MobileNet
Google MobileNets:用于移动视觉应用的高效卷积神经网络的张量流实现
在tensorflow / model中可以正式实施。
对象检测的正式实现现已发布,请参阅tensorflow / model / object_detection。
新闻
YellowFin优化器已经集成,但是我没有gpu资源在imagenet上训练。呼叫培训〜_〜
官方实施点击这里
基本模块

ImageNet-2012验证集的准确性
| 模型 | 宽度乘数 | 预处理 | 精度-TOP1 | 精度-TOP5 |
|---|---|---|---|---|
| MobileNet | 1.0 | 与初始相同 | 66.51% | 87.09% |
失利

时间基准
环境:Ubuntu 16.04 LTS,Xeon E3-1231 v3,4核3.40GHz,GTX1060。
TF 1.0.1(原生pip安装),TF 1.1.0(从源码生成,优化标志'-mavx2')
| 设备 | 前锋 | 向前向后 | 指令系统 | 量化 | 融合-BN | 备注 |
|---|---|---|---|---|---|---|
| 中央处理器 | 52ms | 503ms | - | - | - | TF 1.0.1 |
| 中央处理器 | 44ms | 177ms | - | - | 上 | TF 1.0.1 |
| 中央处理器 | 31毫秒 | - | - | 8位 | - | TF 1.0.1 |
| 中央处理器 | 26ms | 75ms | AVX2 | - | - | TF 1.1.0 |
| 中央处理器 | 128毫秒 | - | AVX2 | 8位 | - | TF 1.1.0 |
| 中央处理器 | 19ms | 89ms | AVX2 | - | 上 | TF 1.1.0 |
| GPU | 为3ms | 16毫秒 | - | - | - | TF 1.0.1,CUDA8.0,CUDNN5.1 |
| GPU | 为3ms | 15毫秒 | - | - | 上 | TF 1.0.1,CUDA8.0,CUDNN5.1 |
图像尺寸:(224,224,3),批量:1
基准速度
python ./scripts/time_benchmark.py
培训MobileNet探测器(调试)
- 准备KITTI数据。
下载KITTI数据后,您需要将数据分成train / val集。
cd /path/to/kitti_root
mkdir ImageSets
cd ./ImageSets
ls ../training/image_2/ | grep ".png" | sed s/.png// > trainval.txt
python ./tools/kitti_random_split_train_val.py
kitti_root floder然后看起来像下面
kitti_root/
|->training/
| |-> image_2/00****.png
| L-> label_2/00****.txt
|->testing/
| L-> image_2/00****.png
L->ImageSets/
|-> trainval.txt
|-> train.txt
L-> val.txt
然后将其转换为tfrecord。
python ./tools/tf_convert_data.py
- 根据您的环境,Mobify'./script/train_mobilenet_on_kitti.sh'。
bash ./script/train_mobilenetdet_on_kitti.sh
这个主题的代码主要基于SqueezeDet和SSD-Tensorflow。如果你能反馈任何错误,我将不胜感激。
故障排除
- 关于MobileNet模型大小
根据这篇论文,MobileNet拥有3.3百万个参数,不会因输入分辨率而异。这意味着由于fc层,最终模型参数的数量应该大于3.3百万。
当使用RMSprop训练策略时,由于RMSprop中使用了一些辅助参数,检查点文件大小应该几乎是模型大小的3倍。你可以使用inspect_checkpoint.py来找出它。
- 纤细的多GPU性能问题
去做
- 在Imagenet上训练
- 添加宽度乘数超参数
- 报告培训结果
- 集成到对象检测任务(进行中)
ResNet在TensorFlow中
的实行图像识别深层残留学习。包括使用He等人在TensorFlow中发布的经过训练的Caffe权重的工具。
MIT许可证。贡献值得欢迎。
目标
-
能够使用Kaiming和Caffe提供的预训练模型。在
convert.py将其转换权与TensorFlow使用。 -
以Inception的风格实现, 不使用任何类,大量使用变量作用域。它应该很容易在其他型号中使用。
-
基础,像随机深度一样试验ResNet的变化,在每个尺度上分享权重,以及音频的一维卷积。(尚未实现。)
-
ResNet是完全卷积的,实现应该允许任何大小的输入。
-
能够在CIFAR-10,100和ImageNet上进行培训。(执行不完整)
预训练模型
要转换已发布的Caffe pretrained模型,请运行convert.py。然而,咖啡烦恼安装,所以我提供了convert.py的输出下载:
tensorflow-resnet-pretrained-20160509.tar.gz.torrent 464M
笔记
-
这个代码依赖于TensorFlow的git commit cf7ce8 或更高版本,因为ResNet需要1x1与步幅2的卷积.TF 0.8是不够新的。
-
该
convert.py脚本检查激活类似caffe版本,但它不完全相同。这可能是由于TF和Caffe如何处理填充差异造成的。另外预处理是用颜色通道方法来完成的,而不是像素方式。
深柱式卷积神经网络
DCCNN是一个卷积神经网络架构,受Ciresan(2012)的多列深度神经网络的启发。
使用批处理标准化,Leaky Relu,初始BottleNeck块和卷积子采样等近期论文的改进,网络使用非常少的参数来获得各种数据集(例如MNIST,CIFAR 10/100和SHVN 。
虽然它在现有技术水平上没有得到改善,但是它表明,较小参数的体系结构可以与大型集成网络的性能相媲美。
论文:“深度柱状卷积神经网络”
架构
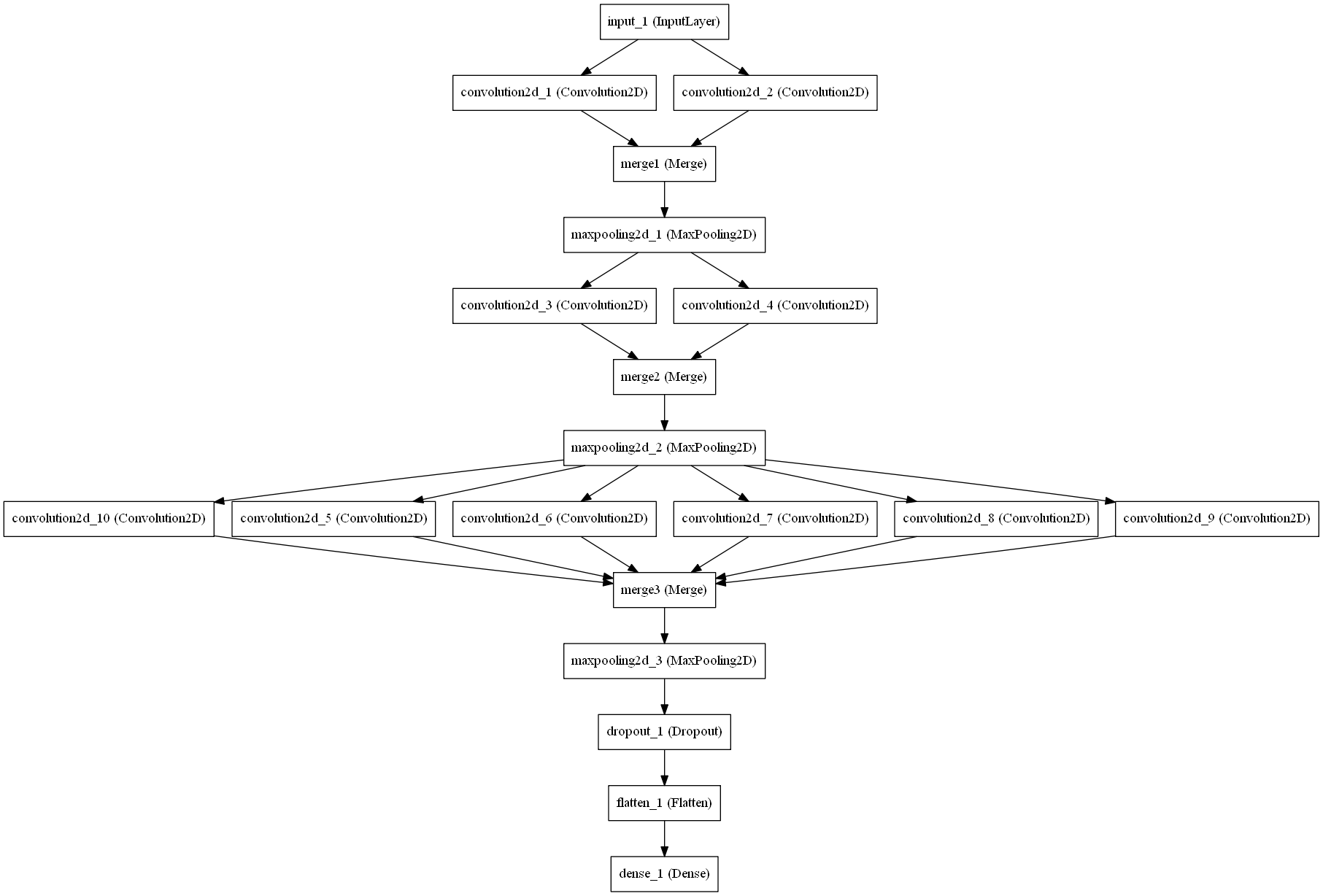
DCCNN MNIST
这种体系结构对于包含小灰度图像的MNIST数据集来说足够简单。经过500个历元后,达到了0.23%的错误率。这个模型的权重可以在权重文件夹中找到。
DCCNN SVHN
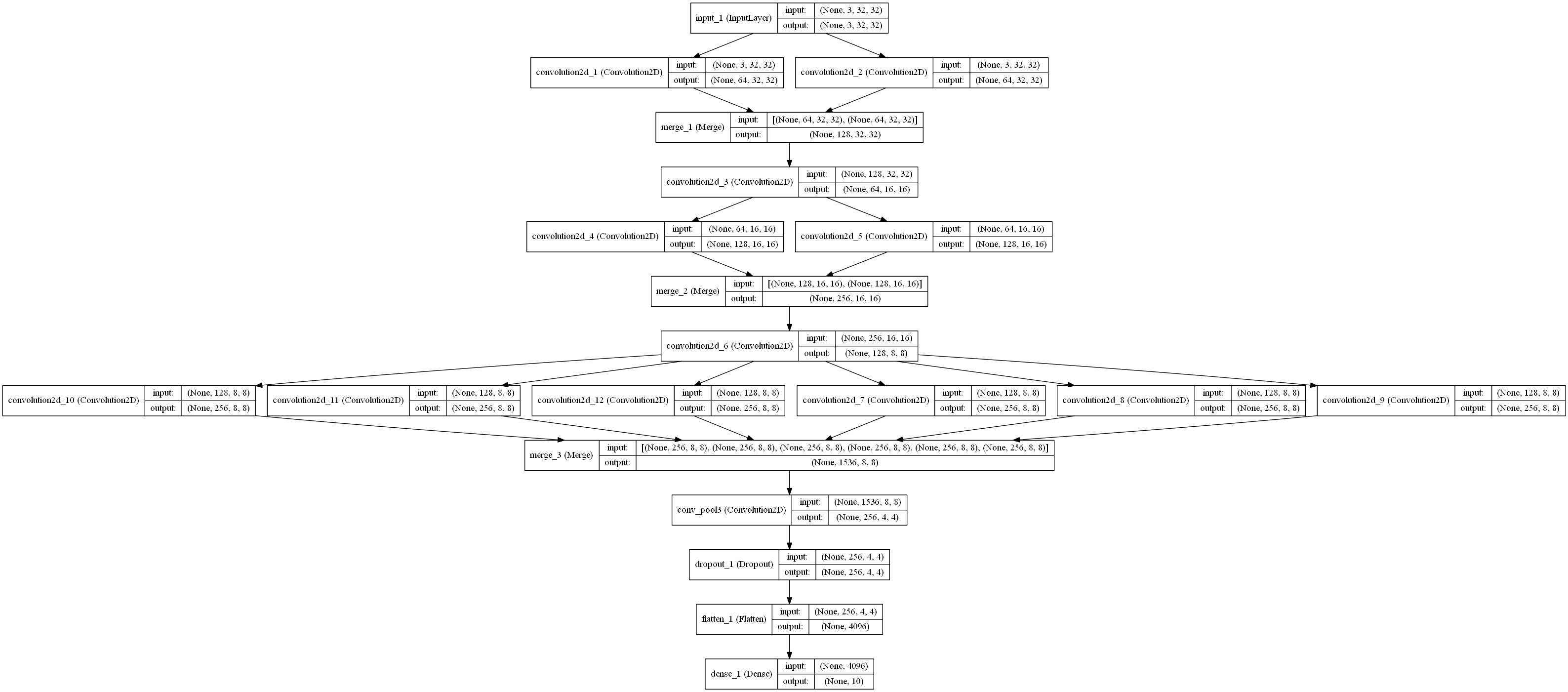
该架构与MNIST数据集相似,但是使用了近60万个彩色图像的SVHN数据集。它实现了1.92%的错误率 。由于GPU内存不足,无法在此模型中使用较大的DCCNN CIFAR 100架构。
请注意,虽然类似,但使用卷积抽样而不是最大池来完成合并。
DCCNN CIFAR 10
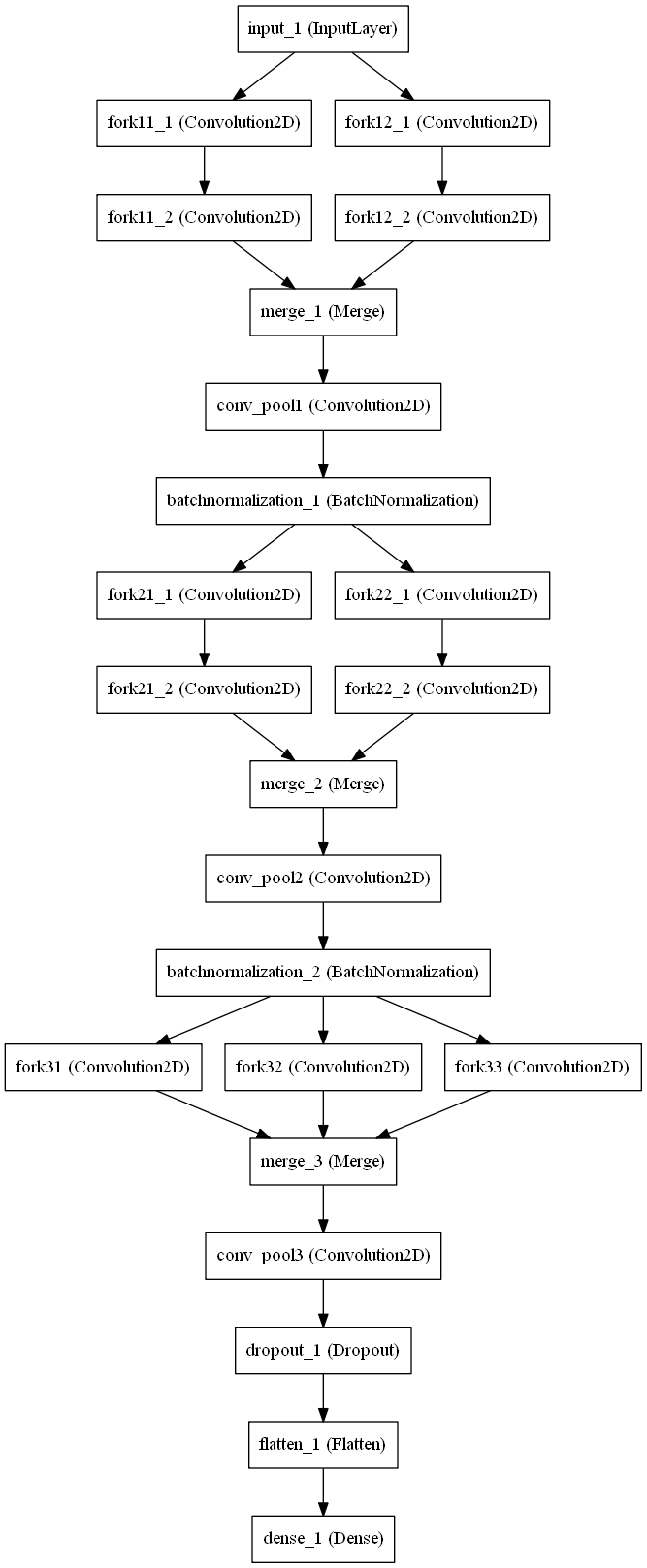
这个架构不同于上述两个,用于CIFAR 10数据集。它实现了6.90%的低错误率。这比现有的3.47%高,但是这是一个非常深的18层网络。
DCCNN CIFAR 100
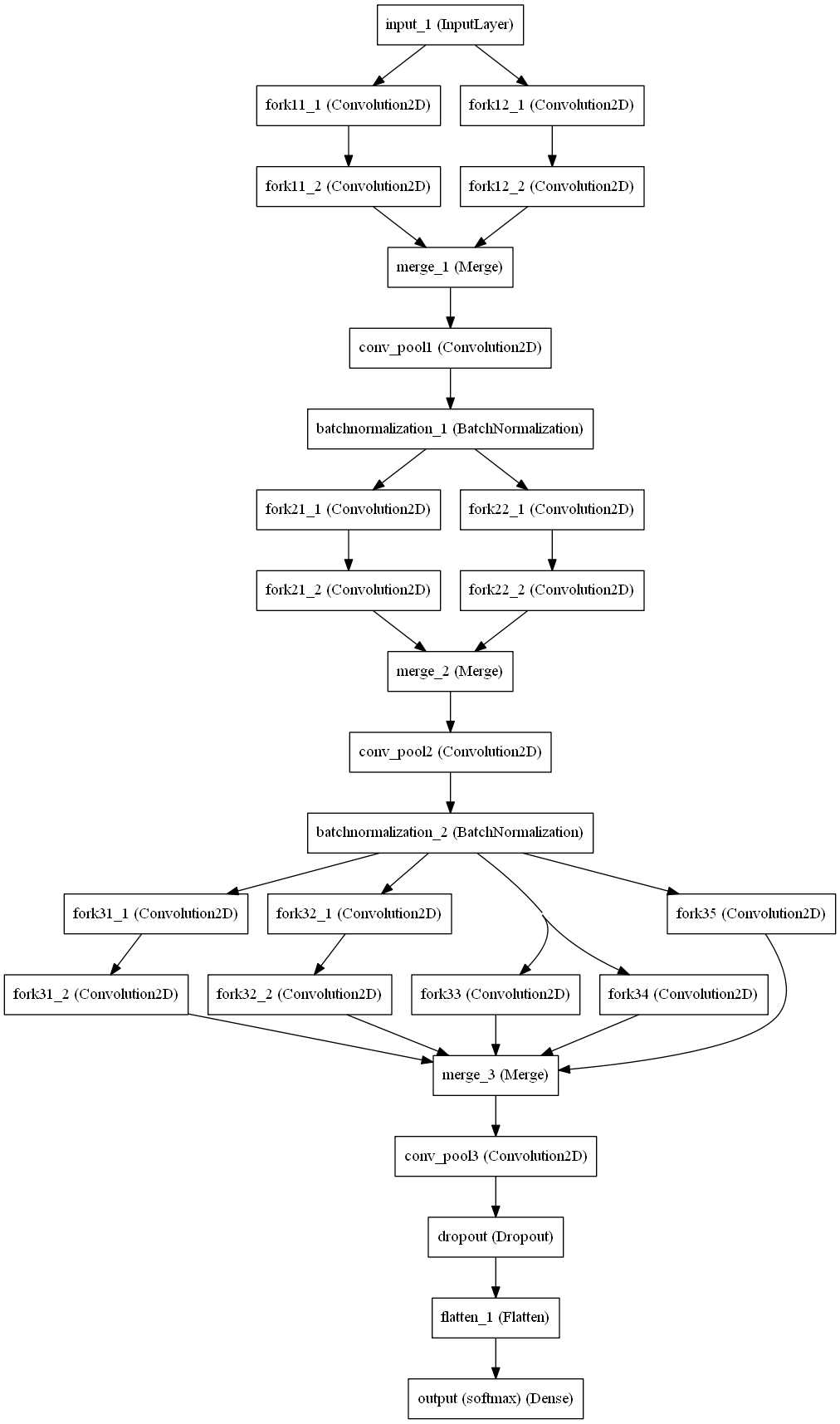
这个架构类似于上面的架构,但是在最后一级有更多的叉子。它实现了28.63%的低错误率。这比现有技术水平高24.28%,其中有五千万参数,需要超过16万个历元。
宽残留网络,Tensorflow
这是一个使用Tensorflow库进行图像分类的宽余量网络的实现该模型在cifar10数据集上进行了训练和测试。然后使用该模型对从Google下载的一些图像进行预测。
一些样品Cifar10训练图像(经过一些处理):

旧型号描述:
(见OLD文件夹内)
我训练了批量大小为120的16-4 WRN 3,3型块(带压差)。任何具有K加宽因子块的L层WRN 3,3型块可以通过简单地改变变量层的值和代码中的'K'。
我实现了90.15%的准确率,这与WRN应达到的最高水平相比是相当低的。
这里有一些图表显示了培训的进行情况:


低准确性有各种可能的原因:
- 由于各种环境问题,我可以训练模型相对较少的迭代(仅约100个时代)
- 性能可能会更好更广泛和更深入的警告
- 我实现了非常轻的增强(仅横向翻转)。用镜子填充裁剪可能是值得一试的。
- 对于预处理,我只使用了全局对比度归一化而没有ZCA白化。不同的预处理步骤可能会产生明显不同的结果。
- 没有二线正规化。似乎有一些过度配合。
- 某些超参数可能需要进一步优化。
新型号的描述
我对旧模型做了一些修改 - 参见Model(WRN)(NEW).ipynb和DataProcessing(NEW).ipynb。
- 包括l2正则化。
- 用平均预处理代替GCN(全局对比度标准化)。
- 图像增强包括在原始32x32
图像上随机化的28x28裁剪和裁剪位置的位移。它创造了翻译般的效果。横向翻转仍然存在。 - 改进了配料方法。
- 用ELU取代了ReLus。
- 添加标签平滑。(https://arxiv.org/abs/1708.01729)
但是,在16-8型号的WRN中,我仍然达不到92%以上。我想我有一些超参数达到了92.7%。
注:我正在使用相同的样本进行测试和验证 - 这应该是一个罪过。即使偏向测试集的假设之后,我的糟糕结果也使得这一切变得更加尴尬。
潜在的改进:
- 用零初始化所有的偏差。
- 首先尝试用ReLus(最初使用的)复制结果,
- Xavier初始化权重。
实验WRN + ResNeXt:
关于ResNeXt的论文(“深度神经网络的聚集残差变换”,谢宁宁,Ross Girshick,PiotrDollár,涂卓文,Kaiming He arXiv:1611.05431)强调了“分裂变换合并”策略(用于初始模型),并建议将其纳入残余块。我在更新的WRN模型上创建了另一个模型,其中我添加了4K基数(其中K是宽度 - 通常基数不必取决于K)。现在将一个块中的卷积层堆栈以4K分隔(由基数指定的号码)分离的并行层,并减小了滤波器的大小。然后添加并行堆栈的输出。结果然后添加标准跳过连接。
我也包括合奏。这个模型没有经过训练,没有经过测试。
(设置基数= 1会变成一个普通的WRN)
我没有广泛地测试它。基数使模型变得沉重。我做了一个天真的实现,使得卷积层的“分支”按顺序处理。这增加了培训所需的时间。在分布式设置中,有一些并行计算,基数没有任何问题。
在旧的里面
文件说明:
数据处理(OLD).ipynb:它包含对cifar10数据执行一些基本预处理并将处理后的数据保存在hdf5文件中的代码。
模型(WRN)(旧).ipynb:这包括用于撤回处理的数据的代码,用于在训练期间实时创建无偏和增强的训练批次的功能,模型定义和构建,训练(连同检查点和模型保存) 。
Predict.ipynb:该文件用于恢复保存的模型,并使用该模型对指定目录中的任何图像进行新的预测。我通过预测通过Google下载的几个图像的类别来测试模型。(这只适用于旧型号)
Predict-lite.ipynb:与Predict.ipynb相同,但下载的图片较少。如果Predict.ipynb需要太多时间加载或打开,请尝试此文件。(这只适用于旧型号)
该Model_Backup文件夹包含可加载预测或进一步培训训练的模型文件。(只适用于旧款)
ResNeXt-in-tensorflow-master.zip WRN-CIFAR10-16-4-Best.h5
ResNet TensorFlow
的实行图像识别深层残留学习。包括使用He等人在TensorFlow中发布的经过训练的Caffe权重的工具。
MIT许可证。贡献值得欢迎。
目标
-
能够使用Kaiming和Caffe提供的预训练模型。在
convert.py将其转换权与TensorFlow使用。 -
以Inception的风格实现, 不使用任何类,大量使用变量作用域。它应该很容易在其他型号中使用。
-
基础,像随机深度一样试验ResNet的变化,在每个尺度上分享权重,以及音频的一维卷积。(尚未实现。)
-
ResNet是完全卷积的,实现应该允许任何大小的输入。
-
能够在CIFAR-10,100和ImageNet上进行培训。(执行不完整)
预训练模型
要转换已发布的Caffe pretrained模型,请运行convert.py。然而,咖啡烦恼安装,所以我提供了convert.py的输出下载:
tensorflow-resnet-pretrained-20160509.tar.gz.torrent 464M
笔记
-
这个代码依赖于TensorFlow的git commit cf7ce8 或更高版本,因为ResNet需要1x1与步幅2的卷积.TF 0.8是不够新的。
-
该
convert.py脚本检查激活类似caffe版本,但它不完全相同。这可能是由于TF和Caffe如何处理填充差异造成的。另外预处理是用颜色通道方法来完成的,而不是像素方式。
Keras中剩余网络
一般来说,残留网络有几百甚至上千层,可以在主要的图像识别任务中对图像进行准确分类,但是通过简单堆积残留块来构建网络,不可避免地限制了其优化能力。
本文试图通过在原有的剩余网络上增加层次快捷连接来提高剩余网络的优化能力,从而提高剩余网络的学习能力。
这可以从纸上的数字看出来: 
有两种不同的体系结构可用,因为RoR可以扩展到宽余隙网络或预先ResNets。
本文下面两张图片描述了ResRets和RoR在宽余留网络上的RoR架构: 

这些网络在CIFAR 10上的分类准确性(来自纸面)是: 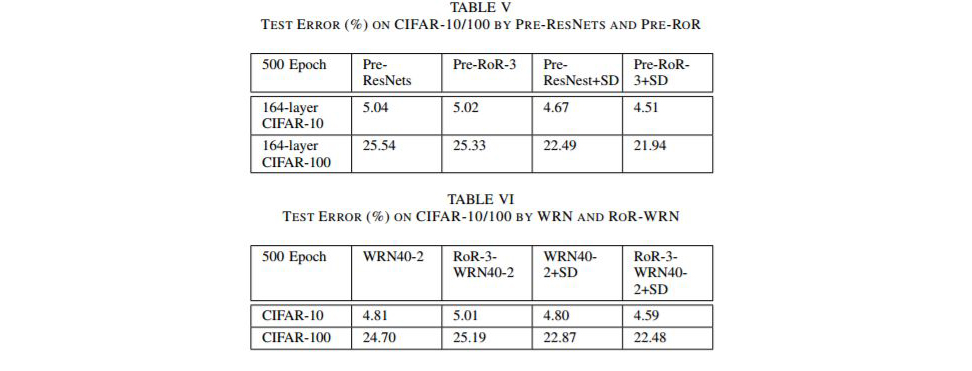
用法
本文使用RoR-3-110(ResNet-101)和RoR-3-WRN-40-2(Wide Residual Network-40-2)等几种型号,但由于GPU内存的限制, RoR-3-WRN-40-2已经在版本标签中提供
请下载重量并将它们放在重量文件夹中。
要创建RoR ResNet模型,请使用以下ror.py脚本:
import ror
input_dim = (3, 32, 32) if K.image_dim_ordering() == 'th' else (32, 32, 3)
model = ror.create_residual_of_residual(input_dim, nb_classes=100, N=2, dropout=0.0) # creates RoR-3-110 (ResNet)
要创建RoR宽余量网络模型,请使用以下ror_wrn.py脚本:
import ror_wrn as ror
input_dim = (3, 32, 32) if K.image_dim_ordering() == 'th' else (32, 32, 3)
model = ror.create_pre_residual_of_residual(input_dim, nb_classes=100, N=6, k=2, dropout=0.0) # creates RoR-3-WRN-40-2 (WRN)
性能
本文所描述的RoR-WRN-40-2模型需要500个时期来达到94.99%的分类准确率(5.01%误差)。
为这个模型提供的Theano权重,使用Adam的学习率为1e-3,训练了100个时期,达到了94.48%的分类准确率(5.52%的误差)
CIFAR-VGG
这是基于CIFAR-10和CIFAR-100的VGG16架构的Keras模型。它可以使用预训练重量文件或从零开始训练。
该软件包为每个数据集包含2个类,该体系结构基于VGG-16 [1],基于[2]适应CIFAR数据集。通过运行py文件,你可以得到一个trining和估计验证错误的样本。
CIFAR-10的验证准确率达到93.56%,CIFAR-100的验证准确率达到70.48%。在实例化模型可以被训练或加载从以前保存的体重文件。
vgg16 model带有ImageNet预训练模型的DenseNet-Keras
这是一个Keras实现DenseNet与ImageNet预训练的权重。权重从Caffe模型转换而来。该实现支持Theano和TensorFlow后端。
要了解更多关于DenseNet的工作原理,请参阅原文
Densely Connected Convolutional Networks
Gao Huang, Zhuang Liu, Kilian Q. Weinberger, Laurens van der Maaten
arXiv:1608.06993
在ImageNet上预训练DenseNet模型
通过使用单中心裁剪(裁剪尺寸:224x224,图像尺寸:256xN),前1/5准确率
| 网络 | 顶1 | 前5 | Tensorflow | |
|---|---|---|---|---|
| DenseNet 121(k = 32) | 74.91 | 92.19 | 型号(32 MB) | |
| DenseNet 169(k = 32) | 76.09 | 93.14 | 模型(56 MB) | |
| DenseNet 161(k = 48) | 77.64 | 93.79 |
用法
首先,将上述预训练的权重下载到imagenet_models文件夹中。
运行test_inference.py一个如何使用预训练模型进行推理的例子。
python test_inference.py
微调
查看此示例,查看使用您自己的数据集微调DenseNet的示例。
要求
- Keras
1.2.22.0.5 - Theano 0.8.2或TensorFlow
0.12.01.2.1
更新
- Keras 2.0.5和TensorFlow 1.2.1被支持
在Keras的密网
现在支持更高效的DenseNet-BC(DenseNet-Bottleneck-Compressed)网络。使用DenseNet-BC-190-40型号,获得了CIFAR-10和CIFAR-100的最新性能
建筑
DenseNet是宽余隙网络的延伸。根据文件:
The lth layer has l inputs, consisting of the feature maps of all preceding convolutional blocks.
Its own feature maps are passed on to all L − l subsequent layers. This introduces L(L+1) / 2 connections
in an L-layer network, instead of just L, as in traditional feed-forward architectures.
Because of its dense connectivity pattern, we refer to our approach as Dense Convolutional Network (DenseNet).
它具有几个改进,如:
- 密集连接:将任何图层连接到任何其他图层。
- 增长率参数决定随着网络变得越来越深,特征数目增加的速度。
- 连续功能:来自Wide ResNet的BatchNorm - Relu - Conv和ResNet纸张的改进。
瓶颈 - 压缩密集网提供了进一步的性能优势,如减少参数数量,具有相似或更好的性能。
-
考虑DenseNet-100-12模型,使用DenseNet-BC-100-12约700万个参数,仅有80万个参数。BC模型与原始模型的4.10%误差相比误差为4.51%
-
最好的原始模型DenseNet-100-24(2720万参数)误差为3.74%,而DenseNet-BC-190-40(2560万参数)误差为3.46%,这是CIFAR- 10。
密集的网络有一个架构可以显示在下面的图像从纸上: 
性能
本文提供了DenseNet的准确性,击败了CIFAR 10,CIFAR 100和SVHN 
用法
导入densenet.py脚本并使用该DenseNet(...)方法创建具有各种参数的自定义DenseNet模型。
例子 :
import densenet
# 'th' dim-ordering or 'tf' dim-ordering
image_dim = (3, 32, 32) or image_dim = (32, 32, 3)
model = densenet.DenseNet(classes=10, input_shape=image_dim, depth=40, growth_rate=12,
bottleneck=True, reduction=0.5)
或者,为ImageNet导入预先构建的DenseNet模型,其中一些模型具有预先训练好的权重(121,161和169)。
例如:
import densenet
# 'th' dim-ordering or 'tf' dim-ordering
image_dim = (3, 224, 224) or image_dim = (224, 224, 3)
model = densenet.DenseNetImageNet121(input_shape=image_dim)
提供DenseNetImageNet121,DenseNetImageNet161和DenseNetImageNet169型号的权重(在版本选项卡中),首次调用时将自动下载。他们已经在ImageNet上接受过培训。权重从存储库https://github.com/flyyufelix/DenseNet-Keras移植。
要求
- Keras
- Theano(重量未测试)/ Tensorflow(测试)/ CNTK(重量未测试)
- h5Py
基于ImageNet预训练模型的微调卷积神经网络
创建这个回购的原因是没有太多的在线资源提供示例代码进行微调,并没有一个集中的地方,我们可以很容易地下载普通的ConvNet架构的ImageNet预训练模型,如VGG,Inception, ResNet和DenseNet。通过提供在Cifar10数据集上进行微调的工作示例,使用流行的ConvNet实现上的ImageNet预训练模型,这个回购可以弥补这个缺陷。
见这在Keras综合治疗微调深学习模型
用法
为了便于说明,假设您想用VGG-16进行微调。首先,将VGG-16的ImageNet预训练重量下载到imagenet_models目录中。在Cifar10上进行微调的架构和示例代码可以在这里找到vgg16.py。运行该文件:
python vgg16.py
该代码将自动下载Cifar10数据集并使用VGG-16进行微调。请注意,模型编译和加载ImageNet权重可能需要一段时间(最多分钟)。
使用你自己的数据集
如果您希望对自己的数据集进行微调,则必须将加载Cifar10数据集的模块替换为您自己的load_data()模块以加载自己的数据集。
X_train, Y_train, X_valid, Y_valid = load_data()
具体来说,必须执行下面的图像预处理步骤以获得与预训练模型兼容的数据集的格式:
# For Tensorflow
# Switch RGB to BGR order
x = x[:, :, :, ::-1]
# Subtract ImageNet mean pixel
x[:, :, :, 0] -= 103.939
x[:, :, :, 1] -= 116.779
x[:, :, :, 2] -= 123.68
# For Theano
# Switch RGB to BGR order
x = x[:, ::-1, :, :]
# Subtract ImageNet mean pixel
x[:, 0, :, :] -= 103.939
x[:, 1, :, :] -= 116.779
x[:, 2, :, :] -= 123.68