本节回到主题-数据去重
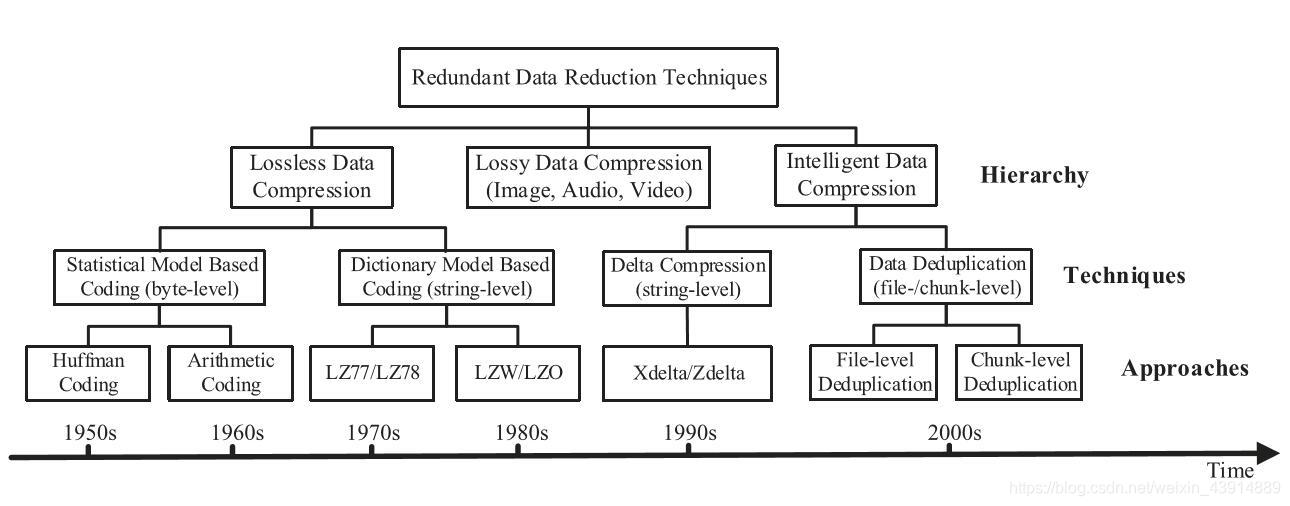
块级重复数据消除主要流程
- chunking 分块
- fingerprinting 指纹
- indexing of fingerprints 指纹索引
- further compression 进一步压缩(可选)
- storage management. 存储管理
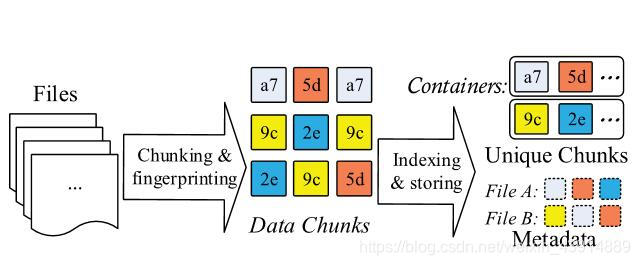 在这里实际上有很多问题,例如索引过大超过RAM怎么做缓存,以及真实数据存放在哪里、如何寻找以及如何完成IO操作等一系列问题暂时按下不表。
在这里实际上有很多问题,例如索引过大超过RAM怎么做缓存,以及真实数据存放在哪里、如何寻找以及如何完成IO操作等一系列问题暂时按下不表。
本文讨论的数据去重特指重复数据的去重,和数据库中的去重(对记录的去重)有着本质区别
压缩的本质就是用更少的bit代表更多的东西,它的上界已经由香农给出了,而在现实生活中往往有很多时候我们只需要还原个大概(例如你的私房钱),所以压缩就分为有损压缩和无损压缩
压缩分为有损压缩和无损压缩
无损压缩通过以可逆方式识别和消除统计冗余来减少数据,如GZIP和LZW等算法所示。有损压缩通过识别不必要的信息并无可挽回地删除它来减少数据,如JPEG图像压缩
而对于压缩来说,香农大师很早就告诉我们,凡事都有个度,不可能一辈子压缩下去。具体怎么算看下面文章告诉你我就不写了。
所以你想把一个文件压缩一百次压倒无穷下是不可能的,实际上会越压越大
这里是压缩一百次以后会发生什么的视频链接,原谅我这么无聊
所以在早期,就是一群人天天在那个地方猜怎么编码用的字符少,后来huffman发明了huffman编码,一种二叉树结构编码能够比较好的接近极限。然后由于huffman是整数,有人在上面做了一些改动。改成小数。此时的压缩都是基于byte的
后来LZ算法横空出世,并且产生了不同的变体。其核心都是形成一个字典,使用滑动窗口标识重复字符串,并用匹配字符串的位置和长度替换这些重复字符串。此时的压缩基于字符串string
然而上述两种方法都有很大的局限性,熵编码方法需要在将频繁出现的字节编码为较短的比特之前计算所有信息,字典编码方法需要搜索所有字符串,以支持匹配和消除重复字符串。有过打题经验的同学都知道,这往往意味着n方的复杂度,这在数据处理中是不可接受的。所以这严重限制了压缩窗口的大小,而压缩窗口大小的广泛范围会导致整体压缩性的很大变化
近年来出现的就是数据去重,由于其良好的扩展性和粒度而热门。
byte level /string level / chunk level / file level