在上一篇文章中我们实现了位图的基本操作,现在我们已经知道位图是用来标记某一个数据是否存在,而今天我们要说的布隆过滤器则是另外一种变形应用,通过布隆过滤器我们可以判断一个字符串是否存在于某一对数据中。与位图相比稍有不同的是这里我们可以将数据插入到布隆过滤器(像哈希表一样)中,通过两个哈希函数从而得到两个哈希地址,将这两个哈希地址同时标记为1,就代表该数据被插入到该布隆过滤器中(不是真的将数据插入),也就表示该布隆过滤器中存在该字符串。
细想我们这里使用了两个哈希函数,那么自然会有两个哈希地址。
可想而知,到我们有多个字符串的时候,就有可能算出的哈希地址中有一个或者两个与别的字符串的哈希地址相同,如果我们想要删除一个数据是,必须同时将这两个哈希地址置为0才算是删除了这个数据,然而当哈希地址与别的字符串的哈希地址重复的时候,如果将相应位置为0,也就意味着另外一个数据也会受影响,所以我们这里实现的布隆过滤器是不能进行删除元素的。
优点:
空间效率高,查询快速,布隆过滤器存储空间和插入 / 查询时间都是O(1)。
哈希函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,因为它所存储的是它数据的状态,在某些对保密要求非常严格的场合有优势。
缺点:
随着存入的元素数量增加,误算率也会增加。但是如果元素数量太少,则使用散列表就可以解决问题。
代码实现:
//bloom_filter.h文件内容如下:
#pragma once
#include"bit_map.h"
//此处定义了布隆过滤器的哈希函数
//把字符串转成下标
typedef uint64_t (*BloomHash)(const char*);
#define BloomHashCount 2
#define BitmapMaxCapacity 1024
typedef struct BloomFilter
{
Bitmap bm;
BloomHash bloom_hash[BloomHashCount];
}BloomFilter;
//初始化
void BloomFilterInit(BloomFilter *bf);
//销毁
void BloomFilterDestroy(BloomFilter *bf);
//插入数据
void BloomFilterInsert(BloomFilter *bf,const char *str);
//判断某个字符串是否存在
int BloomFilterIsExist(BloomFilter *bf,const char *str);#include<stdio.h>
#include"bit_map.h"
#include"bloom_filter.h"
#include"bloom_hash.h"
//初始化
void BloomFilterInit(BloomFilter *bf)
{
if(bf == NULL)
{
//非法输入
return;
}
//将bloom_filter中的位图初始化
BitmapInit(&bf->bm,10000);
//初始化两个哈希函数
bf->bloom_hash[0] = SDBMHash;
bf->bloom_hash[1] = BKDRHash;
return;
}
//销毁
void BloomFilterDestroy(BloomFilter *bf)
{
if(bf == NULL)
{
//非法输入
return;
}
//销毁位图
BitmapDestroy(&bf->bm);
//将两个哈希函数指向空
bf->bloom_hash[0] = NULL;
bf->bloom_hash[1] = NULL;
return;
}
//插入数据
void BloomFilterInsert(BloomFilter *bf,const char *str)
{
if(bf == NULL || str == NULL)
{
//非法输入
return;
}
size_t i = 0;
for(;i < BloomHashCount;i++)
{
//通过循环由两个哈希函数可以算出两个哈希地址
uint64_t hash = bf->bloom_hash[i](str)%BitmapMaxCapacity;
//将每一个哈希地址置为1
BitmapSet(&bf->bm,hash);
}
return;
}
//判断某个字符串是否存在
int BloomFilterIsExist(BloomFilter *bf,const char *str)
{
if(bf == NULL || str == NULL)
{
//非法输入
return 0;
}
size_t i = 0;
for(;i < BloomHashCount;i++)
{
//通过循环由两个哈希函数可以算出两个哈希地址
uint64_t hash = bf->bloom_hash[i](str)%BitmapMaxCapacity;
//检测算出的哈希地址是否为1(即检测待判断的数据是否存在)
int ret = BitmapTest(&bf->bm,hash);
//如果一旦有其中一个地址不为1
//返回了0,就说明该数据不存在
if(ret == 0)
{
return 0;
}
}
//走到这说明两个哈希地址处的值均为1
//说明该数据就存在
return 1;
}
//测试一下
void Test()
{
BloomFilter bf;
//初始化
BloomFilterInit(&bf);
//插入5个字符串
BloomFilterInsert(&bf,"hello world");
BloomFilterInsert(&bf,"hello today");
BloomFilterInsert(&bf,"hi everybody");
BloomFilterInsert(&bf,"how are you?");
BloomFilterInsert(&bf,"I am fine!");
//检测某个字符串是否存在
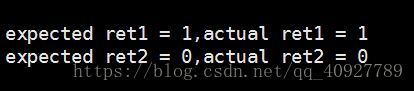
int ret1 = BloomFilterIsExist(&bf,"how are you?");
printf("\nexpected ret1 = 1,actual ret1 = %d\n",ret1);
int ret2 = BloomFilterIsExist(&bf,"where are you?");
printf("expected ret2 = 0,actual ret2 = %d\n\n",ret2);
}测试结果:
布隆过滤器的实现借助了之前写的位图的实现代码,详情请移步上一篇文章:位图
以下是布隆过滤器实现中用到的哈希函数,网上也可以搜到
//.h头文件内容如下:
#pragma once
#include<stddef.h>
size_t SDBMHash(const char *str);
size_t BKDRHash(const char *str);
//.c函数实现内容如下:
#include"bloom_hash.h"
size_t SDBMHash(const char *str)
{
size_t hash = 0;
size_t ch;
while(ch = (size_t)*str++)
{
hash = 65599*hash+ch;
}
return hash;
}
size_t BKDRHash(const char *str)
{
size_t hash = 0;
size_t ch;
while(ch = (size_t)*str++)
{
hash = hash*131+ch;
}
return hash;
}