压缩
为什么要压缩?
1)减少磁盘的存储空间
2)减少网络和磁盘的IO
3) 加快数据在磁盘和网络中的传输速度,从而提高系统的处理速度
压缩的局限性
每次使用数据时需要先将数据解压,加重CPU负荷。
压缩格式
| 压缩格式 |
工具 |
算法 |
文件扩展名 |
是否可切分 |
| DEFAULT |
无 |
DEFAULT |
.deflate |
否 |
| Gzip |
gzip |
DEFAULT |
.gz |
否 |
| bzip2 |
bzip2 |
bzip2 |
.bz2 |
是 |
| LZO |
lzop |
LZO |
.lzo |
设置索引后可切分 |
| LZ4 |
无 |
LZ4 |
.lz4 |
否 |
| Snappy |
无 |
Snappy |
.snappy |
否 |
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器,如下表所示
| 压缩格式 |
对应的编码/解码器 |
| DEFLATE |
org.apache.hadoop.io.compress.DefaultCodec |
| gzip |
org.apache.hadoop.io.compress.GzipCodec |
| bzip2 |
org.apache.hadoop.io.compress.BZip2Codec |
| LZO |
com.hadoop.compression.lzo.LzopCodec |
| LZ4 |
org.apache.hadoop.io.compress.Lz4Codec |
| Snappy |
org.apache.hadoop.io.compress.SnappyCodec |
选择压缩算法需通过以下三个指标:
1)是否可切分?
由上表可看出, bzip2支持切分, LZO在设置索引后也是支持切分。
2)压缩比

以压缩比做评估,由好到差依次为: BIZP2>GZIP>LZ4 ≈ LZO ≈ SNAPPY
3)压缩性能

以压缩性能作为评估,由好到差依次为:Snappy>LZ4>LZO>GZIP>BZIP2
可以看出, 压缩比越优秀的,压缩性能就越差。
压缩格式各自优缺点
gzip
优点:
压缩比在四种压缩方式中较高;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;有hadoop native库;大部分linux系统都自带gzip命令,使用方便
缺点:
不支持split
lzo
优点:
压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便
缺点:
压缩率比gzip要低;hadoop本身不支持,需要安装;lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要指定inputformat为lzo格式)
snappy
优点:
压缩速度快;支持hadoop native库
缺点:
不支持split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令
bzip2
优点:
支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便
缺点:
压缩/解压速度慢;不支持native。
压缩在hadoop中的应用
根据MR的执行流程,详见https://mp.csdn.net/postedit/88049264。
大致如下:
待续
在hadoop中启用压缩(mapred-site.xml)
| 参数 |
默认值 |
阶段 |
建议 |
| io.compression.codecs (在core-site.xml中配置) |
org.apache.hadoop.io.compress.DefaultCodec, org.apache.hadoop.io.compress.GzipCodec, org.apache.hadoop.io.compress.BZip2Codec, org.apache.hadoop.io.compress.Lz4Codec |
输入压缩 |
Hadoop使用文件扩展名判断是否支持某种编解码器 |
| mapreduce.map.output.compress |
false |
mapper输出 |
这个参数设为true启用压缩 |
| mapreduce.map.output.compress.codec |
org.apache.hadoop.io.compress.DefaultCodec |
mapper输出 |
应首先考虑压缩速率高的压缩格式 |
| mapreduce.output.fileoutputformat.compress |
false |
reducer输出 |
这个参数设为true启用压缩 |
| mapreduce.output.fileoutputformat.compress.codec |
org.apache.hadoop.io.compress. DefaultCodec |
reducer输出 |
若reduce输出是作为下一阶段的输入,则考虑压缩速率高的。 若reduce输出持久化磁盘,则考虑压缩比高的 |
| mapreduce.output.fileoutputformat.compress.type |
RECORD |
reducer输出 |
SequenceFile输出使用的压缩类型:NONE和BLOCK |
在Hive中启动压缩(临时启动,通过上述方式修改配置文件也可以开启压缩)
启用map阶段压缩:
-
1)开启hive中间传输数据压缩功能 -
hive >set hive.exec.compress.intermediate=true; -
2)开启mapreduce中map输出压缩功能 -
hive >set mapreduce.map.output.compress=true; -
3)设置mapreduce中map输出数据的压缩方式 -
hive >set mapreduce.map.output.compress.codec= org.apache.hadoop.io.compress.SnappyCodec;
启用reduce阶段压缩:
-
1)开启hive最终输出数据压缩功能 -
hive >set hive.exec.compress.output=true; -
2)开启mapreduce最终输出数据压缩 -
hive >set mapreduce.output.fileoutputformat.compress=true; -
3)设置mapreduce最终数据输出压缩方式 -
hive > set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.SnappyCodec; -
4)设置mapreduce最终数据输出压缩为块压缩 -
hive >set mapreduce.output.fileoutputformat.compress.type=BLOCK;
注:通过hive.exec.compress.output参数启用hive压缩, 默认是false。
总结
不同的场景选择不同的压缩方式,肯定没有一个一劳永逸的方法,如果选择高压缩比,那么对于cpu的性能要求要高,同时压缩、解压时间耗费也多;选择压缩比低的,对于磁盘io、网络io的时间要多,空间占据要多;对于支持分割的,可以实现并行处理。
存储
列式存储与行式存储
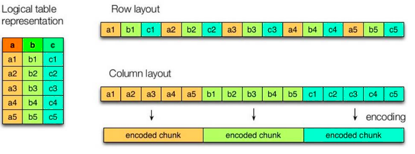
行存储的特点: 查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
TEXTFILE格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
ORC格式
Orc (Optimized Row Columnar)是hive 0.11版里引入的新的存储格式。

可以看到每个Orc文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于RowGroup概念,不过大小由4MB->250MB,这样能提升顺序读的吞吐率。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
1)Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引只是记录某行的各字段在Row Data中的offset。
2)Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
3)Stripe Footer:存的是各个Stream的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
PARQUET格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式如下图所示。

上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。