问题背景
本文是kaggle中的案例,员工离职分析,数据集中包括可能影响员工离职的各种因素(包括绩效水平,岗位, 薪资水平等九个变量) 以及员工是否离职标签。
数据来源于kaggle官网kaggle/hr-analytics ,(下载不方面的同学可以留言)
数据挖掘目标: 找出影响员工离职的因素,并建立员工是否离职预测模型
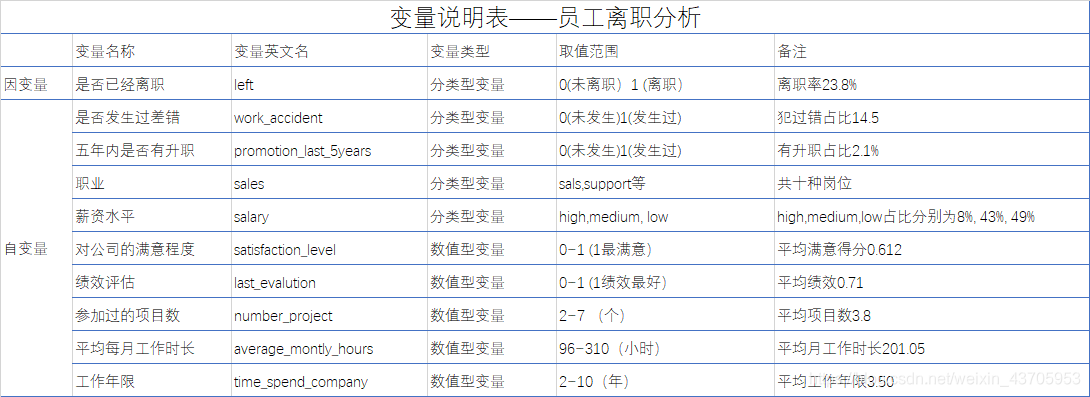
变量说明
下面是变量说明表,对数据集中的所有变量进一步解释说明
读取数据与数据展示
1 读取数据
# 员工离职分析
import pandas as pd
import matplotlib.pyplot as plt
# 1读取数据
data=pd.read_csv('HR_comma_sep.csv')
2 数据初探
使用data.info()查看总体信息,共有10个变量,样本量为14999,且数据质量很高, 没有空值,
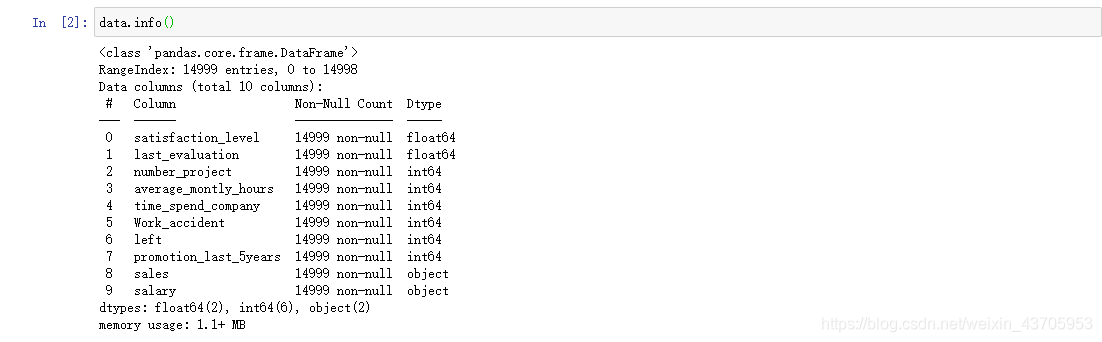
data.shape 查看数据框形状

data.columns查看各列名称

data.head() 查看前十行数据
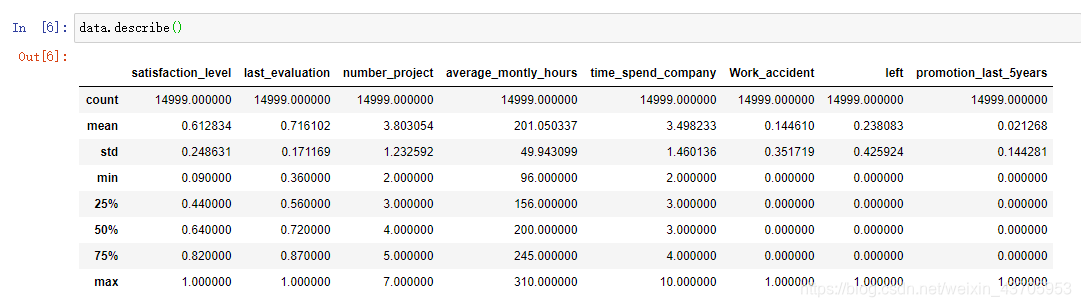
data.describe() 各变量数据特征一览。
描述性统计
数值型变量的分布——箱型图
为了区别, 将原数据‘sales’列名改为’jobs’ ,并将因变量放在第一列。
# 为了区别, 将原数据‘sales'列名改为’jobs'
data.columns=['satisfaction_level', 'last_evaluation', 'number_project', 'average_montly_hours', 'time_spend_company', 'Work_accident', 'left','promotion_last_5years', 'jobs', 'salary']
# 为了方便处理,将相应变量'left',放在第一列
data = data.reindex(columns = [ 'left','satisfaction_level', 'last_evaluation','number_project','average_montly_hours', 'time_spend_company', 'Work_accident','promotion_last_5years', 'salary','jobs'])
# 3.1 数值型变量分布
plt.rcParams['font.sans-serif'] = ['simsun'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = True # 解决保存图像是负号'-'显示为方块的问题
plt.rcParams['boxplot.medianprops.color'] = 'red'
columns_number = ['satisfaction_level', 'last_evaluation', 'number_project',
'average_montly_hours', 'time_spend_company'] # 数值型标签
title_Chinse = ['满意程度', '绩效', '项目数', '月均工作时长','工作年限']
fig = plt.figure(figsize=(10,5),num=1)
subplot_num = len(columns_number)
for i,col in enumerate(columns_number):
plt.subplot(1, 9, 2*i+1)
plt.boxplot(data[col], widths=0.5)
plt.title(title_Chinse[i])
plt.xlabel(col)
plt.xticks([])
del i, col, subplot_num

除了工作年限之外,员工满意程度,绩效,项目数,月均工作时长都没有离群点,员工平均满意度高于0.5, 半数员工有过四个以上项目,半数员工月均工作时长在200小时以上,加班较严重哈。
分类型变量的分布——饼图
# pie图是处理候数据,输出各类别频数 和value_counts()方法搭配
fig = plt.figure(dpi=300,num=2)
data_temp = data.copy() # 浅复制,基于地址的内存管理。 为了讲1,0改为yes,no的临时数据
data_temp['Work_accident'] = ['Yes' if i==1 else 'No' for i in data['Work_accident']]
data_temp['promotion_last_5years'] = ['Yes' if i==1 else 'No' for i in data['promotion_last_5years']]
columns_class = ['Work_accident', 'promotion_last_5years', 'jobs', 'salary']
for i,col in enumerate(columns_class):
#print(i,col)
count = data_temp[col].value_counts()
plt.subplot(2,2,i+1)
plt.pie(count, labels = count.index,startangle=90)
plt.title(col)
del data_temp,i,col,count

犯过错的员工占比较少,五年内有过升职的员工更少。 销售部门员工最多,其次是技术部门,管理最少。接近一半的员工工资较低, 只有8%员工拿到高工资。
数值型自变量与分类型因变量关系可视化——箱线图
fig = plt.figure(figsize=(13,6),num=3)
for i,col in enumerate(columns_number):
left_num = data.loc[data['left']==1, col]
unleft_num = data.loc[data['left']==0, col]
plt.subplot(1,5,i+1)
plt.boxplot([unleft_num, left_num],positions=[0.1,0.5],widths=0.3)
plt.xticks(ticks=[0.1,0.5],labels=['未离职','离职'])
plt.title(title_Chinse[i])
plt.show()
del i,col,left_num,unleft_num

从图中可以看出,离职员工对公司的满意程度更低,绩效更高,可能是能力强的人跳槽的机会更多。离职的人项目数分布更广。离职的人工作时间也更长,看来加班不利于留住员工,望资本家们慎重,毕竟招聘也是有成本的呀。 最后,离职员工工作年限也更高。
分类型(两类别)自变量与分类型因变量关系可视化——百分比堆积图
fig = plt.figure(num=4)
for i,col in enumerate(['Work_accident', 'promotion_last_5years']):
plt.subplot(1,2,i+1)
# 第一组要的是, x轴是自变量, 更
left_y,left_n,unleft_y,unleft_n =0,0,0,0
for j in range(len(data)):
if data.loc[j,'left']==1 and data.loc[j,col]==1:
left_y+=1
elif data.loc[j,'left']==1 and data.loc[j,col]==0:
left_n+=1
elif data.loc[j,'left']==0 and data.loc[j,col]==1:
unleft_y+=1
else:
unleft_n+=1
rate = pd.Series([left_y/(left_y+unleft_y),left_n/(left_n+unleft_n)])
x=[1,1.2]
plt.bar(x, height=rate, width=0.1,label='离职')
plt.bar(x, height=1-rate,width=0.1,bottom=rate,label='未离职')
plt.xlabel( col+'?')
plt.xticks(ticks=[1,1.2,1.4,1.6],labels=['是','否','',''])
plt.legend(loc='upper right' )
del i,j,col,left_y,left_n,unleft_y,unleft_n,rate,x

可以看到没有犯错的员工离职比列更高,没有升职的员工离职的比例远远高于升职的员工。
分类型(多类别)自变量与分类学因变量关系可视化———折线图
for col in ['jobs', 'salary']:
data[col].value_counts()
rate = []
for cla in data[col].value_counts().index:
print(cla)
zipper = zip(data['left']==1, data[col]==cla)
rate.append(len(data.loc[[all(i) for i in zipper],]))
rate = pd.Series(rate).values/data[col].value_counts().values
fig = plt.figure(figsize=(10,5))
plt.plot(range(0,2*len(rate),2),rate,'o-',label='left rate')
plt.xticks(range(0,2*len(rate),2),labels =data[col].value_counts().index )
plt.grid()
plt.xlabel(col)
plt.legend(loc='best')
plt.title('离职率对比')
plt.show()
del rate,col,cla,zipper
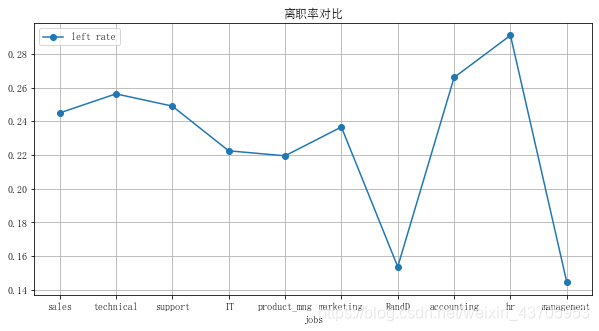

各部门的离职率差异较大, 人力部门离职率最高,rand部门离职率最低。 薪资水平非常真实,工资越高离职率越低 。马云说的对啊,员工离职无非两点原因,钱给少了,心委屈了。
数据预处理
经过数据的描述性统计探究,总体上对各个变量以及各个变量对员工离职的影响有一定的了解, 下面开始建模。建模之前的数据预处理分为以下几个步骤。
- 之前的分析结果表明,该数据不需要做离群点,缺失值处理。
- 将分类学变量数字化,多类别无序变量转为one_hot编码
- 归一化处理,消除数据量纲的影响。
- 数据随机分为训练集和测试集两部分
# 数据转化 (分类型变量数字化)
from sklearn import preprocessing, model_selection,tree,naive_bayes,svm,metrics
# 分类型也分两种,无序和有序。 有序可以直接数字化,无序数字化会产生错误,转为one_hot编码
# salary 有序
salary = list(data['salary'].value_counts().index )
enc = preprocessing.OrdinalEncoder(categories = [salary])
enc.fit([['low']])
salary = enc.transform([[i] for i in data['salary']])
data['salary'] = salary
# jobs无序
jobs = list(data['jobs'].value_counts().index )
enc = preprocessing.OneHotEncoder(categories=[jobs])
enc.fit([['sales']])
jobs = enc.transform([[i] for i in data['jobs']]).toarray()
data.drop('jobs', inplace=True, axis=1) # 可以原地操作, 删除不需要的行或列
data = pd.merge(data, pd.DataFrame(jobs), left_index=True, right_index=True )
# 数据归一化处理
mmscaler = preprocessing.MinMaxScaler() # 实例化一个归一化对象
data.loc[:,['number_project', 'average_montly_hours', 'time_spend_company']] = mmscaler.fit_transform(data.loc[:,['number_project',
'average_montly_hours', 'time_spend_company']])
# 数据分割
X = data.iloc[:,1::] ; y= data['left']
#from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = model_selection.train_test_split(
X, y, test_size=0.3, random_state=0)
模型建立
这里分别用分类问题常用的几个模型建模, 决策树,朴素贝叶斯,支撑向量机。
# 训练模型
# 决策树
dt = tree.DecisionTreeClassifier()
dt = dt.fit(X_train,y_train)#[n_samples, n_features]
#dt.predict(data.iloc[1998:2010,1::]) # 预测数据的结构与X相同 ,返回结构与y相同
# 朴素贝叶斯
gnb = naive_bayes.GaussianNB()
gnb.fit(X_train,y_train)
gnb.predict(data.iloc[:,1::])
# 支持向量机
parameters=[{
'kernel':['rbf'],'gamma':[1e-3,1e-4], 'C':[1,10,100,1000]}]
clf = model_selection.GridSearchCV(svm.SVC(), parameters)
模型评估
分类算法常用指标评估
# 模型评估
# 1 常用分类指标的计算
data_pre = pd.DataFrame({
'dt':dt_pre, 'gnb':gnb_pre, 'svc':svc_pre})
# acuuracy
Scores = np.empty((3,4))
for i in range(3):
print(i)
y_pred = data_pre.iloc[:,i]
#accuracy
Scores[i,0]=metrics.accuracy_score(y_test, y_pred)
# precisoin
Scores[i,1]=metrics.precision_score(y_test, y_pred)
# recall
Scores[i,2]=metrics.recall_score(y_test, y_pred)
# f1_score
Scores[i,3]=metrics.f1_score(y_test, y_pred)
# 混淆矩阵
print(metrics.confusion_matrix( y_pred,y_test))
| 模型 | accuracy | precision | recall | f1_score |
|---|---|---|---|---|
| 决策树 | 0.97644444 | 0.92909761 | 0.97206166 | 0.95009416 |
| 贝叶斯 | 0.74 | 0.4625 | 0.78420039 | 0.58184417 |
| 支撑向量机 | 0.80155556 | 0.69129288 | 0.25240848 | 0.36979534 |
roc曲线
# 2 分类模型roc曲线
fig = plt.figure(dpi =300)
dtcurve = metrics.plot_roc_curve(dt, X_test, y_test)
gnbcurve = metrics.plot_roc_curve(gnb, X_test, y_test,ax=dtcurve.ax_)
svccurve = metrics.plot_roc_curve(svc, X_test, y_test,ax=dtcurve.ax_)
plt.title('各模型ROC曲线')
plt.show()

在员工离职分析上, 决策树性能更优 。
模型优劣势分析
1 变量分布没有检验,可能不满足高斯分布,使用基于高斯的朴素贝叶斯模型的效果有限 .
2 在数据处理时,对多分类变量做了one_hot编码处理, 使得维度增大,数据稀疏,支持向量机模型受到了限制。