#Redis系列-4.哈希(Hash)结构
文章中可能有地方描述偏差,欢迎留言指证
##1.基本
hash是第二种redis结构,在编程语言中非常常见。在redis里,哈希又是另一种键值对结构。redis本身就是key-value型,哈希结构相当于在value里又套了一层kv型数据。哈希和C#里的字典,java里的map结构是一样的。
假如输入命令 hset testKey testField testValue(效果如图)
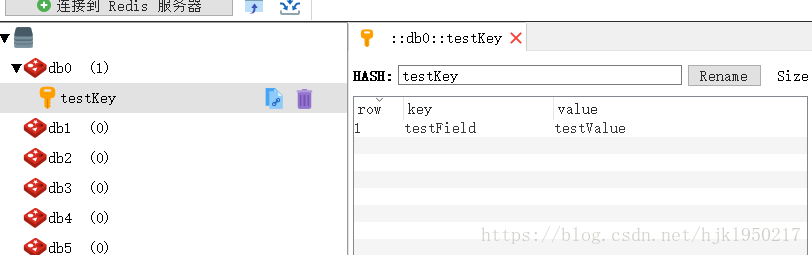
##2.常用命令
下面所有描述里 {}都是必需参数,<>是可选参数
####设置值
hset {key} {field} {value}
key:键名
field:哈希结构中的键名
value:哈希结构中的键名对应的值
注意,这里只能设置一条。如果要设置多条,用 hmset命令 hset {key} {field} {value} [{field} {value}…]
####获取值
hget {key} {field}
如果不存在,会返回nil。
这里第一个key是找到这个哈希结构的数据,第二个参数field是取里面对应的值。
当返回nil时,是里面的这一个值不存在,而不是这个哈希结构数据不存在
批量获取用hmget
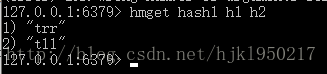
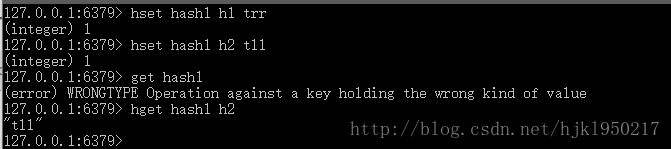
获取和设置如下图
####统计field个数
hlen {key}
####判断field是否存在
hexists {key} {field}
这里判断的是哈希中存不存在,而不是判断这一整条哈希数据存在。如果要判断这一整条数据是否存在,用exists
####遍历哈希结构
遍历键
hkeys {key}
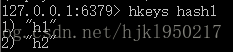
遍历值
hvals {key}
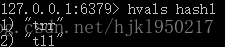
遍历键和值
hgetall {key}
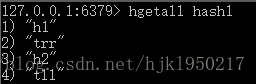
使用时,这个命令会遍历所有的,当数据量大时会阻塞redis。redis是单线程程序,只要阻塞就会一直卡住,所以在线上环境不要使用。
3.不常用命令
####自增、自减
hincrby {key} {field}
hincrbyfloat {key} {field}
和上一节讲的incrby incrbyfloat一样,只是这里的作用在哈希数据的值上面。
4.内部编码
有两种:
ziplist:
内部更加紧凑。
当键的个数小于hash-max-ziplist-entries(默认512)的配置时
同时所有值小于hash-max-ziplist-value(默认64)的配置时
才会使用ziplist
hashtable:
当不能使用ziplist时,就会使用这个结构,因为不满足上面两个条件时,ziplist的读写效率会降低。而hashtable的读写时间复杂度为O(1)。
5.适合场景
1.存对象信息
但使用hash存对象的信息时要注意避免在ziplist和hashtable之间进行转换。hashtabl会消耗更多的内存。