1 Flink简介
Flink是分布式、高性能、随时可用、准确的流处理框架。
Flink是一个一个框架、分布式处理引擎,用于对无界和有界数据流进行有状态计算。
1.1 Flink特点
①事件驱动型(Event-driven)
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新、或其他外部动作。比较典型的就是以Kafka为代表的消息队列就是事件驱动型应用。(Flink的计算也是事件驱动型)。
1.2 流处理VS批处理
批处理和流处理是根据处理方式划分的:
批处理特点:有界、持久、大量,一般用来离线统计。
流处理特点:无界、实时,一般用于实时统计。
SparkStreaming是微批次、准实时。
Flink是流处理、离线数据是有界的流,实时数据是无界的流。
无界流:有头无尾,比如socket
有界流:有头有尾,比如一个文件input/word.txt

1.3 分层API
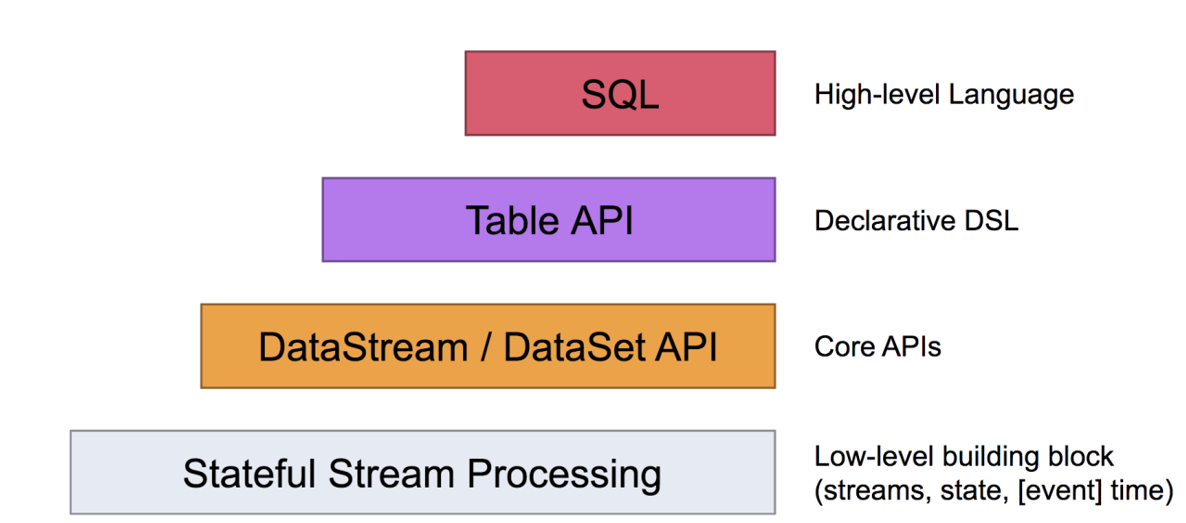
2 Flink快速上手
2.1 创建Maven项目
步骤1:导入pom依赖
声明为provided的依赖,在打包的时候并不会把依赖打进去。
IDEA运行会在本地启动一个迷你集群,如果都是provided这样会报一个找不到类的错误。需要IDEA的application配置provided scope。
<properties>
<flink.version>1.12.0</flink.version>
<java.version>1.8</java.version>
<scala.binary.version>2.11</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<!--flink基本依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!--flink的一个前端页面依赖,这样就不用启动集群,也能登录集群-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!--日志相关的依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
<!--打包插件,把引用的jar包也打进去-->
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
步骤2:在src/main/resources添加文件log4j.properties
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
步骤3:配置IDEA,运行时包括provided scope

2.2 批处理WordCount
①普通
方式1:使用Function
//1 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2 获取数据
DataSource<String> inputDS = env.readTextFile("input/word.txt");
//3 处理数据
//3.1 压平,切分成 word
FlatMapOperator<String, String> wordDS = inputDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
//切分
String[] words = value.split(" ");
for (String word : words) {
//通过采集器 将word往下游发送
out.collect(word);
}
}
});
//3.2转换成元组(word, 1)
MapOperator<String, Tuple2<String, Long>> wordAndOneDS = wordDS.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String value) throws Exception {
return Tuple2.of(value, 1L);
}
});
//3.3 根据word分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneGroup = wordAndOneDS.groupBy(0);
//3.4 组内聚合
AggregateOperator<Tuple2<String, Long>> resultDS = wordAndOneGroup.sum(1);
//4 输出
resultDS.print();
//5 执行
方式2:使用lambda表达式
//1 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2 加载数据
DataSource<String> inputDS = env.readTextFile("input/word.txt");
//3 处理数据
//3.1 扁平化,切分成word
FlatMapOperator<String, String> wordDS = inputDS.flatMap(
(String line, Collector<String> out) -> {
String[] words = line.split(" ");
for (String word : words) {
//通过采集器,将word往下游发送
out.collect(word);
}
}).returns(Types.STRING);
//3.2 转换结构为(word, 1)
MapOperator<String, Tuple2<String, Long>> wordToOneDS = wordDS
.map(value -> Tuple2.of(value, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
//3.3按照word进行分组
UnsortedGrouping<Tuple2<String, Long>> wordGroup = wordToOneDS.groupBy(0);
//3.4 分组内聚合
AggregateOperator<Tuple2<String, Long>> result = wordGroup.sum(1);
//4 输出结果
result.print();
//5 执行
②流批一体(flink1.12新特性)
//1 创建执行时环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//TODO 流式的执行环境下,指定为 批处理 模式
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
//2 加载数据
DataStreamSource<String> inputDS = env.readTextFile("input/word.txt");
//3 处理数据
SingleOutputStreamOperator<Tuple2<String, Long>> resultDS = inputDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(word);
}
}
})
.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String s) throws Exception {
return Tuple2.of(s, 1L);
}
})
.keyBy(0)
.sum(1);
//4 输出结果
resultDS.print();
//5 执行
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
2.3 流处理WordCount
①有界流处理
//1 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2 加载数据
DataStreamSource<String> inputDS = env.readTextFile("input/word.txt");
//3 处理数据
//3.1 扁平化,获得word
SingleOutputStreamOperator<String> wordDS = inputDS.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
//收集器,收集结果输出
collector.collect(word);
}
}
});
//3.2 转换结构(word, 1)
SingleOutputStreamOperator<Tuple2<String, Long>> wordToOneDS = wordDS.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String s) throws Exception {
return Tuple2.of(s, 1L);
}
});
//3.3 根据word分组
KeyedStream<Tuple2<String, Long>, Tuple> wordGroup = wordToOneDS.keyBy(0);
//3.4 分组内聚合
SingleOutputStreamOperator<Tuple2<String, Long>> resultDS = wordGroup.sum(1);
//4 输出结果
resultDS.print();
//5 执行
env.execute();
②无界流处理
//1 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2 获取数据
DataStreamSource<String> inputDS = env.socketTextStream("hadoop102", 9999);
//3 处理数据
//3.1 扁平化
SingleOutputStreamOperator<Tuple2<String, Long>> resultDS = inputDS
.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(word);
}
}
})
//3.2 转换结构(word, 1)
.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String s) throws Exception {
return Tuple2.of(s, 1L);
}
})
//3.3 根据word分组
.keyBy(0)
//3.4 分组内聚合
.sum(1);
//4 输出结构
resultDS.print();
//5 执行
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
2.4 批处理VS流处理 区别
(1)创建环境的类不同
(2)分组算子不同
(3)执行方式不同
(4)流批一体化,可以将流式环境下,指定为 批处理 模式
3 Flink部署
Flink的下载地址:https://flink.apache.org/downloads.html#apache-flink-1120
3.1 开发模式
咱们前面在idea中运行Flink程序的方式就是开发模式.
3.2 local-cluster模式
Flink的Local-Clluster(本地集群)模式,主要用于测试和学习。
①local-cluster模式配置
local-cluster基本属于零配置。
步骤1:上传Flink的安装包flink-1.12.0-bin-scala_2.11.tgz上传到hadoop102
步骤2:解压安装包到/opt/module
tar -zxvf flink-1.12.0-bin-scala_2.11.tgz -C /opt/module
步骤3:为了区分不同部署模式,修改文件名
cd /opt/module
cp -r flink-1.12.0 flink-local
②Web提交任务
在local-cluster模式下运行unbounded-stream-wordcount
步骤1:打包IDEA中的应用
步骤2:启动local-cluster本地集群
bin/start-cluster.sh
步骤3:在hadoop102的另一个会话中启动netcat
nc -lk 9999
如果没有安装netcat需要先安装:sudo yum install -y nc
步骤4:启动Web页面hadoop102:8081
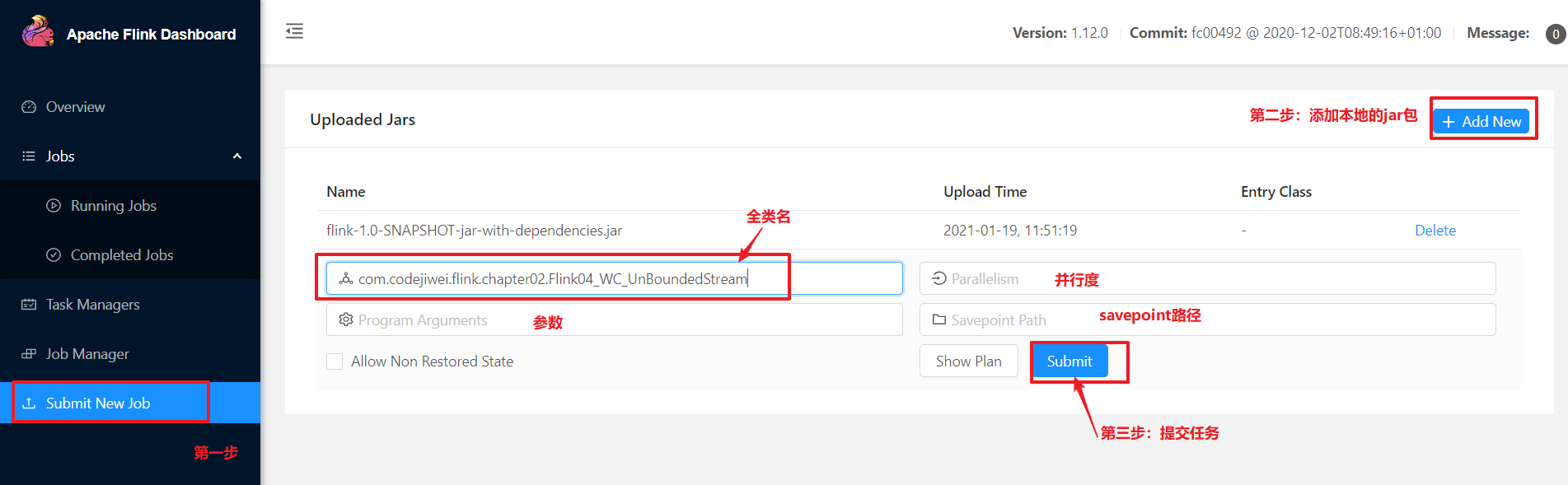
步骤5:netstat输入数据

步骤6:查看web端结果
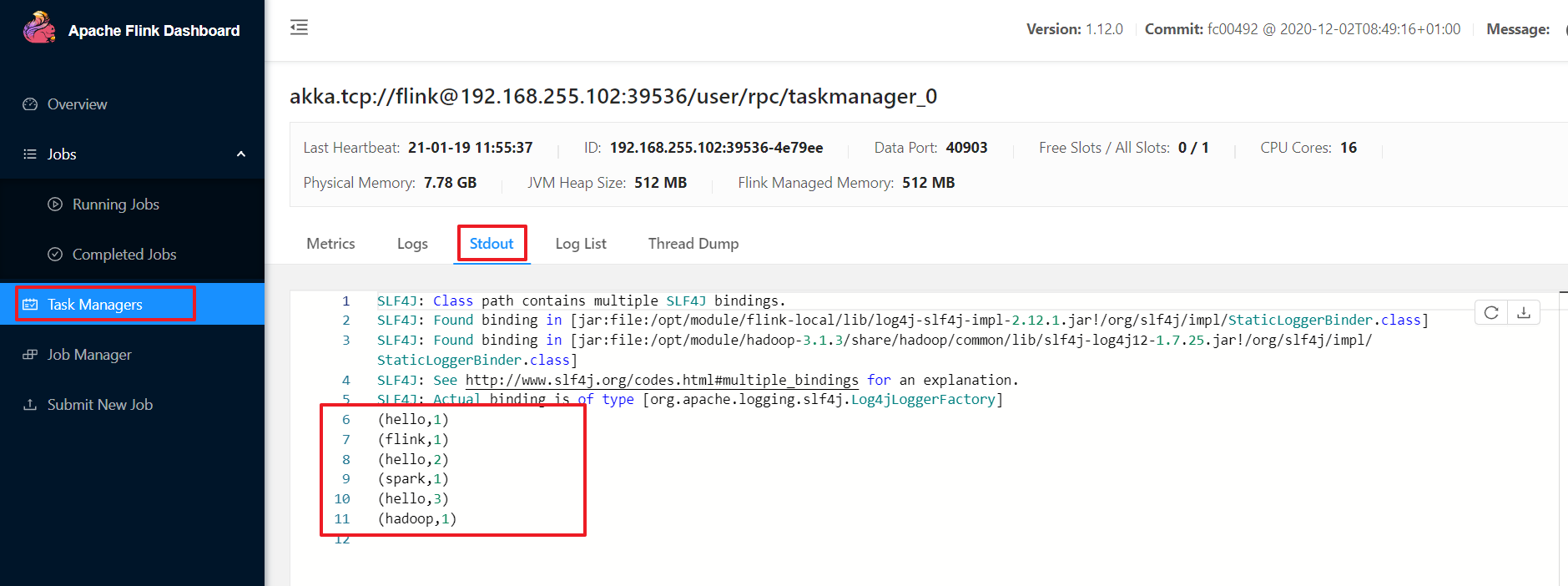
步骤7:杀死运行的任务
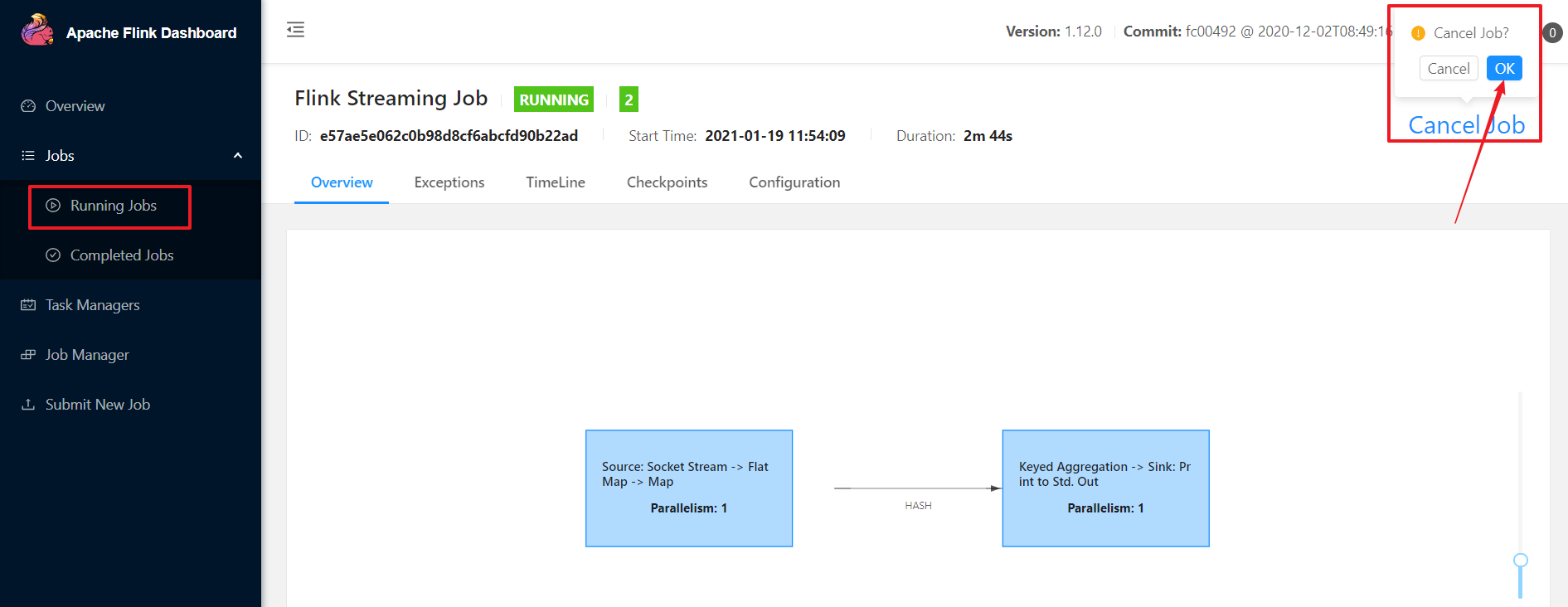
步骤8:关闭local-cluster集群
[atguigu@hadoop102 flink-local]$ bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 2263) on host hadoop102.
Stopping standalonesession daemon (pid: 1963) on host hadoop102.
③命令行提交任务
步骤1:将IDEA打包的jar包上传到/opt/module/flink_data/路径下
步骤2:启动local-cluster集群
[atguigu@hadoop102 flink-local]$ bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop102.
步骤3:在hadoop102的另一个会话窗口开启netcat
[atguigu@hadoop102 ~]$ nc -lk 9999
步骤4:命令行提交Flink命令
[atguigu@hadoop102 flink-local]$ bin/flink run -m hadoop102:8081 -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar

步骤5:netcat中输入数据,查看web页面
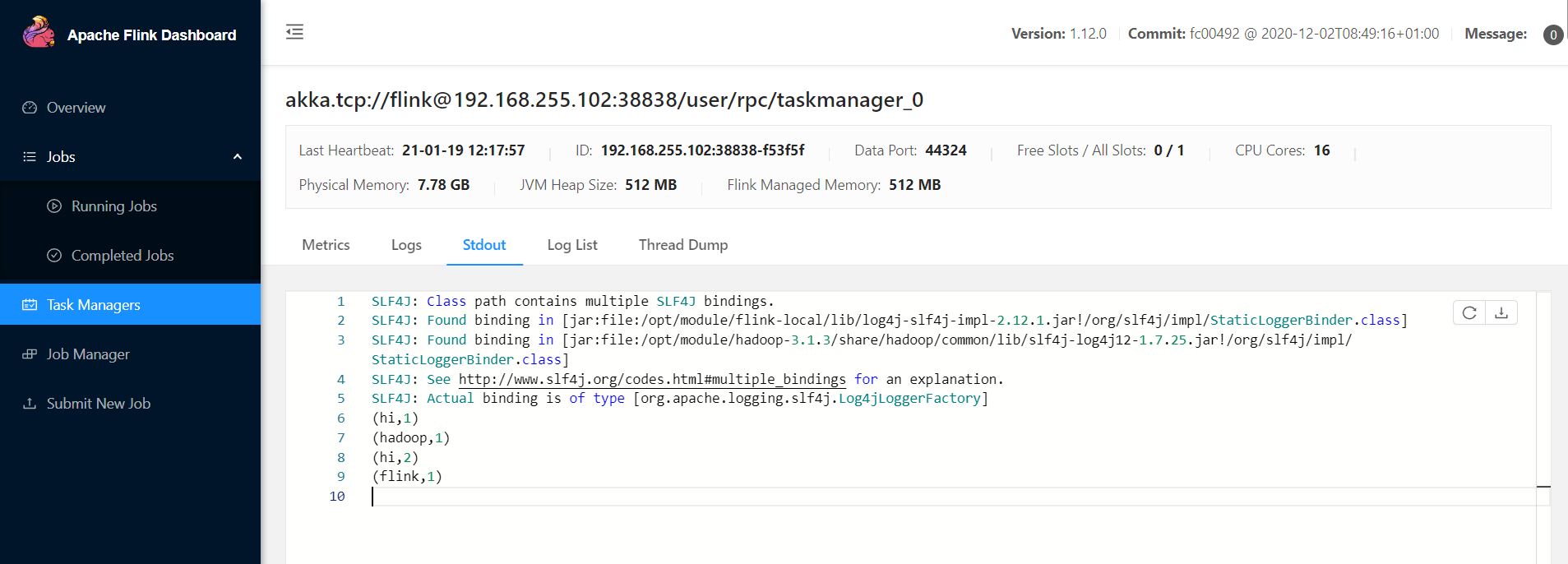
3.3 standalone模式
standalone模式又叫独立部署模式,flink由自身去管理调度资源。
①standalone模式配置
步骤1:复制flink-standalone
cp -r flink-1.12.0 flink-standalone
步骤2:修改配置文件:flink-conf.yaml
jobmanager.rpc.address: hadoop102
步骤3:修改配置文件:workers
standalone模式是集群模式,需要指定wokers是谁
hadoop102
hadoop103
步骤4:分发flink-standalone到集群
xsync /opt/module/flink-standalone
②standalone模式提交任务
standalone模式运行unbounded-stream-wordcount
步骤1:启动standalone集群
[atguigu@hadoop102 flink-standalone]$ bin/start-cluster.sh
步骤2:命令行提交flink应用
bin/flink run -m hadoop102:8081 -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar
-m是指定JobManager的地址去连接。

步骤3:查看结果
步骤4:也支持Web端UI提交Flink应用
③standalone模式高可用(HA)
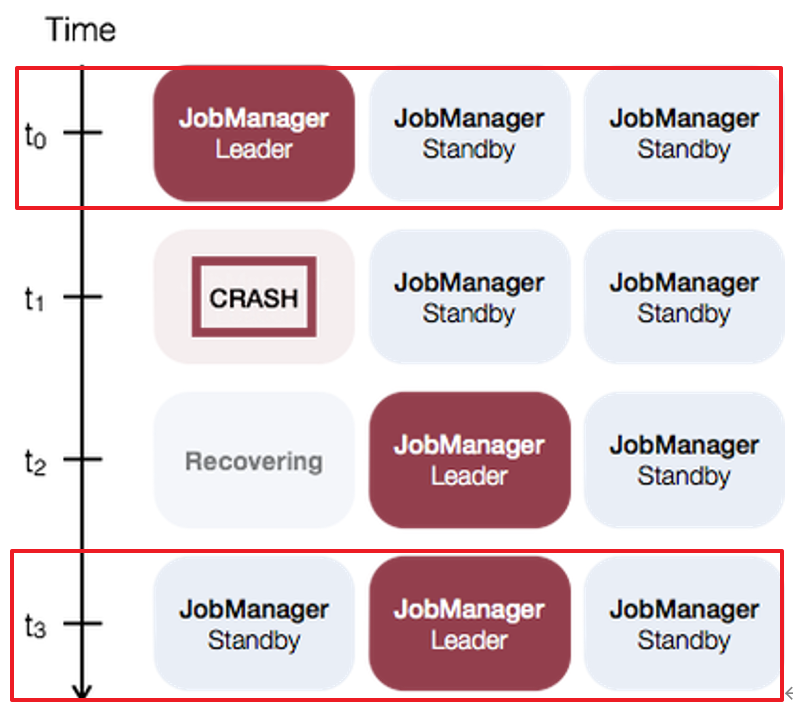
Flink的高可用是依赖于zookeeper的。
并且需要一个可以所有节点访问的持久化的文件系统,所以依赖于HDFS。
步骤1:修改配置文件flink-conf.yaml
high-availability: zookeeper:不开启高可用,默认就是NONE;开启高可用就是zookeeper
high-availability.storageDir:保存zk恢复元数据的路径。
high-availability.zookeeper.quorum: zookeeper的集群地址。
high-availability.zookeeper.path.root:zookeeper的文件在HDFS上的名称。
high-availability.cluster-id:高可用集群ID
high-availability: zookeeper
high-availability.storageDir: hdfs://hadoop162:9000/flink/standalone/ha
high-availability.zookeeper.quorum: hadoop162:2181,hadoop163:2181,hadoop164:2181
high-availability.zookeeper.path.root: /flink-standalone
high-availability.cluster-id: /cluster_atguigu
步骤2:修改配置文件:master
hadoop162:8081
hadoop163:8081
步骤3:分发修改后的配置文件到其他节点
xsync flink-conf.yaml
xsync master
步骤4:在/etc/profile.d/my_env.sh环境变量
运行flink需要用到Hadoop的依赖环境等
Flink1.11版本之前,都是将hadoop的jar包放在flink的lib目录下
Flink1.11版本之后,可以通过环境变量,让flink根据环境变量自己去找所需的hadoopjar包
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
步骤5:分发环境变量到其他节点,然后在各个节点source
sudo xsync /etc/profile.d/my_env.sh
[atguigu@hadoop102 flink-standalone]$ source /etc/profile.d/my_env.sh
[atguigu@hadoop103 flink-standalone]$ source /etc/profile.d/my_env.sh
[atguigu@hadoop104 flink-standalone]$ source /etc/profile.d/my_env.sh
④standalone模式启动
步骤1:启动dfs集群、zookeeper集群
start-dfs.sh
myzk.sh start
步骤2:启动standalone模式集群
bin/start-cluster.sh
步骤3:可以访问Web页面
http://hadoop102:8081/
http://hadoop103:8081/
可以看到两个Web页面一样的,那么哪个节点是leader节点呢?
登录到zookeeper的客户端查看leader
zkCli.sh
get /flink-standalone/cluster_atguigu/leader/rest_server_lock

3.4 yarn模式
独立部署模式Standalone模式由flink自身提供计算资源、资源调度。flink主要是计算框架,而不是资源调度框架,所以一般使用yarn去进行资源调度。
把Flink的应用提交给Yarn的ResourceManager,Yarn的ResourceManager会申请容器,在Yarn的NodeManager上面创建JobManager、TaskManager。Flink会根据JobManager上的Job所需要的slot数量,动态的分配TaskManager资源。
①yarn模式配置
步骤1:复制flink-yarn
cp -r flink-1.12.0 flink-yarn
步骤2:配置环境变量HADOOP_CLASSPATH,如果前面已经配置可以忽略。
# 修改/etc/profile.d/my_env.sh
export HADOOP_CLASSPATH=`hadoop classpath`
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
②Yarn运行unbounded-stream-wordcount
yarn模式启动集群,运行flink应用,不需要启动,但是依赖HDFS、YARN。需要指定yarn模式
因为在配置的时候指定了环境变量HADOOP_CLASSPATH和HADOOP_CONF_DIR,Flink会自动去读取yarn-site、yarn-site、core.site等等集群信息,让yarn去调度资源。
步骤1:启动HDFS、Yarn
[atguigu@hadoop102 ~]$ start-dfs.sh
[atguigu@hadoop103 ~]$ start-yarn.sh
步骤2:运行无界流
[atguigu@hadoop102 flink-yarn]$ bin/flink run -t yarn-per-job -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar

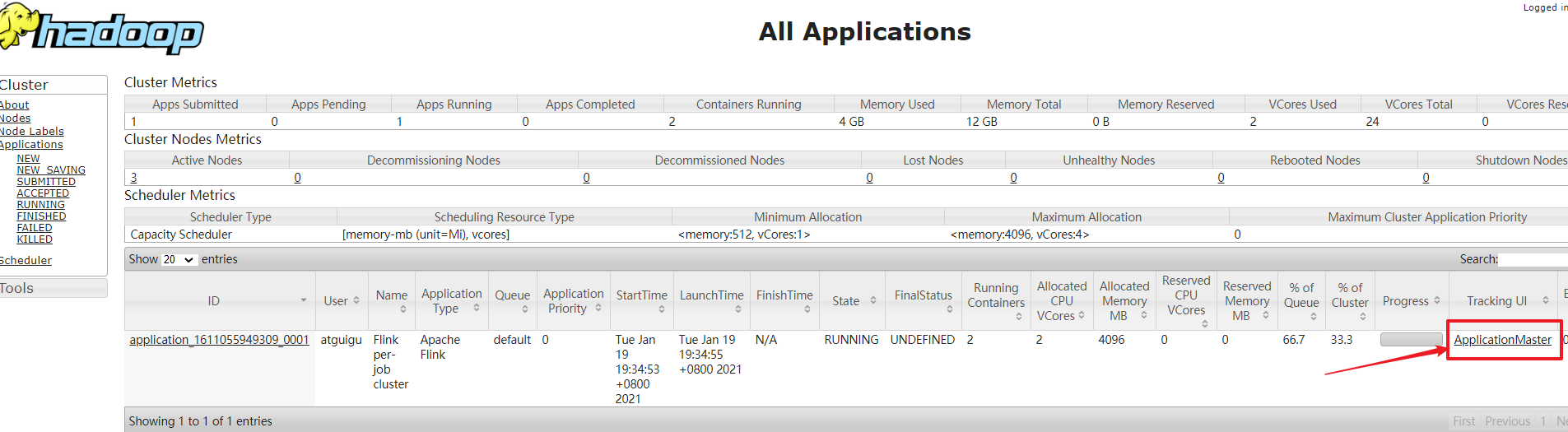
可以通过上面的地址登录web页面,但是这个地址是变化的。所以使用yarn的resourceManager界面查看执行情况。
步骤3:在yarn的resourceManager查看Flink执行情况
③per-job-cluster模式
单作业模式,每提交一次,yarn都会启动一个独立使用的flink集群,并且是每个job独立跑一个集群。
适合规模大、长时间运行的作业。
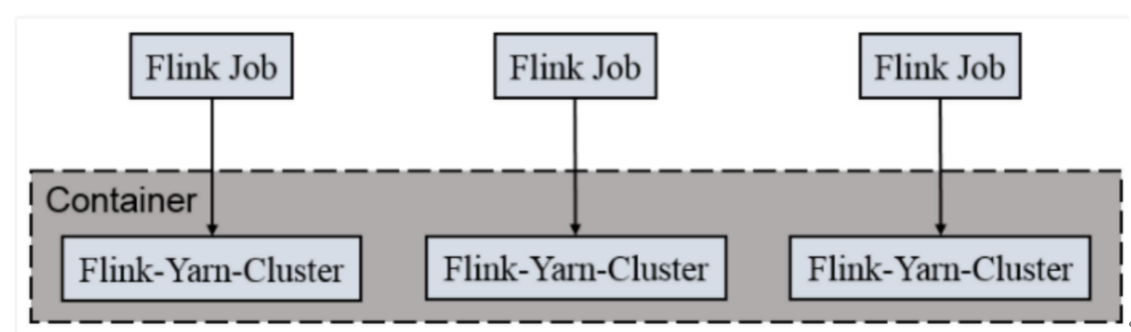
任务执行过程
步骤1:直接运行
[atguigu@hadoop102 flink-yarn]$ bin/flink run -t yarn-per-job -d -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar
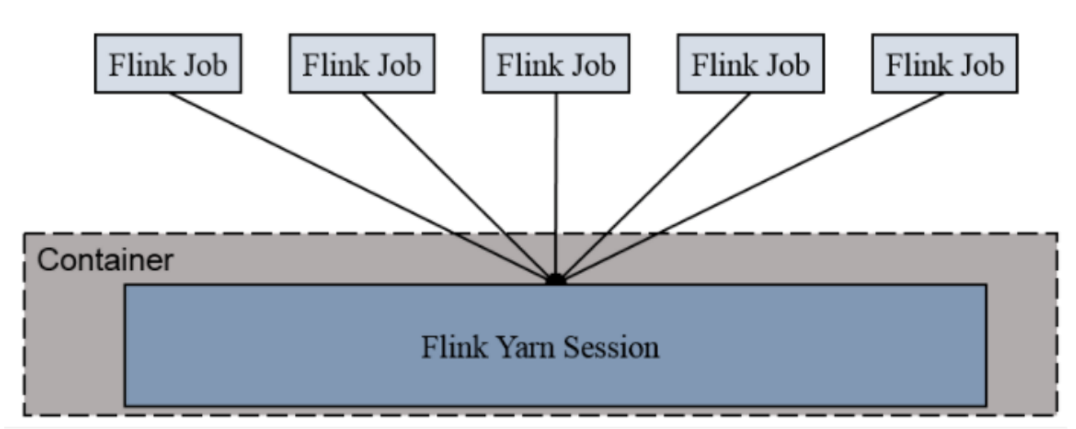
④session-cluster模式
Session-Cluster模式需要先启动Flink集群,向Yarn申请资源,申请到资源后Container保持不变。FlinkJob提交都向这个Container提交,这个Flink集群会常驻在Yarn集群中,除非手动停止。
共享集群,job都提交到一个共享的集群中。
适合那些需频繁提交的多个小Job,并且执行时间不长的Job。但是如果提交的Job如果有长时间执行的大作业,占用了Flink集群的所有资源,则后续无法提交新的Job。
任务执行过程
步骤1:启动一个Flink-Session
[atguigu@hadoop102 flink-yarn]$ bin/yarn-session.sh -d
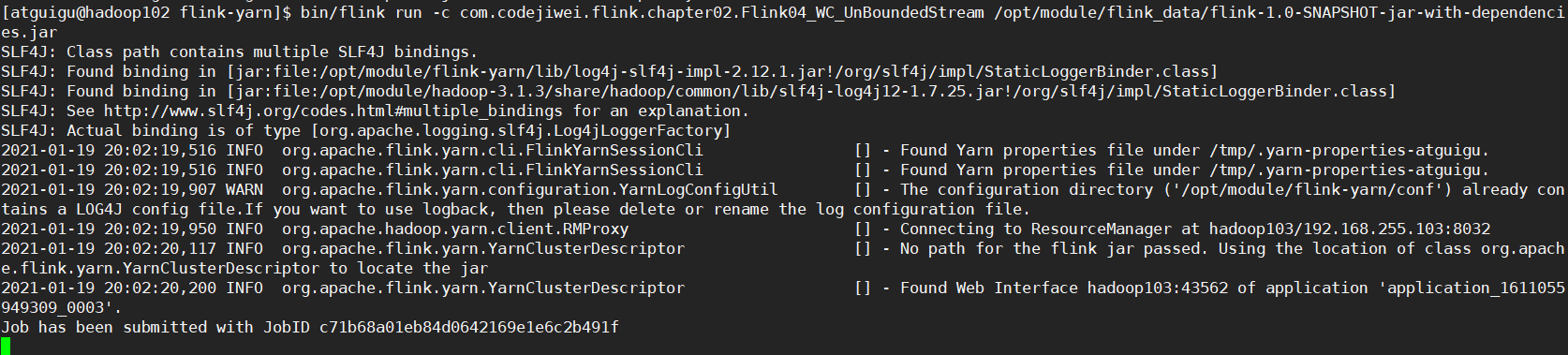
步骤2:在Session上运行Job
[atguigu@hadoop102 flink-yarn]$ bin/flink run -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar
步骤3:指定运行在yarn-session集群
会自动找到yarn-session启动的集群,也可以手动指定的yarn-session集群:
- -t yarn-session,指定为yarn-session模式。
- Dyarn.application.id=application_XXXX_YY 指的是在yarn上启动的yarn应用。
bin/flink run -t yarn-session -Dyarn.application.id=application_XXXX_YY ./flink-prepare-1.0-SNAPSHOT.jar

[atguigu@hadoop102 flink-yarn]$ bin/flink run -t yarn-session -Dyarn.application.id=application_1611055949309_0003 -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar
步骤4:如何杀死这个flink集群?
⑤application mode模式
1.11版本出现。
ApplicationMode会在Yarn上启动集群。
与Per-Job-Cluster的区别: 就是Application Mode下, 用户的main函数式在集群中执行的
出于生产的需求, 我们建议使用Per-job or Application Mode,因为他们给应用提供了更好的隔离!
任务执行过程
步骤1:
[atguigu@hadoop102 flink-yarn]$ bin/flink run-application -t yarn-application -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar

3.5 yarn模式高可用
yarn的高可用模式和standalone的高可用模式原理的对比:
standalone模式高可用:依赖zookeeper和HDFS文件系统。
同时启动多个JobManager,其中一个为leader,其他的是standby的,当leader挂了,其他的才有机会称为leader。
yarn模式高可用:利用yarn的重试机制
yarn的高可用是同时只有一个JobManager
注意:flink的yarn模式高可用注意点
-
flink的yarn模式高可用依赖yarn的重试拉取机制,需要配置yarn的拉取次数
-
只要配置高可用就要配置zookeeper
-
flink里面也需要设置重试次数
-
flink中的重试次数<= yarn中的重试次数,其中以flink的重试次数为准。
-
flink的yarn模式高可用,一定不能指定cluster-id。因为yarn模式的集群id是resourcemanager分配的
-
yarn模式配置完高可用之后,不用分发配置。因为yarn模式只需要一个客户端入口即可
-
yarn高可用模式不用改master。因为有yarn启动JobManager在哪台节点上不确定
-
拉取的次数大于3和4次的原因是:拉取是在一定的时间间隔之内。
也就是说挂掉了10分钟之内起来,那就没事,如果10分钟以后还没起来,那么会去重试拉取3次。
步骤1:在yarn-site.xml中配置重试的次数(默认次数=2)
[atguigu@hadoop102 flink-yarn]$ cd /opt/module/hadoop-3.1.3/etc/hadoop/
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml
<!-- 设置flink高可用的yarn重试次数 -->
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximum number of application master execution attempts.
</description>
</property>
# 分发配置文件到集群
xsync yarn-site.xml
# 重启yarn
yarn-stop.sh
yarn-start.sh
步骤2:在flink-conf.yaml中配置重试的次数(默认次数=2)
yarn.application-attempts: 3
high-availability: zookeeper
high-availability.storageDir: hdfs://hadoop162:8020/flink/yarn/ha
high-availability.zookeeper.quorum: hadoop162:2181,hadoop163:2181,hadoop164:2181
high-availability.zookeeper.path.root: /flink-yarn
步骤3:启动hdfs、yarn、zookeeper、执行flink命令
步骤4:杀死JobManager,查看它的复活次数
Tip1 yarn的容器由3 --> 2
这是因为杀死了一个JobManager,这个时候又会拉起一个JobManager,此时集群中还有一个TaskManager。所以集群的容器时3;
过了一会杀死的JobManager上会被清理掉。这个时候集群的容器就是2了。

3.6 Flink命令说明
①提交命令 ,指定队列(1.12版本)
bin/flink run -t yarn-per-job -D参数名=参数值
bin/flink run-application -t yarn-application -Dyarn.application.queue=hive
1. flink命令,后面可以跟上一些动作: run、 run-application、 list、 stop、 cancel等
2. run动作
1) Generic Cli模式:
-t (如:yarn-per-job)
-D参数名=参数值
①指定为session-cluster模式
-Dyarn.application.id=application_XXXX_YY(resourcemanager上的应用id)
②指定yarn队列
-Dyarn.application.queue=队列名
2) yarn cluster模式:(其实就是yarn-per-job的老版本的写法)
-m yarn-cluster
指定yarn队列为例:
-yqu 指定yarn队列
3) default模式:(比如说standalone模式)
-m 指定JobManager(地址:web端口)=> hadoop102:8081
3. run-application动作(Application模式)
-t (如:yarn-application)
指定参数,也是使用 -D参数名=参数值
-Dyarn.application.queue=队列名
②测试
yarn-per-job模式的flink指定队列为hive队列
[atguigu@hadoop102 flink-yarn]$ bin/flink run -t yarn-per-job -Dyarn.application.queue=hive -d -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar
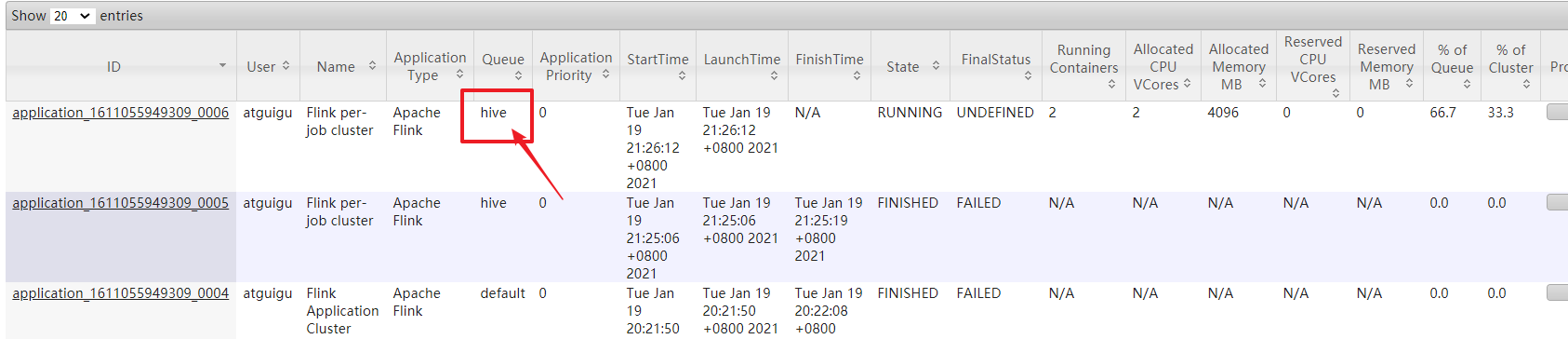
yarn-application模式的flink指定队列
[atguigu@hadoop102 flink-yarn]$ bin/flink run-application -t yarn-application -d -Dyarn.application.queue=hive -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar
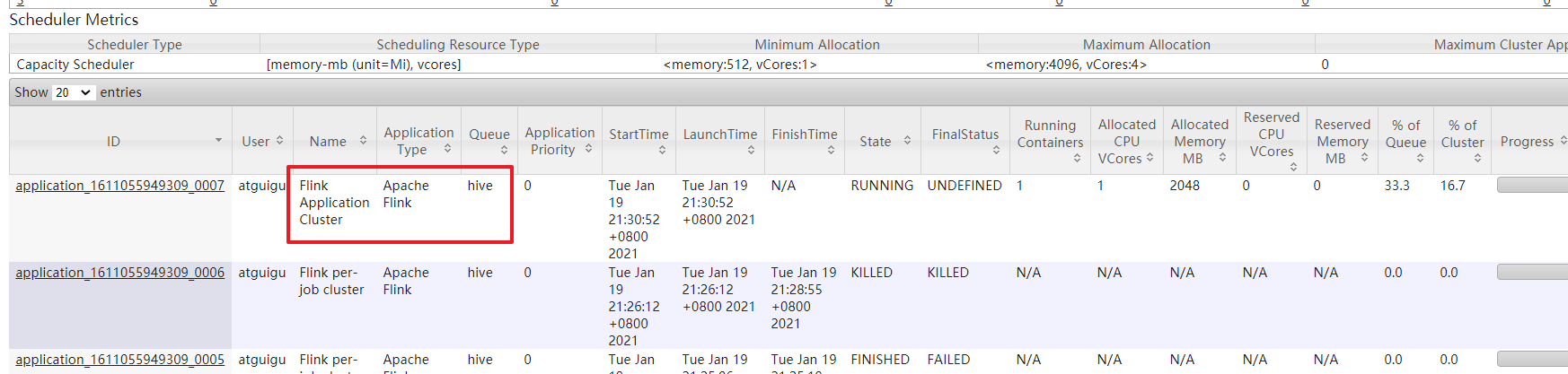
yarn-session-cluster模式的flink指定队列(好像并不能指定)
# 先创建一个session集群
[atguigu@hadoop102 flink-yarn]$ bin/yarn-session.sh -d
# 运行应用
[atguigu@hadoop102 flink-yarn]$ bin/flink run -t yarn-session -Dyarn.application.id=application_1611055949309_0009 -Dyarn.application.queue=hive -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar
3.7 Scala REPL
scala的交互式环境
①local模式启动scala REPL
[atguigu@hadoop102 flink-local]$ bin/start-scala-shell.sh local
scala> senv.socketTextStream("hadoop102", 9999).flatMap(_.split(" ")).map(t=>(t,1)).keyBy(0).sum(1).print
scala> senv.execute
这个时候会阻塞在这边,在hadoop102的另一个会话的netcat中输入数据,会统计单词数量
②yarn模式的启动scala REPL
[atguigu@hadoop102 flink-yarn]$ bin/start-scala-shell.sh yarn
3.8 K8S & Mesos模式
4 Flink运行架构
Flink运行时包含2种进程:JobManager和至少一个TaskManager
https://ci.apache.org/projects/flink/flink-docs-release-1.11/fig/processes.svg
4.1 核心概念
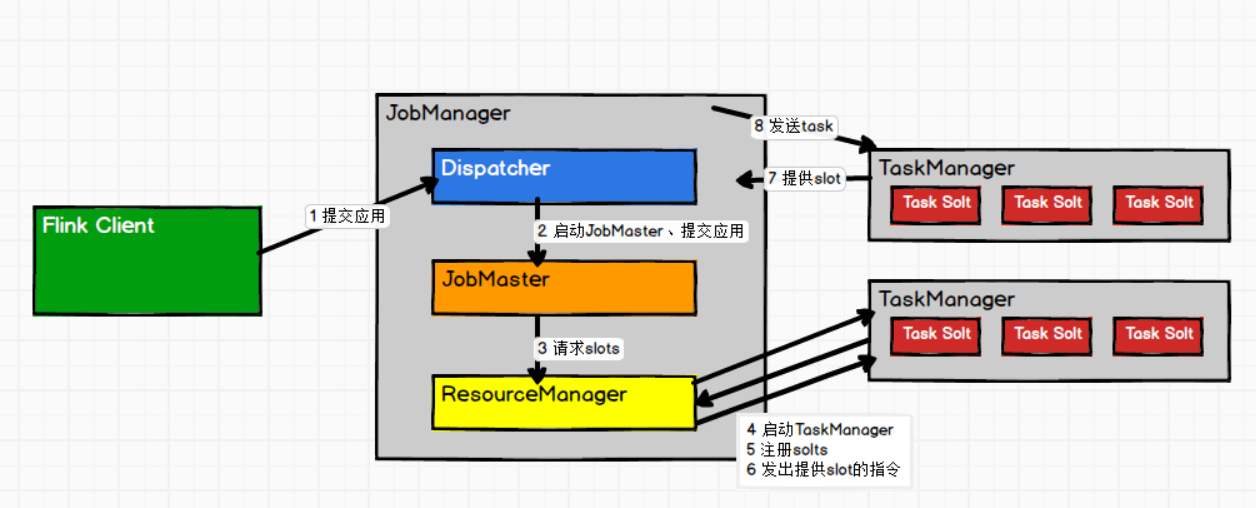
(1)客户端
- 客户端并不是运行和程序执行的一部分,而是准备和发送dataflow到 JobManager,然后客户端可以断开与JobManager的连接(detached mode),也可以继续保持与JobManager的连接(attached mode)
客户端作为触发执行的java或者scala代码的一部分运行, 也可以在命令行运行:bin/flink run …
-
Client解析代码生成逻辑流图(StreamGraph)
-
将StreamGraph优化成作业图(JobGraph),(优化操作链)然后传给JobManager。(Web页面看到的作业图)
(2)JobManager
-
控制一个应用程序的主进程(一个应用程序都会被一个不同的JobManager所控制执行)
-
JobManager会接收到Client端传来应用程序。包括:
- Client端传来的:逻辑数据流图、作业图(JobGraph)、打包的所有类、库、和其他资源的jar包
-
JobManager会把JobGraph转换成物理层面上的执行图(ExecutionGraph),包含了所有可以并行执行的任务。
-
JobManager会向资源管理器(ResourceManager)请求执行任务必要的资源(Solt);然后启动TaskManager(默认是1个Solt);然后会注册solts个数;一旦资源足够,就会将执行图发送给TaskManager
JobManager负责Flink内部资源的管理。
JobManager分为:ResourceManager、Dispatcher、JobMaster三个组件
①Dispatcher
接收用户提供的作业;启动一个新的JobMaster
②JobMaster
JobMaster负责管理单个JobGraph的执行。多个Job可以同时运行在一个Flink集群中,每个Job都有一个自己的 JobMaster。
③ResourceManager
负责flink资源的管理,在整个Flink集群中只有一个ResourceManager。
需要区别于Yarn的ResourceManager,是Flink中内置的。重名
主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger插槽是Flink中定义的处理资源单元。
当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。另外,ResourceManager还负责终止空闲的TaskManager,释放计算资源。
(3)TaskManager
Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(solts)。插槽的数量限制了TaskManager能够执行的任务数量。
启动TaskManager之后,TaskManager会向资源管理器注册它的槽,ResourceManager收到注册信息后向TaskManager发送提供solt指令,然后会给JobManager提供solt,最后JobManager会将Task发送到solt。
(4)槽(solt)和任务task的关系?
① Solt是可以共享的,Job内部共享
理想情况:一个槽执行一个Task。
一般情况:一个Job,并行度为1,有5个Task,有2个槽。那么槽就会共享,因为task有先后顺序。
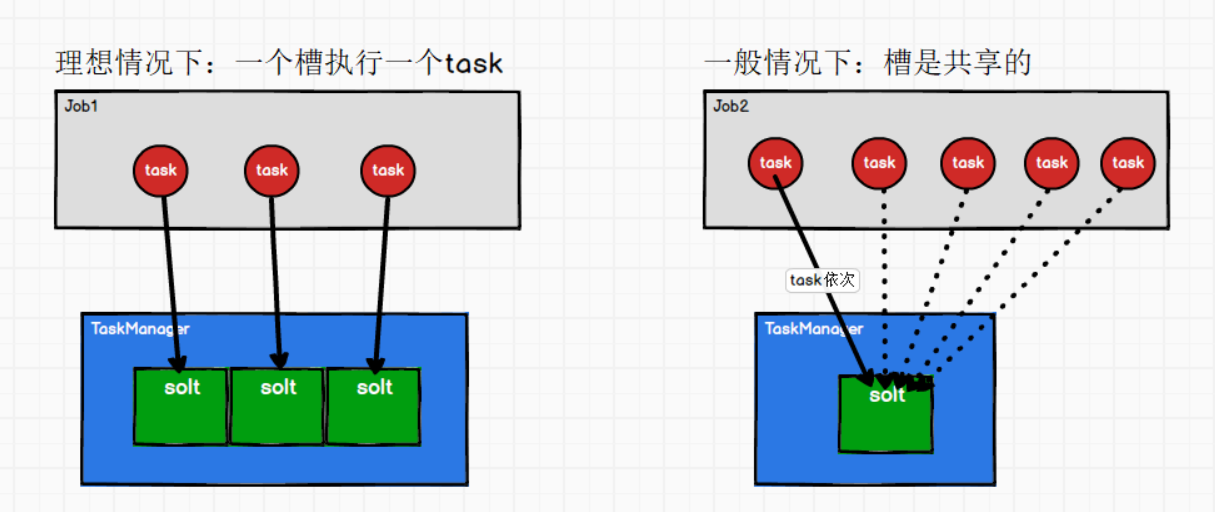
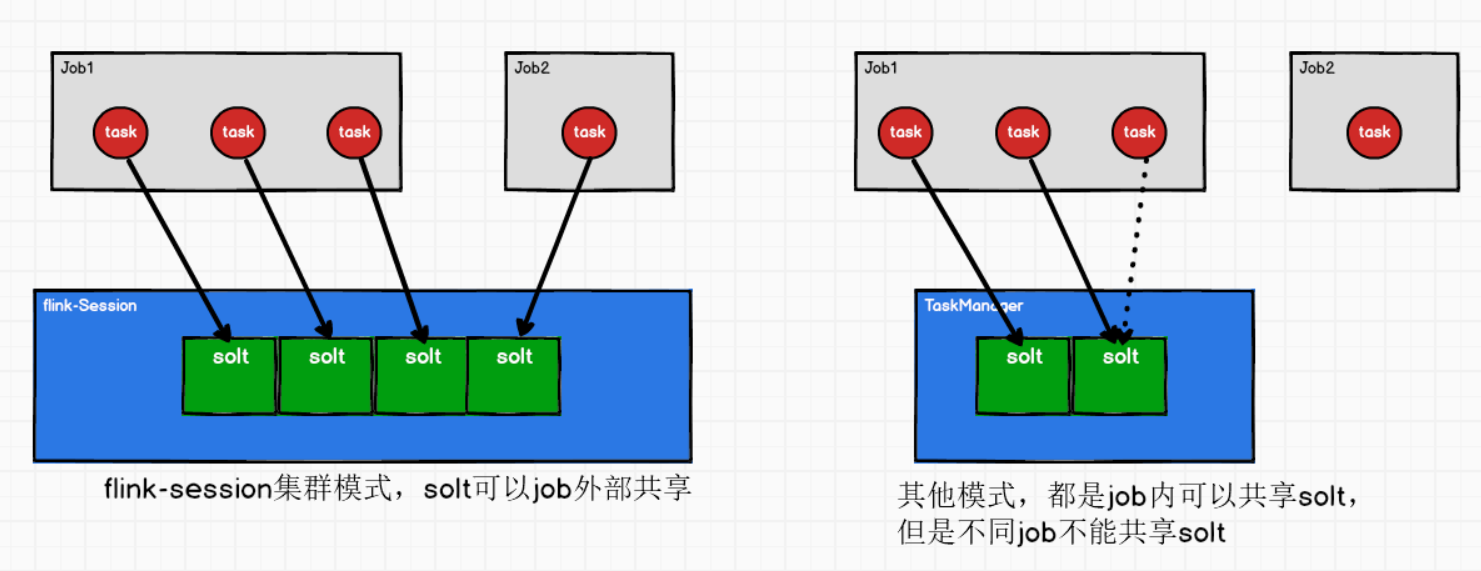
② 只有yarn-session模式,solt可以Job外部共享
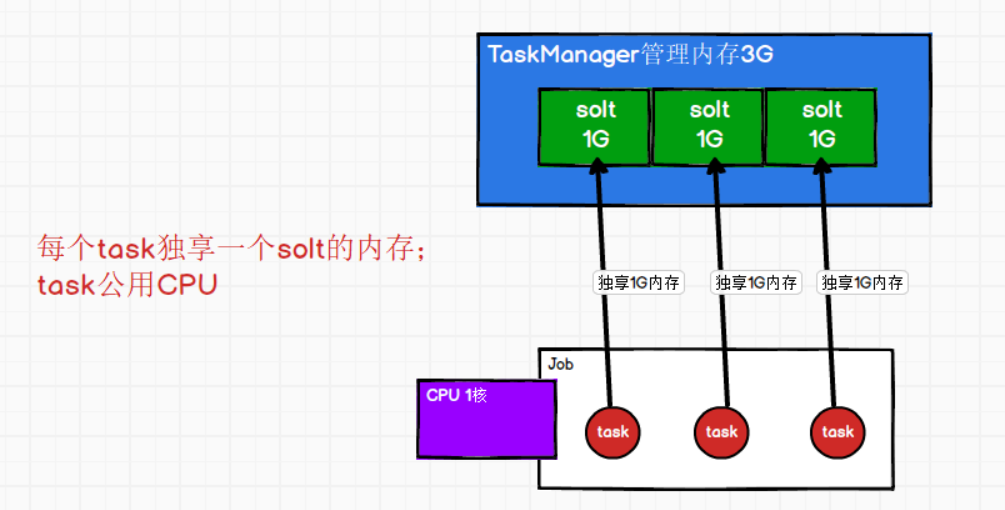
③ 每个solt的内存是均分TaskManager的管理内存;每个task独享一个solt内存
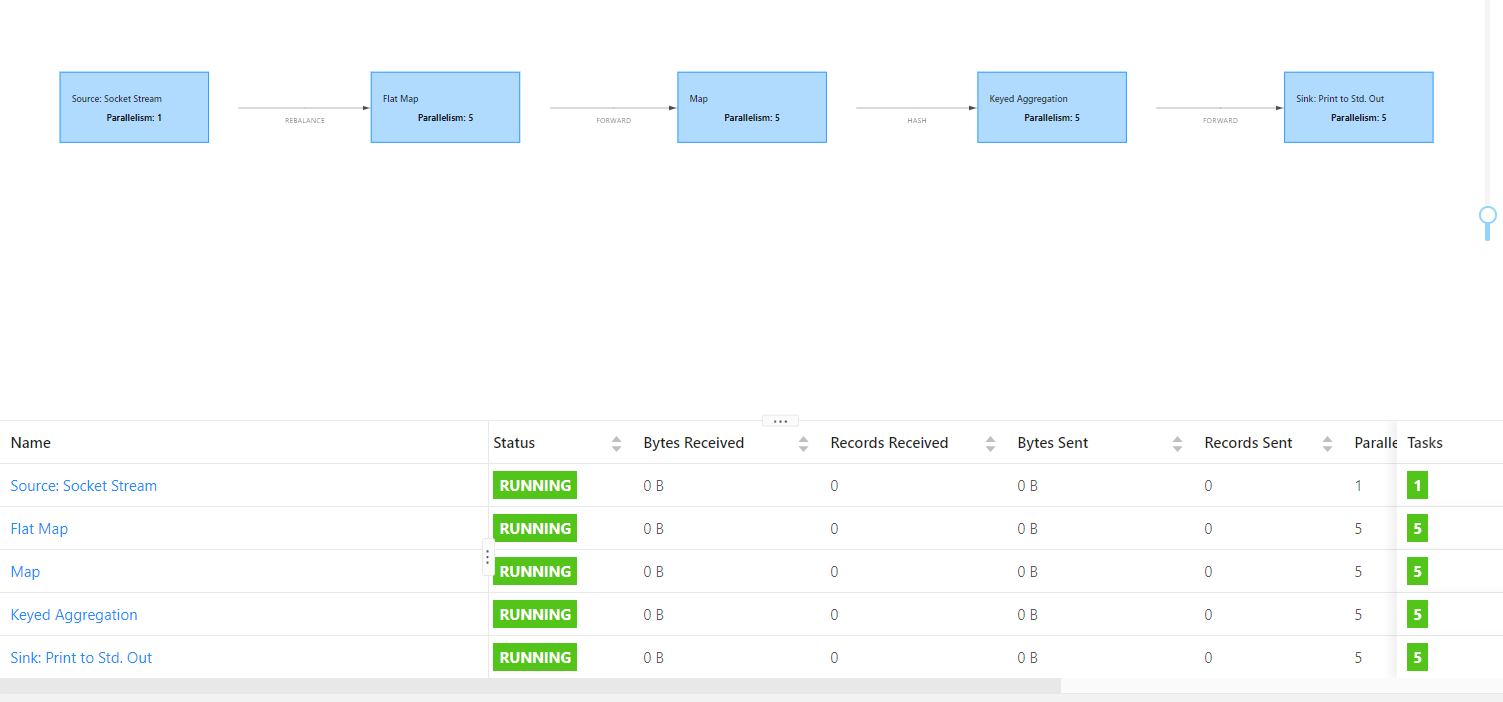
(5)一个Job会有多少个Task、需要多少个solt?
每个应用程序Job需要几个solts呢?
一个task就占用一个solt,也就是说每个Job会产生多少task呢?
Task个数 = 蓝框个个数 * 每个框的并行度
(6)每个TaskManager有多少个槽(solt)呢?
flink中每个TaskManager都是一个JVM进程,TaskManager通过solt来控制能够接收多少个Task
默认每个TaskManager有一个solt,在配置文件flink-conf.yaml修改默认槽的个数
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline. taskmanager.numberOfTaskSlots: 1命令参数方式指定槽的个数:
bin/flink run -t yarn-per-job -d -Dtaskmanager.numberOfTaskSlots=3 -c 全类名 路径
(7)Parallelism(并行度)
① 什么是并行度?
同时运行的任务(task)数量。(动态的一个概念)
如果有4个solts,有3个task同时运行,那么并行度就是3。
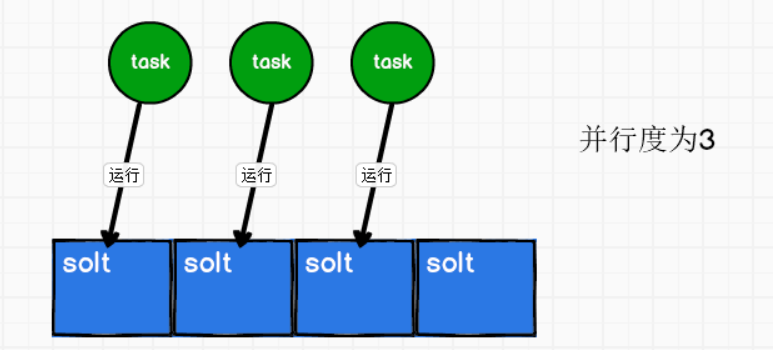
② 算子的并行度
一个特定算子的子任务(subtask)的个数,称为这个算子的并行度(parallelism)
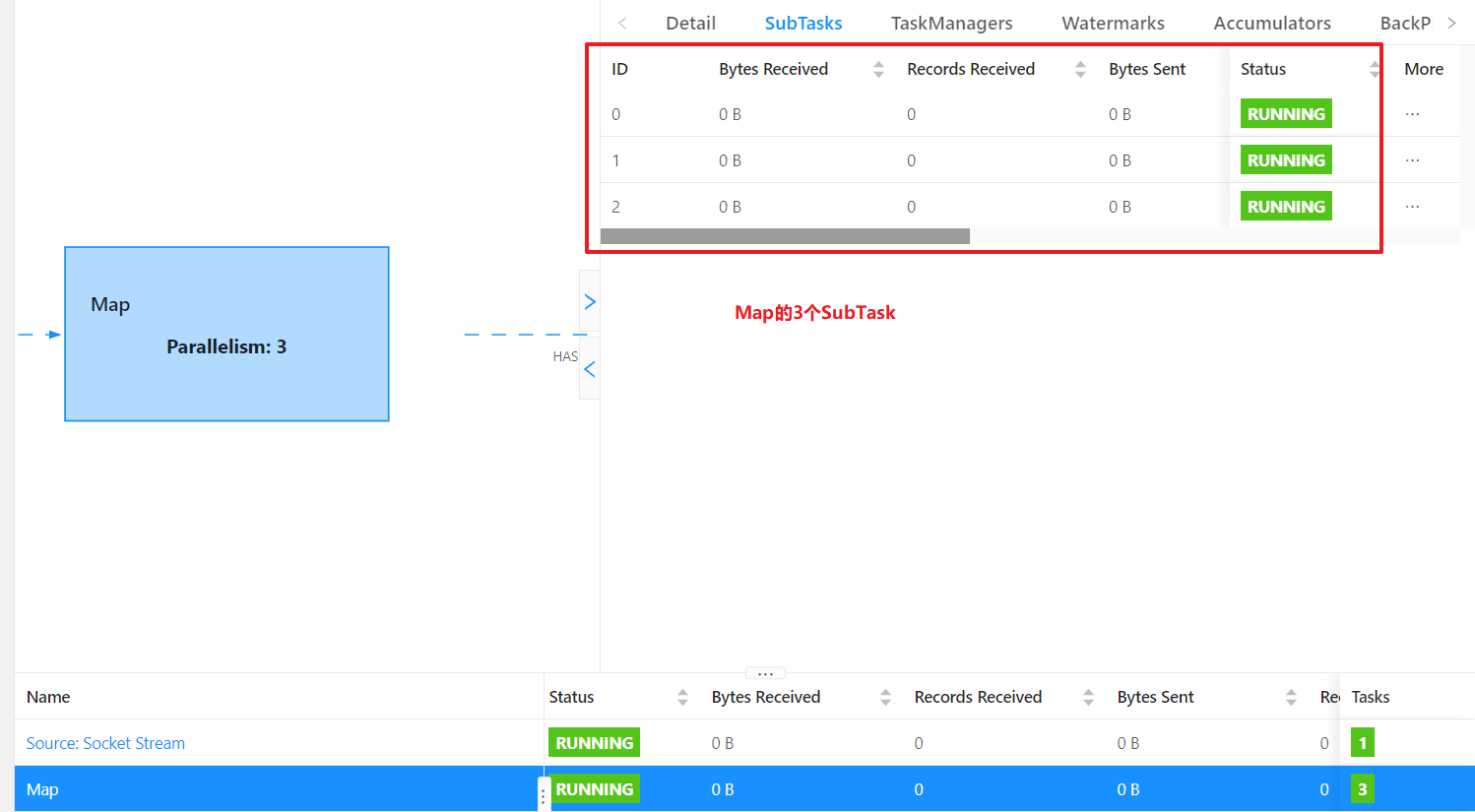
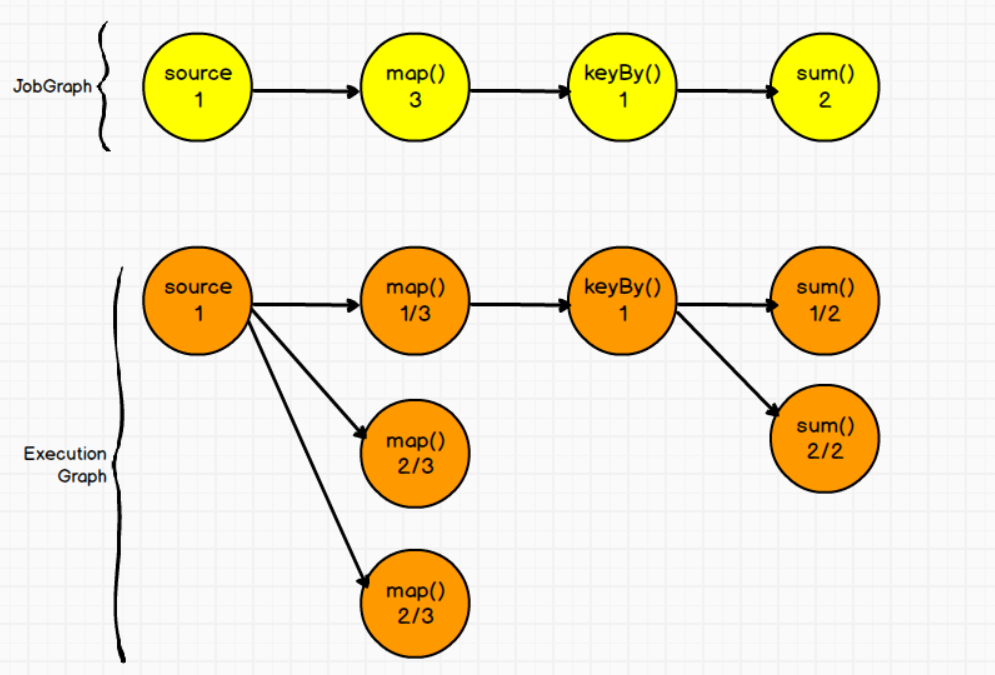
③ 流程序的并行度
流程序的并行度=所有算子中最大的并行度。(一个程序中不同算子可以有不同的并行度)
④ 如何指定并行度?
并行度的优先级:算子指定(代码) > env全局指定(代码) > 提交参数 > 配置文件
方式1:配置文件flink-conf.yaml中配置(默认为1)
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
方式2:提交参数 之 bin/flink run -p 3
# standalone模式:-p 3 会卡住
[atguigu@hadoop102 flink-standalone]$ bin/start-cluster.sh
[atguigu@hadoop102 flink-standalone]$ bin/flink run -m hadoop102:8081 -p 3 -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar
# yarn-per-job模式:-p3 不会卡住, -p5会卡住
[atguigu@hadoop102 flink-yarn]$ bin/flink run -t yarn-per-job -d -p 5 -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar
方式3:提交参数 之 web页面submit
方式4:代码指定 之 执行环境指定并行度
//环境指定并行度
env.setParallelism(1);
方式5:算子后面指定并行度
//处理数据
inputDS.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String s) throws Exception {
return Tuple2.of(s, 1L);
}
}).setParallelism(3)
⑤ 代码中不指定并行度:会使用主机的总线程数16
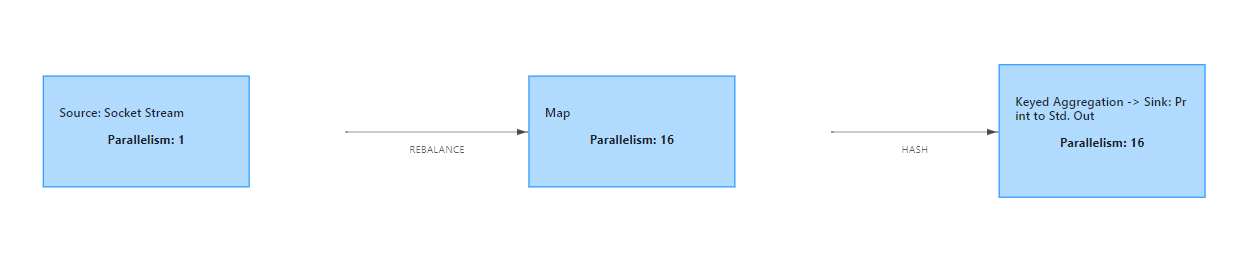
(8)并行度与slot个数关系?
--(如果不是Yarn模式,不会动态申请资源)如果并行度 > 所有的slot数 ,程序会一直处于 create状态,等待足够的资源,才运行
并行度大于solt个数,standalone模式:Flink会卡住
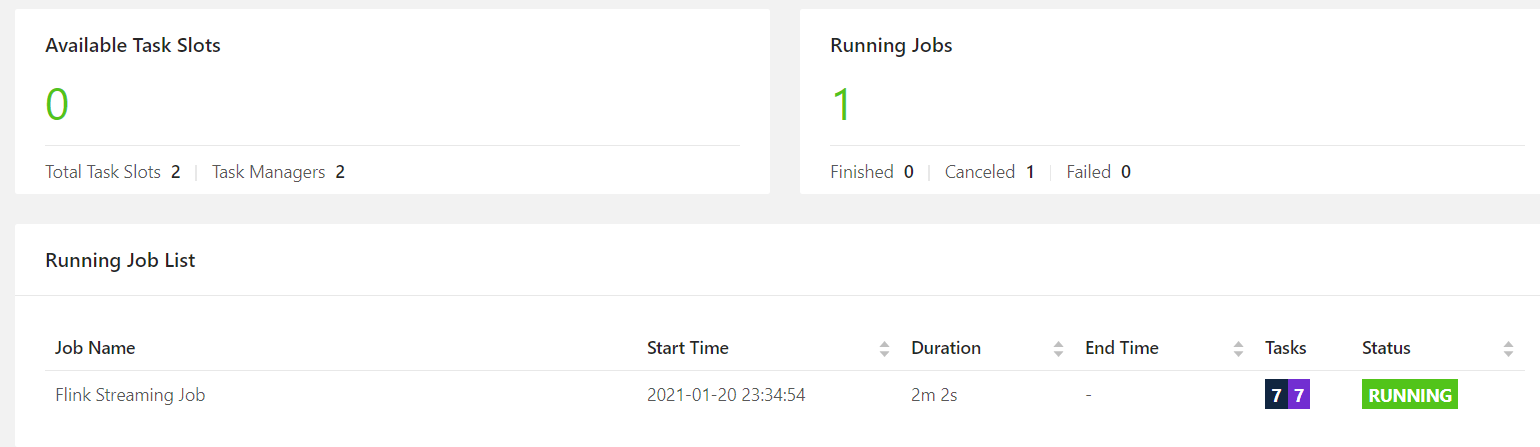
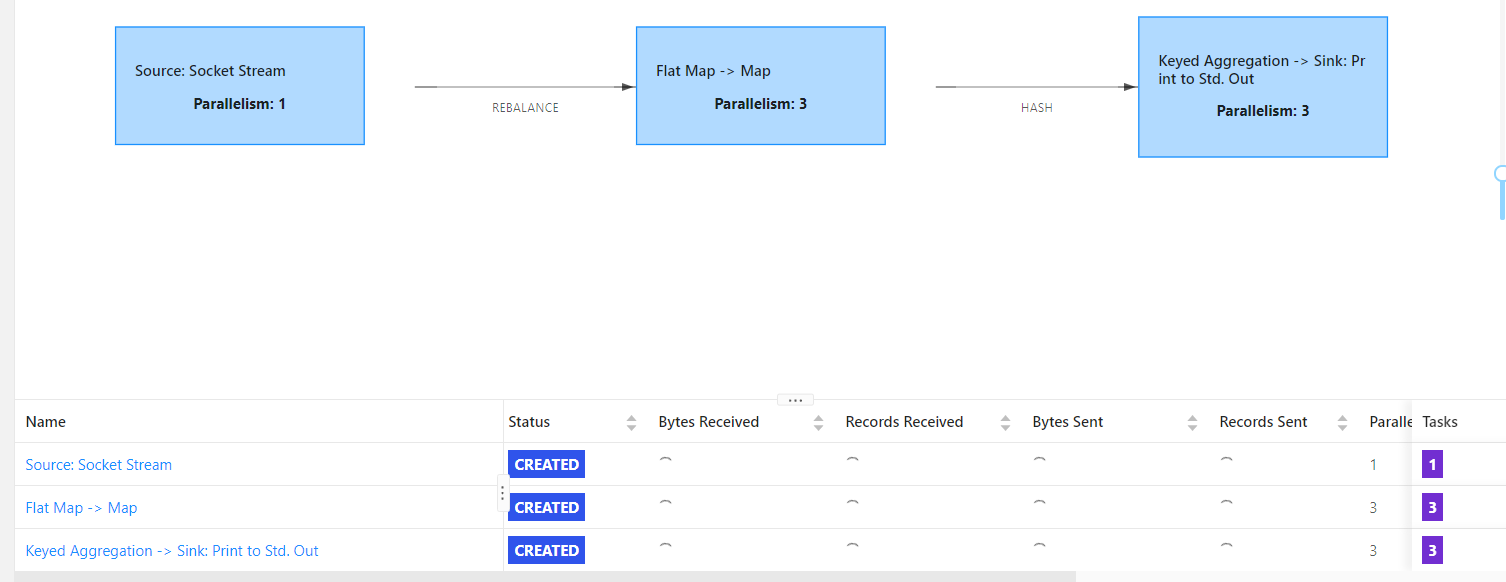
并行度大于solt个数,yarn-per-job模式,动态申请资源,不够了会申请TaskManager
但是如果TaskManager总的solt个数还是小于并行度,那么也会向上面一样卡住。
(9)并行度与task的关系?
Task个数 = 蓝框个个数 * 每个框的并行度
见④一个Job会有多少个Task、需要多少个solt?
(10)Task与SubTask
* Task与 subtask: 不同算子的 子任务(subtask) 经过一定的优化,串在一起,形成一个 新的subtask,叫做task
*
* sum算子 print算子 , 并行度都是 3
* ⭕ ⭕
* ⭕ ⭕
* ⭕ ⭕
*
* sum算子 跟 print算子 满足某种不可描述的关系,可以串在一起
* (⭕ ⭕) -> 新的 subtask -> 对 TaskManager来讲,就是一个 Task
* (⭕ ⭕) -> 新的 subtask -> 对 TaskManager来讲,就是一个 Task
* (⭕ ⭕) -> 新的 subtask -> 对 TaskManager来讲,就是一个 Task
(11)算子之间传输形式
①One-to-one
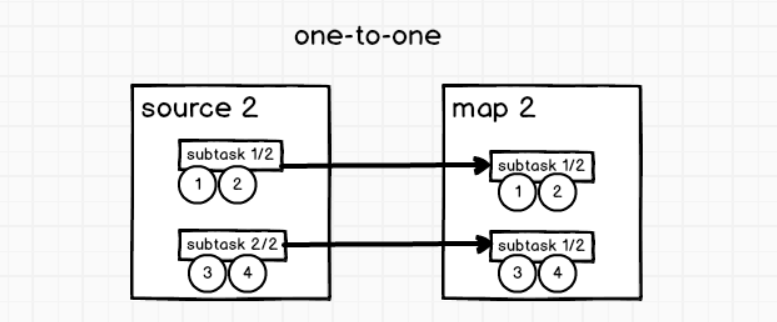
类似于spark中的窄依赖。相同并行度!
stream(比如在source和map operator之间)维护着分区以及元素的顺序。那意味着flatmap 算子的子任务看到的元素的个数以及顺序跟source 算子的子任务生产的元素的个数、顺序相同,map、fliter、flatMap等算子都是one-to-one的对应关系。
②Redistributing

类似于spark中的宽依赖
-
keyBy()基于hashCode重分区
分组,类似于shuffle
-
rebalance重分配
原因是并行度不相等,数据轮询的发送给下游subtask
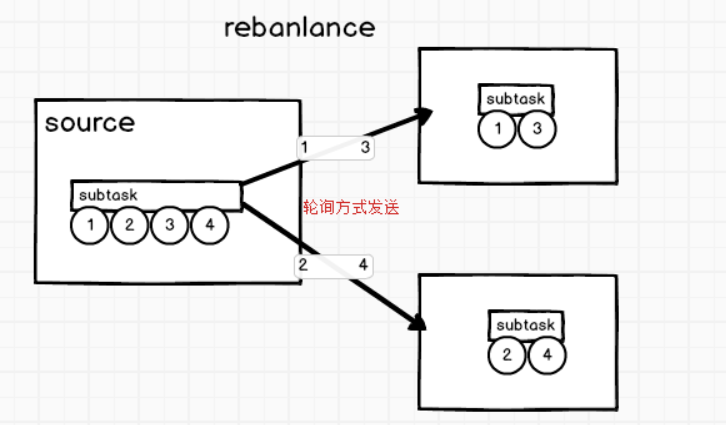
-
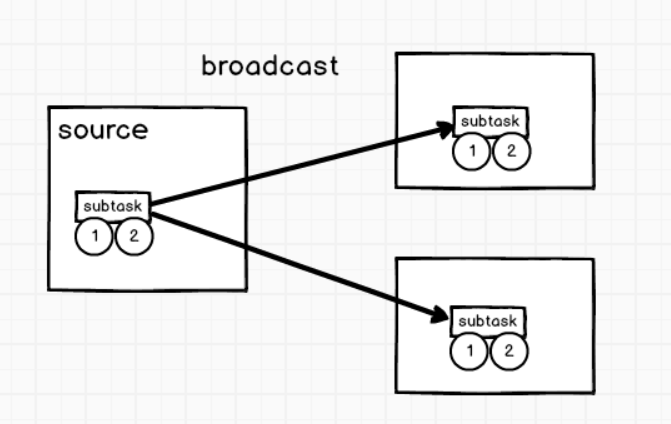
broadcast广播变量
(12)Operator Chains
* 操作链相关API
* 1) 算子.startNewChain() =》 与前面切开
* 2) 算子.disableChaining() =》 与前后都切开
* 3) env.disableOperatorChaining() =》 全局都不串
相同并行度的one to one操作,Flink将这样相连的算子链接在一起形成一个task,原来的算子成为里面的一部分。 每个task被一个线程执行.
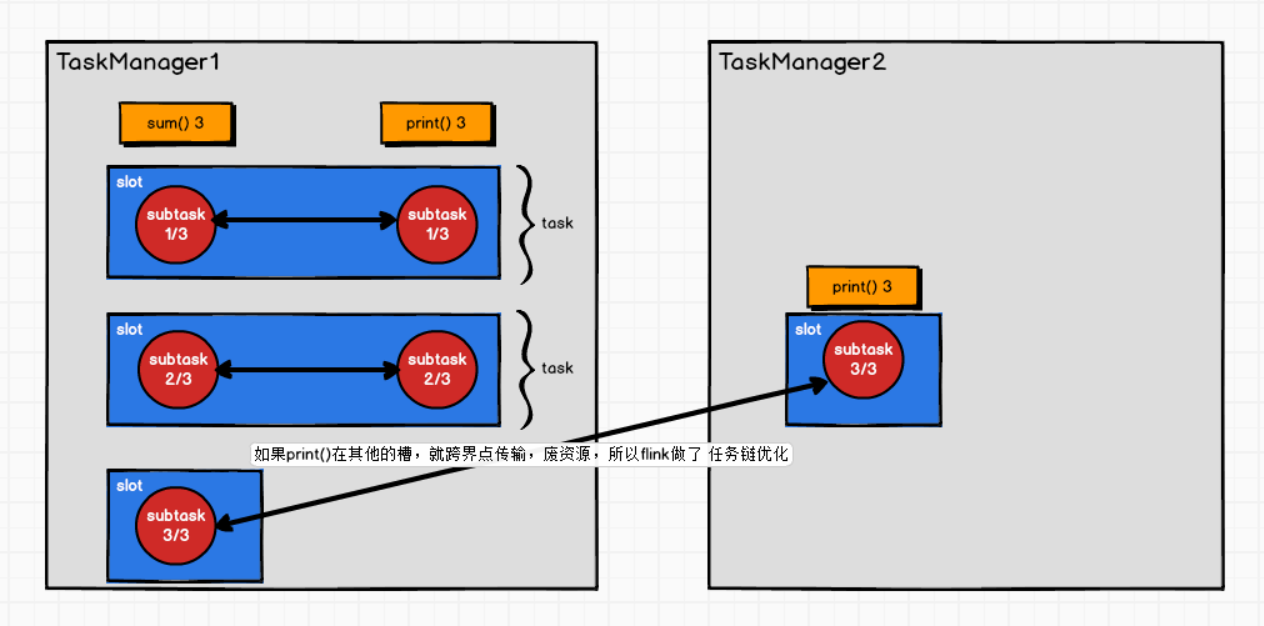
优点:
将算子链接成task是非常有效的优化:它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。链接的行为可以在编程API中进行指定。
// 创建执行环境
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 为了idea运行直接可以看到 webui,使用如下方式:
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// 全局设置并行度
env.setParallelism(5);
env.disableOperatorChaining(); // 全局禁用操作链
env
.socketTextStream("hadoop102", 9999)
// .socketTextStream("hadoop1", 9999)
.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);
}
}
})
// .disableChaining() // 当前算子不加入任何链条
.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String value) throws Exception {
return Tuple2.of(value, 1L);
}
})
//.setParallelism(4)
// .startNewChain() // 以当前算子开始,重新开链条
.keyBy(0)
.sum(1)
.print();
// 执行
env.execute();
(12)ExecutionGraph(执行图)
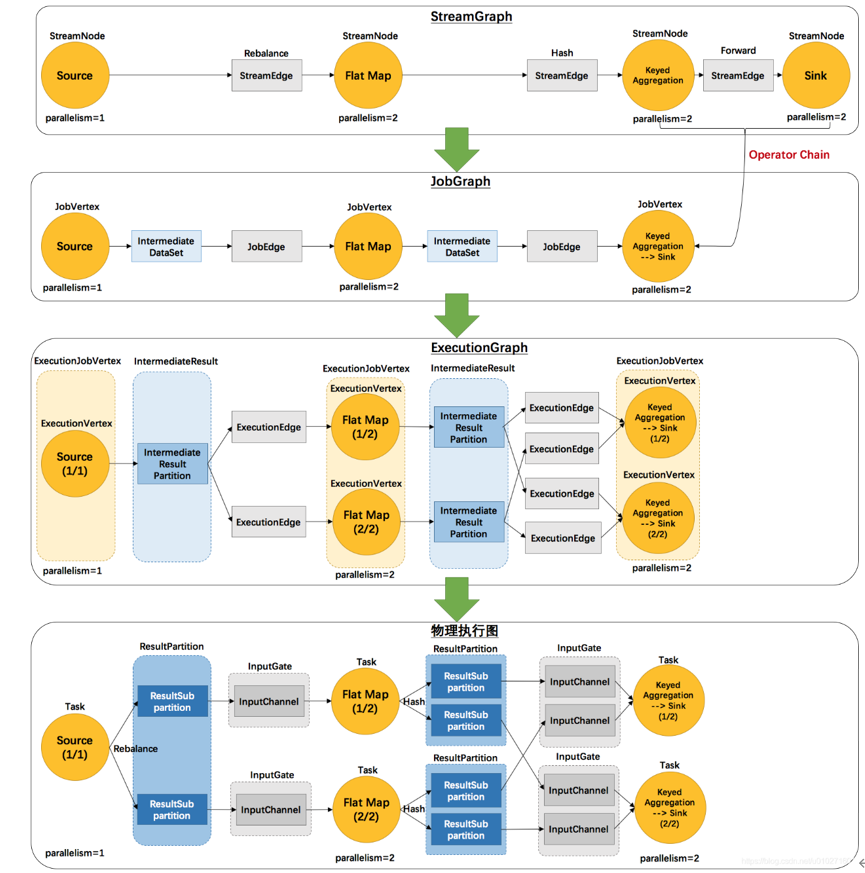
Flink中的执行图分为四层:StreamGraph --> JobGraph --> ExecutionGraph --> PhysicalGraph
①StreamGraph(逻辑流程图)
根据用户Stream API编写的代码生成的原始图,生成于Client
②JobGraph(作业图)
对StreamGraph经过优化生成的JobGraph,生成于Client,用来提交给JobManager。就像Web页面的作业流程图

③ExecutionGraph(执行图)
JobManager根据JobGraph生成的ExecutionGraph。用来传给每个TaskManager,是调度层最核心的数据结构
④PhysicalGraph
JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
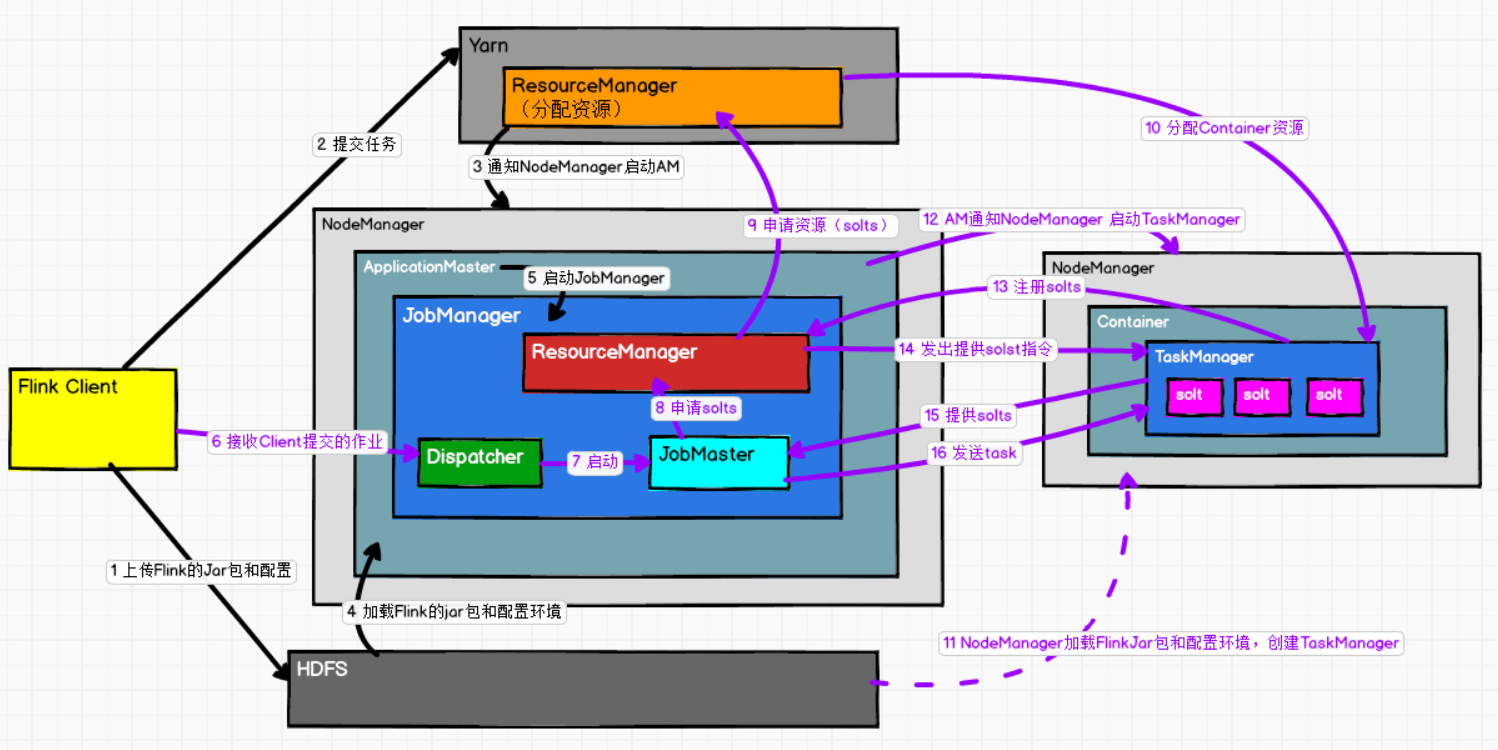
4.2 提交流程
①通用提交流程
②yarn-per-job提交流程
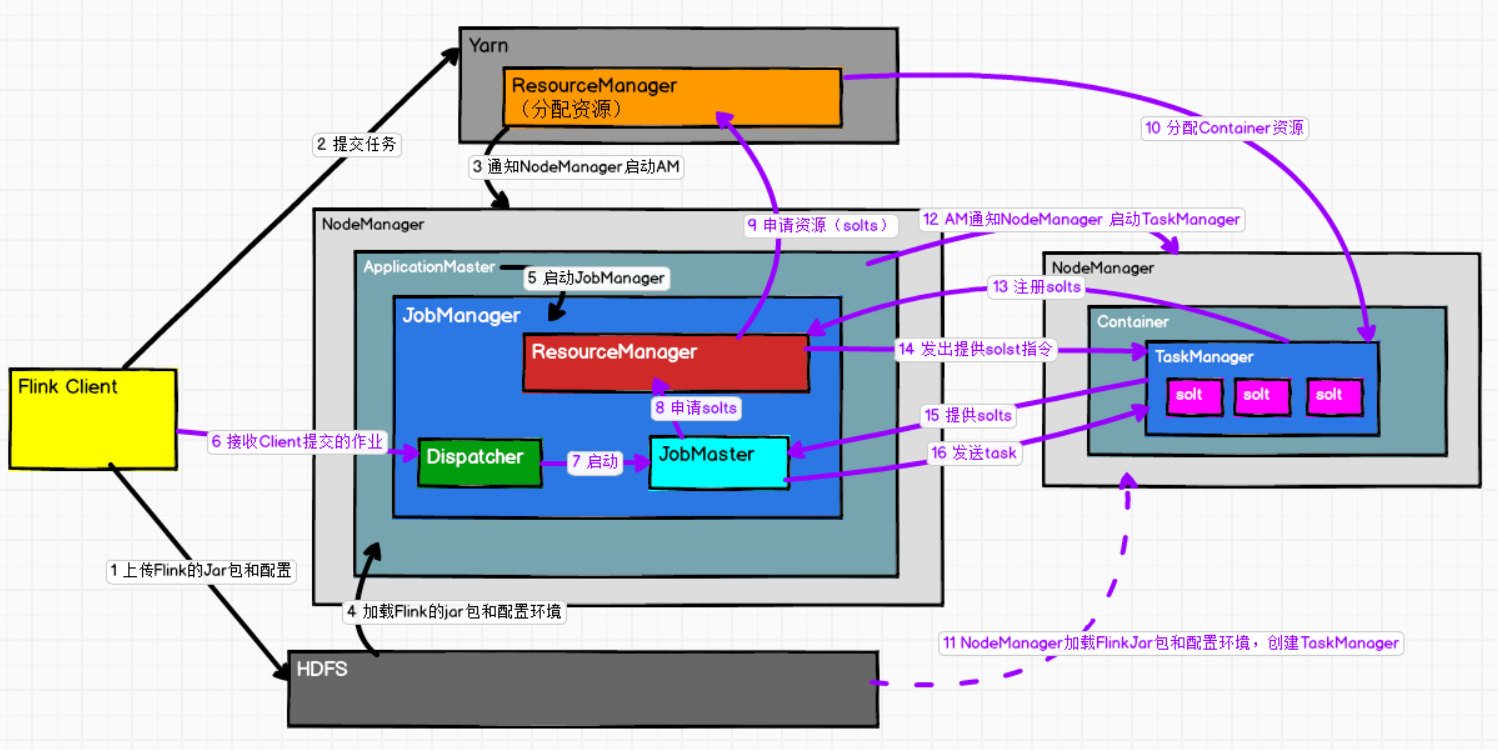
-
FlinkClient通过bin/flink run -t yarn-per-job -c 全类名 jar包路径,的方式将 flink运行时jar包和配置环境上传到HDFS
为什么要上传flink运行时jar包和配置环境到HDFS呢?
区别于Standalone模式,standalone模式要star-cluster启动集群,而yarnper-job是基于Yarn的,由Yarn启动集群(无需手动启动集群),所以需要这些配置。
-
提交任务给Yarn,Yarn ResourceManager分配Contaioner资源
-
通知NodeManager,启动ApplicationMaster
-
AM启动会加载HDFS上的Flink的jar包和配置环境
-
启动JobManager
-
Dispatcher接收Client提交的作业
-
Dispatcher启动一个JobMaster
-
JobMaster会像Flink的ResourceManager申请运行任务的solts
-
Flink ResourceManager作为一个中介,会去向Yarn ResourceManager申请solts
-
Yarn ResourceManager会分配Container给NodeManager
-
NodeManager从HDFS加载flink的jar包和配置,创建TaskManager。
-
由ApplicationMaster通知NodeManager 启动TaskManager
-
TaskManager会向Flink ResourceManager注册自己有的solts
-
Flink ResourceManager 发出提供solts的指令给TaskManager
-
TaskManager会回复准备好了solts
-
最后JobMaster发送Task给TaskManager