目录
- sample() 随机抽样函数
- 选取指定数据
- merge数据连接融合
- join数据连接融合
- 对指定属性排序
- 删除某列并对缺失值进行处理
- strip去除%
- 使用to_numeric将字符串转化为数值型
- 使用cut与qcut将某变量离散化 分割
- 使用replace与map对变量进行值替换
- get_dummies进行哑变量处理
一.sample() 随机抽样函数
loan.sample(n=3,axis=1,random_state=1,replace=True)
#n=3 随即查看3列(默认为行)
#axis=1可实现列采样
#random_state有时,我们希望重复调用某次采样的结果,我们可以设定random_state参数为同一个数来实现。
#replace=True又放回抽样(默认为不放回)
loan.sample(frac=0.01)
#抽取样本中的0.01%
二.选取指定数据
test_user = user.loc[[1,3,5,7,8]]
test_user
test_loan = loan[loan.user.isin([2,3,4,5,6,7])]
test_loan```
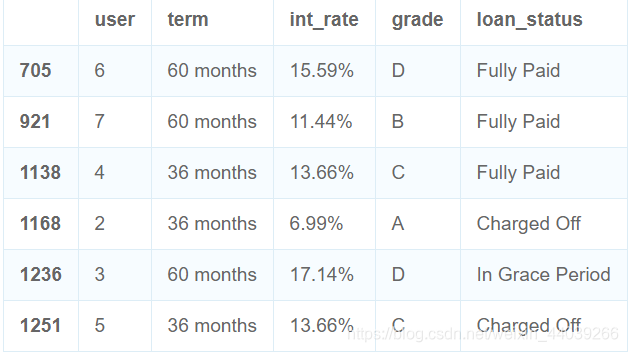
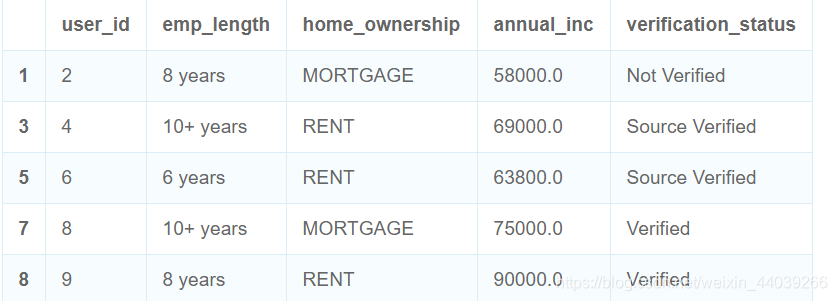
三.merge数据连接融合
left.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), indicator=False)
- left和right分别指代我们要进行连接的两个数据框。
- on, left_on, right_on,
用来指定连接的变量。若这一变量在两个数据框中命名相同,直接使用on指定即可,否则通过left_on和right_on分别指定左表变量名和右表变量名。 - 若需要基于数据框的索引进行连接,则要通过设定left_index和right_index的参数为True来实现。
- how为连接方式,有’inner’(内连接), ‘left’(左连接), ‘right’, 'outer’四种,我们通过几个例子来对比一下。
- indicator参数能很好地帮助我们找到返回结果的来源,设定indicator参数为Ture后,返回结果中多了一列"_merge",取值有"both", “left_only”, "right_only"三种。分别代表左右表匹配成功,左表有而右表没有,右表有而左表没有三种情况。
- 当左表与右表中变量同名时,我们可以通过suffixes参数为左表变量与右表变量附加不同字段,便于后续区分。
- sort指定为True会让返回的结果按连接变量进行升序排列。
#inner这种方式下,只有所选定列在左表与右表能匹配的行会被保留。
test_user.merge(test_loan,how="inner",left_on="user_id",right_on="user")

#左连接(left)。这种方式下,左表所有行都被保留,不能匹配的部分用缺失值填充。(结果如下图)
test_user.merge(test_loan,how="left",left_on="user_id",right_on="user")
#右连接(right)。这种方式下,右表所有行都被保留,不能匹配的部分用缺失值填充。
test_user.merge(test_loan,how="right",left_on="user_id",right_on="user")

#外连接(outer)。这种方式下,左表和右表所有行都会被保留,不能匹配的部分用缺失值填充。
test_user.merge(test_loan,how="outer",left_on="user_id",right_on="user")

test_loan.merge(test_loan,on="user",suffixes=('_l','_r'))

四.join数据连接融合
left.join(right, on=None, how='left', lsuffix='', rsuffix='', sort=False)
- join的参数比merge要简单很多,且各参数merge中含义基本一致,这里不再赘述。事实上,join就是merge的简化版本,所有join能实现的操作,我们都可以使用merge实现,但一些情况下,使用join可以使我们的代码更简洁。(后文我们将结合get_dummies使用)。但需要注意:
- 使用join时,右表只能基于索引进行连接; 通过on参数,可以指定左表进行连接的变量(可以是索引也可以是任意列)。
五.对指定属性排序
- sort_index和sort_values也可以对DataFrame进行排序,sort_index是按照索引进行排序,sort_values是按照指定变量排序。
#升序
history.sort_values(by='avg_cur_bal')[:5]
#降序
history.sort_values(by='avg_cur_bal',ascending=False)[:5]
#将缺失值排在最前面
history.sort_values(by='avg_cur_bal',na_position='first')[:5]
六.删除某列并对缺失值进行处理
a.drop(columns='b',replace=True)
a.info()#查看缺失值
combine.dropna(how="any",axis=0,inplace=True)
#0行1列 any为有则删除 all为都为na才删除
七.strip去除%
- str.strip方法是向量化的字符串处理方法,会对Series的每一个元素应用
int_rate = combine.lieming.str.strip('%')
八.使用to_numeric将字符串转化为数值型
#dtype: object
int_rate=pd.to_numeric(int_rate)
int_rate.dtype
#dtype('float64')
九.使用cut与qcut将某变量离散化 分割
annual_inc = pd.cut(combine.annual_inc,bins=[np.min(combine.annual_inc)-1,np.percentile(combine.annual_inc,50),np.max(combine.annual_inc)+1],labels=['low','high'])
#bins内为区间 np.percentile求取数列第50%分位的数值
annual_inc.value_counts()
'''low 613
high 603
Name: annual_inc, dtype: int64'''
#cut也可以直接指定划分份数,将数据等距划分
pd.cut(combine.annual_inc,5).value_counts()
'''
(15436.0, 128800.0] 1085
(128800.0, 241600.0] 106
(241600.0, 354400.0] 20
(354400.0, 467200.0] 3
(467200.0, 580000.0] 2
Name: annual_inc, dtype: int64
'''
pd.qcut(combine.annual_inc,2).value_counts()
#它将按照每个区间中频数相同的原则进行划分,当我们指定划分份数后,就会用相应的分位数进行划分。
'''
(15999.999, 66000.0] 613
(66000.0, 580000.0] 603
Name: annual_inc, dtype: int64
'''
十.使用replace与map对变量进行值替换
- to_replace指需要替换的值,value指要替换成的新值。replace作为数值替换的方法
combine['loan_status'].replace(to_replace=['Fully Paid','Current','Charged Off','In Grace Period','Late (31-120 days)'],
value=[0,0,1,1,1],
inplace=True)
#可以同时指定不同变量的不同值替换为相同新值。
test_loan.replace(to_replace={
'loan_status':'Fully Paid','grade':'A'},value='Good')
#也可以指定正则表达式进行替换,这时需要设定参数regex为True,代表to_replace部分输入的是正则表达式。
#如查找所有以C开头的字段并替换为Bad。
test_loan.replace(to_replace='C+.*$', value='Bad', regex=True)
- map不能像replace一样直接对DataFrame进行操作。不过map不仅仅可以像上面一样输入字典作为参数,也可以直接输入一个函数进行映射。
#如果只是针对某一个Series进行数值替代,我们也可以使用map方法。
test_loan['loan_status'].map({
'Fully Paid':0,'Charged Off':0,'In Grace Period':1})
- 用map对数据进行分段
def f(x):
if x < 12:
return 'Low'
else:
return 'High'
combine['int_rate'][:5].map(f)
'''
0 high
1 high
2 low
3 low
4 high
Name: int_rate, dtype: object
'''
十一.get_dummies进行哑变量处理
- 哑变量又称虚拟变量、名义变量,从名称上看就知道,它是人为虚设的变量,用来反映某个变量的不同类别。使用哑变量处理类别转换,事实上就是将分类变量转换为哑变量矩阵或指标矩阵,矩阵的值通常为"0"或"1"表示。
pd.get_dummies(combine['grade'], prefix='grade',drop_first=True)[:5]

- prefix可以为新生成的哑变量添加前缀,这方便我们识别新生成的变量是从原来哪一个变量中得来的。
- drop_first设置为True将删去所获得哑变量的第一个,这是因为在建模中,有k类的分类变量我们只需要k-1个变量就可以将其描述,如果使用k个变量则会出现完全共线性的问题。
- 返回的结果与原始数据有相同的索引,使用join直接基于索引进行连接更简洁。