谈谈数据压缩的机制
前言
本文简单谈谈压缩数据的机制,并介绍几种压缩算法。数据压缩我们在生活中经常用到,比如把数据压缩打包为zip,rar等等。那么我们有没有思考过,数据为什么能压缩呢?它的机制是什么呢?本篇博客将进行详解。
一、文件以字节为单位保存
文件是将数据存储在磁盘等存储媒介中的一种形式。程序文件中存储数据的单位是字节。文件的大小之所以用 ××KB、××MB 等来表示,就是因为文件是以字节(B = Byte)为单位来存储的 。因此,文件就是字节数据的集合。那么,如果我们想要压缩数据,最后肯定都归结到一点,那就是把文件中原有的字节个数所表达的内容,用更少的字节数进行表达。
二、RLE 算法的机制
- RLE(Run Length Encoding,行程长度编码)算法,是把文件内容中连续重复的数据结合重复个数进行记录,以达到数据压缩的目的。如原始文件中的内容AAAAAABBCDDEEEEEF,用RLE算法就可以表示为 A6B2C1D2E5F1。这样由原来的17个字节压缩到12个字节(文件压缩率为12/17约等于70%),达到了压缩数据的目的。
- 但是,在实际的文本文件中,同样字符连续重复出现的情况并不多见。虽然针对相同数据经常连续出现的图像、文件等,RLE算法可 以发挥不错的效果,但它并不适合文本文件的压缩。
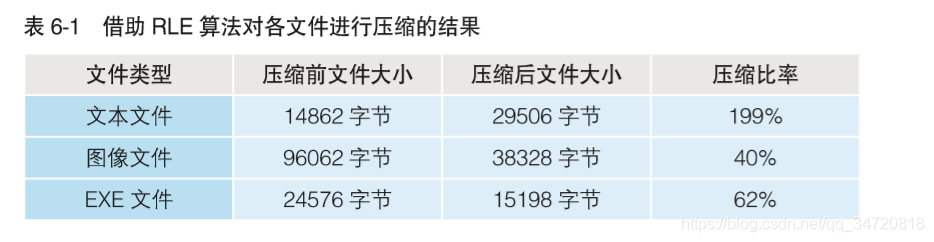
上图中,可以发现利用RLE算法对文本文件不但没有起到压缩数据的目的,反而使得数据占用字节数更加多了。这个应该也很好理解,比如ABC,用RLE算法压缩后变为了A1B1C1,由原来的3个字符变成了6个字符,这也正是RLE算法的致命缺点。
三、哈夫曼算法
- 哈夫曼算法的关键就在于多次出现 的数据用小于 8 位的字节数来表示,不常用的数据则可以用超过 8 位 的字节数来表示。8个A 和 3个Q 都用 8 位来表示时,原文件的大小就是 100 次 × 8位 + 3次 × 8位 = 824位,而假设A用2位、Q用10位来 表示,压缩后的大小就是100次 ×2位+3次 ×10位 = 230位。这样就可以保证数据所占磁盘空间得到最大的优化。
- 不过有一点需要注意,不管是不满8位的数据,还是超过 8 位的 数据,最终都要以 8 位为单位保存到文件中。这是因为磁盘是以字 节(8 位)为单位来保存数据的。
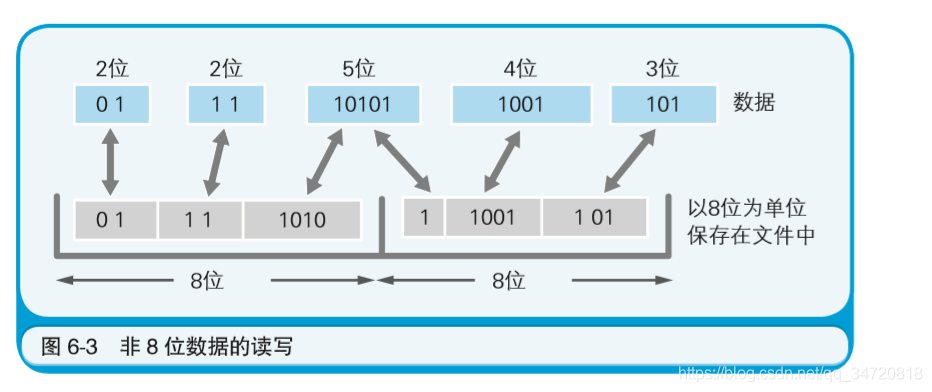
- 哈夫曼算法是指,为各压缩对象文件分别构造最佳的编码体系,并以该编码体系为基础来进行压缩。 也就是说,哈夫曼算法对某个文件进行压缩之前,会先对文件设置最佳的编码体系(根据字符出现频率,来分配每个字符所占的位数)。如对于AAAAAABBCDDEEEEEF的哈夫曼压缩,其流程是先按照“出现频率高的字符用尽量少的位数编码来表示”这一原则进行整理,得到该文件的编码体系,然后再根据该编码体系进行数据的存储。
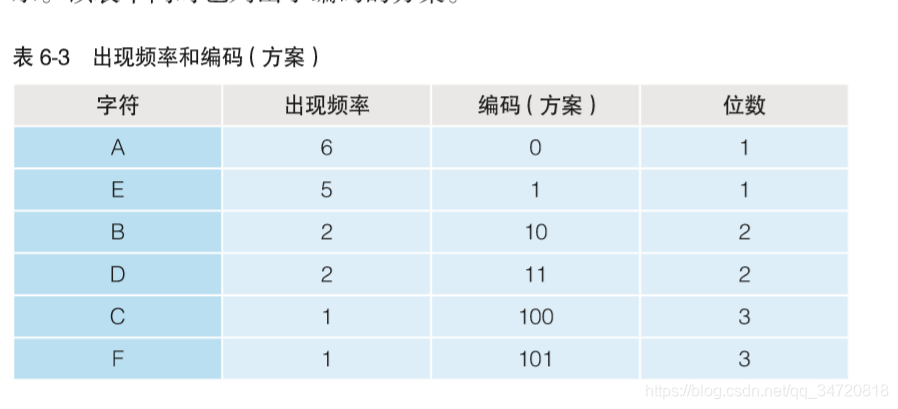
- 但是,上面的压缩方法还有一点不足,那就是在每个字符之间必须加入分隔符进行分隔,不然会造成数据混淆,比如100这三个bit,用1、0、0这3个编码来表示就是E、A、A;用 10、0这两个编码来表示就是B 、A;用100来表示就是C;因此必须加入分隔符号才能避免这种情况,但是,加入分隔符又会占用空间,有没有方法可以不加分隔符就能区分哈夫曼压缩算法呢?
- 通过借助哈夫曼树构造编码体系,即使在不使用字符区分符号的情况下,也可以构建能够明确进行区分的编码体 系。也就是说,利用哈夫曼树后,就算表示各字符的数据位数不同, 也能够做成可以明确区分的编码。比如AAAAAABBCDDEEEEEF,用哈夫曼树构造编码体系如下

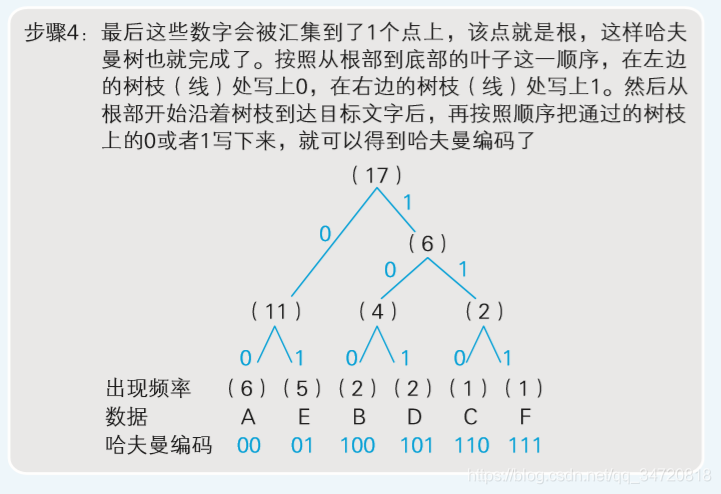
- 按照上图哈夫曼树编码体系得到的编码,就不会出现因没有分隔符而导致的数据混乱情况,因为通过哈夫曼树得到的每个字符的编码都具有唯一性,所以就算字符之间没有分隔也可以准确地读取数据。
-同时,通过上图的步骤2大家应该可以发现,为什么哈夫曼算法可以分配出最佳的编码方案可,因为在用枝条连接数据时,我们是从出现频率较低的数据开始的,这就意味着出现频率越低的数据到达根部 的枝条数就越多,而枝条数越多,编码的位数也就随之增多了。