问题重述
能够读取给定的数据文件
出租车GPS数据文件(taxi_gps.txt)
北京区域中心坐标及半径数据文件(district.txt)
能够输出以下统计信息
A:该出租车GPS数据文件(taxi_gps.txt)包含多少量车?
B:北京每个城区的车辆位置点数(每辆车有多个位置点,允许重复)
开发环境:
开发软件 Pycharm
开发语言:Python
系统macOS Mojave
Spark版本 spark-2.1.1-bin-hadoop2.7
Scala版本Scala-2.10.4
Python版本Python3.7
实验原理
输出A:
以第一列统计车辆数,去重
输出B:
1.从(district.txt)文件中取第一个区的记录,获得其名称D1、中心坐标M(x0,y0)和半径r;
2.从(taxi_gps.txt)中获取第一条位置点记录,获得其坐标N(x1,y1)
3.利用欧几里得距离计算公式计算点M和N的距离dis,如果dis<r,则认为该位置记录属于区域D1;得到<D1,1>
4.继续从2开始循环,获得第二个位置记录;直至所有记录遍历完。
5.继续从1开始循环,获得第二个区的记录
数据说明
待统计区域中心数据格式
区域名称:北京城区拼音,例:haidianqu, chaoyangqu, dongchengqu
区域中心GPS经度:格式ddd.ddddddd,以度为单位。
区域中心GPS纬度:格式dd.ddddddd,以度为单位。
区域半径:格式dd,以km为单位
出租车GPS数据格式说明
数据以ASCII文本表示,以逗号为分隔符,以回车换行符(0x0D 0x0A)结尾。数据项及顺序:车辆标识、触发事件、运营状态、GPS时间、GPS经度、GPS纬度,、GPS速度、GPS方向、GPS状态
车辆标识:6个字符
触发事件:0=变空车,1=变载客,2=设防,3=撤防,4=其它
运营状态:0=空车,1=载客,2=驻车,3=停运,4=其它
GPS时间:格式yyyymmddhhnnss,北京时间
GPS经度:格式ddd.ddddddd,以度为单位。
GPS纬度:格式dd.ddddddd,以度为单位。
GPS速度:格式ddd,取值000-255内整数,以公里/小时为单位。
GPS方位:格式ddd,取值000-360内整数,以度为单位。
GPS状态:0=无效,1=有效
结束串:回车符+换行符
实验步骤
A:该出租车GPS数据文件(taxi_gps.txt)包含多少量车?
- 初始化spark
sc = SparkContext('local', 'wordcount')
导入我们的GPS数据,并将其创建为RDD(弹性分布式数据)。
input = sc.textFile("file:/Users/wangxingwu/Desktop/spark样例程序/python-Word_Count/pycharm/Word_Count/taxi_gps.txt")
- 利用split()函数对PDD数据进行拆分,并第一列数据导入新的RDD中,已知我们的数据由“,”分隔。
- 利用distinct()函数对新的RDD数据进行去重复,而后利用count()函数进行RDD数据的统计,即可得到所有出租车的数量(不重复)。
words = input.flatMap(lambda line: line.split(',')[0:1])#取第一列元素
words = words.distinct()#
print("数据中包含的汽车个数为:",words.count())
4.除了3中的方法,还可以通过wordcount的事例程序进行处理,我们将新的RDD进行词频统计(Map+Reduce),最后统计单词(字符串)数量即可。
counts = words.map(lambda word: (word, 1)).reduceByKey(lambda x, y: x + y)
print("利用wordcount计算的汽车数量:",counts.count())
实验结果

通过进行记数,我们得到汽车的数量为11264辆。
代码
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
from pyspark import SparkContext
#输入路径
sc = SparkContext('local', 'wordcount')
# 读取文件
input = sc.textFile("file:/Users/wangxingwu/Desktop/spark样例程序/python-Word_Count/pycharm/Word_Count/taxi_gps.txt")
# 切分单词
words = input.flatMap(lambda line: line.split(',')[0:1])#取第一列元素
#print(words.collect())
print("数据中包含的汽车个数为:",words.count())
words = words.distinct()#不重复
print("去重后包含汽车的个数为:",words.count())
# 转换成键值对并计数
counts = words.map(lambda word: (word, 1)).reduceByKey(lambda x, y: x + y)
print("利用wordcount计算的汽车数量:",counts.count())
# 输出结果
counts.foreach(print)
B:北京每个城区的车辆位置点数(每辆车有多个位置点,允许重复)
- 初始化spark
sc = SparkContext('local', 'wordcount')
读取两个文件的数据,创建生成2个RDD
input1 = sc.textFile("file:/Users/wangxingwu/Desktop/spark样例程序/python-Word_Count/pycharm/Word_Count/taxi_gps.txt")
input2 = sc.textFile("file:/Users/wangxingwu/Desktop/spark样例程序/python-Word_Count/pycharm/Word_Count/district.txt")
通过flatMap()函数进行以“,”为分隔符的拆分,其中在GPS文件中只需要每行数据的经纬度数据。
distance0= input1.map(lambda line: line.split(',')[4:6])#取第5,6列元素,汽车坐标
distance1= input2.map(lambda line: line.split(','))#取
2. 因为要定位汽车GPS的位置所属街区,我们需要对每条数据进行所有街区的计算分析当两点距离小于区域半径则该点属于该区域。所有我将两表进行笛卡尔积(cartesian())的运算。
distance = distance0.cartesian(distance1)
3. 我们现在有了连接好的表,现在需要对其进行运算判断,这里首先需要编写两点GPS坐标距离公式(具体函数不是重点暂不赘述详见代码)。
4. 难点来了,就是对RDD数据的操作、以及Python中,lambda的语法:
首先我们要明确一点,RDD数据支持两种类型操作:转化操作(transform)、行动操作(action)
我们首先需要对之前笛卡尔积后的RDD的数据带入函数中运算,且在区域内的我将其标记为1,否之为0
而后希望每条数据(x0,y0,x,y,0 or 1)=>(region,1),而后进行wordcount即可统计出每个地区的汽车数量。
在转化上面我们就要用到map()函数进行RDD数据转换,通过Python中,lambda的语句即可实现,而后我们进行RDD数据的行动操作,这里我需要剔除所有的(region,0)数据,利用函数filter(lambda x:x[1]==1)。
现在基本上我们工作只需要最后的一步reduceByKey(lambda x,y:x+y),这个函数就是对每一个key值相同的元素进行一种求和。
counts = distance.map(lambda d0:(d0[1][0], include_number(get_distance_hav(d0[0],d0[1][1:3]),float(d0[1][3])))).filter(lambda x:x[1]==1).reduceByKey(lambda x,y:x+y
实验结果
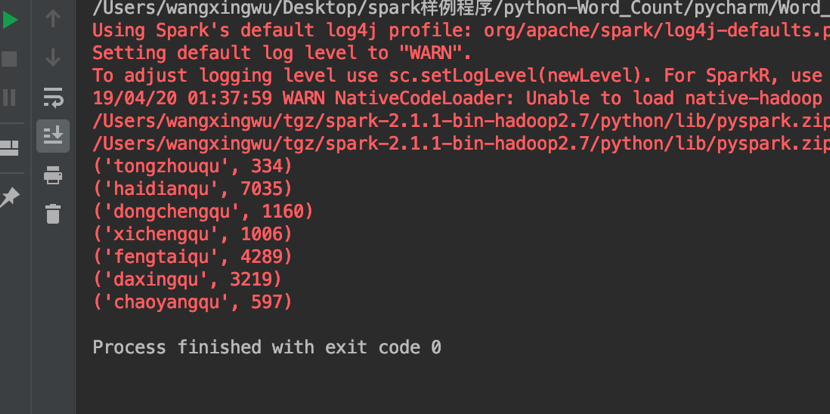
代码
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
from pyspark import SparkContext
from math import sin,asin,cos,radians,fabs,sqrt
EARTH_RADIUS=6371#地球半径
def hav(theta):
s = sin(theta / 2)
return s * s
def get_distance_hav(x,y):
"用haversine公式计算球面两点间的距离。"
# 经纬度转换成弧度
lat0=float(x[0])
lng0=float(x[1])
lat1=float(y[0])
lng1=float(y[1])
lat0 = radians(lat0)
lat1 = radians(lat1)
lng0 = radians(lng0)
lng1 = radians(lng1)
dlng = fabs(lng0 - lng1)
dlat = fabs(lat0 - lat1)
h = hav(dlat) + cos(lat0) * cos(lat1) * hav(dlng)
distance = 2 * EARTH_RADIUS * asin(sqrt(h))
return distance
def include_number(distance,r):
if distance<=r:
return 1
else:
return 0
sc = SparkContext('local', 'wordcount')
# 读取文件
input1 = sc.textFile("file:/Users/wangxingwu/Desktop/spark样例程序/python-Word_Count/pycharm/Word_Count/taxi_gps.txt")
input2 = sc.textFile("file:/Users/wangxingwu/Desktop/spark样例程序/python-Word_Count/pycharm/Word_Count/district.txt")
# 切分单词
distance0= input1.map(lambda line: line.split(',')[4:6])#取第5,6列元素,汽车坐标
distance1= input2.map(lambda line: line.split(','))#取
distance = distance0.cartesian(distance1)#两表进行笛卡尔积
# 转换成键值对并计数
counts = distance.map(lambda d0:(d0[1][0], include_number(get_distance_hav(d0[0],d0[1][1:3]),float(d0[1][3])))).filter(lambda x:x[1]==1).reduceByKey(lambda x,y:x+y)
counts.foreach(print)