认识布隆过滤器
//布隆过滤器和一致性哈希
//布隆过滤器就是爬虫项目,和黑名单项目的常见结构
//查询某一个结构是否存在于某一个集合之中

落地结构:
大数组结构,每一个位置是一个比特位bite

布隆过滤器产生失误的原因:
假如现在有100亿个URL现在你只给了10个位,4个哈希函数,每次涂黑四个位,那么这10个位注定被越图越黑,等到查找的时候,你就会发现,查啥都是错的。
要是有10个URL,你给出了100亿个位,这时候肯定都是对的。
问题就是这个大数组给多大的问题
布隆过滤器的出现就是为了解决超大数据查找的问题,在使用空间较小的情况下,小概率失误的情况
布隆过滤器的查找条件
布隆过滤器和要查找的东西的大小没关系,和查找的东西的个数有关系
如何根据条件确定布隆过滤器
对于布隆过滤器来说,你只需要告诉我,你所要存储的元素的个数,以及你所能容忍的失误率,此时给你计算出需要一个多少比特位的大数组,以及计算所需的K个哈希函数的个数,一单大数组以及哈希函数个数一确定,所有东西都确定了,也就是说,你给出的条件只需要你需要计算的元素个数,以及你能容忍的容错率
数学公式:

m:需要多大的一个bite位数组
K:需要的哈希函数个数
前两个公式一旦发生小数都是向上取整
但是一但向上取整,必定错误了发生改变
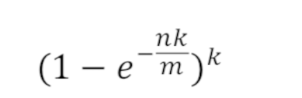
所以用上面这个公式来求真实的容错率,需要的是真实容错率小于真实的容错率就对了。

所以说一旦有人问你,一个和黑名单有关的问题,并且给你的空间和实际需要的空间差的很大,你多问一句允不允许有失误率。一听就知道你你是内行,上道了。
一致性哈希


还有一点忘了说就是,在前端服务器上有一个数组,这个数组里面存的是后面存储服务器的哈希值的值,并且是按顺序来存储的,这样的在接收到一个请求的话,就很方便使用二分法查找到这个请求对应所应该对应的服务器。
上面的机器成环存在两个问题:
这两个问题都是有哈希函数的性质所引起的,哈希函数是离散的函数,是均匀分布的,但是前提是量,数量要多,对于上面的问题来说也就是服务器的数量要多,量起来之后才能体现哈希的特点。
1.在服务器数量较少的时候,哈希域 (也就是上图中的那个环),不一定会被服务器均分
2.就算你解决了第一个问题,服务器均分了哈希域,当你再增加服务器的时候,哈希域又注定不会被均分。
上面两个问题是由哈希函数的性质引起的

那么又该如何解决上面的问题呢?
一个方法,虚拟结点技术:
假设环还是那个环,服务器还是那三台服务器
M1,M2, M3
给M1在哈希域环上虚拟出10000个结点,M2也是,M3也是,此时将有30000个结点遍布在环上,归属于M1的10000个结点中应该存放的数据,都存放在M1上。此时哈希域上的结点数量起来了,哈希域也就自然被均分了。
第一个问题解决,当增加服务器数量的时候也是类似的方法,将服务器虚拟出大量的结点,这样就达到了均分的目的。第二个问题也被解决了
关于服务器虚拟出来的节点类似于路由器中的路由表,可以根据路由表找到结点,也可以根据节结点知道,这个结点属于哪一个路由器。

一个技术解决两个问题(虚拟结点技术)
那如何让一个服务器产生10000个节点呢?
方法很多可以使用的其中一个是服务器IP+节点编号
