3.数据提取
- 目的:建立因果关系模型
- 数据提取的时候要对数据有一定的认识,不能是相关而应该是因果(区分相关关系和因果关系),预测的变量x要在被预测变量y之前取得
相关关系:一个小孩子身高的长高速度和GDP增长的速度就可以做相关关系,但这明显没有什么关系。
因果关系:家庭收入和全国GDP总量,这就明显具有一定的因果关系。

细分了特征变量之后,就有了下面的模型框架:
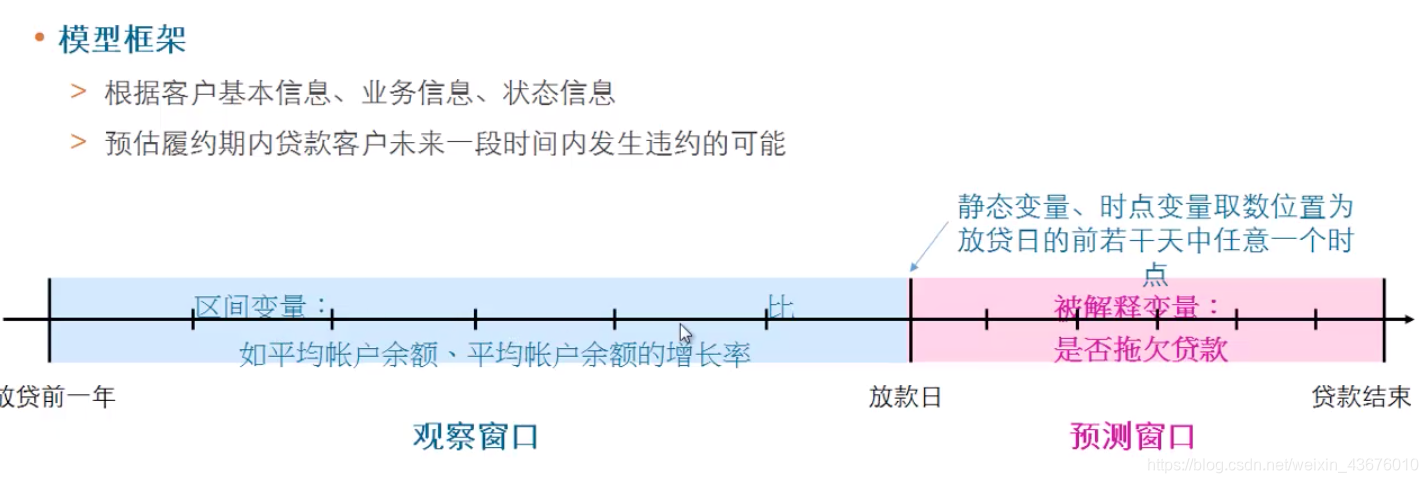
观察窗口(历史)看解释变量:
- 如果是静态变量可以任意提取因为不管它在历史还是未来都不变;
- 如果是时点变量可以提取放贷前(红蓝分界线)任意时间点的数据,例如余额,资产收入,资产支出等;
- 如果是区间变量可以提取放贷日前一年或者前两年的数据,例如平均账户余额,平均账户余额的增长率
这就模拟了放贷人员在放贷之前的审批准则(能够看到客户的)
预测窗口(未来)看被解释变量y:
- 是否拖欠贷款
观察窗口和预测窗口提取数据逻辑要符合实际情况,这样设计的窗口才能得到可用的有价值的模型。
例如:有些股票预测模型,买之前预测的很准,买之后准确率就下降了,这就是因为没有分清x是什么类型的变量,取的是所有时段的,导致预测与实际情况不符
如需数据:请添加QQ1240929749,备注:csdn数据