一、前言
人体姿态估计(Human Pose Estimation)是计算机视觉领域一个很重要的问题,解决这个问题是正确理解图像和视频中人类行为重要的一步。在此篇文章中,我将根据人体姿态估计技术的发展历程做一个简要的介绍。
二、定义
人体姿态估计技术用于解决标注图像和视频中人体关节点(如肩部、肘部、腕部等)的坐标。根据任务的特点不同,人体姿态估计可以分为二维(2D HPE)和三维(3D HPE);根据识别个体不同,可以分为单人姿态估计(Single-Person Pose Estimation)和多人姿态估计(Multi-Person Pose Estimation)。
1. 二维姿态估计(2D Pose Estimation)
此技术用于从一个RGB图像或视频中估计每个关节点的二维坐标(x, y)。
2. 三维姿态估计(3D Pose Estimation)
此技术用于从一个RGB图像或视频中估计每个关节点的二维坐标(x, y, z)。
3. 单人姿态估计(Single-Person Pose Estimation)
单人姿态估计输入是一个从图像中裁剪出的人体,然后在图像上标注出人体的各个关节点,如头部、肩部、肘部、腕部、膝盖、腿等。经过几年的算法提升,单人姿态估计目前已经能够达到较为出色的效果。
4. 多人姿态估计(Multi-Person Pose Estimation)
多人姿态估计的算法往往是以单人姿态估计算法为基础。多人姿态估计的输入是一张完整的图片,可能包含多个人体,其任务目的是将所有行人的关节点识别并标注出来。针对这一问题,一般有两种方法:自底向上——bottom-up和自顶向下——top-down。
对于自底向上方法,往往是先从图片中找出所有的关节点,如所有的腕部、脚踝等,然后将这些关节点一个个的组成一个行人,从而完成所有行人的关节点检测标注;而对于自顶向下方法,则恰恰相反,往往是先找出图片中的所有行人,然后对每个检测出的行人进行单人姿态估计,检测标注出每个行人的关节点。
5. 应用场景
人体姿态估计在动作识别、影视制作、体感游戏、人体定位等领域有着重要的应用背景。例如,使用姿态估计分析篮球运动员的移动和动作等。
5.1 动作识别
通过实时检测人体的动作,可以用于检测一个人是否摔倒、用于体育、舞蹈等领域的教学训练,用于理解肢体语言,用于智慧安防。
5.2 动作捕捉
通过检测出人体姿态,可以将图形、风格、特效等加载到人体上,推动增强现实领域的进步。
5.3 运动追踪
在交互游戏中追踪人体对象的运动,使用3D姿态估计来追踪人类玩家的运动,从而利用它来渲染虚拟人物的动作。
6. 技术难点
姿态估计至今仍面临一些技术难点,如很小到几乎看不见的关节点检测识别、灯光变化、衣物遮挡等。
三、技术方法
1. DeepPose
1.1 思想
DeepPose是第一篇将深度学习技术应用到人体姿态估计的论文。这一方法提出的时候,超越了之前未应用深度学习技术的所有方法。在此方法中,姿态估计被定义为基于卷积神经网络(CNN)的身体关节点回归问题。论文中通过使用级联CNN来提取姿态特征,以获得更好的效果。
1.2 模型
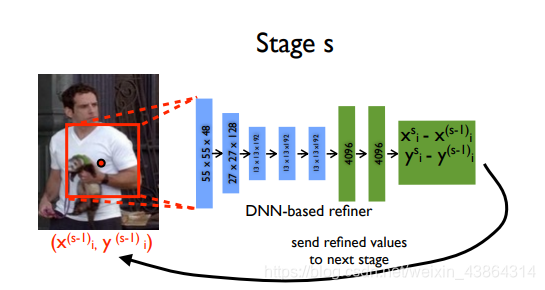
模型由7层AlexNet和一个输出层组成,输出层输出k个二维坐标(x, y),其中k是关节点数量。
此模型一个优越的思想是使用级联回归器对预测进行细化,这样初始图片中粗糙的姿态得到了改进,也就得到了更好的姿态估计效果。这一思想的原理是:图像在预测关节点附近被裁剪,然后作为下一个stage 的输入,这样下一个stage 的姿态回归器得到的就是更加精细的图像,因此能够学习到更佳范围的特征,最终得到更优的预测。
1.3 特点
- 将深度学习技术(CNN)应用到人体姿态估计中,因此出现了更多此方向的研究
- 回归到(x, y)坐标很困难,增加了学习复杂度,削弱了泛化能力,因此在某些领域表现不佳
2. Efficient Object Localization Using Convolutional Network
2.1思想
这种方法通过并行运行多个分辨率库中的图像来生成heatmap,以同时捕获各个比例的特征。输出是一个离散的heatmap,而不是连续的回归。heatmap预测关节点出现在每个像素点的概率。
2.2 模型
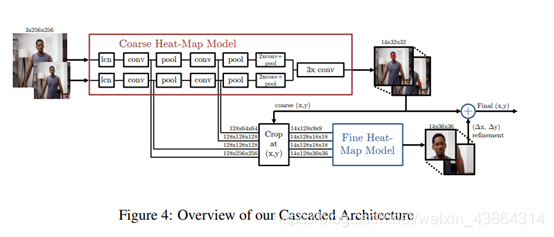
一个多分辨率的CNN架构(粗略heatmap模型)用于实现一个滑动窗口检测器来生成一个粗略的heatmap输出。论文的主要目的是恢复由于初始模型的池化而损失的空间精度。此模型通过使用额外的“姿势细化”卷积神经网络来细化粗略heatmap的定位结果。不同于标准的级联模型,此模型重新使用存在的卷积特征。这不仅减少了训练参数,还充当了粗略heatmap训练的调节器。
2.3 特点
- heatmap比直接的关节点回归效果好
- CNN和图形模型的联合使用
- 缺乏结构建模。二维人体姿势的空间高度结构化,如身体左右对称、关节点限制、物理连接等。对这种结构建模可以使得定位可见关节点更容易,使得估计被遮挡的关节点成为可能。
3. Convolutional Pose Machines
3.1 思想
此模型使用了一个叫姿态机(Pose Machine)的组件。姿态机由一个图像特征计算模块和预测模块组成。卷积姿态机(CPM)的多stage架构使得其能端到端训练。CPM的目的是学习长范围的空间关系,并且论文作者认为这一关系可由更大的感受野获得。
3.2 模型
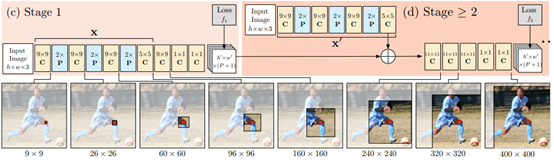
一个CPM模型由至少3个stage组成。stage1 是固定不变的,stage3及之后的stage是stage2的重复。stage2 将原始图像和stage1的heatmap输出作为输入。宏观层面上,CPM通过随后的stage不断地细化heatmap。
为了避免梯度消失的情况,CPM在每个stage之后使用中间监督,即每个stage都计算损失之loss,这解决了多stage 的深度神经网络的问题。
3.3 特点
- 提出了多stage的架构
- 在模型提出时达到了当时的最优效果
4. Human Pose Estimation with Iterative Error Feedback
4.1 思想
此模型的思想较为简洁,即预测当前姿态估计的错误在哪并迭代校正。不同于之前的模型直接预测输出,此模型使用一个自校正模型,通过反馈错误的预测来逐渐改变初始的预测结果,这一过程称为迭代错误反馈(IEF)。
4.2 模型
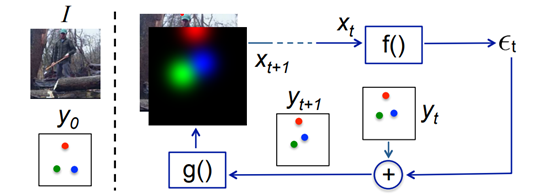
模型的输入由图像I和前一个的输出组成。因为此模型是迭代过程,相同的输出会逐步被细化。
模型主要有两个函数,f和g。f根据输入输出校正值x,这一结果和当前的输出y相加生成yt+1,g将其之中的所有关节点坐标转换未heatmap,因此每一步的输出都能够堆叠到原始的图像I上。这一过程重复T词知道足够细化关节点坐标。
4.3 特点
- 因为能够将原始图像和细化的校正信息作为输入,此模型能够在联合输入输出空间中提取关节点特征
- 引入的迭代校正训练的思想
5. Stacked Hourglass Networks for Human Pose Estimation
5.1 思想
这是一篇里程碑式的论文,它介绍了一种新颖且直观的架构,并击败了之前所有的模型方法。它之所以被称作堆叠沙漏网络(Stacked Hourglass Networks),是因为这一网络结构由一步步的池化和上采样层组成,这使得网络结构很像一个个沙漏堆叠起来。
沙漏结构的设计思想来源于捕获各个比例的信息的需求。人的方位,四肢的排列以及相邻关节的关系是在图像中不同比例下得到最佳识别的众多线索之一(更小的分辨率捕获更多的序列特征和全局context)。
5.2 模型
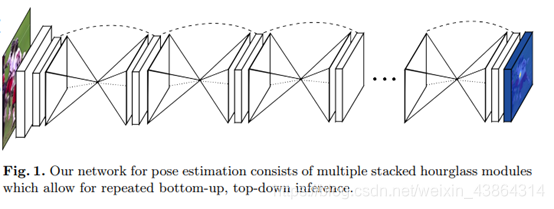
网络在中间监督下重复实现自底向上和自顶向下:
自底向上:从高分辨率到低分辨率
自顶向下:从低分辨率到高分辨率
网络通过使用跳跃连接(skip connection)来在每个分辨率下保留空间信息,并通过上采样向后传递。
在每个沙漏中,每个box不只是简单的卷积神经网络结构,而是能够提取更丰富特征的残差网络块。
5.3 特点
- 在每个比例捕获特征,通过这种方式,全局和局部特征和信息都被完全捕获,并通过网络进行学习进行预测
- 使用残差块而非传统卷积神经网络,能够提取更丰富的特征
- 模型更为简洁高效
6. Deep High-Resolution Representation Learning for Human Pose Estimation [HRNet]
6.1 思想
HRNet(High-Resolution Network)模型在关节点检测、多人姿态估计和单人姿态估计任务中比所有之前的方法模型表现得更为出色,并且是目前最优越的模型。HRNet采取了一个十分简单的思想。之前大多数论文都采取从高分辨率到低分辨率再到高分辨率表示的想法,而HRNet在整个过程中都始终维护一个高分辨率表征,这一想法效果很好。
6.2 模型
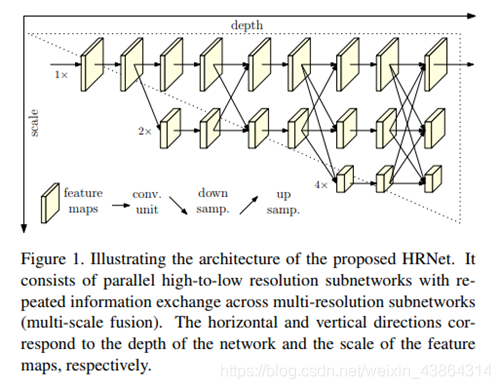
整个HRNet的架构从一个高分辨率的子网络开始,并以此作为stage 1。之后渐渐加入一个个从高分辨率到低分辨率的子网络来组成更多的stage并且并行连接多分辨率的子网络。
通过在整个过程中一遍又一遍地在并行多分辨率子网之间交换信息,可以进行重复的多尺度融合。并且在整个网络中,没有像Stacked Hourglass使用中间heatmap监督。在HRNet中,heatmap通过使用MSE损失函数进行回归。
6.3 特点
- 模型更为简洁直观
- 始终维护一个高分辨率
- 没有使用中间heatmap监督
