RepVGG是2021年发表于CVPR,它和resnet一样是一种图像分类网络,在目标检测中被用作backbone,论文提出一种新型技术称之结构重参数化,简单来说就是对训练出的模型进行等价替换成一个简单的模型,然后用这个简单的模型进行推理(也就是testing),目的就是加快推理速度,提高模型实用性。
论文地址:https://arxiv.org/abs/2101.03697
论文源码:https://github.com/megvii-model/RepVGG
目录
1、摘要和引言(RepVGG是什么)
这两部分提出了RepVGG网络出现的背景以及大致功能优点,由于当前的网络架构都非常的庞大推理速度慢如ResNet-101,论文提出一个简单又高效的网络,推理时结构像VGG一样只有3x3卷积和ReLU,训练时有多个残差边。并且在ImageNet上的有一个非常不错的成绩

对于复杂的网络明明可以达到一个非常高的精度为什么不用呢?
复杂的多分支模型虽然可以达到比较高的准确率,但是也有一些明显的缺点。1)会降低模型的推理速度并且减少内存利用率(后面会提到),2)有些节点会增加内存消耗并且对别的设备不友好。但是在工业中,VGG和ResNet还是非常的受欢迎。论文中提到,大部分学者提到FLOPs会影响推理速度,但是论文中作者做了实验发现FLOPs对模型的速度好像没太大关系,如RepVGG-B3的FLOPs比EfficientNet大但是Speed更快
针对以上缺点,作者提出decouple the training-time multi branch and inference-time plain architecture via structural re-parameterization,通过结构重参数化将训练多分支模型解耦成推理平滑模型,又因为推理模型结构和VGG很像被称之RepVGG,这个技术简单来说,因为模型是由一组参数构建而成,那么是否能够找出另一组参数与其效果相同,而新的这组参数对应的模型用于推理,这就是结构重参数化。
1.1RepVGG模型结构
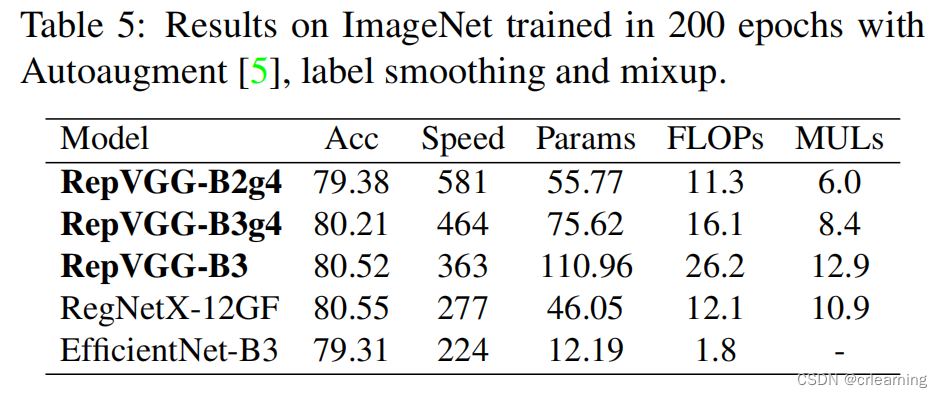
RepVGG沿用ResNet的残差边,只不过RepVGG在每一层都使用了残差连接,3x3卷积接上一个identity和1x1的卷积,图中B代表在训练时所使用的模型结构,图中C代表推理时所用的模型结构,在训练模型当中,在每一分支输出前加一个BN层,如何将B->C就是重参数化的重要体现,下面会谈到实现细节,先了解大概流程
2、作者所作的相关研究
1、网络从单一到多分支的发展)VGG是一种单路径网络结构也就是没有残差边,精度在当年也还不错,但是在ResNet和DenseNet提出后精度就被比下去了,但是想DenseNet超大型网络不一定能在普通GPU上训练,因此限制了它的实用性,此外还存在这推理速度慢的问题,并行度低。
2、单一模型训练的有效性)作者做了一些对比实验,在单一模型和多分支模型上,显然是多分支模型在训练上的效果更好并且预测结果更精确,因此作者设计网络时并没有抛弃多分支结构,而是在推理时将其融合成单一路径。
3、模型重参数化)作者提到在DiracNet当中使用的重参数化方式和RepVGG不同,DiracNet在训练时将网络进行调整,换句话说RepVGG训练时还是一个多分支结构,但是DiracNet不是。
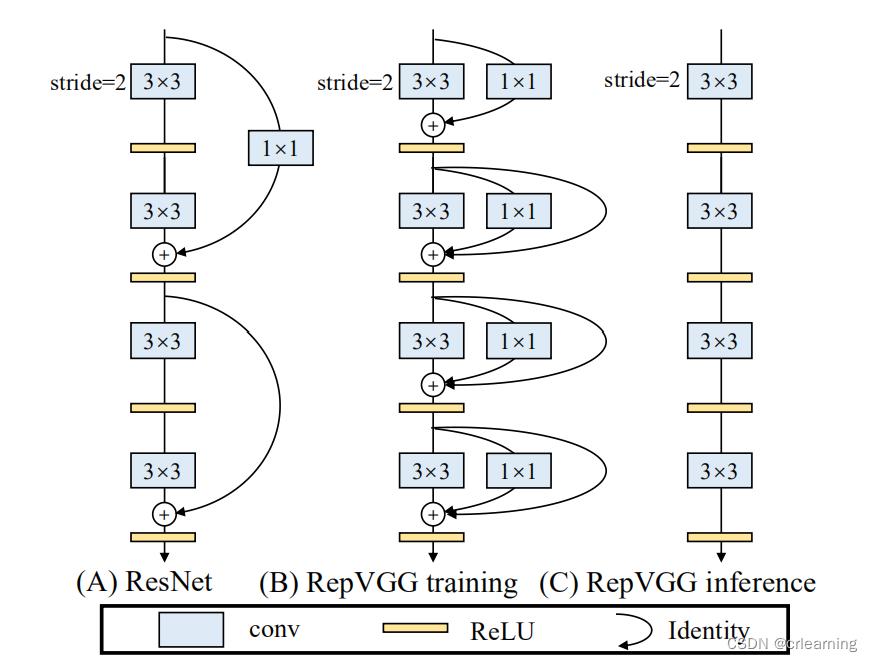
4、为什么使用3x3卷积)在GPU上3x3卷积被封装优化,计算密度对比其他卷积高,作者也做了相关实验
3、RepVGG的优点
1)Fast,使用重参数化后,在推理上速度会有非常大的提升,并且有助于模型部署提高实用性。2)节省内存,采用多分支模型,在每次计算都需要多份内存分别保存每条分支的结果,所以导致内存消耗大

3)修改模型会更加方便,使用多分支存在一个问题,就是每条分支的输入通道和输出通道要保持一致,那么对模型的修改产生不便,如果是单路径就不存在这个问题
4、怎么实现结构重参数化
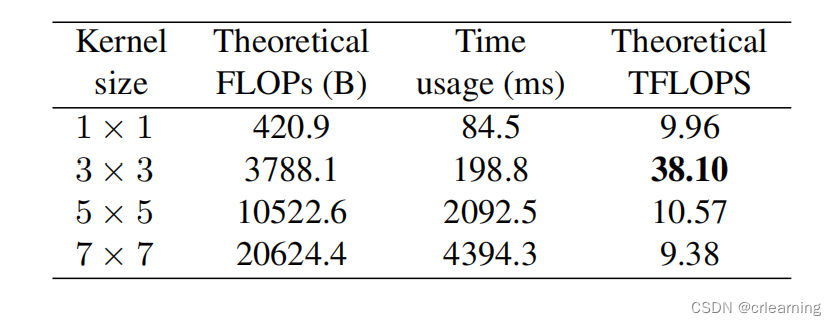
在上述提到,RepVGG在训练时每一层都有三个分支,分别是identify,1x1,3x3,模型训练时,输出,每一层就需要3个参数块,对于n层网络,就需要
个参数块。所以我们需要重参数化,会使得推理时模型参数量小。
第一个问题,在每个卷积后都接上一个BN,怎么将卷积和BN融合。第二个问题,存在不同大小的卷积,怎么将几个不同大小的卷积融合在一起。
对于第一个问题,假如输入为M(1),卷积核为W,BN后的输出为:
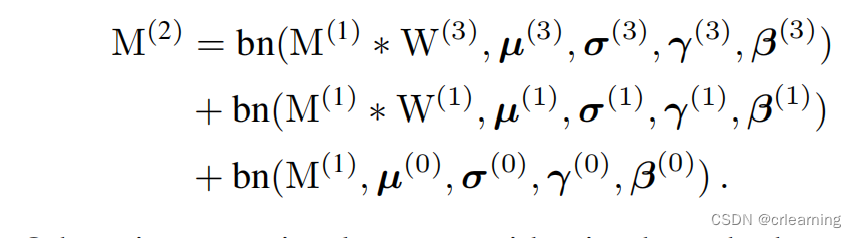
BN是怎么计算的:

提出其中的M特征图和偏移量:
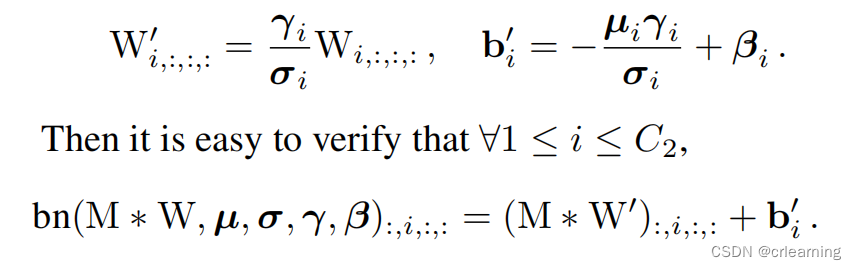
所以卷积加上BN等于三个卷积核的融合对M进行卷积再加上偏置
第二个问题,对于1x1的卷积,对1x1扩充为3x3,多余部分补0,而identify也可转化成1x1,所以将三个3x3累加就形成新的3x3卷积,至此完成整个重参数化操作
5、模型部署
作者针对小模型和大模型对RepVGG进行设计,层数分别为[1, 2, 4, 14, 1]和[1, 4, 6, 16, 1],小模型称之RepVGG-A,大模型RepVGG-B,对于每层的通道数[64a, 128a, 256a, 512b],

为什么这样设计,作者提到因为第一层输入的图片分辨率高,所以通道数不能太大,可能导致计算量过大。最后stage设计了512b是因为最后只有一层,所以大一点有助于存储参数。其中在4stage中有14层block,这是借鉴ResNet的架构布局
6、实验对比
作者提出7个模型和主流模型在Imagenet上进行对比: 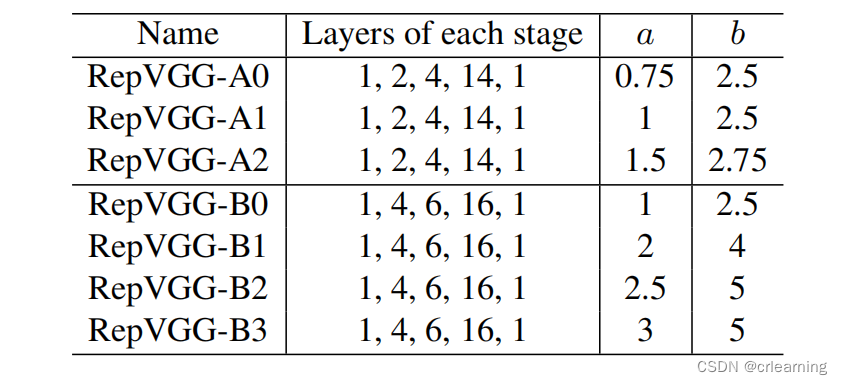
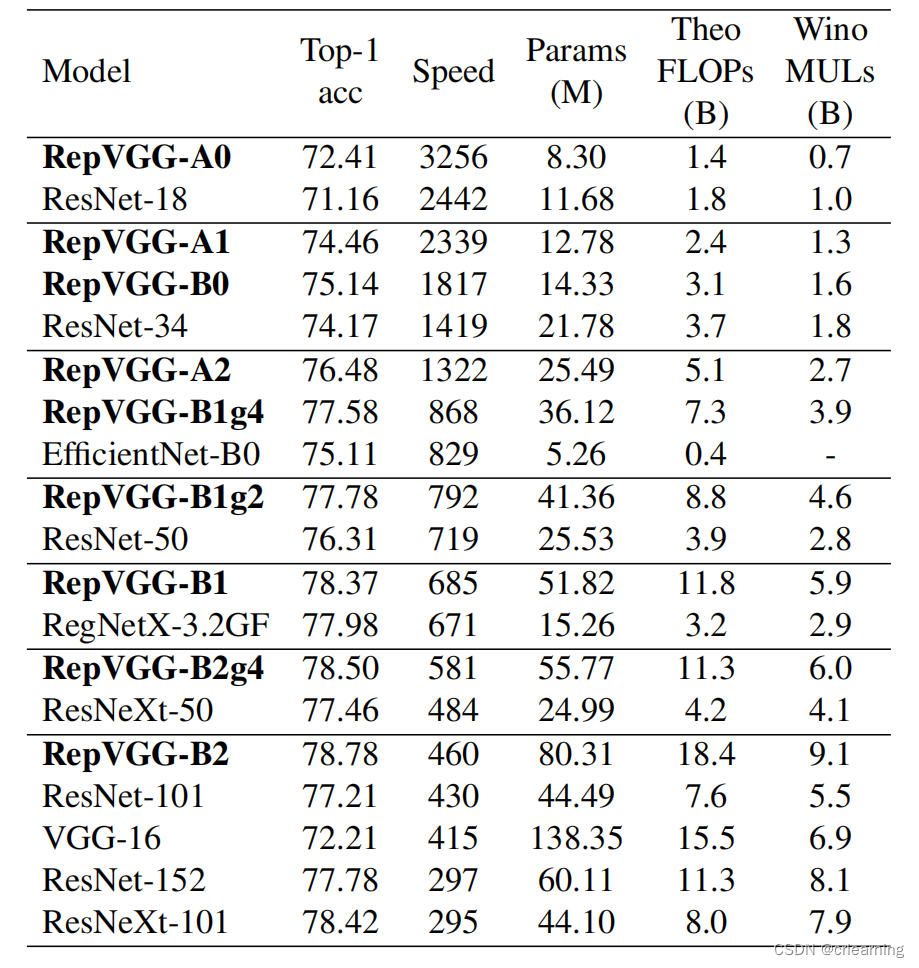
从实验可以看出,RepVGG的推理速度是比较快的,虽然参数比ResNet大,但是使用重参数化替换成推理模型,说明这个工作是非常有效果的。下图RepVGG-B0不做重参数化的速度,比起上图的速度有一个很大的降低,提升将近50%
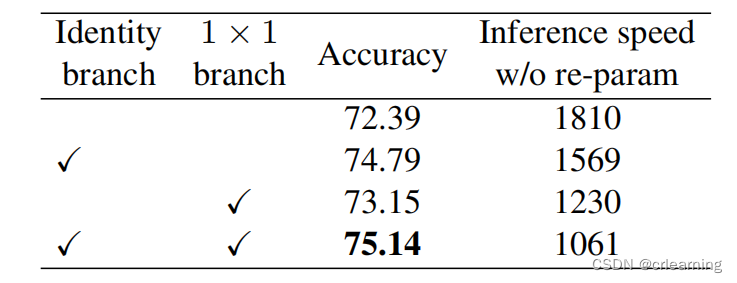
总之,RepVGG当中的结构重参数化这个方法值得我们去学习,对模型的部署非常友好,在未来的发展中,重参数化会越来越受欢迎(YOLOv6使用了这个方式)。