introduce
STMN——是一个RNN结构的网络,同时学习如何对目标的长期外观(long-term appearance)运动动力学进行建模和对齐。其核心是STMM——一个卷积循环计算单元,利用在静态图像数据库(如ImageNet)中训练得到的权重。因为是使用静态图像数据库的权重,所以对当前视频数据集缺少标记信息的情况不太敏感。
为了说明二维空间的视觉数据的本质,STMM在内存中存储每帧的空间信息,为了实现像素级准确的空间对齐,使用MatchTrans模块来显式地模拟跨帧运动引起的位移(详细过程见下方——时空存储对齐)。因为每帧的卷积特征在空间存储中被对齐和聚合,且存储中包含多帧的信息,所以任何目标对象的特征都易于定位。除此之外,每个区域的特征都可以通过存储中的ROI池化操作而轻易的获取到。
虽然RNN在计算机视觉领域被广泛应用,且基于RNN提出了很多方法,STMN方法与之前的方法有三点不同:
- STMN是对边框进行分类,而不是对帧或像素进行分类;
- 设计了一个新的循环计算单元,使用在静态图像数据集上训练的权重进行计算;
- 时空存储通过MatchTrans模块实现帧到帧的对齐。
STMN
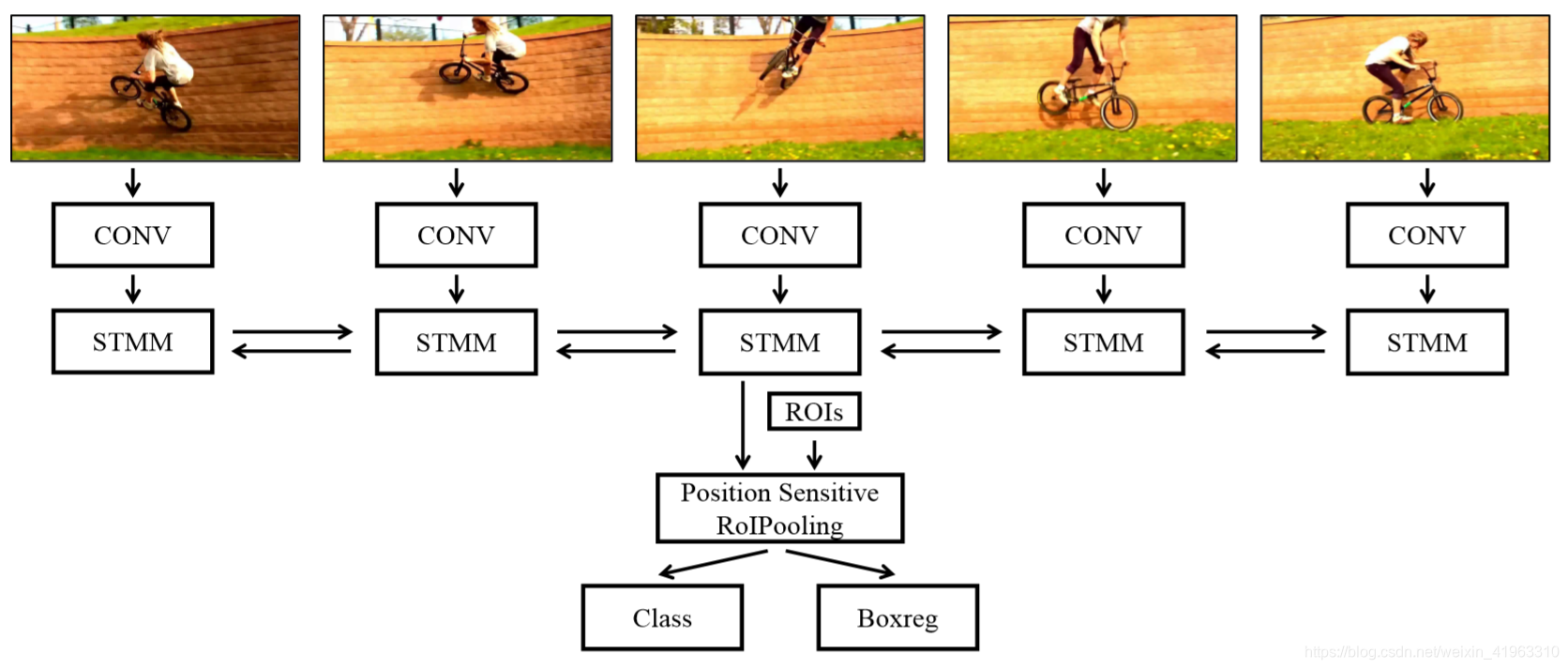
STMN的实现步骤:
- 将长度为T的视频序列中的每一帧传入卷积网络,得到对应的特征图F1,F2…FT;
- 每一帧的特征都分别传入STMM,位于帧t的STMM的输入为特征图Ft和一个时空存储(spatial-temporally memory) M t − 1 → M^→_{t-1} Mt−1→(其中内包含前t-1帧的信息),输出 M t → M^→_{t} Mt→;
- 为了使当前帧可以使用前后帧的信息,使用两个STMM分别获取 M → M^→ M→和 M ← M^← M←,把他们链接形成每帧的时间调制存储(temporally modulated memory) M M M;
- 因为M中也存储着空间信息,所以可以使用后续的卷积层和全连接层进行分类和边框回归操作;
STMM的实现细节:
-
每一个时间点,STMM都是把Ft和Mt-1作为输入并进行计算:
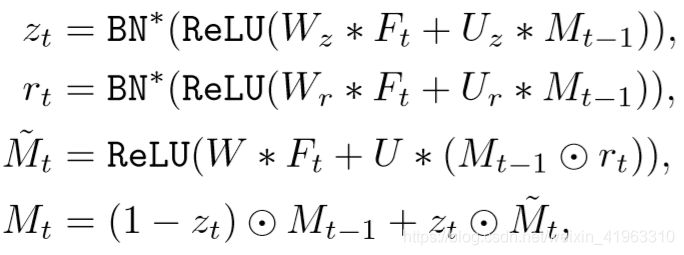
其中 ⨀ \bigodot ⨀表示对应元素相乘, ∗ * ∗表示卷积计算, U , W , U r , W r , U z , W z U,W,U_r,W_r,U_z,W_z U,W,Ur,Wr,Uz,Wz都是二维卷积核,门(gate) r t r_t rt掩膜 M t − 1 M_{t-1} Mt−1的元素(即允许其忘记之前的状态)来生成后续存储 M ~ t \tilde{M}_t M~t,门 z t z_t zt指出如何对 M t − 1 M_{t-1} Mt−1和 M ~ t \tilde{M}_t M~t进行加权和合并;
-
为了生成 r t r_t rt和 z t z_t zt,STMM对Ft和Mt-1进行仿射变换,然后使用ReLU进行处理得到最终结果。因为 r t r_t rt和 z t z_t zt是gate,其值只能为0或1,所以需要进行BatchNorm,这里使用零均值和单位标准偏差来替代传统的BatchNorm方法;
-
和标准ConvGRU的两点区别:①.为了更好的利用权重,需要确保循环单元的输出和预训练的权重相互兼容,因为标准ConvGRU的输出值位于[-1,1],与输入范围不匹配。为了解决这个问题,把标准ConvGRU内的Sigmoid和Tanh替换为ReLU;②使用卷积层的权重对 W z W_z Wz, W r W_r Wr和 W W W进行初始化,而不是随机初始化。从概念上讲,这可以看作是一种使用预先训练的静态卷积特征映射初始化内存的方法。
时空存储对齐(spatial-temporal memory align)
不使用空间对齐的话,存储会在目标移动后缺无法忘记它之前的位置,导致原来的位置会与后续的memory map叠加在一起,参数错误的结果产生多个识别框,产生假阳性检测结果(false positive detection)和不准确的定位,如下图:
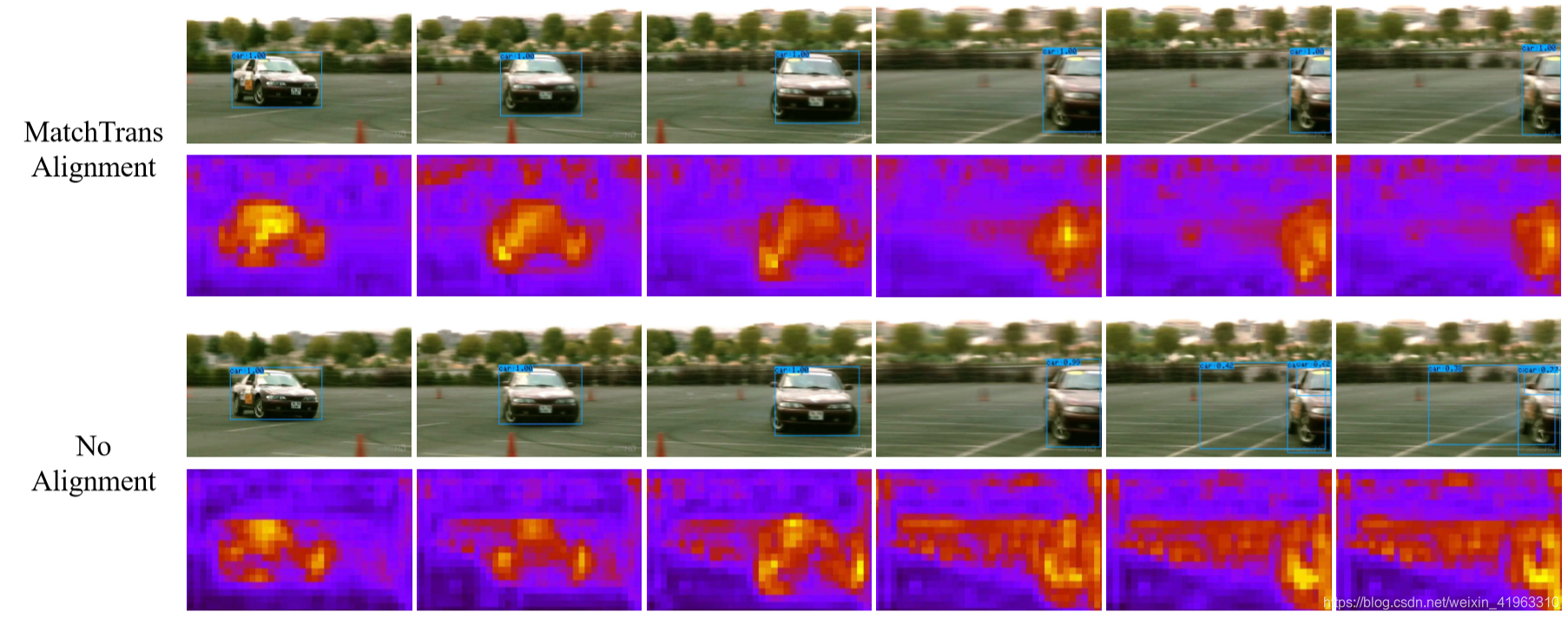
为了缓和这种情况,提出了MatchTrans模块来对齐帧间的时空存储。
因为 F t F_t Ft中的(x,y)对应 F t − 1 F_{t-1} Ft−1中(x,y)附近的一块区域,所以利用这个对应关系可以实现存储的对齐,来消除没对齐时产生的错误检测边框。
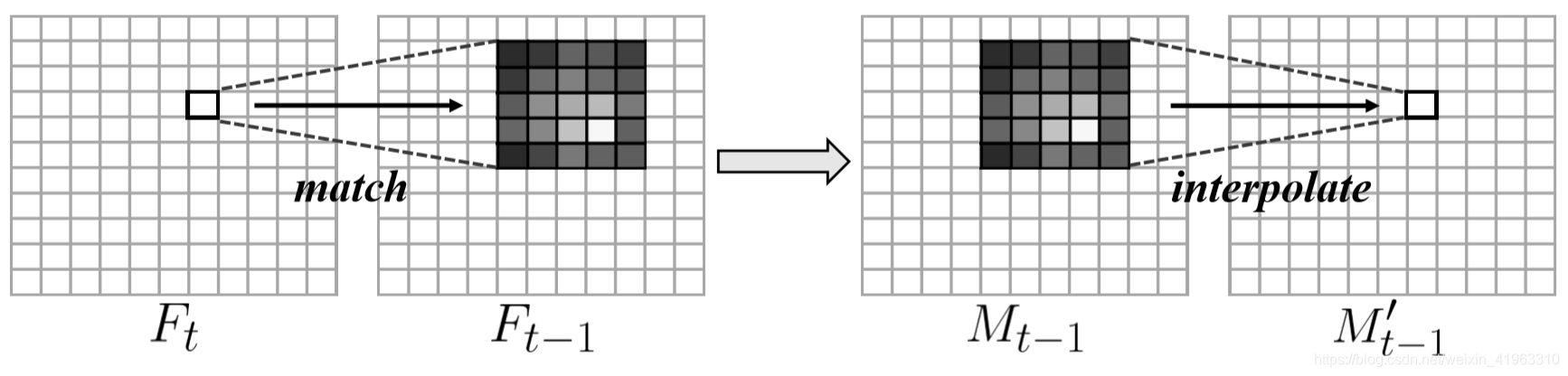
为了将时空存储 M t − 1 M_{t-1} Mt−1进行转换来与帧t对齐,使用MatchTrans计算特征 F t F_t Ft内位置(x,y)的特征块 F t ( x , y ) F_t(x,y) Ft(x,y)和其邻近帧 F t − 1 F_{t-1} Ft−1相同位置特征块 F t − 1 ( x , y ) F_{t-1}(x,y) Ft−1(x,y)的亲和性(affinity),转换系数 Γ \Gamma Γ:
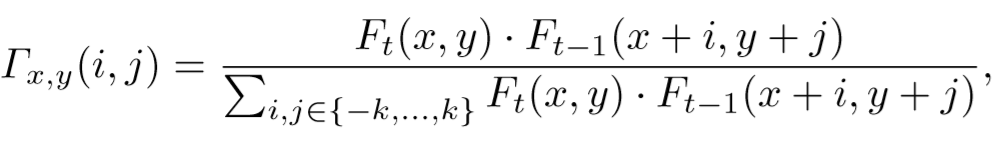
然后使用 Γ \Gamma Γ将未对齐的空间存储 M t − 1 M_{t-1} Mt−1转换为对齐的 M t − 1 ′ M^{\prime}_{t-1} Mt−1′:
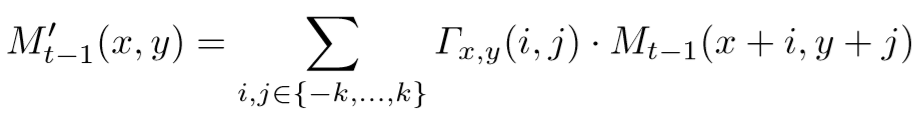
MatchTrans与之前的对齐方法相比,因为不需要计算和存储光流所以更加高效,而转换系数的获取过程与之前的方法相比,没有使用转换系数去跟踪和链接检测结果,而是用来随时间对齐存储以在每个候选区域产生个呢个好的特征。
最后使用Seq_NMS来确保邻近帧检测结果的空间平滑性。
总结
STMN的特点:
- STMN直接在训练时学习如何整合运动信息和时间依赖性,因为模型是端到端的训练,所以速度快。
- STMN只需要计算一个帧级空间存储,且它的计算独立于任何proposal。
- STMN聚合邻近超过两帧的信息,当计算邻近帧之间的相互关系时,会为了对齐而warp整个特征图,不仅仅是使用它来预测边框的偏移。
- 因为STMN使用在图像数据集训练得到的权重,所以针对当前视频数据集标准信息少的问题不太敏感。