Bert-用于文本分类
Github包含代码
之前在做文本分类任务,源于CCFBDCI汽车行业用户观点主题及情感识别任务,数据集(只有9000多的短文本)在Github上(README)可以下载。在这个数据集上用过TF-IDF特征、RNN还有Bert词向量+RNN(在自己设置的验证集上提高了3个点),可惜的是Bert词向量加RNN效果在官网提交的结果并没有提升。
但是在另一个数据集上,清华的新浪新闻数据集(十类各取了5000个文档级别的语料)上,效果直接从91.95%提升到93.59%(双向+Attention)以及97%(Bert词向量)。所以在汽车行业用户观点主题及情感识别任务上可能是由于数据集的问题,使得Bert词向量没有很好的提升,关于这点,也欢迎各位评论探讨原因。
下面就介绍一下该任务。
- 用户对汽车的相关内容文本数据的评论作为训练集,对文本内容中的讨论主题进行提取
- 分析用户对所讨论主题的偏好
数据集
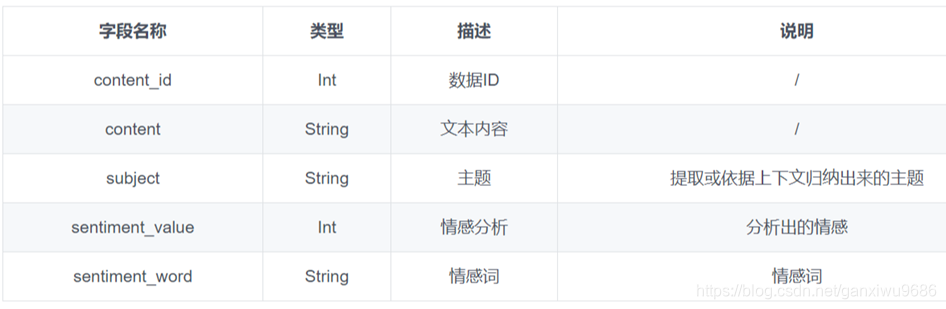

- 训练集数据中主题被分为10类,包括:动力、价格、内饰、配置、安全性、外观、操控、油耗、空间、舒适性。
- 情感分为3类,分别用数字0、1、-1表示中立、正向、负向。
- 情感词不作为评分依据。
- 训练9948条,测试集2364条。
TDIDF这个特征在这里就不多说了,大家感兴趣可以自行查找。
RNN模型
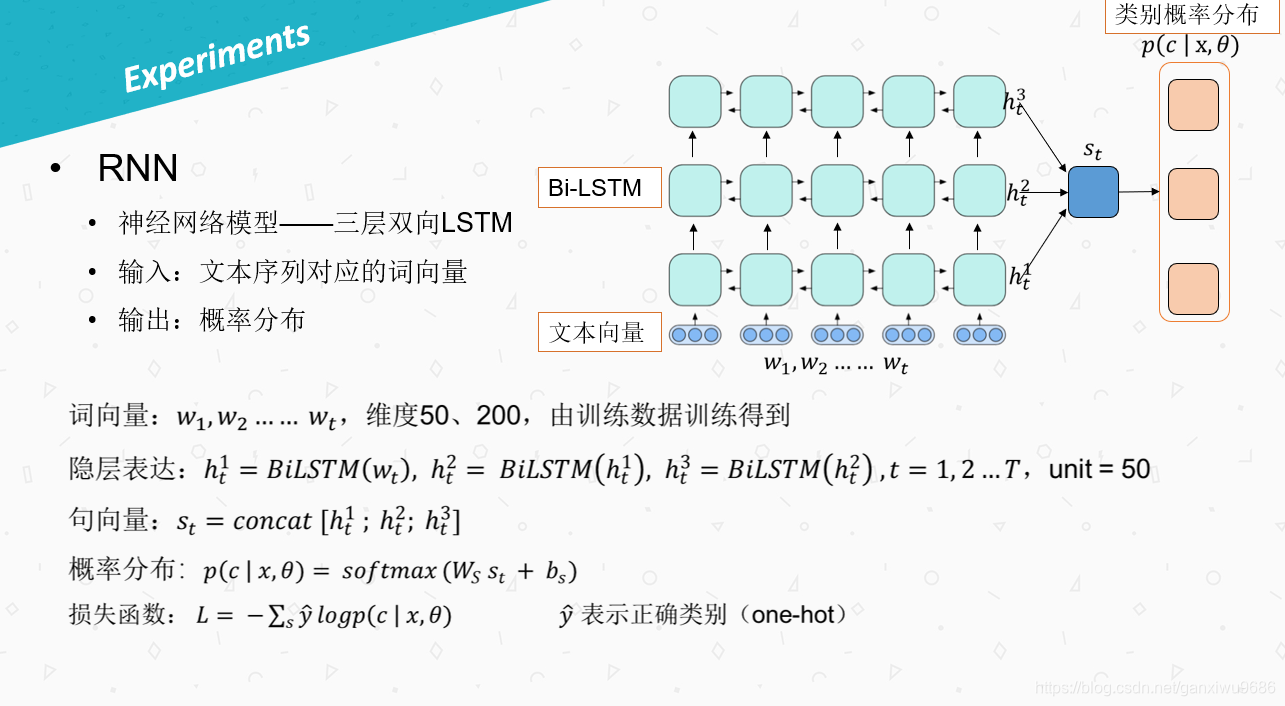
最后训练得到的效果见下图:
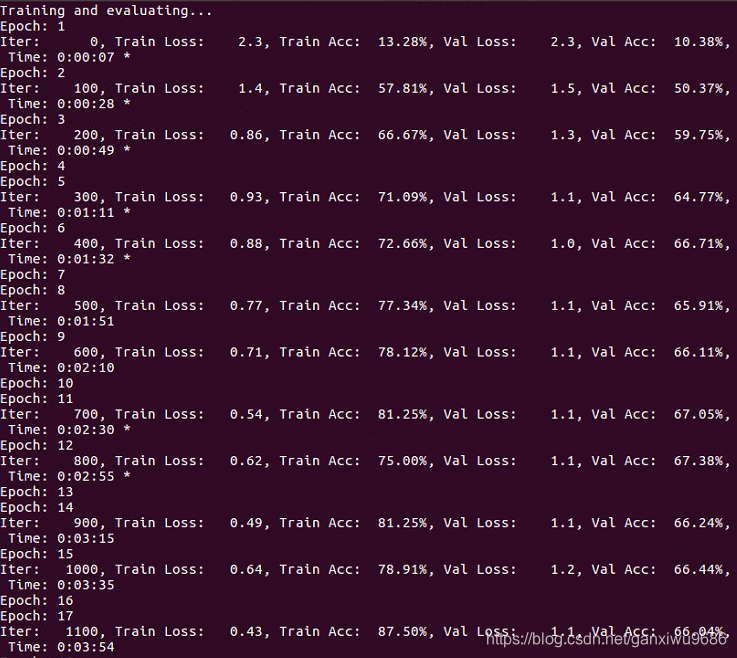
可以看到到迭代到12轮左右的时候测试集的效果最好能够达到67%,下面引入Bert词向量,我们直接用Bert的词向量作为模型的输入,不微调。
Bert模型
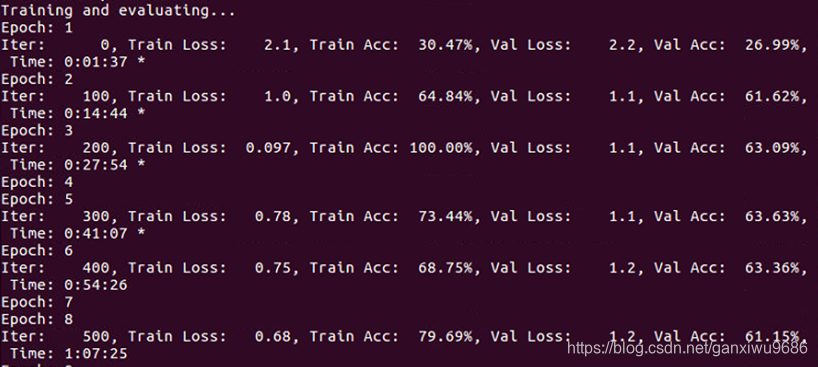
1、直接用Bert的句向量+分类器(不微调),效果不是很好,见下图。但是收敛比较快,说明词向量确实是学习到了先验知识。
2、换成词向量,网络结构和RNN模型一致。这里的Bert模型引用了腾讯AI-Han Xiao博士的github,附上链接。可以看到模型在第六轮就收敛了,而且验证集的精度也提升了。可是把结果提交到官网的时候,分数和RNN的差不多,很奇怪。
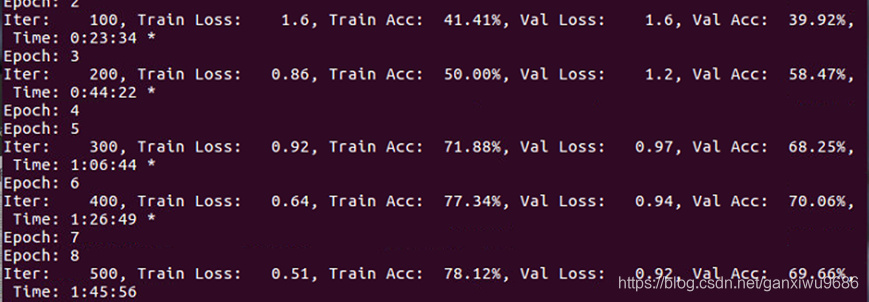
最后在Github链接下有清华新浪新闻数据集的实现,效果可以提升至97%,但是训练速度很慢,八个小时才跑了300轮,batch_size设置的64,也就是说只跑了2w(乱序)的数据集(有5w),连一个epoch都没有跑到,但是效果已经很好了,还有一个缺点就是迭代300轮时腾讯AI-Han Xiao博士服务器就断了。下一步就是考虑不用服务器客户端的方式,直接用google的特征抽取,这样就不用担心服务器会断了,另外如何进行微调也是一个需要研究的地方。
博客如果有借鉴之处没有指出,或者有错误,欢迎大家批评指正,谢谢!