1 依赖和血缘关系
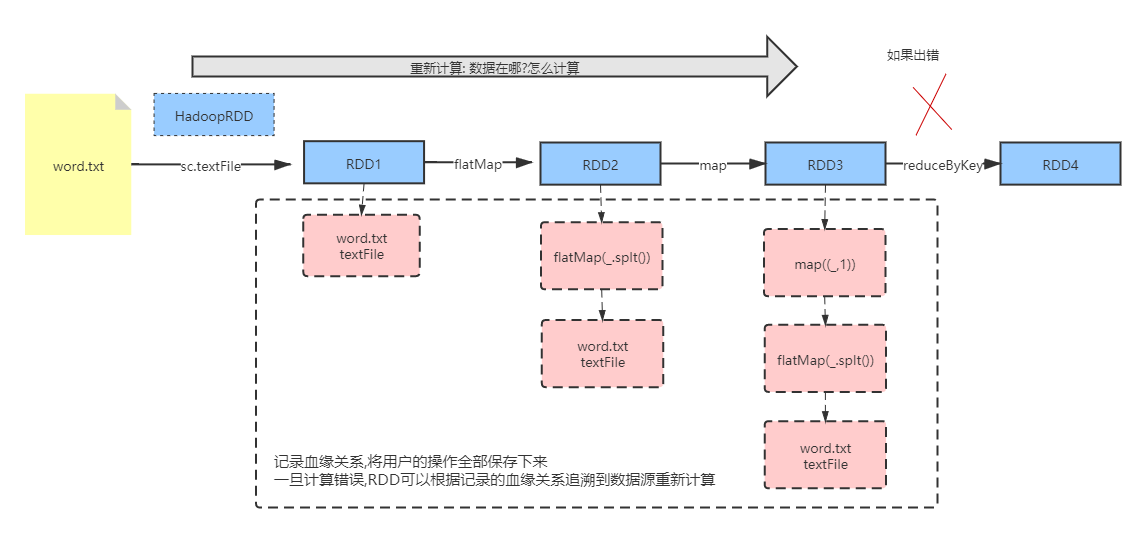
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。(由于RDD中是不记录数据的,为了实现分布式计算中的容错 , RDD必须记录RDD之间的血缘关系)
-
RDD之间的依赖关系
相邻的两个RDD之间的依赖关系就是RDD的依赖关系 , RDD之间的依赖关系有两种 一种是窄依赖,一种是宽依赖
- 展示依赖血缘关系
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
val rdd1: RDD[String] = sc.textFile("d://word.txt" , 1)
// dedug 打印RDD的依赖关心
println("rdd1:"+rdd1.toDebugString)
val rdd2: RDD[String] = rdd1.flatMap(_.split("\\s+"))
println("rdd2:"+rdd2.toDebugString)
val rdd3: RDD[(String, Int)] = rdd2.map((_, 1))
println("rdd3:"+rdd3.toDebugString)
val rdd4: RDD[(String, Int)] = rdd3.reduceByKey(_ + _)
println("rdd4:"+rdd4.toDebugString)
rdd4.collect()
sc.stop()
}rdd1:(1) d://word.txt MapPartitionsRDD[1] at textFile at WordCount.scala:15 []
| d://word.txt HadoopRDD[0] at textFile at WordCount.scala:15 []
rdd2:(1) MapPartitionsRDD[2] at flatMap at WordCount.scala:17 []
| d://word.txt MapPartitionsRDD[1] at textFile at WordCount.scala:15 []
| d://word.txt HadoopRDD[0] at textFile at WordCount.scala:15 []
rdd3:(1) MapPartitionsRDD[3] at map at WordCount.scala:19 []
| MapPartitionsRDD[2] at flatMap at WordCount.scala:17 []
| d://word.txt MapPartitionsRDD[1] at textFile at WordCount.scala:15 []
| d://word.txt HadoopRDD[0] at textFile at WordCount.scala:15 []
rdd4:(1) ShuffledRDD[4] at reduceByKey at WordCount.scala:21 []
+-(1) MapPartitionsRDD[3] at map at WordCount.scala:19 []
| MapPartitionsRDD[2] at flatMap at WordCount.scala:17 []
| d://word.txt MapPartitionsRDD[1] at textFile at WordCount.scala:15 []
| d://word.txt HadoopRDD[0] at textFile at WordCount.scala:15 []
Process finished with exit code 0
2 RDD依赖关系
1) 窄依赖
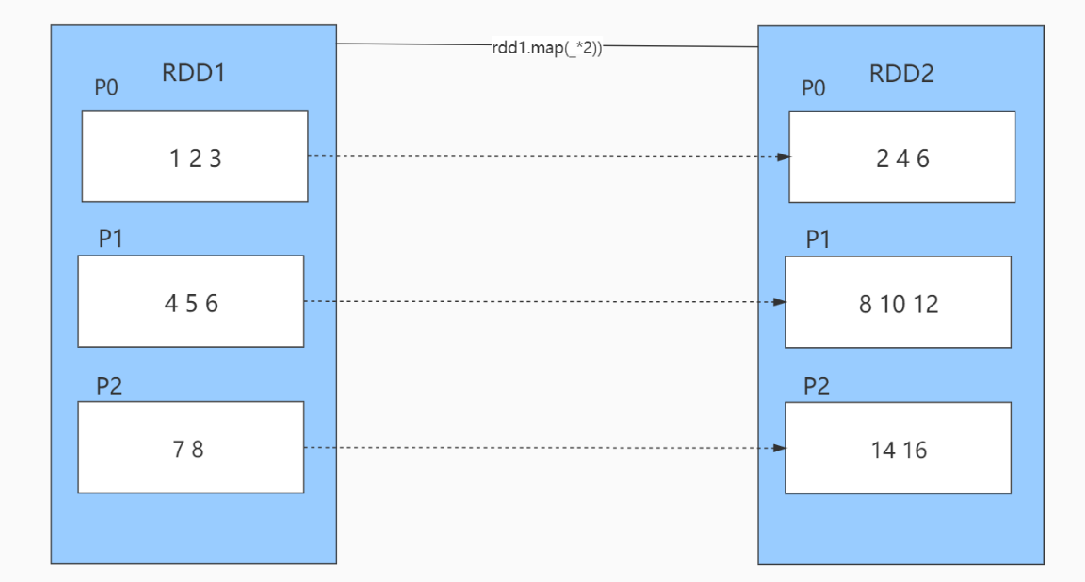
窄依赖:表示每一个父(上游)RDD 的Partition最多被子(下游)RDD的一个 Partition使用,,例如map、filter、union等操作都会产生窄依赖;
单RDD调用某些转换算子,前面RDD分区的数据还在一个分区中 , map() filter()等
- 从父RDD角度看:一个父RDD只被一个子RDD分区使用。父RDD的每个分区最多只能被一个Child RDD的一个分区使用
- 从子RDD角度看: 依赖上级RDD的部分分区,精确知道依赖的上级RDD分区,会选择和自己在同一节点的上级RDD分区,没有网络IO开销,高效。如map,flatmap,filter
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId)
}
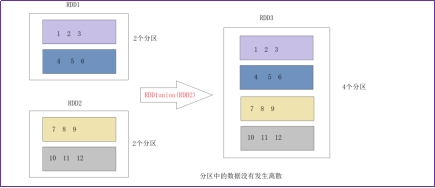
(RDD和RDD)调用某些算子 union() 算子 ,分区数量是两个RDD之和!
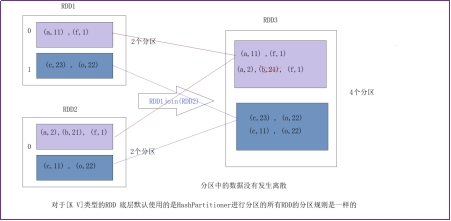
(RDD和RDD)调用某些算子 join() 算子 ,分区数量是两个RDD之和!
2) 宽依赖
宽依赖表示同一个父(上游》RDD 的Partition被多个子(下游)RDD的Partition依赖,会引起Shuffle ,:宽依赖我们形象的比喻为多生。例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖;发生了数据重新分发现象!
需要特别说明的是对join操作有两种情况:如果两个RDD在进行join操作时,一个RDD的partition仅仅和另一个RDD中已知个数的Partition进行join,那么这种类型的join操作就是窄依赖,例如图1中左半部分的join操作(join with inputs co-partitioned);其它情况的join操作就是宽依赖,例如图1中右半部分的join操作(join with inputs not co-partitioned),由于是需要父RDD的所有partition进行join的转换,这就涉及到了shuffle,因此这种类型的join操作也是宽依赖。
- 从父RDD角度看:一个父RDD被多个子RDD分区使用。父RDD的每个分区可以被多个Child RDD分区依赖
- 从子RDD角度看:依赖上级RDD的所有分区 无法精确定位依赖的上级RDD分区,相当于依赖所有分区(例如reduceByKey) 计算就涉及到节点间网络传输需要shuffle
@DeveloperApi
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false,
val shuffleWriterProcessor: ShuffleWriteProcessor = new ShuffleWriteProcessor)
extends Dependency[Product2[K, V]] {
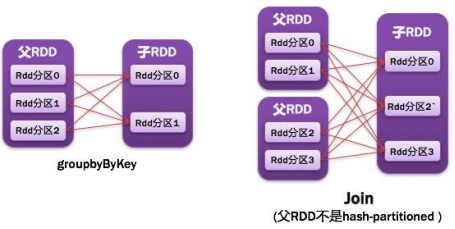
总结:在这里我们是从父RDD的partition被使用的个数来定义窄依赖和宽依赖,因此可以用一句话概括下:如果父RDD的一个Partition被子RDD的一个Partition所使用就是窄依赖,否则的话就是宽依赖。因为是确定的partition数量的依赖关系,所以RDD之间的依赖关系就是窄依赖;由此我们可以得出一个推论:即窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖。
一对固定个数的窄依赖的理解:即子RDD的partition对父RDD依赖的Partition的数量不会随着RDD数据规模的改变而改变;换句话说,无论是有100T的数据量还是1P的数据量,在窄依赖中,子RDD所依赖的父RDD的partition的个数是确定的,而宽依赖是shuffle级别的,数据量越大,那么子RDD所依赖的父RDD的个数就越多,从而子RDD所依赖的父RDD的partition的个数也会变得越来越多。
数据在没有分区的时候 ,任务可以并行的处理 ,如果数据在处理的过程中需要shuffle ,那么下游的数据就需要从上游中获取数据
1) 一定是要获取所有的数据 , 有可能需要等待上游数据的处理完毕
2) 需要网络之间的数据传输, 占用带宽
3) 某些情况下需要重新排序排序