布隆过滤器,看名字就知道,不就是一个过滤器么!首先,过滤器大家都知道,像筛子啊,纱网啊等用来过滤大颗粒的工具。使用过滤器可以过滤一些不需要的东东,最终获取我们想要的。还记得某个矿泉水的广告么,全部工序经过20道以上的过滤流程!牛皮爆了!可能过滤沙子什么的也都算一层过滤吧!【微微一笑:呵呵】
前几天,看Redis方面的东西的时候,看到了一个结构,叫做BitMap,等看完之后,我打呼:好家伙,这不就是布隆过滤器的根子么!于是,我默默在心里打个箭头,指向了布隆过滤器。
来来来,先加个百度词条,秀点字数:
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
这种词条解释,有些哥们可能不是很明白,咱们还是用通俗的话来说下。
布隆过滤器,简单来说就是过滤用的,怎么过滤呢?首先,我准备一段很大的数字段,比如从0到1亿,然后每个数字上都有一个对应的true和false值,默认的是false。然后我这边接收到一个请求,请求中有一个参数,比如Id。我要怎么过滤呢?首先,我先把数据库中所有的Id,多次求hash(先来3次吧),那么就会有3个hash值,接着,我就把这3个数字对应数字段上的值改成true,如果数据库有30万数据,我就求了90万次hash,然后把这些hash对应数字段上的值都改成了true,当然可能有重复的。(这个都是提前做好的,起码请求到来之前已经搞完了,嘿嘿。)
请求到来之后,我对请求的参数进行求hash,嗯,也是3次,然后从这个数字段上查看对应的值,如果是true,就让你过,如果有一个是false,那么对不起,你这个id明显不在数据库啊,爱哪哪去,爷不伺候了!
当然,求hash在某一数据段内也会有重复,也有可能来了一个数据,它特别幸运,虽然数据库中没有它,但是3次求hash上面的值都是true,它也从过滤器中溜了过去!
所以,布隆过滤器就有这么一个特性,存在的一定能通过,不存在的可能会通过。
大家这个时候不要抬杠哈,过滤器主要是针对负载、攻击进行一层拦截的,哪怕有一些漏网之鱼,最终经过代码的处理,对服务器或者DB的伤害几乎微不可查了,这种少量的数据处理,是可以接受的。
我们来看个简单的示意图:
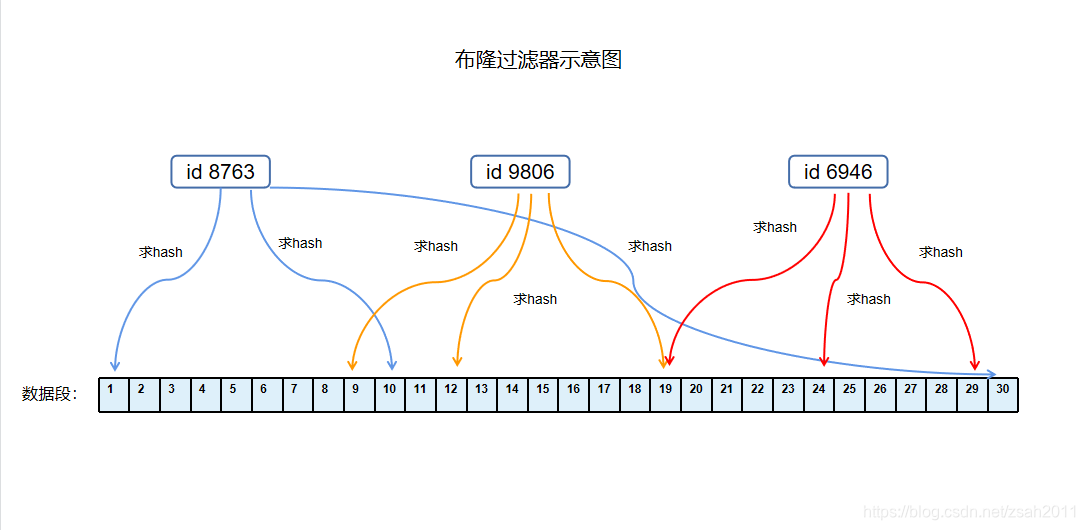
如图,下面那个数据段就是我们提前准备好的,而且数据提前求hash,修改数据段中的true和false。当请求来的时候,根据求hash来判断是否对数据进行过滤。
好了,模型图已经出来了,我们要怎么实现呢?
难道创建一个数组?唉! 刚好哎,这个数据段不就是一个数组么?然后在数据里面写上true和false,这样功能不就实现了?
不错,功能是实现了,看示意图也能明白,这个数据段必须十分大,否则随随便便就填充满了,都是true,那么,还有啥过滤的必要?咱们不说多,就千万级吧!你确定要创建一个千万级别的数组或者说是list?先不说这个能不能很好的过滤攻击,就这个千万级别的数组,都够服务器受的!来来来,给你小算一下,Java中创建一个对象,咱们按照最小的算吧,也要16Byte,乘以千万,也就是1.6亿Byte,也就是1GB左右了。
然后,你还要对这个1GB的数组进行多次查询判断,然后过滤。
先不说能不能减轻服务器压力,如果多来几个这种布隆过滤器,那么,恭喜你!game over!服务器直接挂了,还要啥过滤器!

布隆过滤器:“数组肯定是不能用的,这辈子打死都不用数组!咱也是有节操的过滤器!”
既然不用数组,那要用什么呢?百度词条里面也说了-------一个很长的二进制向量。
关于二进制,这里面牵涉到一部分计算机底层了,我在这里稍稍解释下。
计算机编程,最终从高级语言,诸如java,C,C++等,然后到汇编语言,再到机器语言,最终都将化作两个数字0和1,计算机也只认识这两个数字,什么if..else..?爱哪哪去!
早起的大型计算机其实也就是打孔识别,不过经过一代代更新换代,目前的计算机已经不知道超出了祖辈多少,不管是存储还是计算能力。
好吧,说多了。
对于存储大家都十分熟悉吧?哪怕不知道底层,但是平时总会经常接触到。比如某某某硬盘中几百个GB的动作片,手机又用了几十MB的流量等等等等,这些其实也是1和0这两个数字的传输。
大家熟悉的单位一般是TB(1024GB),GB(1024MB),MB(1024KB),KB(1024B),B(Byte),那么B就是最小的单位了么?
NO!这个B(Byte)距离1和0还有一段距离,那就是bit,1Byte = 8 bit,而bit才真正是传说中1和0存储的地方,1bit就是一个存储1或者0的地方。 那么,显而易见,1Byte就占据了8位,1KB就是1024*8 = 8192位,1MB就是8,388,608位,如果每一位代表一个数字,就可以表示8,388,608(百万级),然后再通过1和0表示true和false,那岂不是1MB就可以表示8百多万的数据段?而且能直接定位某个数字,直接返回0和1,速度直接是O(1),这不就是为布隆过滤器而生的么?哦,不,反了,应该是布隆过滤器不是正好利用这个存储机制么?我们来看个示意图:
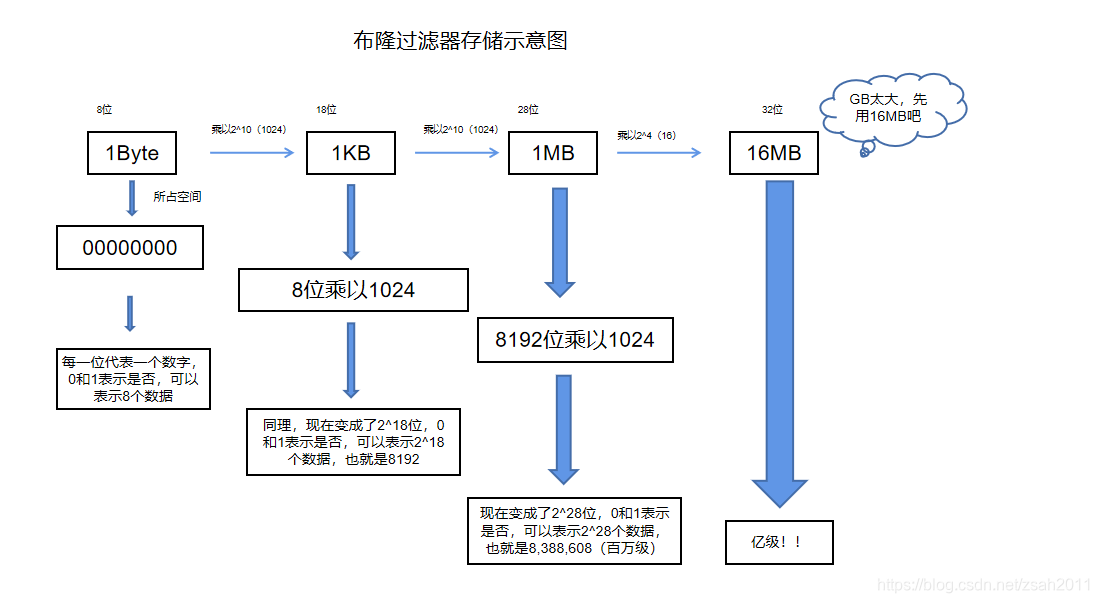
看看,仅仅耗费10-20M左右的空间就能完成布隆过滤器,它不香么?要啥数组啊!布隆过滤器理解起来十分简单,不过自己独立实现的话也有一点小麻烦的,不过,Don't warry! Java中都有封装好的,嘿嘿,先来一起看看。
public class BloomTest {
// 需要存储的数据,数据段的话是后台创建的,是根据下面的概率来的, 不用你管的,
private static int dataAmount = 500000;
// 百分比,就是漏网之鱼的概率,布隆过滤器总有一些不存在的数据能通过,
//这个就是不存在的数据能通过的概率
// 千分之一的概率
private static double rate = 0.001;
public static void main(String[] args) {
// 本来想用Integer的,但是字段哪可能刚好是数字啊,字符串的可能更大,适应性更强,反正也是求hash,差别不大。
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.defaultCharset()), dataAmount, 0.001);
// 先塞数据吧
for (int i = 0; i < dataAmount; i++) {
String uuid = UUID.randomUUID().toString();
bloomFilter.put(uuid);
}
//数据放好了,开始拦截呗,放50000数据过来呗,
int number = 0;
for (int i = 0; i < 50000; i++) {
String uuid = UUID.randomUUID().toString();
if (bloomFilter.mightContain(uuid)){
number++;
}
}
System.out.println("50000条数据误判的数据量为:"+number
+"\n所占百分百:"+ new BigDecimal(number).divide(new BigDecimal(50000)));
}
}大家可以自己运行下这个main方法,百分比是接近0.001 这数字的,或多或少,下面是我执行的某一次的结果:
50000条数据误判的数据量为:51
所占百分百:0.00102
Process finished with exit code 0
对了,复制代码的的时候记得添加依赖哦,谷歌的BloomFilter 的maven依赖(版本什么的,看你喽):
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</dependency>
怎么样?这个布隆过滤器使用起来是不是很方便,是不是so easy!是不是真来劲?嘿嘿,然并卵,没多少人用的。
这个是单个服务器的 布隆过滤器,现在部署服务,还单机?你在逗我!分布式环境下,你每台机器来个布隆过滤器,内存不要钱啊?你土豪?那您请。
Redis:“分布式环境?我熟啊,来来来,让我来,嘿嘿!”。
于是,Redis有上场了!这个Redis中布隆过滤器的实现,有些哥们是自己实现的,不过在java整合Redis里面是有封装的,为了简单,我没有构造bean注入,只是写了已经简单的test方法,然后通过构造方法,把redisson引入,然后就直接使用布隆过滤器了。
public class RedissonBloomTest {
// 需要存储的数据,数据段的话是后台创建的,是根据下面的概率来的, 不用你管的,
private static int dataAmount = 1000000;
// 百分比,就是漏网之鱼的概率,布隆过滤器总有一些不存在的数据能通过,
//这个就是不存在的数据能通过的概率
// 千分之一的概率
private static double rate = 0.001;
// 客户端服务,spring中,应该是创建bean,然后直接注入的,我这边为了简单把Redisson在构造方法中初始化了
RedissonClient redisson;
public static void main(String[] args) {
//获取redissonClient 服务
RedissonClient redissonClient = new RedissonBloomTest().getRedisson();
//获取(创建)布隆过滤器
RBloomFilter<String> redisBloomFilter = redissonClient.getBloomFilter("RedisBloomFilter");
//初始化布隆过滤器
redisBloomFilter.tryInit(dataAmount, rate);
// 代码copy过来
// 先塞数据吧
for (int i = 0; i < dataAmount; i++) {
String uuid = UUID.randomUUID().toString();
//这里塞数据就很慢了,建议少放点数据,生产中肯定要提前弄好,不然很容易出事故哦
redisBloomFilter.add(uuid);
}
//数据放好了,开始拦截呗,放100000数据过来呗,
int number = 0;
for (int i = 0; i < 100000; i++) {
String uuid = UUID.randomUUID().toString();
if (redisBloomFilter.contains(uuid)){
number++;
}
}
System.out.println("100000条数据误判的数据量为:"+number
+"\n所占百分百:"+ new BigDecimal(number).divide(new BigDecimal(100000)));
redissonClient.shutdown();
}
static Config config = new Config();
static {
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379");
}
public RedissonBloomTest(){
redisson = Redisson.create(config);
}
public static Config getConfig() {
return config;
}
public RedissonClient getRedisson() {
return redisson;
}
}这个是我运行之后的结果:
100000条数据误判的数据量为:1847
所占百分百:0.01847这个结果好像离设定的错误率有点差距,看了下布隆过滤器的size,对比谷歌的,百万级的数据,布隆过滤器大小差不多,都是千万级。不过这个falseProbability似乎有点差距。(如果哪位看出来,还请不吝指教!)
这个问题可能还要磕一下,下面看下布隆过滤器的优缺点吧:
优:简单,方便,容易对大批量数据进行过滤处理
缺:需要提前对数据进行整理添加,而且只能一次性使用,如果基础数据有删除,新增的话,布隆过滤器就要重置,很不方便。
还有就是布隆过滤器的应用场景:
1、面试中常问的缓存穿透,使用布隆过滤器,直接过滤掉
2、对大数据进行去重,比如爬虫系统中,我们需要对 URL 进行去重
3、垃圾邮件过滤功能也普遍用到了布隆过滤器,因为用了这个过滤器,所以平时也会遇到某些正常的邮件被放进了垃圾邮件目录中,这个就是误判所致,概率很低。
险之又险,在月末才输出这一篇。
no sacrifice,no victory~
感觉写的还过得去的话,给个赞吧~