1.8 sample
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
采样操作,用于从样本中取出部分数据。
withReplacement; 参数一 是否放回
fraction : 每个元素取出的比例
seed: 随机种子 , 用于返回结果数据
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
val rdd: RDD[Int] = sc.parallelize(1 to 10, 2)
val rdd2: RDD[Int] = rdd.sample(true, 0.5, 1)
rdd2.collect().foreach(println)
sc.stop
}
随机的获取一批数据 , 如果计算的任务出现了数据倾斜 ,可以使用这个方法定位KEY
1.9 takeSample
takeSample()函数和上面的sample函数是一个原理,但是不使用相对比例采样,而是按设定的采样个数进行采样,同时返回结果不再是RDD,而是相当于对采样后的数据进行Collect(),返回结果的集合为单机的数组。
**def** main(args: Array[String]): Unit = {
**val** sc: SparkContext = SparkUtil.*getSparkContext*()
**val** rdd: RDD[Int] = sc.parallelize(1 to 10, 3)
**val** rdd2: Array[Int] = rdd.takeSample(**false** ,2,2)
rdd2.foreach(*println*) *// 4 9* *
\* sc.stop()
}
图中左侧的方框代表分布式的各个节点上的分区,右侧方框代表单机上返回的结果数组。 通过takeSample对数据采样,设置为采样一份数据,返回结果为V1 , U1。
1.10 distinct
distinct将RDD中的元素进行去重操作。通过distinct函数,将每个分区中的数据去重。
distinct将RDD中的元素进行去重操作。通过distinct函数,将每个分区中的数据去重。
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSparkContext()
val arr = Array("a", "b", "a", "c", "f", "f", "f", "v", "c")
val rdd: RDD[String] = sc.parallelize(arr, 3)
// 去除所有分区中的重复数据
rdd.distinct().collect().foreach(println)
sc.stop()
}
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtils.getSparkContext()
val rdd1: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4 ,2,3,4,5,6), 2)
// 1 收集所有的数据 使用set去重
// rdd1.collect().toSet
// 2 使用groupby分组
/* val groupedRDD : RDD[(Int, Iterable[Int])] = rdd1.groupBy(e => e)
val res: RDD[Int] = groupedRDD.map(_._1)
res.foreach(println)*/
/* val res: RDD[Int] = rdd1.distinct()
res.foreach(println)*/
// 3 使用reduceByKey
val res: RDD[Int] = rdd1.distinct()
val value = rdd1.keyBy(e => e).reduceByKey((e, _) => e).map(_._1)
value.foreach(println)
sc.stop()
}
去重以后 ,减少分区
补充
- keyBy将value类型的RDD转换成KEY-VALUE类型的RDD
def keyBy[K](f: T => K): RDD[(K, T)] = withScope {
val cleanedF = sc.clean(f)
map(x => (cleanedF(x), x))
}
val rdd2: RDD[(Int, Int)] = rdd1.keyBy(e => e)
- sortByKey 根据KEY进行排序
def sortByKey(ascending: Boolean = true, numPartitions: Int = self.partitions.length)
1.11 sortBy
该操作用于排序数据。在排序之前,可以将数据通过 f 函数进行处理,之后按照 f 函数处理的结果进行排序,默认为升序排列。排序后新产生的 RDD 的分区数与原 RDD 的分区数一致。中间存在 shuffle 的过程
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
val rdd1: RDD[String] = sc.parallelize(List("a", "c", "d", "f", "b"))
val rdd2: RDD[Int] = sc.parallelize(List(2, 1, 3, 7, 4, 5))
val rdd3 = sc.parallelize(List(("b", 3), ("c", 3), ("a", 11), ("f", 6)))
// 默认按照升序排列
val res1: RDD[Int] = rdd2.sortBy(e => e,true , 3)
val red2 = rdd3.sortBy{
case (k,v)=> -v} // 按照v降序排列
println(red2.collect().toList)
sc.stop()
}
1.12 intersection
对于源数据集和其他数据集求交集,并去重,且无序返回。
**def** main(args: Array[String]): Unit = {
**val** sc: SparkContext = SparkUtil.*getSparkContext*()
**val** list1 = *List*(**"java"**, **"java"**, **"scala"**, **"python"**, **"js"**, **"vue"** , **"js"**)
**val** list2 = *List*(**"A"**, **"B"**, **"scala"**, **"C"**, **"js"**, **"F"**,**"js"**)
**val** rdd1: RDD[String] = sc.parallelize(list1 , 3)
**val** rdd2: RDD[String] = sc.parallelize(list2 , 3)
**val** rdd: RDD[String] = rdd1.intersection(rdd2)
rdd.collect().foreach(*println*)
sc.stop()
}
只返回scala和js两个元素!
1.13 union
对于源数据集和其他数据集求并集,不去重。union的两个RDD的数据类型要求是一致的!
**def** main(args: Array[String]): Unit = {
**val** sc: SparkContext = SparkUtil.*getSparkContext*()
**val** list1 = *List*(**"java"**, **"java"**, **"scala"**, **"python"**, **"js"**, **"vue"**)
**val** list2 = *List*(**"A"**, **"B"**, **"scala"**, **"C"**, **"js"**, **"F"**)
**val** rdd1: RDD[String] = sc.parallelize(list1 , 3)
**val** rdd2: RDD[String] = sc.parallelize(list2 , 3)
**val** rdd: RDD[String] = rdd1.union(rdd2)
rdd.collect().foreach(*println*)
sc.stop()
}
1.14 subtract
去除RDD1中在RDD2中出现的元素

subtract相当于进行集合的差操作,RDD 1去除RDD 1和RDD 2交集中的所有元素。
**def** main(args: Array[String]): Unit = {
**val** sc: SparkContext = SparkUtil.*getSparkContext*()
**val** list1 = *List*(**"java"**, **"scala"**,**"A"**)
**val** list2 = *List*(**"A"**, **"B"**,**"C"**,**"D"**)
**val** rdd1: RDD[String] = sc.parallelize(list1 , 3)
**val** rdd2: RDD[String] = sc.parallelize(list2 , 3)
**val** rdd: RDD[String] = rdd1.subtract(rdd2)
rdd.collect().foreach(*println*)
sc.stop()
}
返回java , scala两个元素
1.15 zip 和zipWithIndex
zip拉链操作 ,将两个RDD中的元素按照区内的顺序进行zip返回对偶数据!
注意:两个RDD中的分区数 , 每个分区中数据的条数要一致
zip
**def** main(args: Array[String]): Unit = {
**val** sc: SparkContext = SparkUtil.*getSparkContext*()
**val** rdd1: RDD[Int] = sc.parallelize(*Array*(1, 3, 5), 3)
**val** rdd2: RDD[String] = sc.parallelize(*Array*(**"a"**, **"b"**, **"c"**), 3)
**val** res: RDD[(Int, String)] = rdd1.zip(rdd2)
res.collect().foreach(*println*)
sc.stop()
}
zipWithIndex
**def** main(args: Array[String]): Unit = {
**val** sc: SparkContext = SparkUtil.*getSparkContext*()
**val** rdd1: RDD[Int] = sc.parallelize(*Array*(1, 3, 5,7,2), 3)
**val** rdd2: RDD[String] = sc.parallelize(*Array*(**"a"**, **"b"**, **"c"**,**"d"**,**"b"**), 3)
*//带编号**
\* **val** res: RDD[((Int, String), Long)] = rdd1.zip(rdd2).zipWithIndex()
res.collect().foreach(*println*)
sc.stop()
}
1.16 partitionBy
partitionBy函数对RDD进行分区操,本质就是将数组重新分配到不同的分区中
函数定义如下。
partitionBy(partitioner:Partitioner)
如果原有RDD的分区器和现有分区器(partitioner)一致,则不重分区,如果不一致,则相当于根据分区器生成一个新的ShuffledRDD。
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
val rdd1: RDD[String] = sc.parallelize(List("a", "c", "d", "f", "b"), 2)
val rdd2: RDD[Int] = sc.parallelize(List(2, 1, 3, 7, 4, 5), 2)
val rdd3: RDD[(String, Int)] = sc.parallelize(List(("b", 3), ("c", 3), ("a", 11), ("f", 6)), 2)
val rdd4: RDD[(String, Iterable[(String, Int)])] = rdd1.map((_, 1)).groupBy(_._1)
// 非键值对的RDD不需要分区器 , 每部有自己的数据划分的逻辑
println(rdd1.partitioner) // None
println(rdd2.partitioner) // None
println(rdd3.partitioner) // None
println(rdd4.partitioner) // HashPartitioner
// 如果两次使用的分区器是一致的,并且分区的个数也一致 ,数据就不回产生shuffle
val rdd5 = rdd4.partitionBy(new HashPartitioner(2))
println(rdd5.partitioner)
sc.stop()
}
1.17 join
join 对两个需要连接的 RDD 进行 cogroup函数操作,将相同 key 的数据能够放到一个分区,在 cogroup 操作之后形成的新 RDD 对每个key 下的元素进行笛卡尔积的操作,返回的结果再展平,对应 key 下的所有元组形成一个集合。最后返回 RDD[(K, (V, W))]。
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSparkContext()
val arr1 = Array(("a", 11), ("c", 22), ("d", 33), ("d", 333), ("a", 111), ("b", 222), ("f", 2))
val arr2 = Array(("a", 1111), ("c", 2222), ("d", 3333), ("o", 333), ("a", 111), ("b", 422), ("f", 21))
val rdd1: RDD[(String, Int)] = sc.parallelize(arr1)
val rdd2: RDD[(String, Int)] = sc.parallelize(arr2)
val rdd: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
rdd.collect().foreach(println)
sc.stop()
}
1.18 leftOutJoin和rightOutJoin
LeftOutJoin(左外连接)和RightOutJoin(右外连接)相当于在join的基础上先判断一侧的RDD元素是否为空,如果为空,则填充为空。 如果不为空,则将数据进行连接运算,并返回结果。
if (ws.isEmpty) {
vs.map(v => (v, None))
} else {
for (v <- vs; w <- ws) yield (v, Some(w))
}
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSparkContext()
val arr1 = Array(("a", 11),("a", 11), ("c", 22), ("d", 33))
val arr2 = Array(("a", 1111), ("c", 2222),("c", 2222))
val rdd1: RDD[(String, Int)] = sc.parallelize(arr1)
val rdd2: RDD[(String, Int)] = sc.parallelize(arr2)
val rdd: RDD[(String, (Int, Option[Int]))] = rdd1.leftOuterJoin(rdd2)
rdd.collect().foreach(println)
sc.stop()
}
1.19 reduceByKey
与groupByKey类似,却有不同。如(a,1), (a,2), (b,1), (b,2)。groupByKey产生中间结果为( (a,1), (a,2) ), ( (b,1), (b,2) )。而reduceByKey为(a,3), (b,3)。
reduceByKey主要作用是聚合,groupByKey主要作用是分组。(function对于key值来进行聚合)
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSparkContext()
val rdd1: RDD[String] = sc.textFile("d://word.txt")
// 处理的是切割好的所有的单词
val rdd2: RDD[String] = rdd1.flatMap(_.split("\\s+"))
// 组装成(单词 , 1)
val rdd3: RDD[(String, Int)] = rdd2.map((_,1))
val rdd4: RDD[(String, Int)] = rdd3.reduceByKey(_+_)
rdd4.sortBy(_._2,false).collect().foreach(println)
sc.stop()
}
1.20 groupByKey
在一个PairRDD或(k,v)RDD上调用,返回一个(k,Iterable)。主要作用是将相同的所有的键值对分组到一个集合序列当中,其顺序是不确定的。groupByKey是把所有的键值对集合都加载到内存中存储计算,若一个键对应值太多,则易导致内存溢出。内部会对数据进行分区
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSparkContext()
val rdd1: RDD[String] = sc.textFile("d://word.txt")
// 处理的是切割好的所有的单词
val rdd2: RDD[String] = rdd1.flatMap(_.split("\\s+"))
// 组装成(单词 , 1)
val rdd3: RDD[(String, Int)] = rdd2.map((_,1))
// 按照相同的key分到一起 迭代器中存储是所有的单词
val rdd4: RDD[(String, Iterable[Int])] = rdd3.groupByKey()
val rdd5: RDD[(String, Int)] = rdd4.map(x=>(x._1,x._2.toList.size))
rdd5.collect().foreach(println)
sc.stop()
}
groupByKey和reduceByKey的区别
groupBykey根据key进行分组会产生shuffle现象, 我们可以在分组以后对数据进行聚合操作,这种效率不是很高,我们知道进行shuffle的时候要将数据落地磁盘(如果不落地磁盘数据在内存中存储的时间过长占用大量内存)
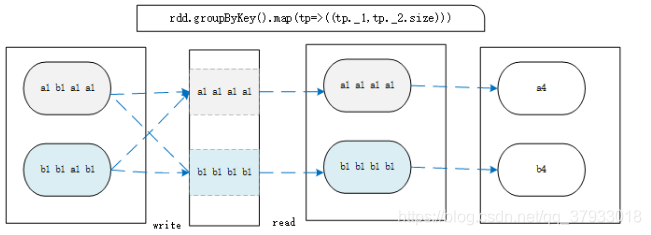
reduceBykey会在数据写出到磁盘的时候,对数据进行预先聚合操作,所以,写出和读取的数据量会变小, 性能上更好
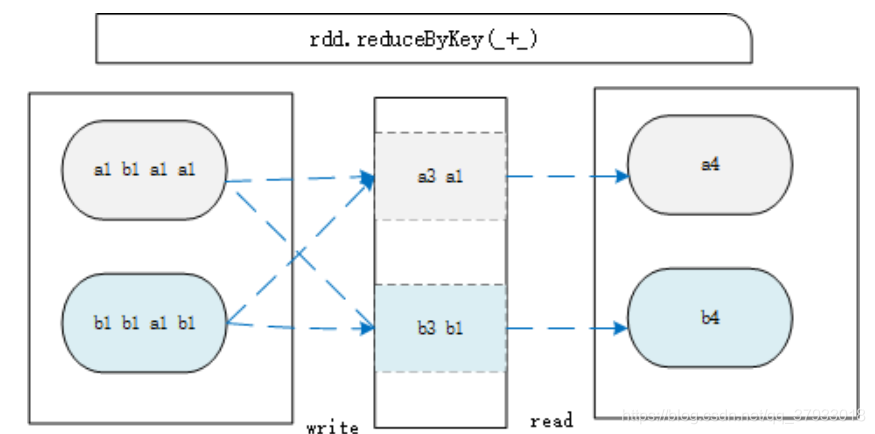
从 shuffle 的角度:reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的数据量,而 groupByKey 只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较高。
从功能的角度:reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那么还是只能使用 groupByKey
源码解析
groupByKey
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
// groupByKey shouldn't use map side combine because map side combine does not
// reduce the amount of data shuffled and requires all map side data be inserted
// into a hash table, leading to more objects in the old gen.
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
reduceByKey
def combineByKeyWithClassTag[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true, // 开启map端聚合
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
if (keyClass.isArray) {
if (mapSideCombine) {
throw new SparkException("Cannot use map-side combining with array keys.")
}
if (partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("HashPartitioner cannot partition array keys.")
}
}
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}
1.21 aggregateByKey
当分区内的聚合逻辑和分区间的计算逻辑是一样的可以时候可以使用reduceByKey ,但是当分区内和分区间不同的时候怎么办?
val sc: SparkContext = SparkUtil.getSc
val rdd1 = sc.makeRDD(List(("a",1),("a",2),("a",3),("a",4)) ,2)
// 参数一 默认值,参与一次每个分区的计算
// 参数二 区内数据的计算逻辑
// 参数三 分区间数据的计算逻辑
val res: RDD[(String, Int)] = rdd1.aggregateByKey(0)((x1, x2) => math.max(x1, x2), (x1, x2) => x1 + x2)
res.foreach(println)
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)]
可以看出 算子在执行后返回值的数据类型和默认值的参数类型是一致的
val rdd1 = sc.makeRDD(List(("a",1),("a",2),("b",3),("a",3),("b",4),("b",5)) ,2)
// val res: RDD[(String, Int)] = rdd1.aggregateByKey(0)((x1, x2) => math.max(x1, x2), (x1, x2) => x1 + x2)
// 求每个个单词的平均值
// sum , cnt
val res: RDD[(String, (Int, Int))] = rdd1.aggregateByKey((0, 0))(
// 返回的结果是分区内的和 分区内的次数
(tp, v) => (tp._1 + v, tp._2 + 1),
(tp1, tp2) => (tp1._1 + tp2._1, tp1._2 + tp2._2)
)
val resRDD : RDD[(String, Int)] = res.mapValues(tp => (tp._1 / tp._2))
resRDD.foreach(println)
1.22 mapValues
mapValues :针对(Key, Value)型数据中的 Value 进行 Map 操作,而不对 Key 进行处理。K不会发生变化
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSparkContext()
val rdd1: RDD[String] = sc.textFile("d://word.txt")
val rdd2: RDD[(String, Int)] = rdd1.flatMap(_.split("\\s+")).map((_,1))
val rdd3: RDD[(String, Int)] = rdd2.mapValues(_*10)
for (elem <- rdd3.collect()) {
println(elem)
}
sc.stop()
}
1.23 combineByKey
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null)
1 createCombiner: V => C ,这个函数把当前的值作为参数,此时我们可以对其做些附加操作(类型转换)并把它返回 (这一步类似于初始化操作)
2 mergeValue: (C, V) => C,该函数把元素V合并到之前的元素C(createCombiner)上 (这个操作在每个分区内进行)
3 mergeCombiners: (C, C) => C,该函数把2个元素C合并 (这个操作在不同分区间进行)
工作流程
1、combineByKey会遍历分区中的所有元素,因此每个元素的key要么没遇到过,要么和之前某个元素的key相同。
2、如果这是一个新的元素,函数会调用createCombiner创建那个key对应的累加器初始值。
3、如果这是一个在处理当前分区之前已经遇到的key,会调用mergeCombiners把该key累加器对应的当前value与这个新的value合并。
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
val arr = Array(("Fred", 88.0), ("Fred", 95.0), ("Fred", 91.0), ("Wilma", 92.0), ("Wilma", 95.0), ("Wilma", 95.0))
val rdd1: RDD[(String, Double)] = sc.parallelize(arr)
// 定义一种类型 科目的次数和科目的分数
type myType = (Int, Double)
val rdd2: RDD[(String, (Int, Double))] = rdd1.combineByKey(
score => (1, score), // 分数出现一次
(c1: myType, newScore) => (c1._1 + 1, c1._2 + newScore), //次数+1 分数累加
(c1: myType, c2: myType) => (c1._1 + c2._1, c1._2 + c2._2)
)
val rdd3 = rdd2.map {
case (name, (num, score)) => {
(name, score / num)
}
}
println(rdd3.collect().toList)
sc.stop()
}
参数含义的解释
a 、score => (1, score),我们把分数作为参数,并返回了附加的元组类型。 以"Fred"为列,当前其分数为88.0 =>(1,88.0) 1表示当前科目的计数器,此时 个科目
b、(c1: myType, newScore) => (c1._1 + 1, c1._2 + newScore),注意这里的c1就是createCombiner初始化得到的(1,88.0)。在一个分区内,我们又碰到了"Fred"的一个新的分数91.0。当然我们要把之前的科目分数和当前的分数加起来即c1._2 + newScore,然后把科目计算器加1即c1._1 + 1
c、 (c1: myType, c2: myType) => (c1._1 + c2._1, c1._2 + c2._2),注意"Fred"可能是个学霸,他选修的科目可能过多而分散在不同的分区中。所有的分区都进行mergeValue后,接下来就是对分区间进行合并了,分区间科目数和科目数相加分数和分数相加就得到了总分和总科目数
1.24 cogroup
合并两个RDD,生成一个新的RDD。实例中包含两个Iterable值,第一个表示RDD1中相同值,第二个表示RDD2中相同值(key值),这个操作需要通过partitioner进行重新分区,因此需要执行一次shuffle操作。(若两个RDD在此之前进行过shuffle,则不需要)
cogroup函数将两个RDD进行协同划分,cogroup函数的定义如下。
cogroup[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (Iterable[V], Iterable[W]))]
对在两个RDD中的Key-Value类型的元素,每个RDD相同Key的元素分别聚合为一个集合,并且返回两个RDD中对应Key的元素集合的迭代器。
(K, (Iterable[V], Iterable[W]))
其中,Key和Value,Value是两个RDD下相同Key的两个数据集合的迭代器所构成的元组。
val arr1 = Array(("a", 11), ("c", 22), ("d", 33), ("d", 333), ("a", 111), ("b", 222), ("f", 2))
val arr2 = Array(("a", 1111), ("c", 2222), ("d", 3333), ("o", 333), ("a", 111), ("b", 422), ("f", 21))
val rdd1: RDD[(String, Int)] = sc.parallelize(arr1)
val rdd2: RDD[(String, Int)] = sc.parallelize(arr2)
val rdd: RDD[(String, (Iterable[Int], Iterable[Int]))] = rdd1.cogroup(rdd2)
rdd.collect().foreach(println)
1.25 RDD案例
求每个部门下每个岗位工资最高的前3位员工信息
数据示例
部门数据
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
员工数据
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
7934 TOMMER CLERK 7782 1982-1-23 6300.00 10
7934 JACKER CLERK 7782 1982-1-23 1300.00 10
7934 ROLSER CLERK 7782 1982-1-23 7300.00 10
7934 CARY CLERK 7782 1982-1-23 4500.00 10
代码实现
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
val rdd: RDD[String] = sc.textFile("data/demo1/emp.txt")
//7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
val rdd2: RDD[Array[String]] = rdd.map(line => line.split("\t"))
// ( deptno,(name ,job ,sal))
val rdd3: RDD[(String, (String, String, Double))] = rdd2.map(arr => {
(arr(7), (arr(1), arr(2), arr(5).toDouble))
})
val detpRDD1: RDD[String] = sc.textFile("data/demo1/dept.txt")
val arrRDD: RDD[Array[String]] = detpRDD1.map(_.split("\t"))
// (deptno , dname)
val noRDD: RDD[(String, String)] = arrRDD.map(arr => (arr(0), arr(1)))
//(10,(ACCOUNTING,(CARY,CLERK,4500.0)))
val joinRDD: RDD[(String, (String, (String, String, Double)))] = noRDD.join(rdd3)
//(dname , job , name , sal )
val dataRDD: RDD[(String, String, String, Double)] = joinRDD.map(tp => {
(tp._2._1, tp._2._2._2, tp._2._2._1, tp._2._2._3)
})
val groupedRDD: RDD[((String, String), Iterable[(String, String, String, Double)])] = dataRDD.groupBy(e => (e._1, e._2))
/*val sorted: RDD[((String, String), List[(String, String, String, Double)])] = groupedRDD.map(tp => {
val dnameAndJob: (String, String) = tp._1
val ls: List[(String, String, String, Double)] = tp._2.toList.sortBy(-_._4)
(dnameAndJob, ls)
})*/
val sorted: RDD[((String, String), List[(String, String, String, Double)])] = groupedRDD.mapValues(iter => {
iter.toList.sortBy(-_._4).take(3)
})
// sorted.collect().foreach(println)
val resRDD: RDD[List[(String, String, String, Double)]] = sorted.map(tp=>{
val dnameAndJob: (String, String) = tp._1
val res = for (elem <- tp._2) yield (dnameAndJob._1 , dnameAndJob._2 , elem._3 ,elem._4)
res
})
resRDD.flatMap(e=>e).collect().foreach(println)
sc.stop()
}