机器学习的回归评价指标
回归类算法的模型评估一直都是回归算法中的一个难点,但不像无监督学习算法中的轮廓系数等等评估指标,回归类与分类型算法的模型评估其实是相似的法则——找真实标签和预测值的差异。只不过在分类型算法中,这个差异只有一种角度来评判,那就是是否预测到了正确的分类,而在回归类算法中,有两种不同的角度来看待回归的效果:
第一,是否预测到了正确的数值。
第二,是否拟合到了足够的信息。
这两种角度,分别对应着不同的模型评估指标。
角度一、是否预测了正确的数值
回忆一下RSS残差平方和,它的本质是预测值与真实值之间的差异,也就是从第一种角度来评估回归的效力,所以RSS既是损失函数,也是回归类模型的模型评估指标之一。但是,RSS有着致命的缺点:它是一个无界的和,可以无限地大。我们只知道,我们想要求解最小的RSS,从RSS的公式来看,它不能为负,所以RSS越接近0越好,但我们没有一个概念,究竟多小才算好,多接近0才算好?
为了应对这种状况,sklearn中使用RSS的变体,均方误差MSE(mean squared error)来衡量我们的预测值和真实值的差异。均方误差,本质是在RSS的基础上除以了样本总量,得到了每个样本量上的平均误差。有了平均误差,我们就可以将平均误差和我们的标签的取值范围在一起比较,以此获得一个较为可靠的评估依据。
在sklearn当中,我们有两种方式调用这个评估指标,一种是使用sklearn专用的模型评估模块metrics里的类mean_squared_error,另一种是调用交叉验证的类cross_val_score并使用里面的scoring参数来设置使用均方误差。cross_val_score的均方误差为负。我们在决策树和随机森林中都提到过,虽然均方误差永远为正,但是sklearn中的参数scoring下,均方误差作为评判标准时,却是计算”负均方误差“(neg_mean_squared_error)。这是因为sklearn在计算模型评估指标的时候,会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss)。在sklearn当中,所有的损失都使用负数表示,因此均方误差也被显示为负数了。真正的均方误差MSE的数值,其实就是neg_mean_squared_error去掉负号的数字。
除了MSE,我们还有与MSE类似的MAE(Mean absolute error,绝对均值误差)。其表达的概念与均方误差完全一致,不过在真实标签和预测值之间的差异外我们使用的是L1范式(绝对值)。现实使用中,MSE和MAE选一个来使用就好了。
在sklearn当中,我们使用命令from sklearn.metrics import mean_absolute_error来调用MAE,同时,我们也可以使用交叉验证中的scoring = “neg_mean_absolute_error”,以此在交叉验证时调用MAE。
RSS残差平方和
MSE:均方误差
RMSE:均方根误差
MAE:平均绝对误差
角度二,是否拟合到了足够的信息
以上描述的都是评价标准的第一个角度,即:是否预测到了正确的数值。
对于回归类算法而言,只探索数据预测是否准确是不足够的。除了数据本身的数值大小之外,我们还希望我们的模型能够捕捉到数据的”规律“,比如数据的分布规律,单调性等等,而是否捕获了这些信息并无法使用MSE来衡量。比如,对数据进行回归,前端大部分预测的效果很好,但是后面部分的预测结果并不好,这样使用第一种角度考虑预测的结果,其实效果还很好,但是拟合的函数并没有准确的学习到数据的分布和走势。
故使用R2:决定系数,来从第二种角度来预测结果进行评价:
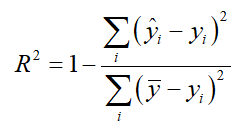
分子表示预测值与真实值的平方差之和,类似于均方误差;分母部分表示均值与真实值的平方差之和,类似于方差Var。根据R2的取值来判断模型的好坏。如果结果为0,说明模型拟合的效果很差,如果结果为1,说明模型无错误。
R-squared既考量了回归值与真实值的差异,也兼顾了真实值的离散程度。模型对样本数据的拟合度R-squared 取值范围 (-∞,1],值越大表示模型越拟合训练数据,最优解是1;当模型 预测为随机值的时候,有可能为负;若预测值恒为样本期望,R2为0。
分子(RSS离差平方和)是模型没有捕获到的信息总量,分母是真实标签所带的信息量(可以理解为方差:m被消除了)。
1- 模型没有捕获到的信息量/真实标签中所带的信息量 = 模型捕获到的信息量/真实标签中所带的信息量,所以,R^2 越接近1越好。
在sklearn中可以查看所有的模型评价指标:
如下代码:
#查看评价指标
import pprint
from sklearn import metrics
pprint.pprint(sorted(metrics.SCORERS.keys()))
- 1
- 2
- 3
- 4
输出结果:
['accuracy',
'adjusted_mutual_info_score',
'adjusted_rand_score',
'average_precision',
'balanced_accuracy',
'completeness_score',
'explained_variance',
'f1',
'f1_macro',
'f1_micro',
'f1_samples',
'f1_weighted',
'fowlkes_mallows_score',
'homogeneity_score',
'jaccard',
'jaccard_macro',
'jaccard_micro',
'jaccard_samples',
'jaccard_weighted',
'max_error',
'mutual_info_score',
'neg_brier_score',
'neg_log_loss',
'neg_mean_absolute_error',
'neg_mean_gamma_deviance',
'neg_mean_poisson_deviance',
'neg_mean_squared_error',
'neg_mean_squared_log_error',
'neg_median_absolute_error',
'neg_root_mean_squared_error',
'normalized_mutual_info_score',
'precision',
'precision_macro',
'precision_micro',
'precision_samples',
'precision_weighted',
'r2',
'recall',
'recall_macro',
'recall_micro',
'recall_samples',
'recall_weighted',
'roc_auc',
'roc_auc_ovo',
'roc_auc_ovo_weighted',
'roc_auc_ovr',
'roc_auc_ovr_weighted',
'v_measure_score']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
****************补充
分类问题的评价指标是准确率,那么回归算法的评价指标就是MSE,RMSE,MAE、R-Squared
①RMSE(Root Mean Square Error)均方根误差
衡量观测值与真实值之间的偏差。常用来作为机器学习模型预测结果衡量的标准。
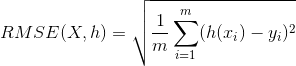
②MSE(Mean Square Error)均方误差
MSE是真实值与预测值的差值的平方然后求和平均。通过平方的形式便于求导,所以常被用作线性回归的损失函数。
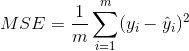
③MAE(Mean Absolute Error)平均绝对误差
是绝对误差的平均值。可以更好地反映预测值误差的实际情况。
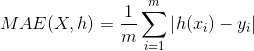
④R-squared
R Squared又叫可决系数(coefficient of determination)也叫拟合优度,反映的是自变量x对因变量y的变动的解释的程度.越接近于1,说明模型拟合得越好。 在sklearn中回归树就是用的该评价指标。
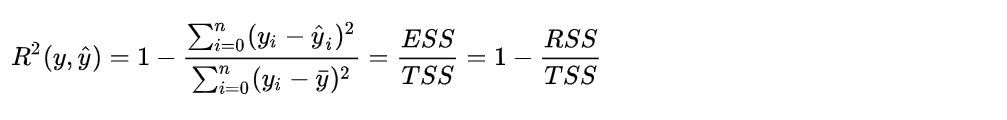

参考:https://blog.csdn.net/weixin_44441131/article/details/109037673
https://blog.csdn.net/qq_39777550/article/details/107322783
分类问题的评价指标是准确率,那么回归算法的评价指标就是MSE,RMSE,MAE、R-Squared
①RMSE(Root Mean Square Error)均方根误差
衡量观测值与真实值之间的偏差。常用来作为机器学习模型预测结果衡量的标准。
②MSE(Mean Square Error)均方误差
MSE是真实值与预测值的差值的平方然后求和平均。通过平方的形式便于求导,所以常被用作线性回归的损失函数。
③MAE(Mean Absolute Error)平均绝对误差
是绝对误差的平均值。可以更好地反映预测值误差的实际情况。
④R-squared
R Squared又叫可决系数(coefficient of determination)也叫拟合优度,反映的是自变量x对因变量y的变动的解释的程度.越接近于1,说明模型拟合得越好。 在sklearn中回归树就是用的该评价指标。