农行知道问答系统
该项目是基于 hunggingface transformers BertSequenceClassification 模型, 使用BERT中文预训练模型,进行训练.
模型源码可以参考我的github: QABot
模型使用和结果
-
BERT 中文预训练模型和数据集可以从百度云盘下载
pytorch_model.bin 提取码: y7t6
其中, train.csv 和 dev.csv 是通过切分nonghangzhidao.csv得到的.
pytorch_model.bin是bert-base-chinese-pytorch_model.bin 重命名后的,因为transformers 从本地加载bert 预训练模型时,模型的名字必须时pytorch_model.bin,这个是由’file_utils.py’里面的 WEIGHTS_NAME=‘pytorch_model.bin’, 并且在modeling_utils.py中是寻找 path/pytorch_model.py 来加载预训练模型的.
请参考transformers 里面 file_utils.py 和 modeling_utils.py
file_utils.py## file_utils.py WEIGHTS_NAME = "pytorch_model.bin" TF2_WEIGHTS_NAME = 'tf_model.h5' TF_WEIGHTS_NAME = 'model.ckpt' CONFIG_NAME = "config.json"modeling_utils.py
## modeling_utils.py # Load from a PyTorch checkpoint archive_file = os.path.join(pretrained_model_name_or_path, WEIGHTS_NAME) -
模型运行命令:
python bert_main2.py \ --data_dir . \ ## 数据集的路径.我的train.csv和dev.csv都放到当前目录下了 --output_dir BERT2_output \ ## 输出结果的路径 --train_batch_size 4 \ --num_train_epochs 10 \ --max_seq_length 512 \ ##这个值可以调整 --warmup_steps 10 \ ## 这个值模型调优可以调,这个是learning rate 变化 --learning_rate 1e-6 \ ## 初始learning_rate,建议设置小一些,因为我用默认5e-5时,模型loss一路上升,acc 一路下降,估计模型已经飘了起来 --log_path lr1e6_epoch10_seq512_warm10 \ ## 这个是每次调参后保存的模型结果和train_loss_file.txt, eval_acc_file.txt,train_acc_file.txt. 方便后面对比 --model_dir cache_down \ --evaluate_during_training
运行参数和结果分析
1. epoch 10, learning_rate: 1e-6, warm_up:10, max_seq_len 512, weigth_decay 0.
python bert_main2.py \
--data_dir . \ ## 数据集的路径.我的train.csv和dev.csv都放到当前目录下了
--output_dir BERT2_output \ ## 输出结果的路径
--train_batch_size 4 \
--num_train_epochs 10 \
--max_seq_length 512 \ ##这个值可以调整
--warmup_steps 10 \ ## 这个值模型调优可以调,这个是learning rate 变化
--learning_rate 1e-6 \ ## 初始learning_rate,建议设置小一些,因为我用默认5e-5时,模型loss一路上升,acc 一路下降,估计模型已经飘了起来
--log_path lr1e6_epoch10_seq512_warm10 \ ## 这个是每次调参后保存的模型结果和train_loss_file.txt, eval_acc_file.txt,train_acc_file.txt. 方便后面对比
--model_dir cache_down \
--evaluate_during_training
运行结果 在训练集上:

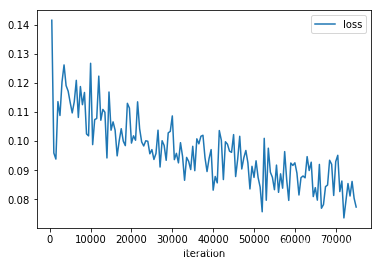
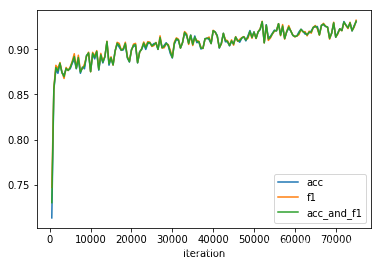
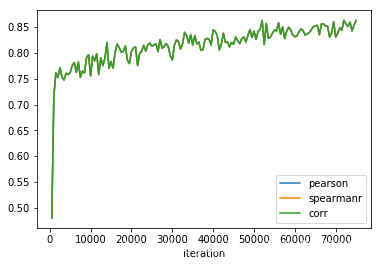
在验证集上:


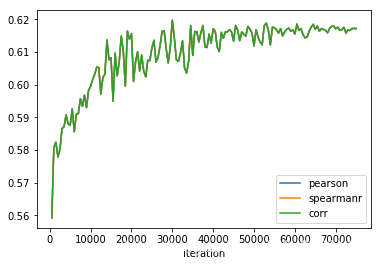
可以看出,模型在训练集上 acc 能达到96-97%, 在验证集上只有80%,且在验证集上loss几乎没有变化,怀疑模型有可能过拟合.
调整模型参数 查看运行结果:
调参步骤: 加大L2正则,就是weight decay. 查看运行效果.
2. epoch 10, learning_rate: 1e-5, warm_up:100, max_seq_len 512, weigth_decay 3e-4.
运行结果在训练集上:


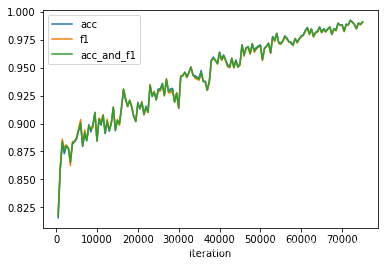
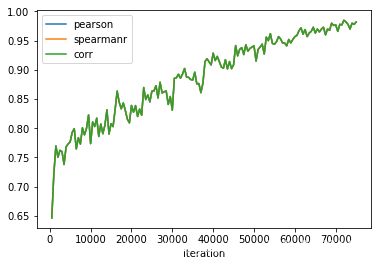
在验证集上:
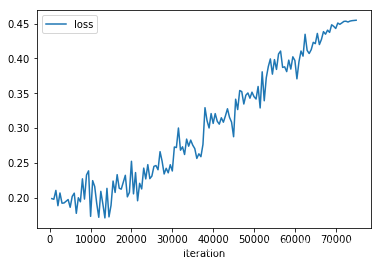
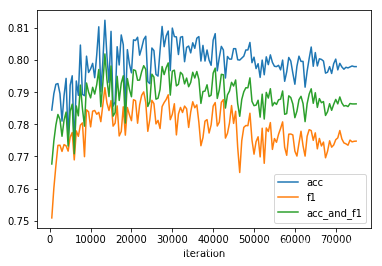

acc刚开始上升, 大概15000个iteration之后 开始 处于平稳. loss 则一直上升…
模型在验证集上最好的时候是: eval_loss:0.17111020261775256, result: {‘acc’: 0.8123730190979277, ‘f1’: 0.7914172783738002, ‘acc_and_f1’: 0.8018951487358639, ‘pearson’: 0.63346710015176, ‘spearmanr’: 0.6334671001517601, ‘corr’: 0.63346710015176}
3. 3个epoch, batch_size 4*32=128 seq_len:512, lr: 5e-5 用bert 预训练模型 batch_size 设置大一些时 不用更改默认的learning rate. 这里只是训练3个epoch 在验证集上 已经达到了80%的准确率. (前两次实验batch_size=4, 这一次将 gradient_accumulation_steps=32, batch_size=4,效果等价于 batch_size=128)
10/14/2019 19:45:49 - INFO - main - ***** Eval results update/output_update *****
10/14/2019 19:45:49 - INFO - main - acc = 0.8042462413652987
10/14/2019 19:45:49 - INFO - main - acc_and_f1 = 0.7944574597149434
10/14/2019 19:45:49 - INFO - main - corr = 0.620513225901862
10/14/2019 19:45:49 - INFO - main - f1 = 0.7846686780645883
10/14/2019 19:45:49 - INFO - main - pearson = 0.6205132259018619
10/14/2019 19:45:49 - INFO - main - spearmanr = 0.6205132259018621
模型代码
该代码参考run_glue.py. 稍微做了些调整
代码分为:
评估指标函数
数据处理函数 FAQProcessor
数据加载函数load_and_cache_examples
训练和验证函数 train 和 evaluation
主函数 main
代码如下:
import argparse
from collections import Counter
import code
import os
import logging
import random
from tqdm import tqdm, trange
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
from transformers import AdamW, WarmupLinearSchedule
from transformers import BertConfig, BertForSequenceClassification, BertTokenizer
from transformers import glue_convert_examples_to_features as convert_examples_to_features
from transformers.data.processors.utils import DataProcessor, InputExample
import numpy as np
import pandas as pd
from scipy.stats import pearsonr, spearmanr
from sklearn.metrics import matthews_corrcoef, f1_score
logger = logging.getLogger(__name__)
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
def simple_accuracy(preds, labels):
return (preds == labels).mean()
def acc_and_f1(preds, labels):
acc = simple_accuracy(preds, labels)
f1 = f1_score(y_true=labels, y_pred=preds)
return {
"acc": acc,
"f1": f1,
"acc_and_f1": (acc + f1) / 2,
}
def pearson_and_spearman(preds, labels):
pearson_corr = pearsonr(preds, labels)[0]
spearman_corr = spearmanr(preds, labels)[0]
return {
"pearson": pearson_corr,
"spearmanr": spearman_corr,
"corr": (pearson_corr + spearman_corr) / 2,
}
def acc_f1_pea_spea(preds, labels):
acc_f1 = acc_and_f1(preds, labels)
pea_spea = pearson_and_spearman(preds,labels)
return {**acc_f1, **pea_spea}
class FAQProcessor(DataProcessor):
def get_train_examples(self, data_dir):
return self._create_examples(os.path.join(data_dir, 'train.csv'))
def get_dev_examples(self, data_dir):
return self._create_examples(os.path.join(data_dir, 'dev.csv'))
def get_labels(self):
return [0, 1]
def _create_examples(self, path):
df = pd.read_csv(path)
examples = []
titles = [str(t) for t in df['title'].tolist()]
replies = [str(t) for t in df['reply'].tolist()]
labels = df['is_best'].astype('int').tolist()
for i in range(len(labels)):
examples.append(
InputExample(guid=i, text_a=titles[i], text_b=replies[i], label=labels[i]))
return examples
def train(args, train_dataset, model, tokenizer):
train_sampler = RandomSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps //(len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
no_decay = ['bias', 'LayerNorm.weight']
## any((True, False, False)) 只要一个为True, 结果就为True,
## if not any() ->没有一个为True. nd in n for nd in ['bias','LayerNorm.weight']->表示 parameter 不是'bias','weight'
## 所以下面第一个是 非 bias,weight的parameters, 第二个只有bias, weight的parameters
## 对于非bias,LayerNorm.weight 的parameters, weight_decay 值为args.weight_decay
## 对于 bias, LayerNorm.weight 的parameters, weight_decay 值为0
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
'weight_decay': args.weight_decay},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = WarmupLinearSchedule(optimizer, warmup_steps=args.warmup_steps, t_total=t_total)
logger.info('*****Running training*******')
logger.info(' Num examples = %d', len(train_dataset))
logger.info(' Num epochs = %d', args.num_train_epochs)
logger.info(' Gradient Accumulation steps = %d', args.gradient_accumulation_steps)
logger.info(' Total optimization steps = %d', t_total)
global_step = 0
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = trange(int(args.num_train_epochs), desc='Epoch')
set_seed(args)
preds, logging_preds = None, None
out_label_ids, logging_out_label_ids = None, None
best_acc_f1 = 0.0
train_loss_file = os.path.join(args.output_dir, args.log_path, 'train_loss_file.txt')
eval_acc_file = os.path.join(args.output_dir, args.log_path, 'eval_acc_file.txt')
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc='Iteration')
for step, batch in enumerate(epoch_iterator):
model.train()
batch = tuple(t.to(args.device) for t in batch)
inputs = {'input_ids': batch[0], 'attention_mask': batch[1], 'token_type_ids': batch[2], 'labels': batch[3]}
outputs = model(**inputs)
loss, logits = outputs[:2] ## crossEntropy loss. outputs: (loss), logits, (hidden_states), (attentions)
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
tr_loss += loss.item()
logging_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step() # update learning rate schedule
model.zero_grad()
global_step += 1
if preds is None:
preds = logits.detach().cpu().numpy()
else:
preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
if out_label_ids is None:
out_label_ids = inputs['labels'].detach().cpu().numpy()
else:
out_label_ids = np.append(out_label_ids, inputs['labels'].detach().cpu().numpy(), axis=0)
if logging_preds is None:
logging_preds = logits.detach().cpu().numpy()
else:
logging_preds = np.append(logging_preds, logits.detach().cpu().numpy(), axis=0)
if logging_out_label_ids is None:
logging_out_label_ids = inputs['labels'].detach().cpu().numpy()
else:
logging_out_label_ids = np.append(logging_out_label_ids, inputs['labels'].detach().cpu().numpy(), axis=0)
if global_step % args.logging_steps == 0:
results = acc_f1_pea_spea(np.argmax(logging_preds, axis=1), logging_out_label_ids)
with open(train_loss_file, 'a+') as writer:
writer.write("iteration: {}, lr: {}, loss: {}, results:{}\n".format(global_step, scheduler.get_lr()[0],
logging_loss/(args.logging_steps * args.train_batch_size * args.gradient_accumulation_steps), results))
logging_loss = 0.0
logging_preds = None
logging_out_label_ids = None
# code.interact(local=locals())
if args.evaluate_during_training:
eval_dataset = load_and_cache_examples(args, tokenizer, evaluate=True)
results = evaluate(args, eval_dataset, model, args.device, tokenizer)
with open(eval_acc_file, 'a+') as eval_writer:
eval_writer.write('iteration:{}, lr: {}, eval_loss:{}, result: {}\n'.format(global_step, scheduler.get_lr()[0],results[0], results[1]))
if results[1]['acc_and_f1'] > best_acc_f1:
best_acc_f1 = results[1]['acc_and_f1']
print('saving best model')
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(os.path.join(args.output_dir, args.log_path))
tokenizer.save_pretrained(os.path.join(args.output_dir, args.log_path))
torch.save(args, os.path.join(args.output_dir, args.log_path, 'training_args_bert.bin'))
def evaluate(args, eval_dataset, model, device, tokenizer):
model.eval()
eval_sampler = RandomSampler(eval_dataset)
eval_dataloader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=args.train_batch_size)
tr_loss = 0.0
global_step = 0
preds = None
out_label_ids = None
epoch_iterator = tqdm(eval_dataloader, desc='Iteration')
with torch.no_grad():
for step, batch in enumerate(epoch_iterator):
batch = tuple(t.to(args.device) for t in batch)
inputs = {'input_ids': batch[0], 'attention_mask': batch[1], 'token_type_ids': batch[2], 'labels': batch[3]}
# if step == 0:
# print(inputs)
outputs = model(**inputs)
loss, logits = outputs[:2]
batch_preds = None
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
tr_loss += loss.item()
global_step += 1
batch_preds = logits.detach().cpu().numpy()
batch_out_label_ids = inputs['labels'].detach().cpu().numpy()
if preds is None:
preds = batch_preds
else:
preds = np.append(preds, batch_preds, axis=0)
if out_label_ids is None:
out_label_ids = batch_out_label_ids
else:
out_label_ids = np.append(out_label_ids, inputs['labels'].detach().cpu().numpy(), axis=0)
total_loss = tr_loss / (global_step * args.train_batch_size)
print("iteration: {}, loss: {}".format(global_step, total_loss))
preds = np.argmax(preds, axis=1)
results = acc_f1_pea_spea(preds, out_label_ids)
print(total_loss, results)
return (total_loss,results)
def load_and_cache_examples(args, tokenizer, evaluate=False):
processor = FAQProcessor()
cached_features_file = "cached_{}_bert".format("dev" if evaluate else 'train')
if os.path.exists(cached_features_file):
features = torch.load(cached_features_file)
else:
label_list = processor.get_labels()
examples = processor.get_dev_examples(args.data_dir) if evaluate else processor.get_train_examples(args.data_dir)
# print(len(examples))
features = convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_length=args.max_seq_length,
label_list=label_list,
output_mode='classification',
pad_on_left=False,
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
pad_token_segment_id=0)
logger.info('saving features into cached file %s', cached_features_file)
torch.save(features, cached_features_file)
'''
InputExample:
self.guid = guid
self.text_a = text_a
self.text_b = text_b
self.label = label
InputFeatures:
self.input_ids = input_ids
self.attention_mask = attention_mask
self.token_type_ids = token_type_ids
self.label = label
features.append(
InputFeatures(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
label=label))
'''
## convert tensors and build dataset
all_input_ids = torch.tensor([f.input_ids for f in features],dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
all_label = torch.tensor([f.label for f in features], dtype=torch.long)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_label)
return dataset
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--seed', type=int, default=42,
help="random seed for initialization")
parser.add_argument("--data_dir", default=None, type=str, required=True,
help="directory containing the data")
parser.add_argument("--output_dir", default="BERT_output", type=str, required=True,
help="The model output save dir")
parser.add_argument("--do_train", action='store_true', help="Whether to run training.")
parser.add_argument("--do_eval", action='store_true', help="Whether to run eval on the dev set.")
parser.add_argument("--evaluate_during_training", action='store_true',
help="Run evaluation during training at each logging step.")
parser.add_argument("--max_seq_length", default=100, type=int, required=False,
help="maximum sequence length for BERT sequence classificatio")
parser.add_argument("--max_steps", default=-1, type=int,
help="If > 0: set total number of training steps to perform. Override num_train_epochs.")
parser.add_argument("--warmup_steps", default=0, type=int,
help="Linear warmup over warmup_steps.")
parser.add_argument('--gradient_accumulation_steps', type=int, default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.")
parser.add_argument("--num_train_epochs", default=3, type=int,
help="Total number of training epochs to perform.")
parser.add_argument("--learning_rate", default=1e-5, type=float,
help="The initial learning rate for Adam.")
parser.add_argument("--weight_decay", default=0.0, type=float,
help="Weight deay if we apply some.")
parser.add_argument("--max_grad_norm", default=1.0, type=float,
help="Max gradient norm.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float,
help="Epsilon for Adam optimizer.")
parser.add_argument("--train_batch_size", default=64, type=int, required=False,
help="batch size for train and eval")
parser.add_argument('--logging_steps', type=int, default=500,
help="Log every X updates steps.")
parser.add_argument('--log_path', default=None, type=str, required=False)
parser.add_argument('--model_dir', default=None, type=str, required=False)
args = parser.parse_args()
logging.basicConfig(format = '%(asctime)s - %(levelname)s - %(name)s - %(message)s',
datefmt = '%m/%d/%Y %H:%M:%S',
level = logging.INFO)
set_seed(args)
## get train and dev data
print('loading dataset...')
processor = FAQProcessor()
label_list = processor.get_labels()
num_labels = len(label_list)
# config = BertConfig.from_pretrained('bert-base-chinese', cache_dir='./cache_down', num_labels=num_labels)
# tokenizer = BertTokenizer.from_pretrained('bert-base-chinese', cache_dir='./cache_down',do_lower_case=True, tokenize_chinese_chars=True)
#'BERT2_output/lr1e6_epoch5_seq512_warm1/'
config = BertConfig.from_pretrained(args.model_dir, num_labels=num_labels)
tokenizer = BertTokenizer.from_pretrained(args.model_dir,do_lower_case=True, tokenize_chinese_chars=True)
train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False)
#
## 构建模型
model = BertForSequenceClassification.from_pretrained(os.path.join(args.model_dir, 'pytorch_model.bin'), config=config)
# model = BertForSequenceClassification.from_pretrained("./cache_down/pytorch_model.bin", config=config)
args.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(args.device)
if not os.path.exists(os.path.join(args.output_dir, args.log_path)):
os.makedirs(os.path.join(args.output_dir, args.log_path))
train(args, train_dataset, model, tokenizer)
# evaluate on best model
config = BertConfig.from_pretrained(os.path.join(args.output_dir, args.log_path), num_labels=num_labels)
tokenizer = BertTokenizer.from_pretrained(os.path.join(args.output_dir, args.log_path),do_lower_case=True, tokenize_chinese_chars=True)
model = BertForSequenceClassification.from_pretrained(os.path.join(args.output_dir, args.log_path, 'pytorch_model.bin'), config=config)
args.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(args.device)
eval_dataset = load_and_cache_examples(args, tokenizer, evaluate=True)
results = evaluate(args, eval_dataset, model, args.device, tokenizer)
print('eval_loss:{}, result: {}\n'.format(results[0], results[1]))
if __name__== "__main__":
main()
