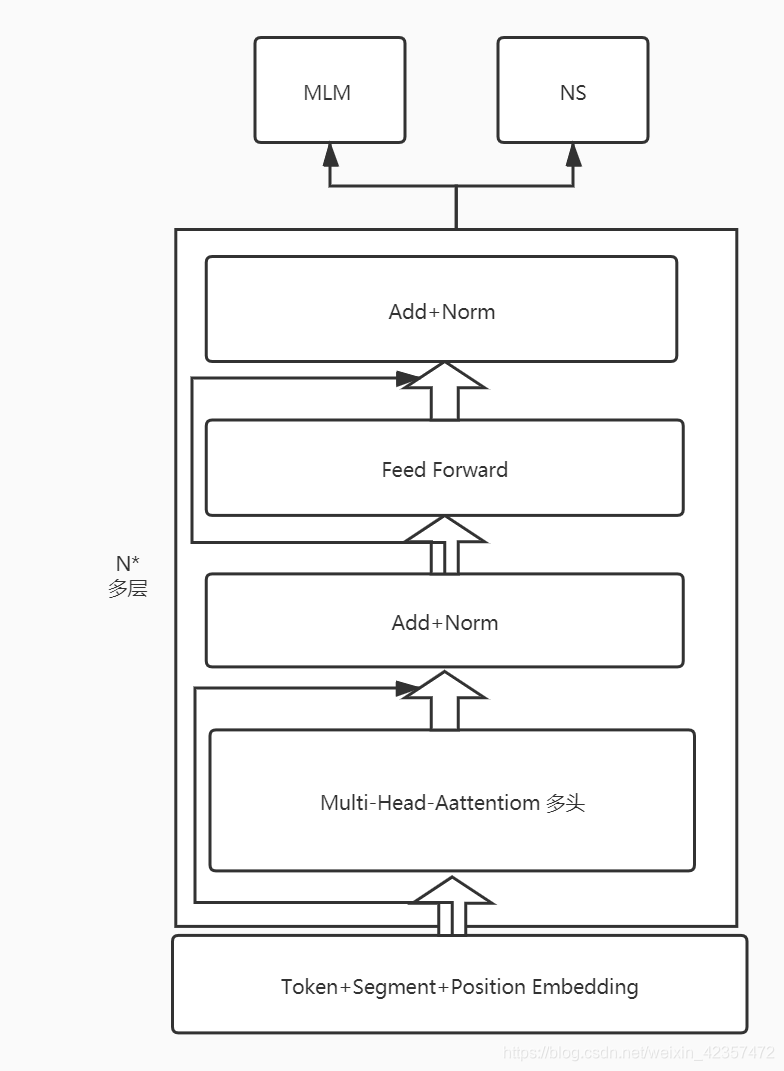
代码模块
代码参考:https://github.com/cmd23333/BERT-Tensorflow2.x
https://github.com/MorvanZhou/NLP-Tutorials
1、 损失函数模块
with tf.GradientTape() as t:
nsp_predict, mlm_predict, sequence_output = model((batch_x, batch_padding_mask, batch_segment),
training=True)
nsp_loss, mlm_loss = loss_fn((mlm_predict, batch_mlm_mask, origin_x, nsp_predict, batch_y))
nsp_loss = tf.reduce_mean(nsp_loss)
mlm_loss = tf.reduce_mean(mlm_loss)
loss = nsp_loss + mlm_loss
gradients = t.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
loss_fn函数
def call(self, inputs):
(mlm_predict, batch_mlm_mask, origin_x, nsp_predict, batch_y) = inputs
x_pred = tf.nn.softmax(mlm_predict, axis=-1)
mlm_loss = tf.keras.losses.sparse_categorical_crossentropy(origin_x, x_pred)
mlm_loss = tf.math.reduce_sum(mlm_loss * batch_mlm_mask, axis=-1) / (tf.math.reduce_sum(batch_mlm_mask, axis=-1) + 1)
y_pred = tf.nn.softmax(nsp_predict, axis=-1)
nsp_loss = tf.keras.losses.sparse_categorical_crossentropy(batch_y, y_pred)
return nsp_loss, mlm_loss
2、Bert主函数model
bertlayer层,多层上图所示N*叠加
def call(self, inputs, training=None):
batch_x, batch_mask, batch_segment = inputs
x = self.embedding((batch_x, batch_segment))
for i in range(self.num_transformer_layers):
x = self.transformer_blocks[i](x, mask=batch_mask, training=training)
first_token_tensor = x[:, 0, :] # [batch_size ,hidden_size]
nsp_predict = self.nsp_predictor(first_token_tensor)
mlm_predict = tf.matmul(x, self.embedding.token_embedding.embeddings, transpose_b=True)
sequence_output = x
return nsp_predict, mlm_predict, sequence_output
transformer_blocks模块,就是里面的多头自注意+layer norm+ffn
def call(self, x, mask, training=None):
attn_output = self.mha(x, mask) # (batch_size, input_seq_len, d_model)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2
mha函数就是具体多头自注意的实现
def scaled_dot_product_attention(q, k, v, mask):
"""计算注意力权重。
q, k, v 必须具有匹配的前置维度。
k, v 必须有匹配的倒数第二个维度,例如:seq_len_k = seq_len_v。
mask 必须能进行广播转换以便求和。
参数:
q: 请求的形状 == (..., seq_len_q, depth)
k: 主键的形状 == (..., seq_len_k, depth)
v: 数值的形状 == (..., seq_len_v, depth_v)
mask: Float 张量,其形状能转换成
(..., seq_len_q, seq_len_k)。默认为None。
返回值:
输出,注意力权重
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# 缩放 matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# 将 mask 加入到缩放的张量上。
if mask is not None:
scaled_attention_logits + (tf.cast(mask[:, tf.newaxis, tf.newaxis, :], dtype=tf.float32) * -1e9)
# softmax 在最后一个轴seq_len_k上归一化,因此分数相加等于1。
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights