看了很多资料,本身想放一个正则化的概念的,实在不敢放,怕吓跑一堆人,所以,将就吧。
首先,我们知道正则化(Regularization)是解决过拟合问题的,简单来说,过拟合(也叫高方差)就是训练样本效果比较好,但是在测试集上的效果就比较差了,官方一点的话就是模型的泛化能力太差。
泛化能力:一个假设模型能够应用到新样本的能力。
解决过拟合我们可以采用
(1)丢弃一些不能帮助我们正确预测的特征,可以手工保留,也可以采用算法(例PCA)
(2)正则化处理。保留所有的特征,但是减少参数的大小。
正则化的方式有很多,常见的有数据增强、L1正则化,L2正则化,早停,Dropout等。
正则化代价函数 =经验代价函数 +正则化参数 *正则化项
其中,经验损失函数就是我们所说的损失函数,最小化误差让模型更好拟合训练集
范数的概念:

从概率角度进行分析,很多范数约束相当于对参数添加先验分布,其中L2范数相当于参数服从高斯先验分布,L1范数相当于拉普拉斯分布。从贝叶斯的角度来分析, 正则化是为模型参数估计增加一个先验知识,先验知识会引导损失函数最小值过程朝着约束方向迭代。
相关资料表示:
L0和L1可以解决稀疏问题
L0 问题是NP组合难问题,对较大规模数据无法直接求解;
存在两种直接求解L0问题的算法:
(1)贪婪算法
(2)门限算法
问题:
(1)贪婪算法时间代价过高,无法保证收敛到全局最优
(2)门限算法时间代价低,但对数据噪声十分敏感。解不具有连续性 ,无法保证全局最优解。
L0应用场景:压缩感知、稀疏编码
L0过渡到L1:从一个组合优化问题放松 到凸优化问题来解,L1范数是L0范数的最优凸近似
实线的椭圆代表示没有正则化目标的等值线,虚线圆圈表示L1正则化的等值线
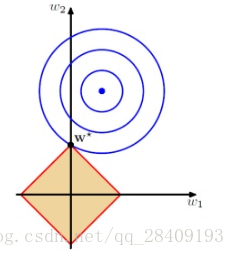
里边涉及一堆数学推理,我简化来说,L1正则化可以产生稀疏矩阵(去掉没用的特征,将权重置为0),有利于特征选择。
扩充:参考https://wenku.baidu.com/view/00613bc4f78a6529657d536c.html?from=search
L2(Tikhonov正则) 权重衰减
目标是通过向目标函数添加一个正则项,使权重更加接近原点。
实线的椭圆代表示没有正则化目标的等值线,虚线圆圈表示L2正则化的等值线
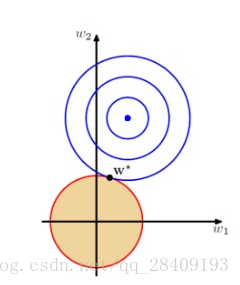
在岭回归中,我们主要解决的问题就是特征数大于样本数的情况,也是奇异矩阵问题。
奇异矩阵:若存在X的列间存在完全的线性依赖,即它的某一或某些列元素正好是另一或另一列元素的线性函数,这称为共线性 或多重共线性。X的共线性必然导致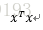
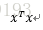
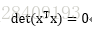
在回归分析中,存在着近似于但不同于奇异矩阵的情况,即行列式的值近似于0,此类矩阵通常称为病态矩阵或者近奇异矩阵。 L2范数有助于计算病态问题。