1 基本概念
- 数据挖掘是什么
从一堆数据中通过分析挖掘得到目标需求想要得到的结论
- 数据挖掘的基本流程
- 商业理解:数据挖掘的目的是更好地帮助业务,所以要从商业的角度理解项目需求,在这个基础上,再对数据挖掘的目标进行定义。
- 数据理解:尝试收集部分数据,然后对数据进行探索,包括数据描述、数据质量验证等;
可以对收集的数据有个初步的认知。 - 数据准备:开始收集数据,并对数据进行清洗、数据集成等操作,完成数据挖掘前的准备工作。
- 模型建立:选择和应用各种数据挖掘模型,并进行优化,以便得到更好的分类结果。
- 模型评估:对模型进行评价,并检查构建模型的每个步骤,确认模型是否实现了预定的商业目标。
- 上线发布:模型的作用是从数据中找到“知识”,获得的知识需要转化成用户可以使用的方式,呈现的形式可以是一份报告,也可以是实现一个比较复杂的、可重复的数据挖掘过程;
数据挖掘结果如果是日常运营的一部分,那么后续的监控和维护就会变得重要。
- 商业智能 BI、数据仓库 DW、数据挖掘 DM
商业智能的英文是 Business Intelligence,缩写是 BI。相比于数据仓库、数据挖掘,它是一个更大的概念;
商业智能可以说是基于数据仓库,经过了数据挖掘后,得到了商业价值的过程;
所以说数据仓库是个金矿,数据挖掘是炼金术,而商业报告则是黄金。
数据仓库通过数据库技术来存储数据
- 元数据和数据元
元数据(MetaData):描述其它数据的数据,也称为“中介数据”;
元数据最大的好处是使信息的描述和分类实现了结构化,让机器处理起来很方便;
通过元数据,可以很方便地管理数据仓库。
数据元(Data Element):最小数据单元。
比如一本图书的信息包括了书名、作者、出版社、ISBN、出版时间、页数和定价等多个属性的信息;
可以把这些属性定义成图书的元数据。
在图书这个元数据中,书名、作者、出版社等就是数据元。
- 数据挖掘(也叫KDD)的重要任务:分类、聚类、预测和关联分析
1 分类
通过训练集得到一个分类模型,然后用这个模型可以对其他数据进行分类
一般来说数据可以划分为训练集和测试集;
训练集是用来给机器做训练的,通常是人们整理好训练数据,以及这些数据对应的分类标识;
通过训练,机器就产生了自我分类的模型,然后机器就可以拿着这个分类模型,对测试集中的数据进行分类预测;
如果测试集中,人们已经给出了测试结果,那么就可以用测试结果来做验证,从而了解分类器在测试环境下的表现。
2 聚类
是将数据自动聚类成几个类别,聚到一起的相似度大,不在一起的差异性大。

往往会利用聚类来做数据划分
3 预测
通过当前和历史数据来预测未来趋势
可以更好地帮助人们识别机遇和风险。
4 关联分析
发现数据中的关联规则
想完成这些任务,需要将数据库中的数据经过一系列的加工计算,最终得出有用的信息。:
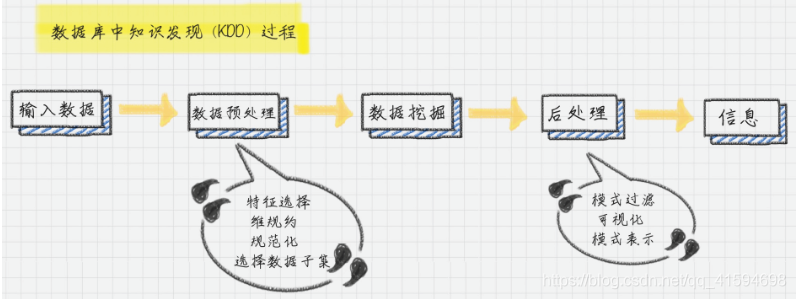
首先,输入收集到的数据;
然后,对数据进行预处理,预处理通常是将数据转化成想要的格式;
接着再对数据进行挖掘;
最后通过后处理得到想要的信息。
数据预处理的步骤::数据清洗,数据集成,数据变换
数据后处理:将模型预测的结果进一步处理后,再导出
2 分析用户数据
首先给用户画像做个白描:用户“都是谁”“从哪来”“要去哪“
建模流程:
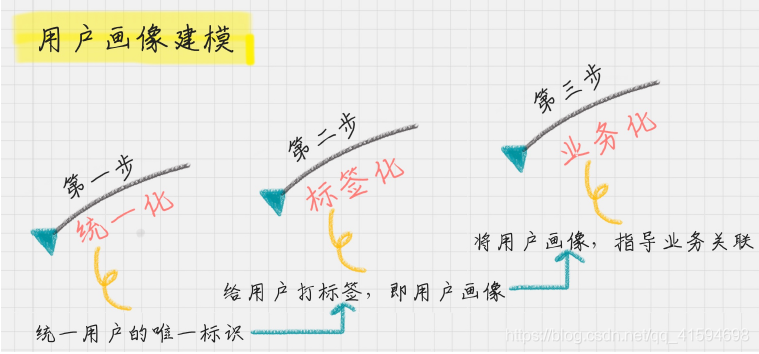
可以通过4个维度进行标签划分:
- 用户(基础)标签:包括了性别、年龄、地域、收入、学历、职业等;
这些包括了用户的基础属性。- 消费标签:消费习惯、购买意向、是否对促销敏感。这些统计分析用户的消费习惯。
- 行为标签:时间段、频次、时长、访问路径。这些是通过分析用户行为,来得到他们使
用 App 的习惯。- 内容分析:对用户平时浏览的内容,尤其是停留时间长、浏览次数多的内容进行分析,
分析出用户对哪些内容感兴趣,比如,金融、娱乐、教育、体育、时尚、科技等。
用户画像的业务价值:
- 获客:如何进行拉新,通过更精准的营销获取客户。
- 粘客:个性化推荐,搜索排序,场景运营等。
- 留客:流失率预测,分析关键节点降低流失率。
用户画像建模流程也可以按照数据流处理的阶段来划分:数据层打上“事实标签”,算法层打上“模型”标签,业务层打上“预测标签”
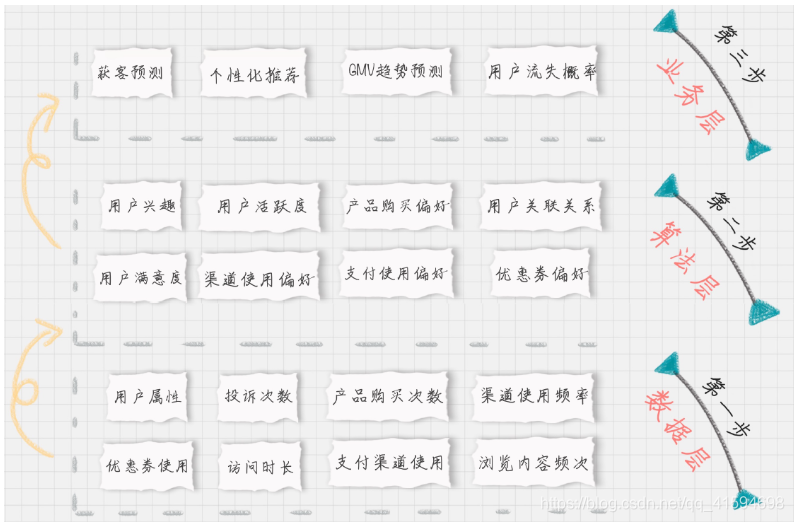
此标签化的流程,就是通过数据层的“事实标签”(指的是用户消费行为里的标签),在算法层(指的是透过这些行为算出的用户建模)进行计算,打上“模型标签”的分类结果,最后指导业务层(指的是获客、粘客、留客的手段),得出“预测标签“。
3 数据采集
数据源:
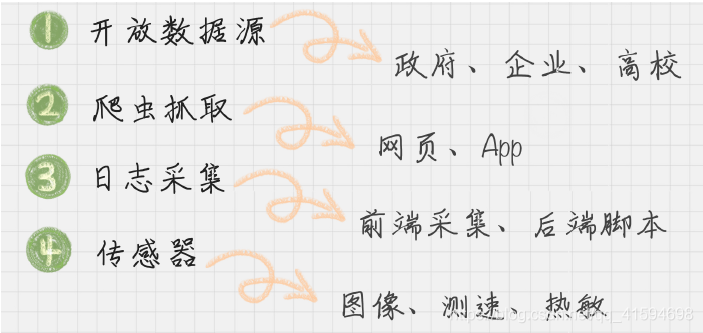
自动化采集的关键:自动切换IP以及云采集
爬虫分为三个阶段:打开网页、提取数据、保存数据
4 数据清洗
做完数据采集,由于采集到的数据往往有很多问题,因此在分析前,要投入大量的时间和精力把数据“整理裁剪”成自己想要或需要的样子,也就是数据清洗
在整个数据分析过程中花费的时间和精力数据清洗大概占到了 80%。
4.1 数据质量的准则
使用Pandas按照如下准则一一清洗:
1 完整性:单条数据是否存在空值,统计的字段是否完善,是否有空行
2 全面性:观察某一列的全部数值,比如在 Excel 表中,我们选中一列,可以看到该列的平均值、最大值、最小值。
我们可以通过常识来判断该列是否有问题,比如:数据定义、单位标识、数值本身。3 合法性:数据的类型、内容、大小的合法性。
比如数据中存在非 ASCII 字符,性别存在了未知,年龄超过了 150 岁等。4 唯一性:数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的。
行数据、列数据都需要是唯一的,比如一个人不能重复记录多次,且一个人的体重也不能在列指标中重复记录多次。
没有高质量的数据,就没有高质量的数据挖掘,而数据清洗是高质量数据的一道保障,因此要养成数据审核的习惯
5 数据集成
将多个数据源合并(去重)存放在一个数据存储中(如数据仓库),从而方便后续的数据挖掘工作。
ETL:数据的抽取、转换、加载三个过程
抽取是将数据从已有的数据源中提取出来
转换是对原始数据进行处理,例如将多表的输入进行连接形成一张新的表
加载就是写入目的地
根据转换发生的顺序和位置,数据集成可以分为 ETL 和 ELT 两种架构:
ETL 的过程为提取 (Extract)——转换 (Transform)——加载 (Load),在数据源抽取后首先进行转换,然后将转换的结果写入目的地。
ELT 的过程则是提取 (Extract)——加载 (Load)——变换 (Transform),在抽取后将结果先写入目的地,然后利用数据库的聚合分析能力或者外部计算框架,如 Spark 来完成转换的步骤。
目前数据集成的主流架构是 ETL,但未来使用 ELT 作为数据集成架构的将越来越多,原因:
ELT 和 ETL 相比,最大的区别是“重抽取和加载,轻转换”,从而可以用更轻量的方案搭建起一个数据集成平台。
使用 ELT 方法,在提取完成之后,数据加载会立即开始。
一方面更省时,另一方面 ELT 允许 BI 分析人员无限制地访问整个原始数据,为分析师提供了更大的灵活性,使之能更好地支持业务。在 ELT 架构中,数据变换这个过程根据后续使用的情况,需要在 SQL 中进行,而不是在加载阶段进行。这样做的好处是可以从数据源中提取数据,经过少量预处理后进行加载。这样的架构更简单,使分析人员更好地了解原始数据的变换过程。
建议使用的工具:Kettle
Kettle 采用可视化的方式进行操作,来对数据库间的数据进行迁移。它包括了两种脚本:Transformation 转换和 Job 作业:
Transformation(转换):相当于一个容器,对数据操作进行了定义。数据操作就是数据从输入到输出的一个过程。
可以把转换理解成为是比作业粒度更小的容器。
在通常的工作中,会把任务分解成为不同的作业,然后再把作业分解成多个转换。Job(作业):相比于转换是个更大的容器,它负责将转换组织起来完成某项作业。
可以完成的操作:将文本文件的内容转化到 MySQL 数据库中等
6 数据变换
假设 A 考了 80 分,B 也考了 80 分,但前者是百分制,后者 500 分是满分,如果把从这两个渠道收集上来的数据进行集成、挖掘,就算使用效率再高的算法,结果也不是正确的。因为这两个渠道的分数代表的含义完全不同
因此需要让不同渠道的数据统一到一个目标数据库里,这也是是数据变换的意义
常见的变换方法:
数据平滑:去除数据中的噪声,将连续数据离散化。这里可以采用分箱、聚类和回归的方式进行数据平滑
数据聚集:对数据进行汇总,在 SQL 中有一些聚集函数可以供我们操作,比如 Max()反馈某个字段的数值最大值,Sum() 返回某个字段的数值总和;
数据概化:将数据由较低的概念抽象成为较高的概念,减少数据复杂度,即用更高的概念替代更低的概念。比如说上海、杭州、深圳、北京可以概化为中国。
数据规范化:使属性数据按比例缩放,这样就将原来的数值映射到一个新的特定区域中。常用的方法有最小—最大规范化(将原始数据变换到 [0,1] 的空间中)、Z—score 规范化(新数值 =(原数值 - 均值)/ 标准差,可以将数据转换为正态分布的情况)、按小数定标规范化(移动小数点的位置来进行规范化)等
属性构造:构造出新的属性并添加到属性集中。这里会用到特征工程的知识,因为通过属性与属性的连接构造新的属性,其实就是特征工程。比如说,数据表中统计每个人的英语、语文和数学成绩,可以构造一个“总和”来作为新属性。这样“总和”这个属性就可以用到后续的数据挖掘计算中。
使用SciKit-Learn 库来进行数据规范化
数据挖掘中数据变换比算法选择更重要
7 数据可视化
常用的可视化视图超过 20 种,分别包括:文本表、热力图、地图、符号地图、饼图、水平条、堆叠条、并排条、树状图、圆视图、并排圆、线、双线、面积图、双组合、散点图、直方图、盒须图、甘特图、靶心图、气泡图等。
使用这些视图的目的有9种情况:
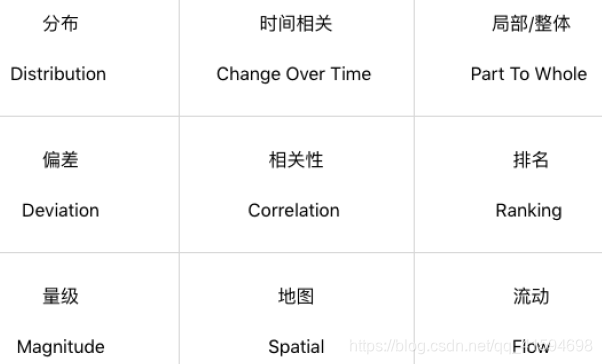
在设计之前需要思考的是:用户是谁,想给他们呈现什么,需要突出数据怎样的特点,以及采用哪种视图来进行呈现。(具体要采用哪种视图,取决于想要数据可视化呈现什么样的目的。)
数据可视化的工具:Tableau、PowerBI、FineBI、DataV、FineReport
Python库:Matplotlib 和 Seaborn。
可视化视图分为四类:比较、、联系、构成和分布
比较:比较数据间各类别的关系,或者是它们随着时间的变化趋势,比如折线图;
联系:查看两个或两个以上变量之间的关系,比如散点图;
构成:每个部分占整体的百分比,或者是随着时间的百分比变化,比如饼图;
分布:关注单个变量,或者多个变量的分布情况,比如直方图。
按照变量的个数,也可以把可视化视图划分为单变量分析和多变量分析。
8 概念解析
- 数据规范化、归一化、标准化
数据规范化是更大的概念,它指的是将不同渠道的数据,都按照同一种尺度来进行度量;
这样做有两个好处,一是让数据之间具有可比较性;另一个好处就是方便后续运算,因为数据在同一个数量级上规整了,在机器学习迭代的时候,也会加快收敛效率。
数据归一化和数据标准化是数据规范化的方式;
不同点在于数据归一化会让数据在一个[0,1] 或者 [-1,1] 的区间范围内,而数据标准化会让规范化的数据呈现正态分布的情况,
归一化的“一”,是让数据在 [0,1] 的范围内。而标准化,目标是让数据呈现标准的正态分布。
