参考博文:人体姿态项目的一个博客
https://learnopencv.com/deep-learning-based-human-pose-estimation-using-opencv-cpp-python/
参考github连接:
https://github.com/spmallick/learnopencv/tree/master/OpenPose
本项目实现:
1.single 单人图像的姿态扫描
2.single 单人视频的姿态识别
插播一个有意思的哔哩哔哩视频:https://www.bilibili.com/video/BV1fW411N7nf?spm_id_from=333.999.0.0
极乐净土多人体姿态识别
运行项目我们即将看到如何在 OpenCV 中加载训练好的模型并检查输出。我们将讨论仅用于单人姿势估计的代码,以保持简单,输出由置信度图和亲和力图组成。
项目链接:https://pan.baidu.com/s/13zTTzhNdO7HGp5SO4kHbHQ
提取码:9s5z
项目步骤
1.下载模型
a,可以在百度网盘进行下载

b,可以翻墙的用户也可以:
在ubantu系统建立 getModels.sh的文本,文本内容为
# ------------------------- BODY KEYPOINT-DETECTION MODELS -------------------------
# Downloading body pose (COCO)
OPENPOSE_URL="https://www.dropbox.com/s/2h2bv29a130sgrk/pose_iter_440000.caffemodel"
OPENPOSE_FOLDER="pose/coco/"
wget -c ${
OPENPOSE_URL} -P ${
OPENPOSE_FOLDER}
然后右键打开终端输入 。。。 进行下载
sudo chmod a+x getModels.sh
./getModels.sh
c,在资源下载
https://download.csdn.net/download/qq_43033547/29961279
2,建立文件夹
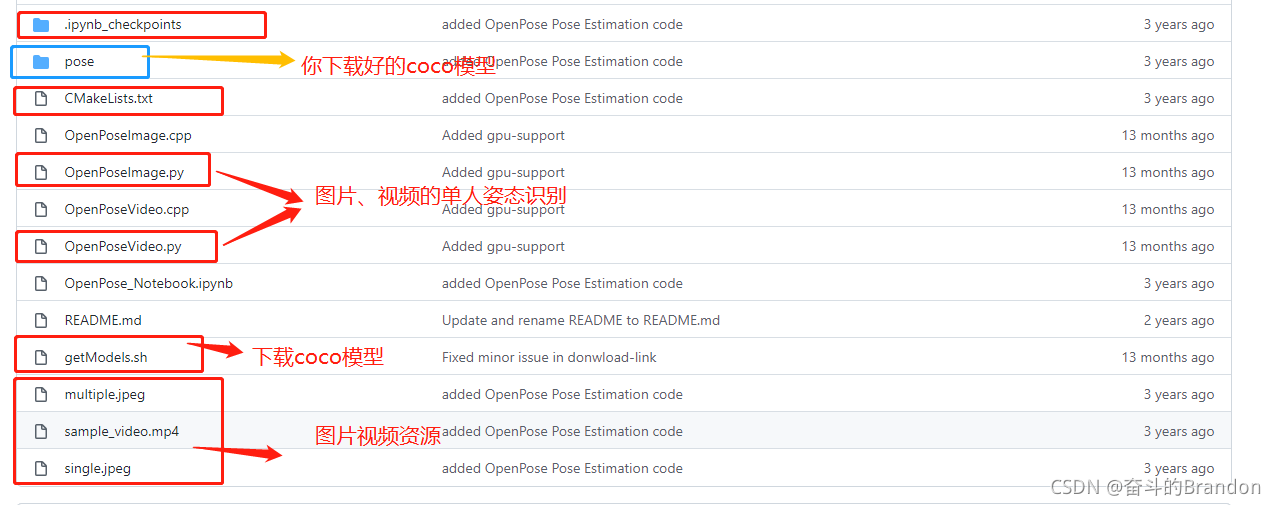
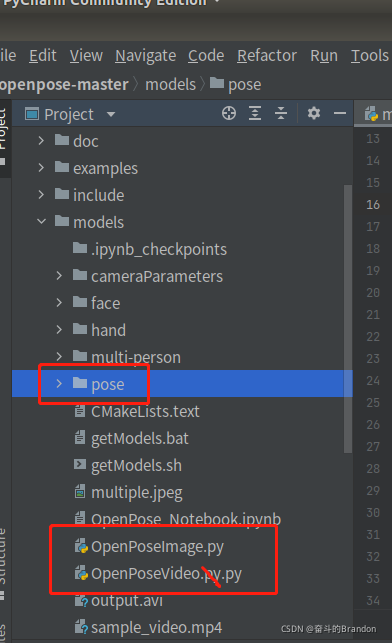
3,在ubantu中打开pycharm,打开opencv这个项目,然后运行那两个.py文件
4,效果

视频效果微信扫描查看:

5,说明
加载网络
# Specify the paths for the 2 files
protoFile = "pose/mpi/pose_deploy_linevec_faster_4_stages.prototxt"
weightsFile = "pose/mpi/pose_iter_160000.caffemodel"
# Read the network into Memory
net = cv2.dnn.readNetFromCaffe(protoFile, weightsFile)
.prototxt 文件,它指定了神经网络的架构——不同层的排列方式等。
.caffemodel 文件,用于存储训练模型的权重
读取图像并准备网络输入
我们使用 OpenCV 读取的输入帧应转换为输入 blob(如 Caffe),以便将其馈送到网络。这是使用 blobFromImage 函数完成的,该函数将图像从 OpenCV 格式转换为 Caffe blob 格式。这些参数将在 blobFromImage 函数中提供。首先,我们将像素值归一化为 (0,1)。然后我们指定图像的尺寸。接下来,要减去的平均值,即 (0,0,0)。由于 OpenCV 和 Caffe 都使用 BGR 格式,因此无需交换 R 和 B 通道
# Read image
frame = cv2.imread("single.jpg")
# Specify the input image dimensions
inWidth = 368
inHeight = 368
# Prepare the frame to be fed to the network
inpBlob = cv2.dnn.blobFromImage(frame, 1.0 / 255, (inWidth, inHeight), (0, 0, 0), swapRB=False, crop=False)
# Set the prepared object as the input blob of the network
net.setInput(inpBlob)
进行预测并解析关键点
output = net.forward()
输出是一个 4D 矩阵:
第一个维度是图像 ID(以防您将多个图像传递给网络)。
第二个维度表示关键点的索引。该模型生成置信度图和部件亲和度图,它们都是串联的。对于 COCO 模型,它由 57 个部分组成 – 18 个关键点置信度图 + 1 个背景 + 19*2 部分 Affinity Maps。
同样,对于 MPI,它产生 44 个点。我们将仅使用与关键点相对应的前几个点。
第三个维度是输出地图的高度。
第四个维度是输出图的宽度。
我们检查图像中是否存在每个关键点。我们通过找到该关键点的置信度图的最大值来获得关键点的位置。我们还使用阈值来减少错误检测。
一旦检测到关键点,我们只需将它们绘制在图像上。
H = output.shape[2]
W = output.shape[3]
# Empty list to store the detected keypoints
points = []
for i in range(nPoints):
# confidence map of corresponding body's part.
probMap = output[0, i, :, :]
# Find global maxima of the probMap.
minVal, prob, minLoc, point = cv2.minMaxLoc(probMap)
# Scale the point to fit on the original image
x = (frameWidth * point[0]) / W
y = (frameHeight * point[1]) / H
if prob > threshold :
cv2.circle(frameCopy, (int(x), int(y)), 8, (0, 255, 255), thickness=-1, lineType=cv2.FILLED)
cv2.putText(frameCopy, "{}".format(i), (int(x), int(y)), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2, lineType=cv2.LINE_AA)
# Add the point to the list if the probability is greater than the threshold
points.append((int(x), int(y)))
else :
points.append(None)
cv2.imshow('Output-Keypoints', frameCopy)
cv2.imwrite('Output-Keypoints.jpg', frameCopy)
cv2.waitKey(0)
绘制骨架
# Draw Skeleton
for pair in POSE_PAIRS:
partA = pair[0]
partB = pair[1]
if points[partA] and points[partB]:
cv2.line(frame, points[partA], points[partB], (0, 255, 255), 2)
cv2.circle(frame, points[partA], 8, (0, 0, 255), thickness=-1, lineType=cv2.FILLED)
cv2.imshow('Output-Skeleton', frame)
cv2.imwrite('Output-Skeleton.jpg', frame)
cv2.waitKey(0)