布隆过滤器是用来处理爬虫去重问题或者黑名单问题的。
爬虫去重问题:将访问过的URL存储在数据库中,对于新进的URL,判断数据库中是否存在这个URL。(URL的量很大)
黑名单问题:假设给定100亿个URL是黑名单,用户输入一个URL,判断这个URL是否在黑名单中存在。
我们以黑名单问题举例:
布隆过滤器:
1:首先准备一个比特类型的数组,数组的大小为m。
如何准备呢?
我们知道,一个整型的大小是四个字节,一个字节是八个比特,所以一个整型是32个比特。我们可以用一个整型数组来构造出一个比特类型的数组。
假设现在有一个整型数组a[1000],那么它代表大小为1000*32的比特类型的数组。
如何实现这个比特类型的数组呢?
代码如下:
void tuhei(int m)//将比特数组中m位置标记
{
int intIndex=m/32;
int bitIndex=m%32;
arr[intIndex]=(arr[intIndex]|(1<<bitIndex));
}
int main()
{
int arr[1000];
memset(arr,0,sizeof(arr));
tuhei(30000);
}
2:对于每一个黑名单里的URL,我们通过K个哈希函数算出K个哈希值(有可能小于K个),然后把每个哈希值都(%m),对于每个哈希值(%m),我们都能对应到比特数组中的某个位置,相应的把这个位置给标记。
3:对于用户给定的URL,我们还是通过相同的K个哈希函数算出K个哈希值,然后把每个哈希值都(%m),对于每个哈希值(%m),我们都能对应到比特数组中的某个位置,如果每个对应位置都已经被标记了,我们就可以肯定用户给定的URL在黑名单中(因为之前这个URL已经算过了,对应位置都已被标记了),只要有一个位置没有被标记,说明用户给定的位置没有在黑名单中。
布隆过滤器对于每个在黑名单中的URL,都可以给出正确的判断,但是如果一个URL不在黑名单中,布隆过滤器有可能判断错误,判断为这个URL在黑名单中。(因为哈希函数的性质:对于不同的输入,哈希函数有可能给出相同的输出)。
对于上图中的m,k,我们可以给出公式来计算:
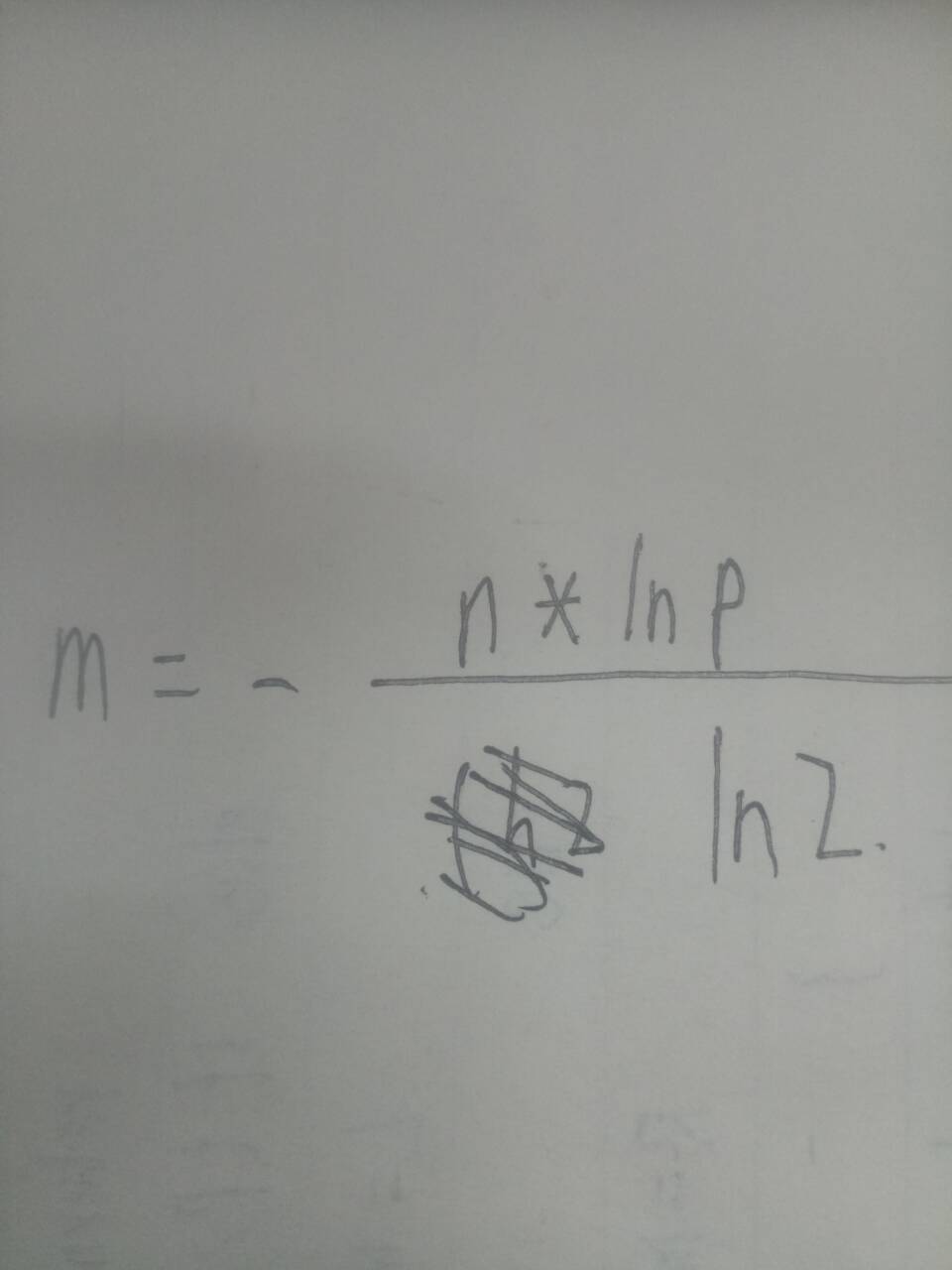
其中,m为比特数组应该开的大小,n为样本量(本题中为URL的个数),p为预期失误率。
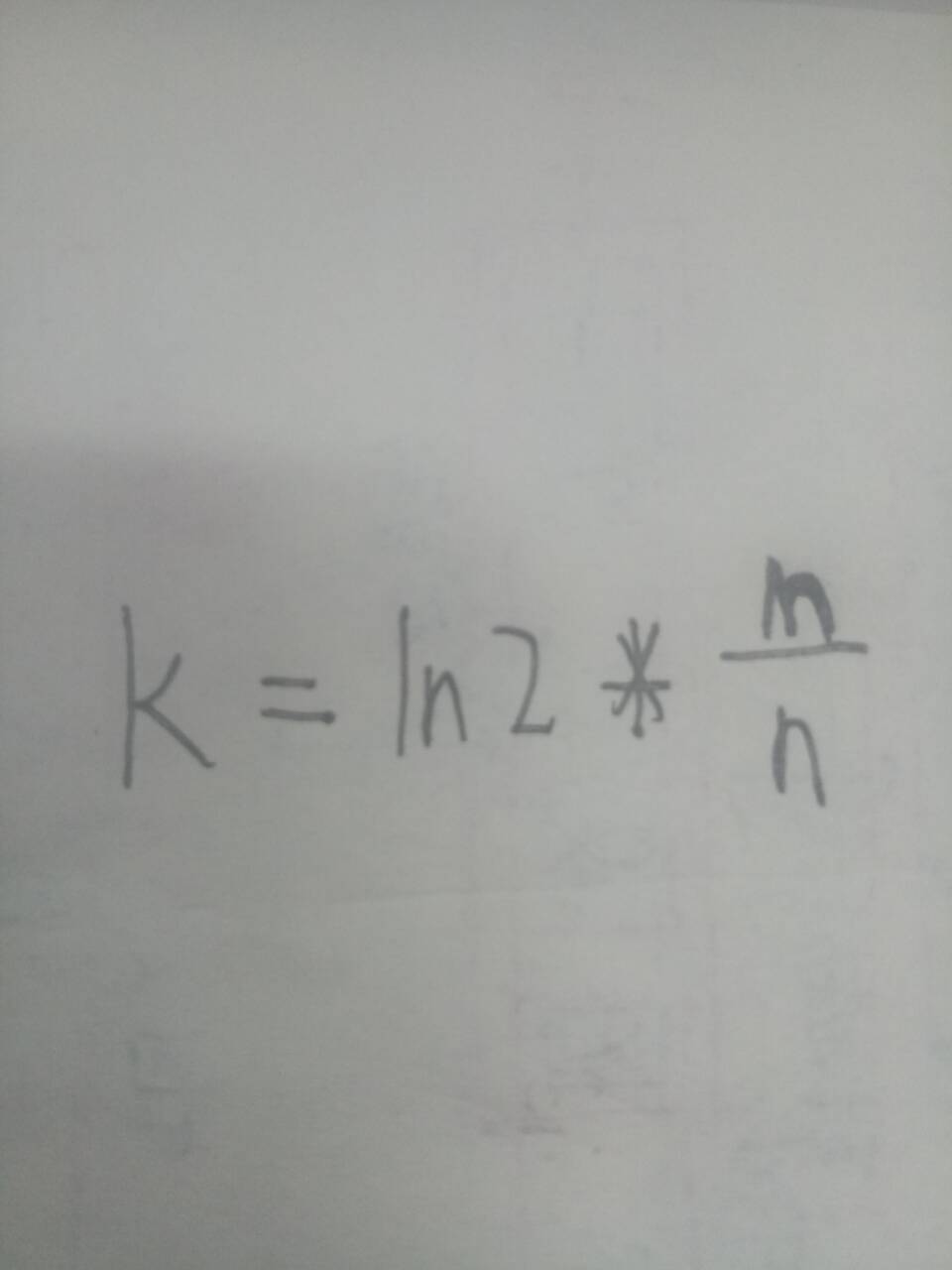
其中,k为哈希函数的个数,n为样本量(本题中为URL的个数),m是比特数组应该开的大小。
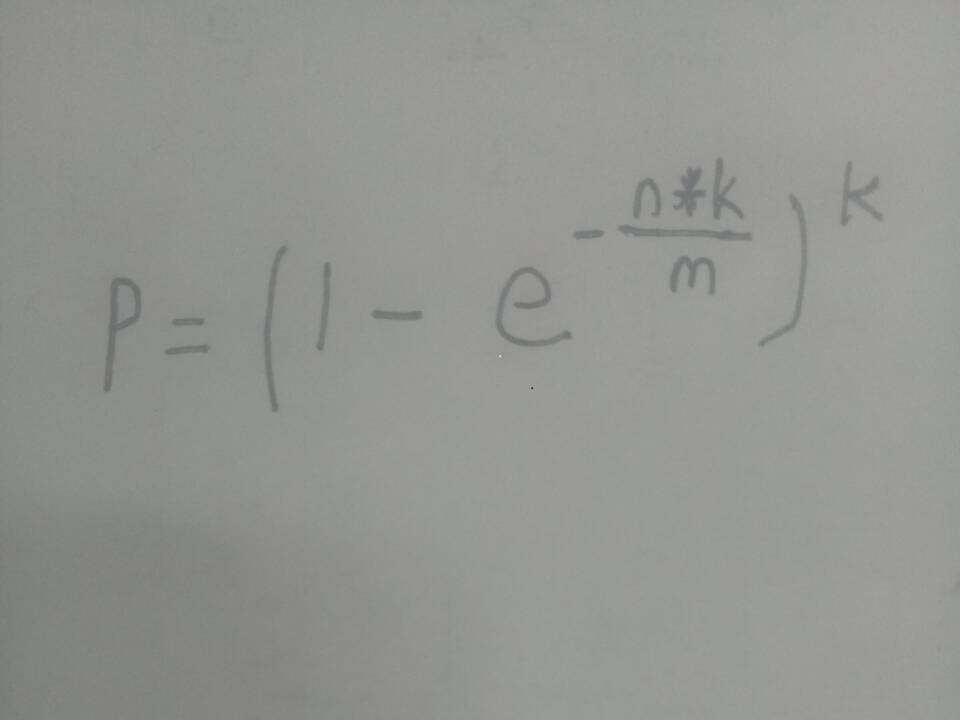
其中,p为实际的失误率(和上面的p不一样),n为样本量(本题中为URL的个数),m是比特数组应该开的大小,k为哈希函数的个数。
当m越大,k越大时,p(实际失误率)越小。