1.数据分析
1.1 基本统计分析
1.1.1 含义
基本统计分析是统计某个变量的最小值、第一个四分位值、中值、第三个四分位值以及最大值。
1.1.2 数据的中心
数据的中心位置可分为均值(Mean)、中位数(Median)和众数(Mode)。
1.1.3 describe函数
描述性统计分析函数为describe。该函数返回值有均值、标准差、最大值、最小值、分位数等。括号中可以带一些参数,如percentiles=[0,0.2,0.4,0.6,0.8]就是指定只计算0.2、0.4、0.6、0.8分位数,而不是默认的1/4、1/2、3/4分位数。
常用的统计函数有:
size:算样本数(此函数不需要括号)
sum():求和。
mean():平均值。
var():方差。
std():标准差。
1.1.4 例题
展示i_nuc_utf8.csv
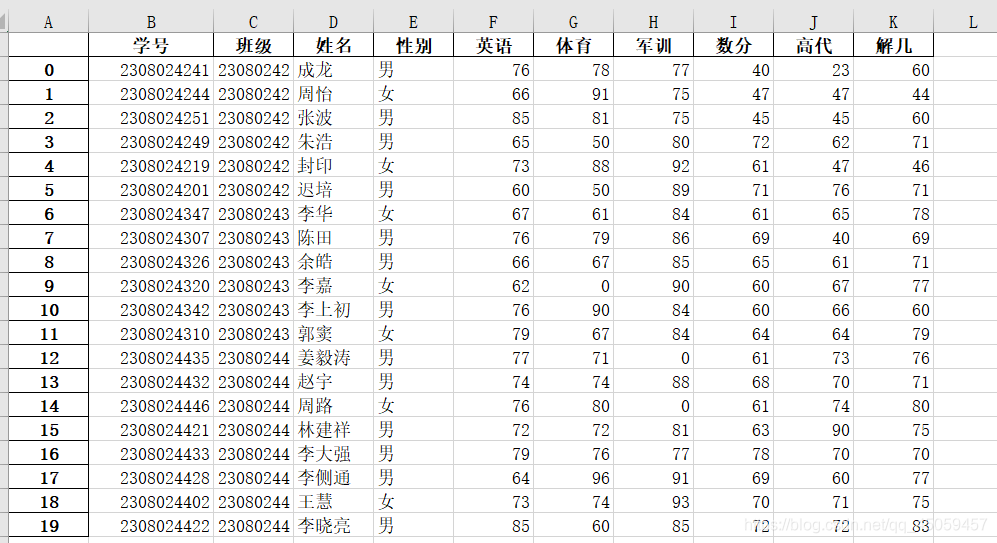
import pandas as pd
import numpy as np
np.set_printoptions(suppress=True)#显示的数字不是以科学记数法显示
import pandas as pd
#display.max_columns 显示最大列数,display.max_rows 显示最大行数
df=pd.DataFrame(pd.read_csv('i_nuc_utf8.csv'))#d读取文件
df#展示读取的文件
运行结果:

df.describe()#所有各列的基本统计
运行结果:
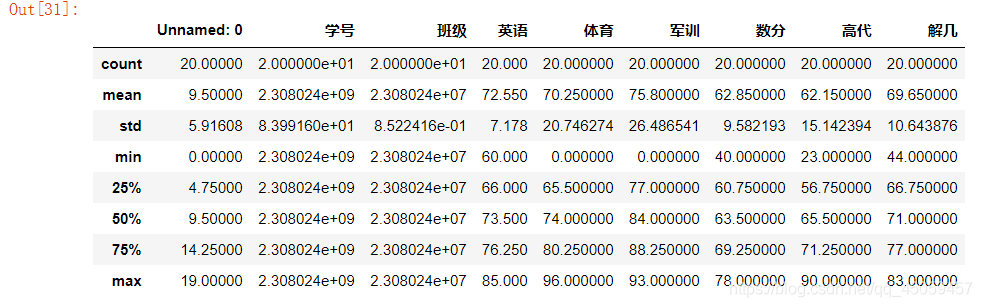
计算某一变量的基本数据

计算平均值的方法(有三种)

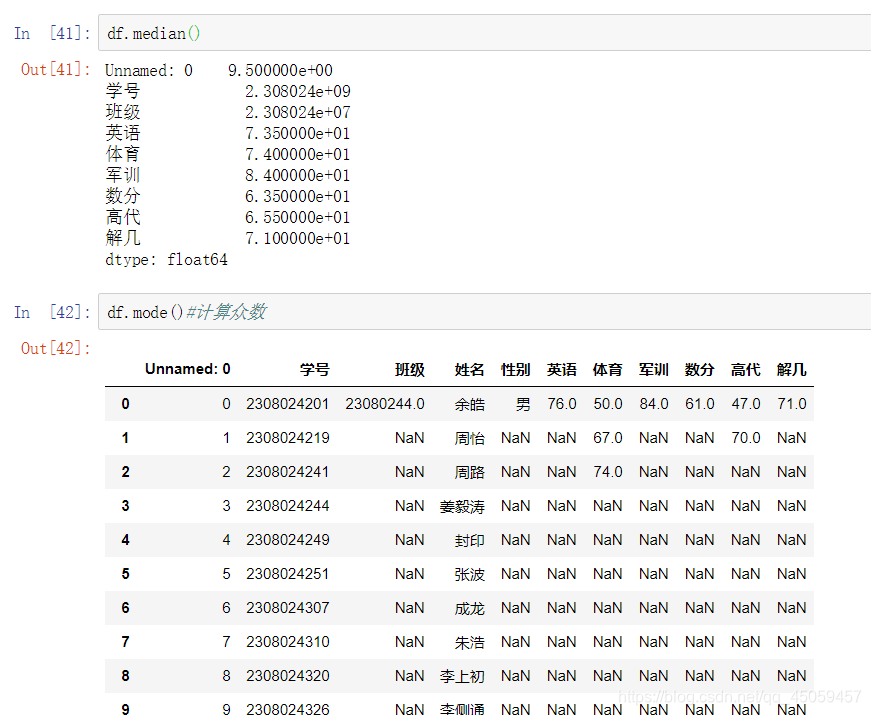
计算整个表的中位数,众数
1.1.5 总结
describe函数计算出每一个变量的基本数据。
计算平均数的三种方法。
表示表的变量,如:df[‘变量’]。
median函数算中位数
mode函数算众数
1.2 分组分析
1.2.1 含义
根据分组字段将分析对象划分不同的部分。
1.2.2 格式
常用命令形式如下:
df.groupby(by=[‘分组依据’,…])[‘被统计的列’].agg({列别名:统计函数1,…})
其中:
by表示用于分组的列;
[]表示用于统计的列;
agg表示统计别名统计值的名称,统计函数用于统计数据。常用的统计函数有:size表示计数;sum表示求和;mean表示求均值。
1.2.3 例子
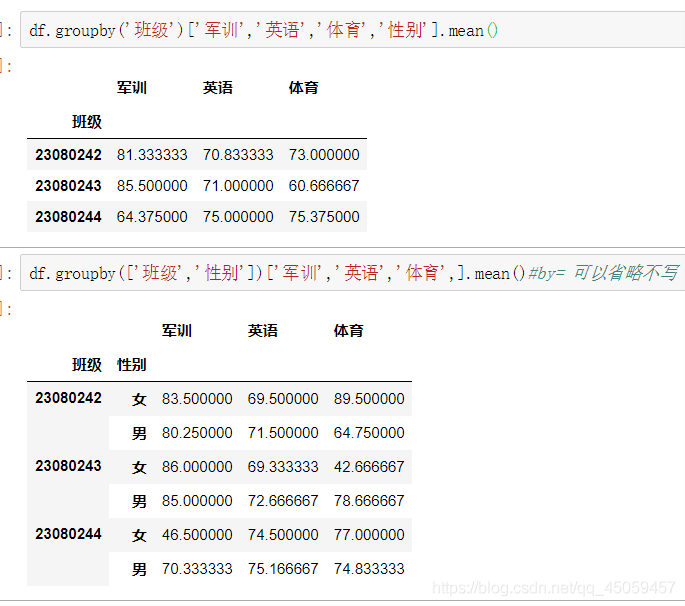
groupby分组中,数值列会被聚合,非数值列会从结果中排除,当分组的依据不知一个时,则需要使用list。
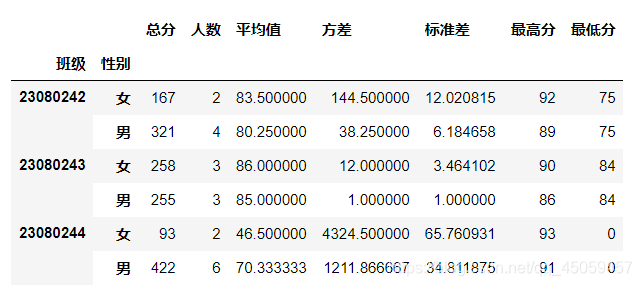
df.groupby(by=['班级','性别'])['军训','英语','体育'].mean()
当要同时计算各组数据的平均数,标准差,总数等,需要使用agg()。
df.groupby(by=['班级','性别'])['军训'].agg({
'总分':np.sum,
'人数':np.size,
'平均值':np.mean,
'方差':np.var,
'标准差':np.std,
'最高分':np.max,
'最低分':np.min,
})
运行结果:
1.2.4 总结
牢记df.groupby(by=[‘分组依据’,…])[‘被统计的列’].agg({列别名:统计函数1,…})
什么是分组依据,什么是被统计的列。
1.3 分布分析
1.3.1 含义
研究各组分布规律的一种分析方法。建立在分组分析之上
1.3.2 步骤
1.3.2.1 生成总列
df['总分']=df.英语+df.体育+df.军训+df.数分+df.高代+df.解几
df['总分']#按一行求总数
运行结果:

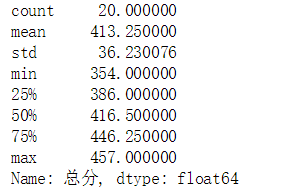
df['总分'].describe()
运行结果:
1.3.2.2 划分区间,生成标签
bins=[min(df.总分)-1,400,450,max(df.总分)+1]
bins

labels=['400分以下','400到450','450及其以上']
labels

1.3.2.3 按刚刚生成的总列和区间分层并进行统计
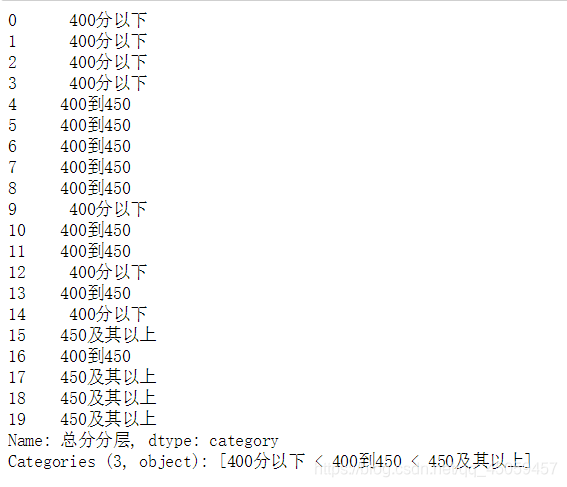
总分分层=pd.cut(df.总分,bins,labels=labels)#cut函数
总分分层
1.3.2.4 生成变量
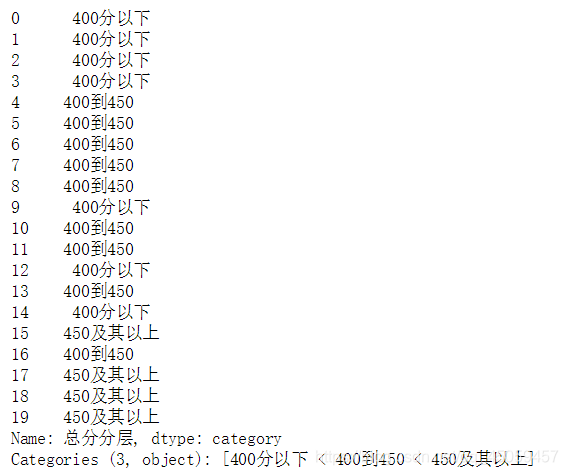
df['总分分层']=总分分层
df['总分分层']
1.3.2.5 统计
df.groupby(by=['总分分层'])['总分'].agg({
'人数':np.size})

1.4 交叉分析
1.4.1 含义
交叉分析通常用于分析两个或两个以上分组变量之间的关系。
1.4.2 格式和参数
格式:
pivot_table(values,index,columns,aggfunc,fill_values)
参数:
values 表示数据透视表中的值
index 表示数据透视表的分组依据,显示
columns 表示数据透视表中的列
aggfunc 表示统计函数
fill_values 表示NA值得统一替换
返回值是数据透视表
1.4.3 例子
from pandas import pivot_table
df.pivot_table(index=['班级','姓名'])
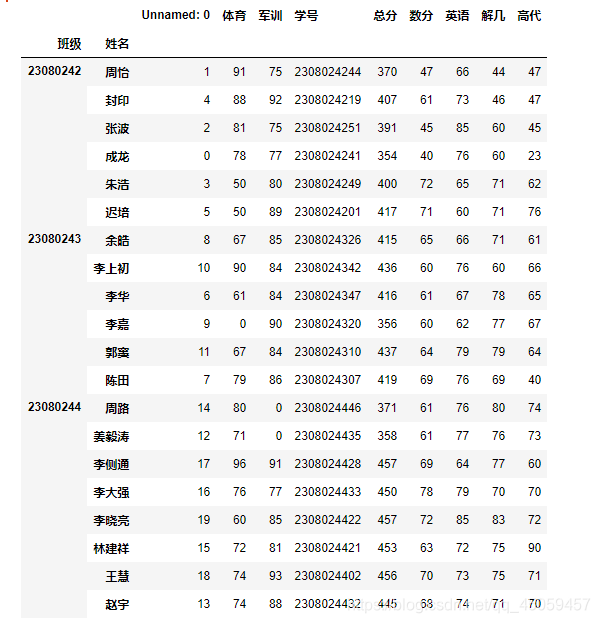
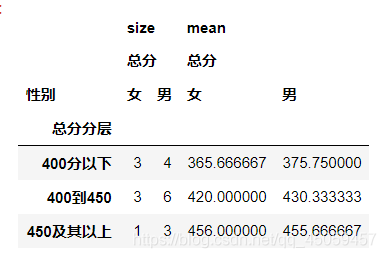
df.pivot_table(values=['总分'],index=['总分分层'],columns=['性别'],aggfunc=[np.size,np.mean])
运行结果:
1.5 结构分析
1.5.1 含义
画饼状图
1.5.2 例子
分班分性别,求总分
df['总分']=df.英语+df.体育+df.军训+df.数分+df.高代+df.解几
df_pt=df.pivot_table(values=['总分'],
index=['班级'],columns=['性别'],aggfunc=[np.sum])
df_pt

df_pt.div(df_pt.sum(axis=1),axis=0)
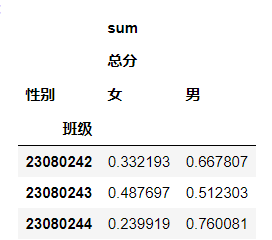
2308242班的女生占总分的0.332193,男生占总分的0.667807
1.5.3 小结
用div求百分比。
sum函数求和。axis=1,行上相加,axis=0,列上面相加。
1.6 相关分析
1.6.1 含义
1.6.2 相关系数与相关程度的关系
1.6.3 例子
df.loc[:,['英语','体育','军训','解几','数分','高代']].corr()
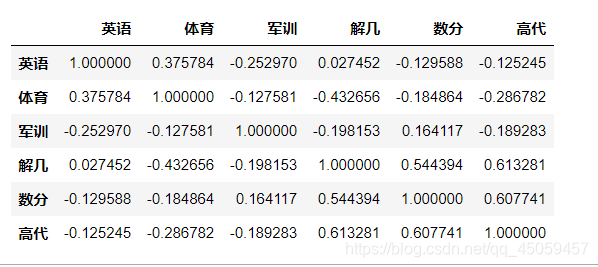
高代和数分有中度相关,解几和数分有中度相关。
1.6.4 总结
loc取值,corr函数做相关性分析。