声明:工作以来主要从事TTS工作,平时看些文章做些笔记。文章中难免存在错误的地方,还望大家海涵。平时搜集一些资料,方便查阅学习:TTS 论文列表 http://yqli.tech/page/tts_paper.html TTS 开源数据 http://yqli.tech/page/data.html。如转载,请标明出处。欢迎关注微信公众号:低调奋进
目录
1 背景
2 研究情况
3 总结
4 引用
1 背景
-
脑机接口的研究已经发展很长时间,在语音方面通常使用脑信息来进行语音识别和语音合成,其中脑信息的获取主要包括侵入式和非侵入式。侵入式方式的信息获取是通过手术把芯片植入到大脑中,这样可以减少很多噪声。非侵入式的信息获取是使用电子传感器通过头皮来获取信息,常用的就是脑电图(EEG),这种方式更加安全和廉价。基于EEG的语音合成主要使用EEG来预测声学特征或者直接预测波形,其训练使用的数据获取是当参与者录取音频的时候,同时获取其脑电图来获取<EEG, audio>的并行数据。脑机接口的语音合成还是非常有趣,至少可以实现玄幻中的"内功传音",想想这种场面:两个人戴着脑电波采集器并发射给对方,对方接受脑电波后合成语音,通过播放器可以听到对方的悄悄话。
2 研究情况
粗略的搜了一下2020年的基于脑电图EEG语音合成的文章,几篇文章都是出自德克萨斯大学奥斯汀分校脑机接口实验室,真是一招鲜,吃遍天呀!(有点失望的是没找到demo):
1)Advancing Speech Synthesis using EEG
2)Speech Synthesis using EEG
-
接下来我就主要对这三篇文章进行讲解。
2.1 Advancing Speech Synthesis using EEG
-
Advancing Speech Synthesis using EEG, 本文提出了基于attention的回归系统,使合成的声学特征更加逼近于真实的特征。
本文主要是使用attention机制来优化基于EEG的语音合成,其中attention机制主要如下的公式1~3。我们可以看一下图1所示的架构,该架构很简单,就不再阐述(这类似的图在接下来的几篇文章都会出现)。图2展示了两种实验方式,直接从EEG转成声学特征MFCC,第二种是先使用EEG转成发音的特征articulatory,然后再转成MFCC。
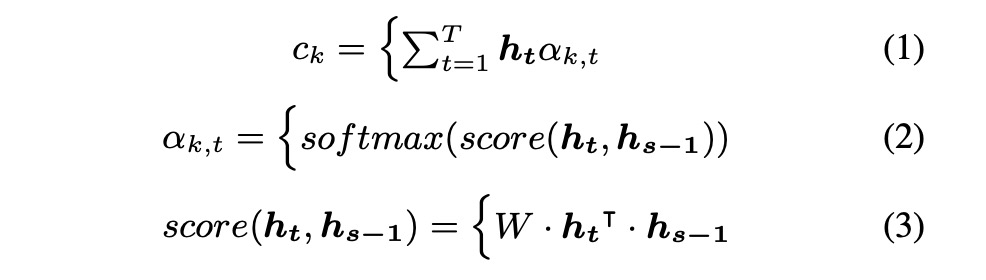
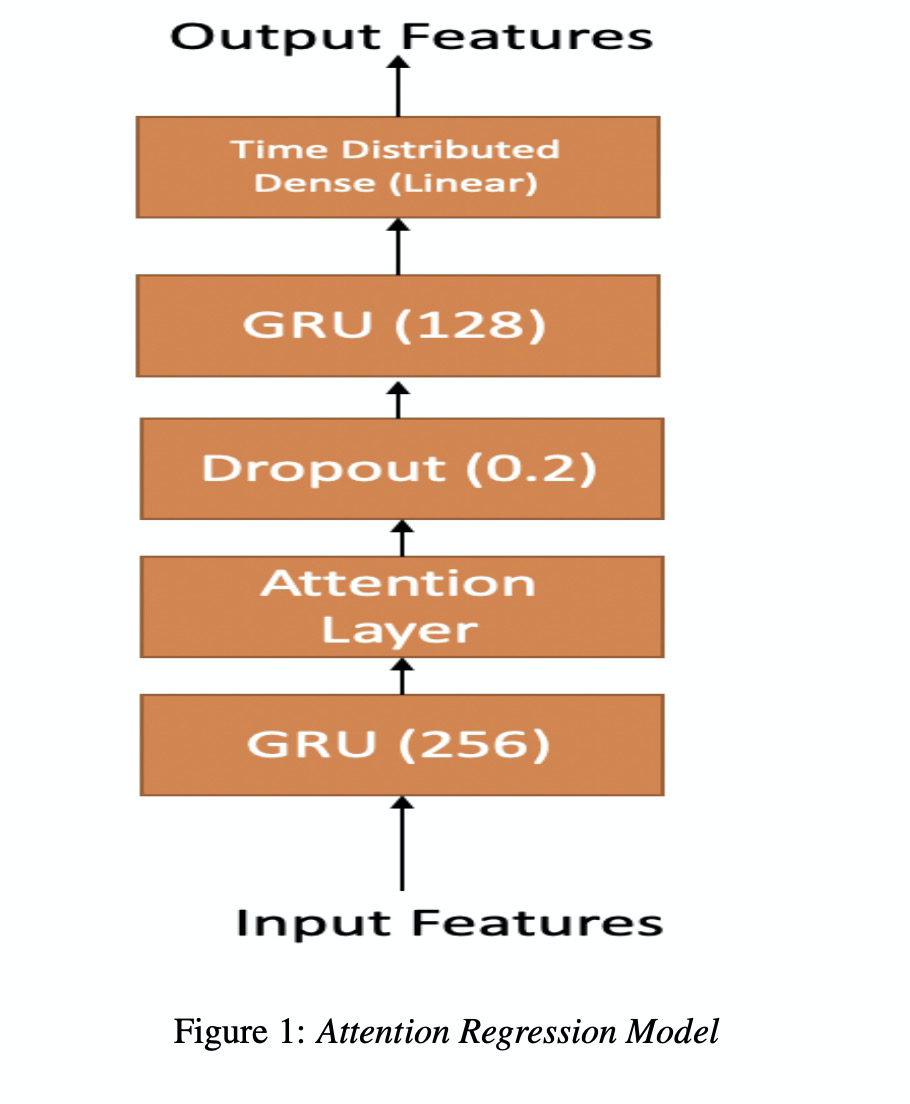
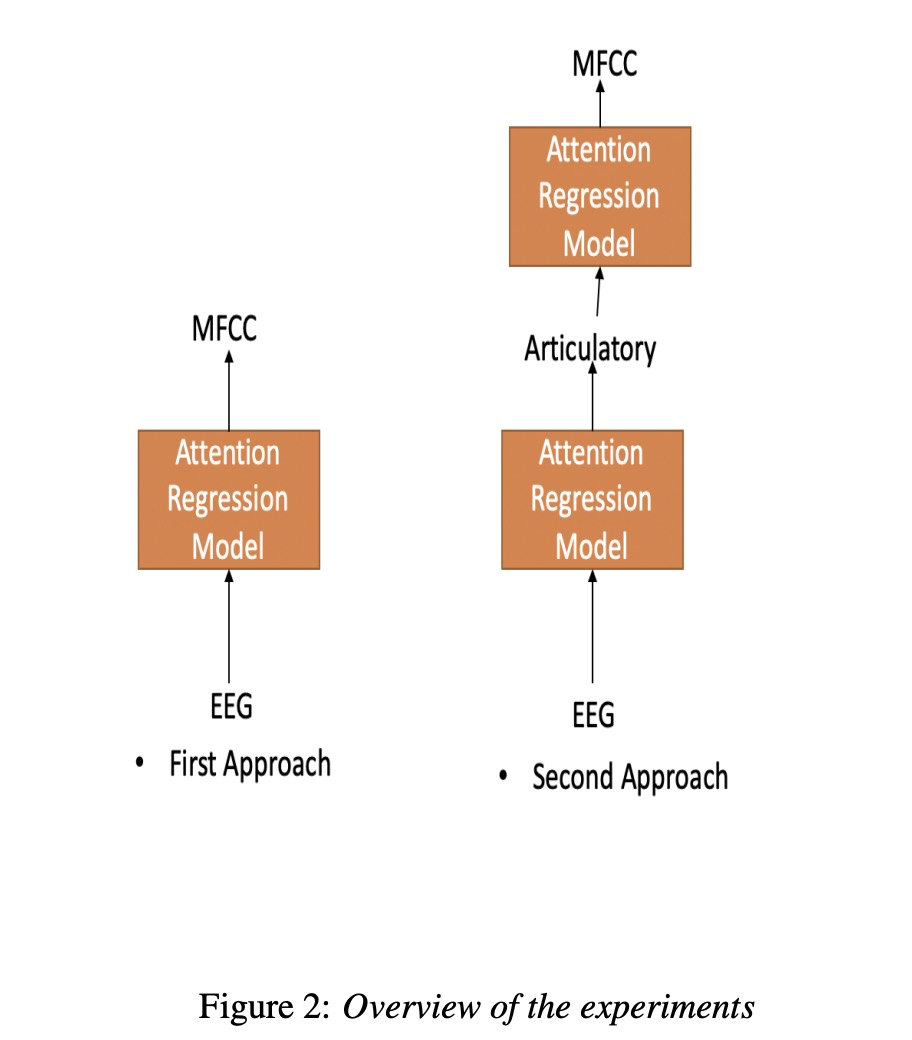
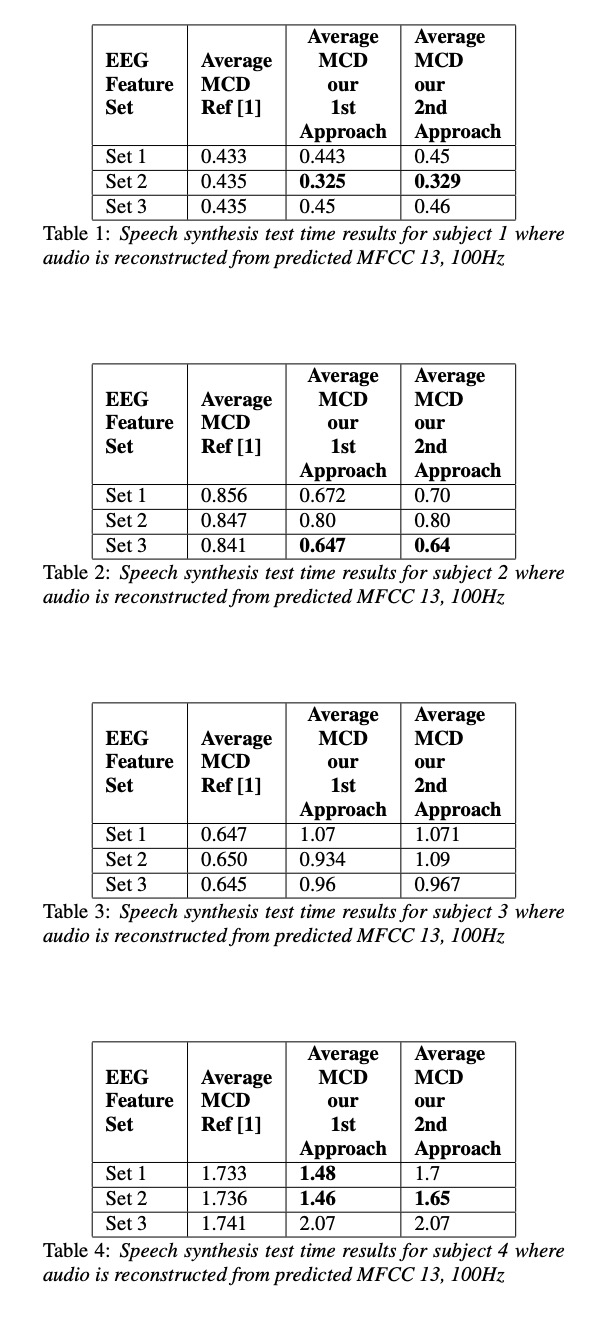
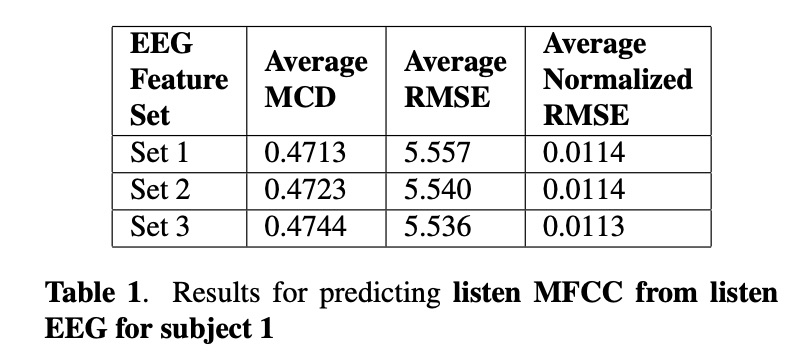
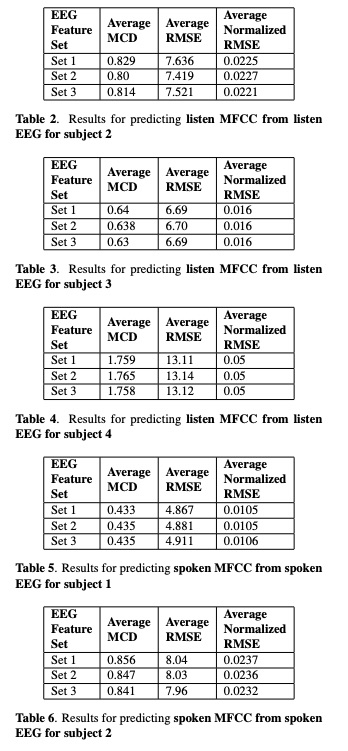
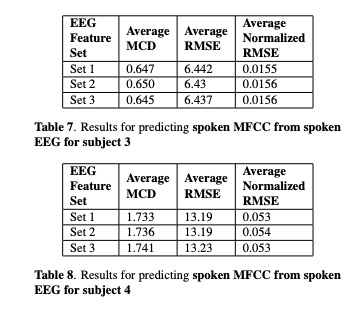
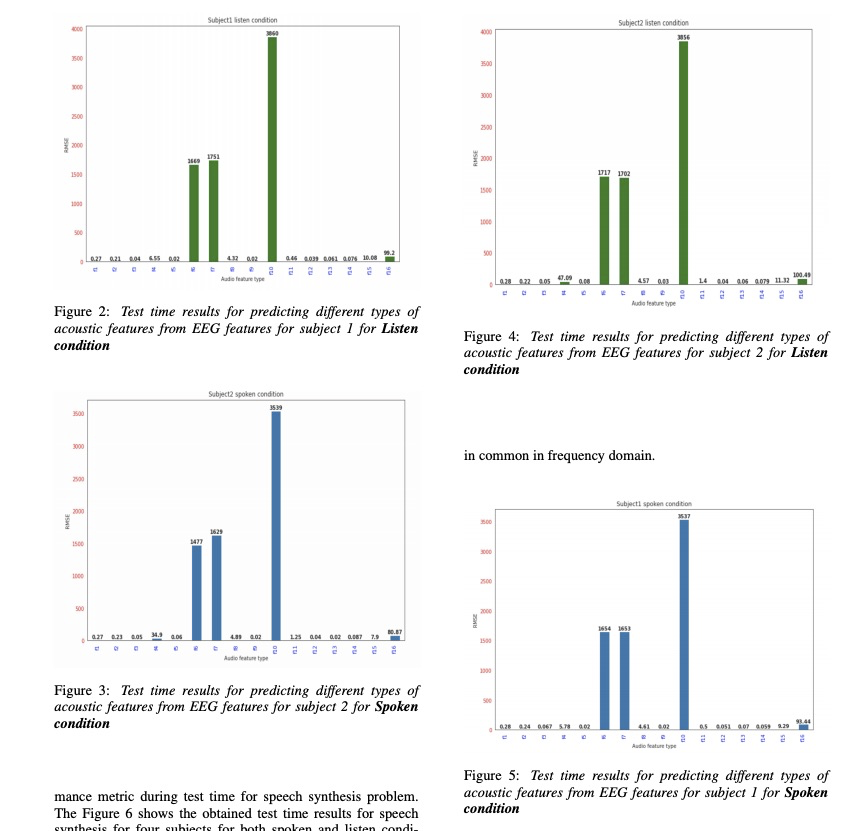
接下来看一下实验。本文实验主要包括4位参加者,其中set 1,set2 , set3的区别是EEG的维度分别为30, 50 和93。table1~4显示各测试结果,其中第1种方法比第2种方法低一些(作者说不是MCD越低就是合成音频越好,但本文章又说比以前的方案低多了。)table 5展示了MFCC 128为结果,图3图4展示语音重构的结果。
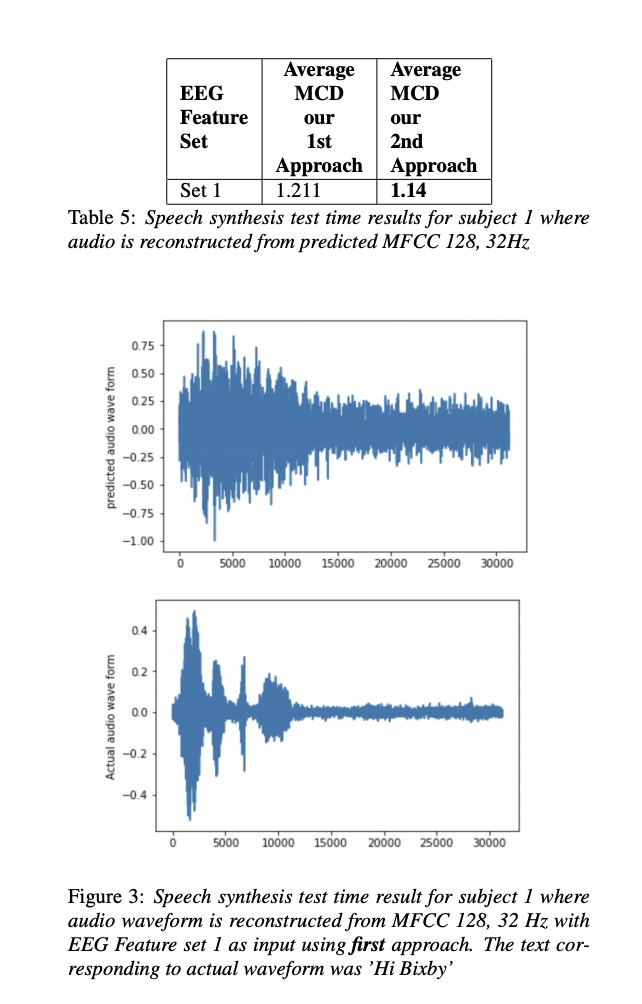
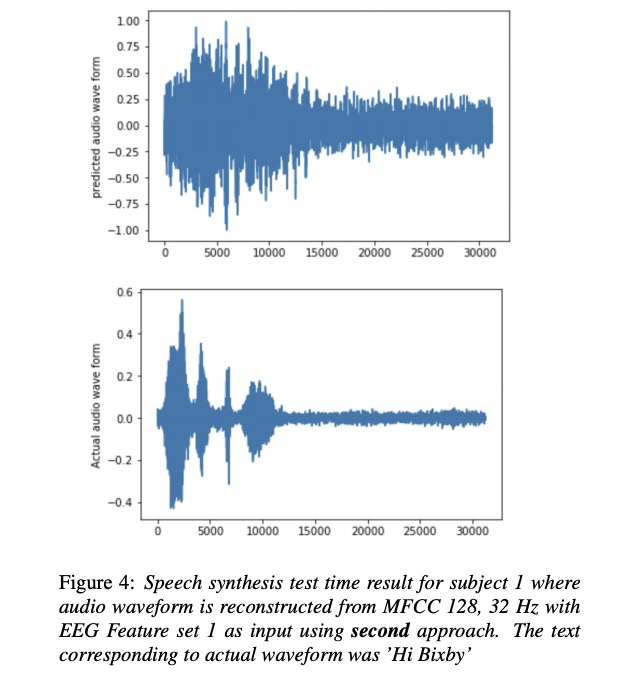
2.2 Speech Synthesis using EEG
-
Speech Synthesis using EEG这篇文章跟上一篇文章不同两个方面:1)只使用gru结构 2)使用EEG数据不仅采集说话人的EEG,也采集听者的EEG。
搞交叉研究领域使用的架构很简单,如图1所示,两层gru模型。其中脑电图的采集装备传感器的位置为图2所示。
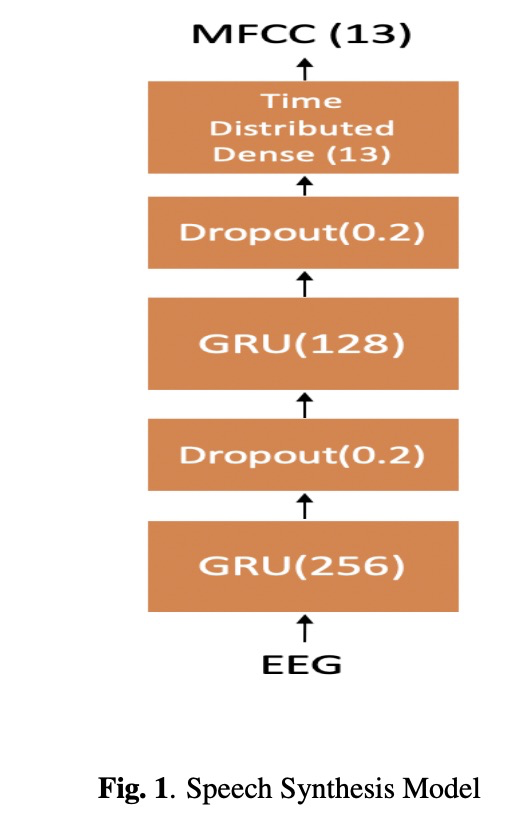
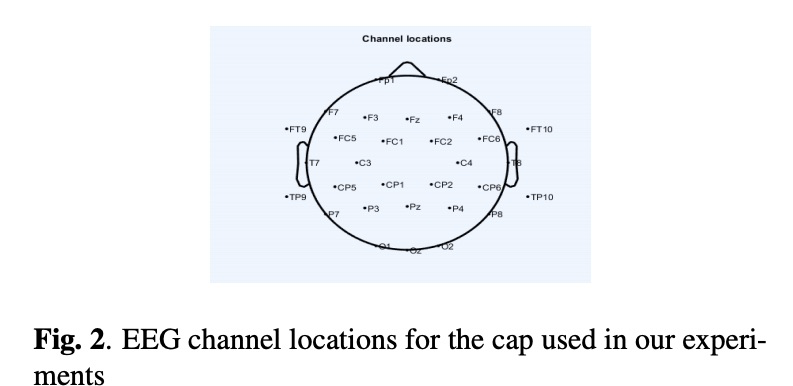
接下来看一下实验,本文的实验测试主要客观指标。
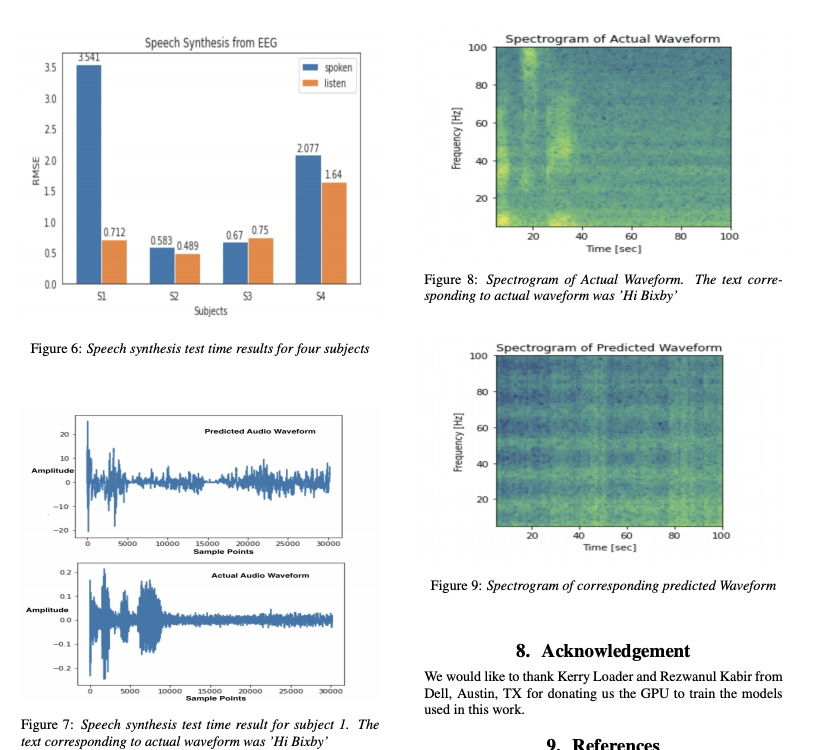
Predicting Different Acoustic Features from EEG and towards direct synthesis of Audio Waveform from EEG 本文与上边两篇文章主要不同就是不需要声码器,只用EEG预测波形。
本文的直接从EEG预测波形,从而省去声码器的使用。其结构如图1所示。
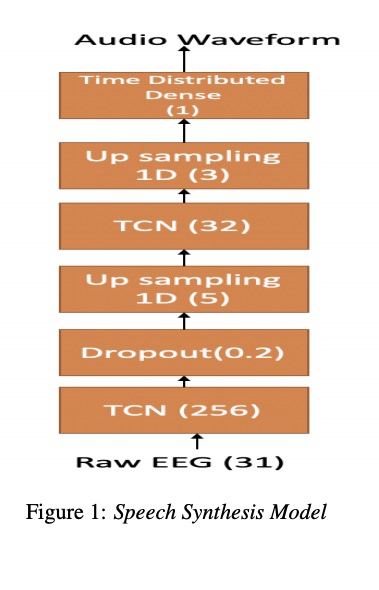
本文实验如下显示。主要比上边的两篇文章更接近可懂度高的语音。
3 总结
脑机接口的语音合成目前还处在学术阶段,还不能够生成可懂度较高的语音,不过还是期待EEG分析能够突破,这样会产生很多好玩的东西。
4 引用
[1] Krishna G, Tran C, Carnahan M, et al. Advancing speech synthesis using eeg[J]. arXiv preprint arXiv:2004.04731, 2020.
[2] Krishna G, Tran C, Han Y, et al. Speech synthesis using EEG[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 1235-1238.
[3] Krishna G, Tran C, Carnahan M, et al. Predicting Different Acoustic Features from EEG and towards direct synthesis of Audio Waveform from EEG[J]. arXiv preprint arXiv:2006.01262, 2020.
欢迎关注公众号:低调奋进