GROUP-TRANSFORMER: TOWARDS A LIGHTWEIGHT CHARACTER-LEVEL LANGUAGE MODEL
INTRODUCTION
本文介绍了一种用于字符级语言建模的轻量级转换器。我们的方法是一种因式分解方法,它使用分组线性操作来分离transformer架构中的标准线性层,并在线性转换之间进行稀疏连接。该模型受到群卷积方法的启发,被称为Group Transformer,它们有效地压缩了移动设备上可用性的巨大图像处理模型。
当组策略减少了所提模块中的参数和计算量时,它对多个组的互斥计算降低了性能,导致组间相关性的信息丢失。为了弥补这个问题,我们为组注意层添加了两个组间操作,它们在组之间共享一个共同的特征,并为组前馈层添加了不同组之间的连接特征。通过对组间信息流的建模,组转换器不仅是高性能的,而且是轻量级的。据我们所知,group Transformer是使用group策略构建轻量级Transformer的第一次尝试。
RELATED WORKS
轻量化Transformer
自从Transformer成为一种很有前途的NLP任务模型以来,已经尝试使用两种主要的方法来提高它的效率。第一种是限制输入令牌之间的依赖关系,以减少不必要的成对计算。该方法在推理过程中提高了时间效率,但没有解决Transformer的重参数化问题。第二种方法是开发轻量级的网络架构,同时维护Transformer的属性。例如,Tay等人(2019)利用四元数代数构建Transformer的轻量级模块。它们也使用了对嵌入层的分量进行因式分解,但是基于四元数原理的分解后的分量之间的连接限制了表达式的能力。另一种方法将多头注意和点向前馈层相结合,设计出参数较少的统一模块。尽管尝试了这些架构上的改变,他们的模型仍然难以提供一个仍然有近30万个参数的轻量级语言模型。在这项工作中,我们描述了一个小于10M参数的轻量级转换器,它与以前的字符级语言模型相比是非常小的。
分组策略
一种分组策略最近引起了广泛的关注,它可以压缩许多大而深的卷积神经网络(CNNs) (Krizhevsky et al., 2012;Szegedy等人,2015;Chollet, 2017)。例如,当组策略应用于权值![]() 的标准线性层时,将特征映射划分为G组。结果,该层被G个小的线性层替换,每个层的权值
的标准线性层时,将特征映射划分为G组。结果,该层被G个小的线性层替换,每个层的权值![]() ,导致显著的参数约简。尽管从直觉上看很吸引人,但有报道称,将组策略应用于模型常常会导致巨大的性能下降,因为不同组中的特性不能彼此交互。为了克服这个问题,ShuffleNet (Zhang et al., 2018)提出了通道洗牌操作,使不同组之间进行交互。这种思想也被应用于递归神经网络(RNNs)。Kuchaiev & Ginsburg(2017)提出了分组式RNN作为一种特殊的集合rns形式。但是,他们没有考虑不同群体之间的相互作用。受ShuffleNet的启发,Gao等人(2018)将shuffling的思想结合到组明智的RNN中,并取得了有希望的结果。在这项工作中,我们采用了组策略,并构建了适合于Transformer架构的组明智操作。
,导致显著的参数约简。尽管从直觉上看很吸引人,但有报道称,将组策略应用于模型常常会导致巨大的性能下降,因为不同组中的特性不能彼此交互。为了克服这个问题,ShuffleNet (Zhang et al., 2018)提出了通道洗牌操作,使不同组之间进行交互。这种思想也被应用于递归神经网络(RNNs)。Kuchaiev & Ginsburg(2017)提出了分组式RNN作为一种特殊的集合rns形式。但是,他们没有考虑不同群体之间的相互作用。受ShuffleNet的启发,Gao等人(2018)将shuffling的思想结合到组明智的RNN中,并取得了有希望的结果。在这项工作中,我们采用了组策略,并构建了适合于Transformer架构的组明智操作。
Group Transformer
图1a显示了Group Transformer的总体架构。它包括一个组嵌入(底部灰色框),将一个字符嵌入到分组的特征中,一个组注意(黄色框),它包含识别时域依赖关系的注意模块,和一个组前馈层(绿色框),它重新配置分组的特征。可以看出,当输入字符给定时,Group Transformer将输入转换为多个组表示(蓝点和红点),处理并合并它们以预测下一个字符。图1b和1c显示了子模块中组间信息流(蓝色和红色箭头)和组间信息流(灰色箭头)。在没有组间信息流的情况下,对分组后的特征进行独立处理。我们观察到,组间建模确保了组能够意识到其他组,并防止不同的组持有相同的信息。下面的小节描述了子模块的体系结构细节及其关系。

图1:当组数量为2时,组转换器及其子模块的架构概述。灰色箭头表示整个组的信息流,蓝色和红色箭头表示每个组的信息流。
GROUP EMBEDDING LAYER
组嵌入层标识一组表示令牌的嵌入。使用一组向量来表示句子、单词甚至字符的想法可以在许多NLP模型中广泛发现,这些NLP模型通过连接(或求和)其嵌入和其子单元的嵌入来嵌入输入标记。类似地,我们假设一个字符c用组的G向量表示,即![]() 其中,
其中,![]() 。当给定一个字符时,组嵌入层检索相应的一组向量,并将其传递给下一组注意层。通过本文,我们描述了一个单一时间步长的过程。
。当给定一个字符时,组嵌入层检索相应的一组向量,并将其传递给下一组注意层。通过本文,我们描述了一个单一时间步长的过程。
GROUP ATTENTION LAYER
注意机制识别时域特征之间的依赖关系,并结合这些特征的信息。它包含三个步骤;(1)识别查询、键和值,(2)在不同时间检索相关特征,(3)将参与的特征转换为输入域。本文的研究重点是将群策略应用于变压器的特征空间。因此,我们让第二步与原来的Transformer相同,重点放在第一步和第三步。
图1b解释了群体注意力的结构。多头注意模块表示第二步,下操作识别第一步的查询,上操作转换第三步的注意输出。我们注意到,我们没有在图中表示multi-head attention块的键和值,因为它们可能来自另一个源域。分组注意通过组内操作(白盒)和组间操作(灰盒)处理分组特征。
Grouped Queries, Keys and Values
令x = [,…,
]为g组的输入向量集合,其中
∈
。由于多注意包含单个组的H个注意模块,所以组注意首先计算g组及其头H的查询
如下:

![]()
![]()
![]()
![]()
Multi-head Attention
识别的头元素用于连接时域特征。在这一步中,位置编码对于特征在输入序列中的位置感知起着重要作用。本文利用相对位置编码有效地描述了一个长字符序列。在Dai等(2019)的基础上,我们定义了具有相对位置信息的注意分值图,注意机制决定了g组h头部的注意特征。
Combination of Multiple Heads
多个头[,…
]合并如下:
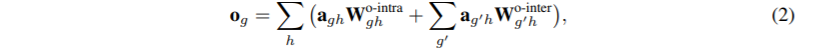

GROUP FEED-FORWARD LAYER
Group前馈层配置注意模块的输出,ˆxg,通过应用group-wise操作在每个位置。图1c显示了所提议的模块的体系结构。可以看到,这些组被打乱(灰色框)并相互支持。通过两个线性变换和一个非线性激活处理组态特征。与原始模块一样,我们的模块中的线性层将输入特征转换为高维空间,并进行非线性激活,将输出转换回输入空间。
组前馈层的形式化解释如下:鉴于G输入特性(ˆx1,…,ˆxG)、组前馈层转置到一个高维空间如下分组功能。
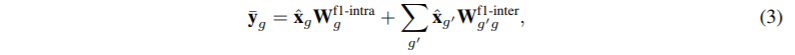
![]()
最后,对高维特征进行一组线性变换:
![]()
其中![]() 为线性加权。对于残差连接,将每个分组输入特征加入到分组前馈层的输出中;
为线性加权。对于残差连接,将每个分组输入特征加入到分组前馈层的输出中;![]()
