Flink 基础核心概念
(1)客户端
- 客户端并不是运行和程序执行的一部分,而是准备和发送dataflow到 JobManager,然后客户端可以断开与JobManager的连接(detached mode),也可以继续保持与JobManager的连接(attached mode)
客户端作为触发执行的java或者scala代码的一部分运行, 也可以在命令行运行:bin/flink run …
-
Client解析代码生成逻辑流图(StreamGraph)
-
将StreamGraph优化成作业图(JobGraph),(优化操作链)然后传给JobManager。(Web页面看到的作业图)
(2)JobManager
-
控制一个应用程序的主进程(一个应用程序都会被一个不同的JobManager所控制执行)
-
JobManager会接收到Client端传来应用程序。包括:
- Client端传来的:逻辑数据流图、作业图(JobGraph)、打包的所有类、库、和其他资源的jar包
-
JobManager会把JobGraph转换成物理层面上的执行图(ExecutionGraph),包含了所有可以并行执行的任务。
-
JobManager会向资源管理器(ResourceManager)请求执行任务必要的资源(Solt);然后启动TaskManager(默认是1个Solt);然后会注册solts个数;一旦资源足够,就会将执行图发送给TaskManager
JobManager负责Flink内部资源的管理。
JobManager分为:ResourceManager、Dispatcher、JobMaster三个组件
①Dispatcher
接收用户提供的作业;启动一个新的JobMaster
②JobMaster
JobMaster负责管理单个JobGraph的执行。多个Job可以同时运行在一个Flink集群中,每个Job都有一个自己的 JobMaster。
扫描二维码关注公众号,回复: 12687074 查看本文章
③ResourceManager
负责flink资源的管理,在整个Flink集群中只有一个ResourceManager。
需要区别于Yarn的ResourceManager,是Flink中内置的。重名
主要负责管理任务管理器(TaskManager)的插槽(slot),TaskManger插槽是Flink中定义的处理资源单元。
当JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager。如果ResourceManager没有足够的插槽来满足JobManager的请求,它还可以向资源提供平台发起会话,以提供启动TaskManager进程的容器。另外,ResourceManager还负责终止空闲的TaskManager,释放计算资源。
(3)TaskManager
Flink中的工作进程。通常在Flink中会有多个TaskManager运行,每一个TaskManager都包含了一定数量的插槽(solts)。插槽的数量限制了TaskManager能够执行的任务数量。
启动TaskManager之后,TaskManager会向资源管理器注册它的槽,ResourceManager收到注册信息后向TaskManager发送提供solt指令,然后会给JobManager提供solt,最后JobManager会将Task发送到solt。
(4)槽(solt)和任务task的关系?
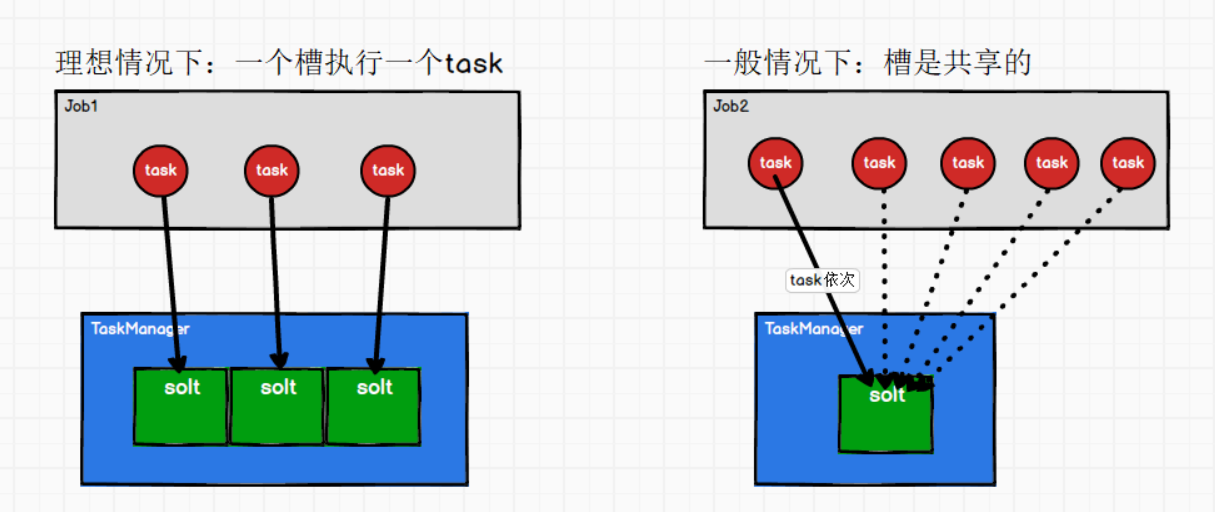
① Solt是可以共享的,Job内部共享
理想情况:一个槽执行一个Task。
一般情况:一个Job,并行度为1,有5个Task,有2个槽。那么槽就会共享,因为task有先后顺序。
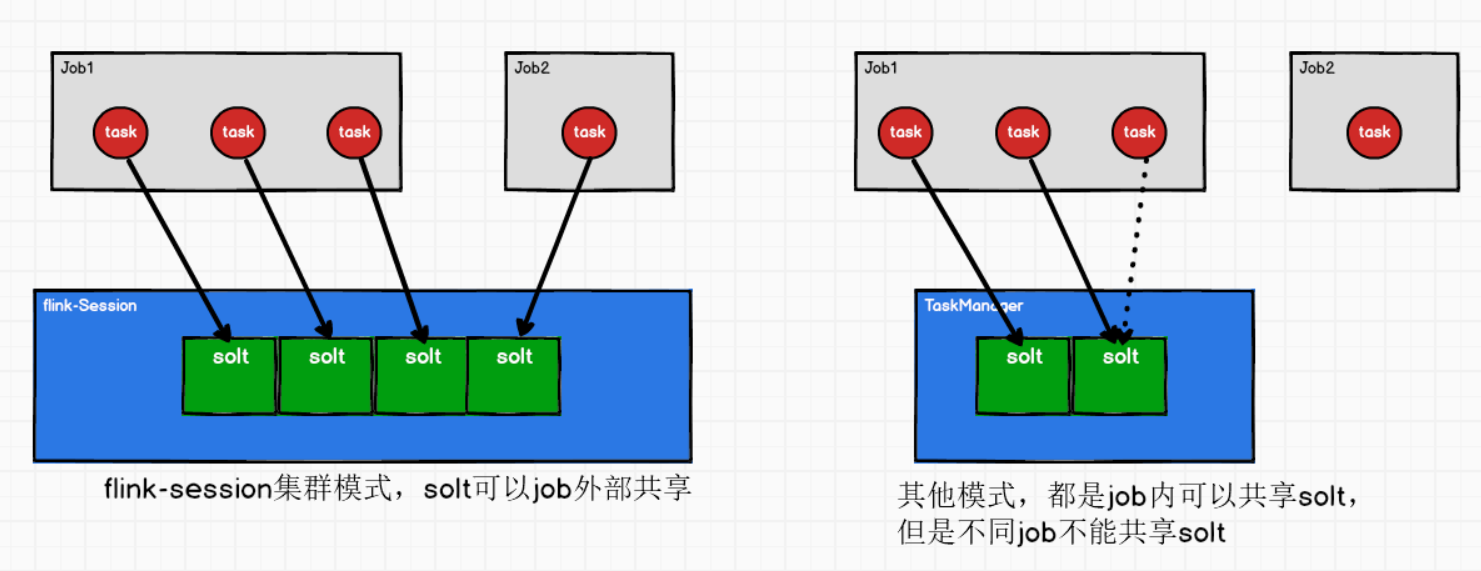
② 只有yarn-session模式,solt可以Job外部共享
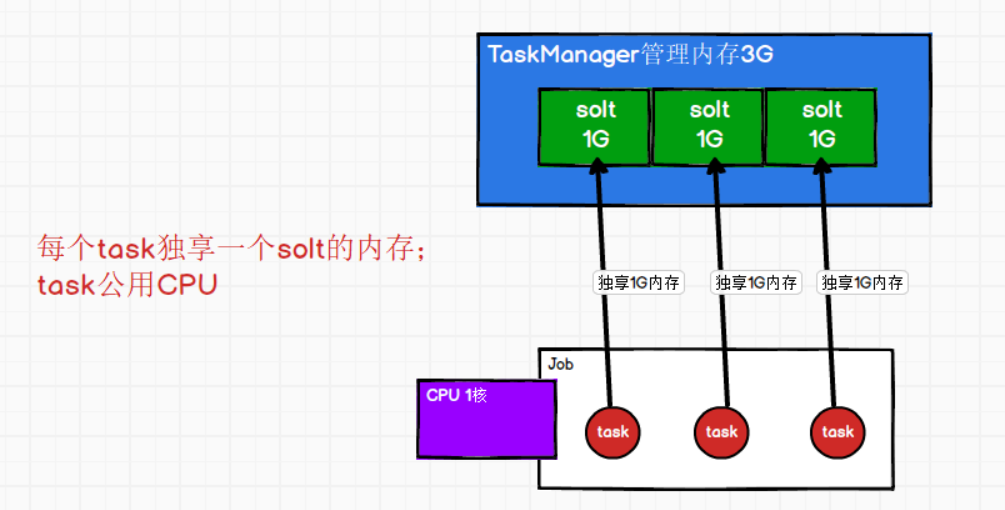
③ 每个solt的内存是均分TaskManager的管理内存;每个task独享一个solt内存
(5)一个Job会有多少个Task、需要多少个solt?
每个应用程序Job需要几个solts呢?
一个task就占用一个solt,也就是说每个Job会产生多少task呢?
Task个数 = 蓝框个个数 * 每个框的并行度
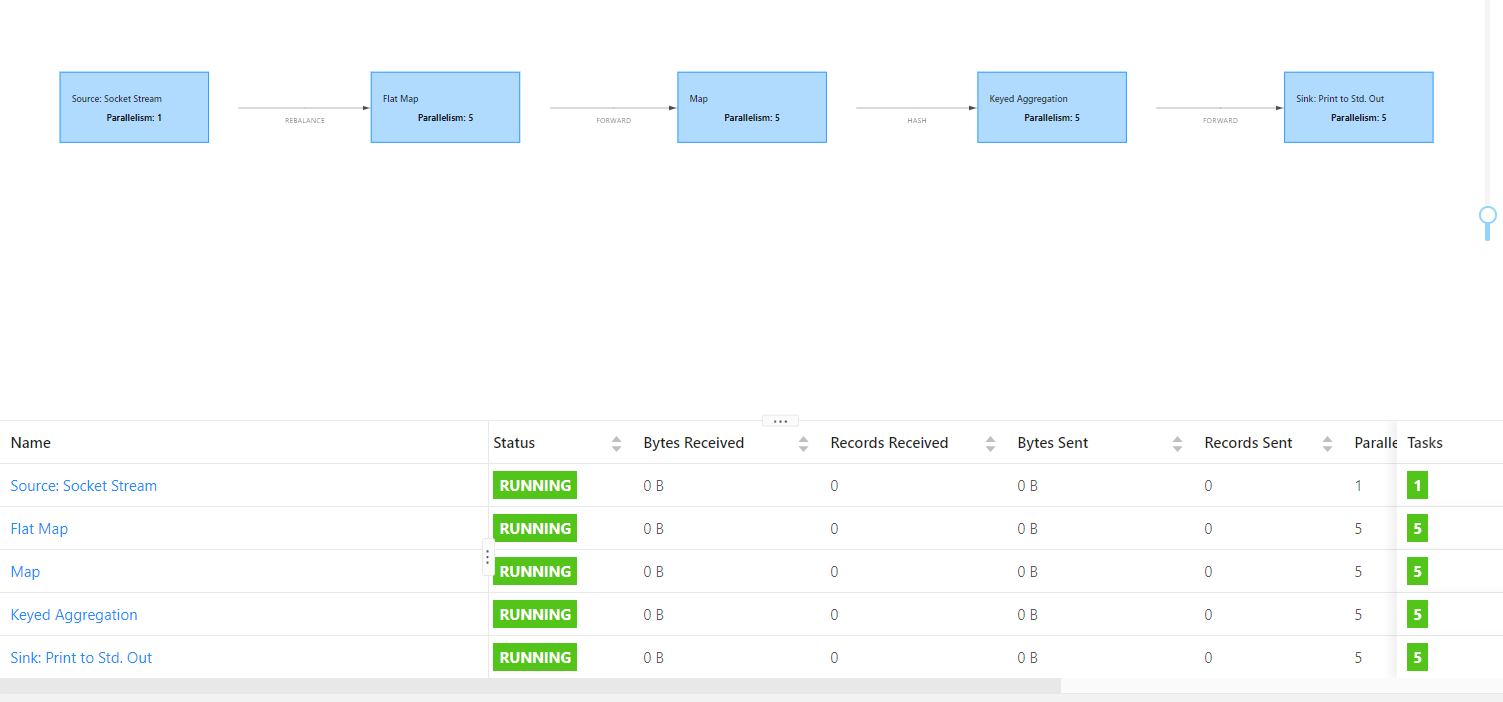
(6)每个TaskManager有多少个槽(solt)呢?
flink中每个TaskManager都是一个JVM进程,TaskManager通过solt来控制能够接收多少个Task
默认每个TaskManager有一个solt,在配置文件flink-conf.yaml修改默认槽的个数
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline. taskmanager.numberOfTaskSlots: 1命令参数方式指定槽的个数:
bin/flink run -t yarn-per-job -d -Dtaskmanager.numberOfTaskSlots=3 -c 全类名 路径
(7)Parallelism(并行度)
① 什么是并行度?
同时运行的任务(task)数量。(动态的一个概念)
如果有4个solts,有3个task同时运行,那么并行度就是3。
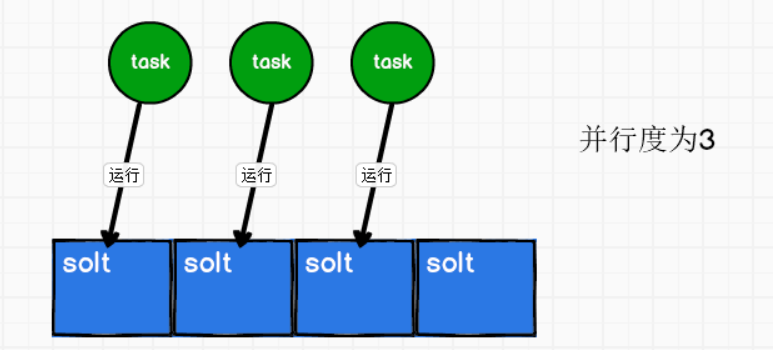
② 算子的并行度
一个特定算子的子任务(subtask)的个数,称为这个算子的并行度(parallelism)
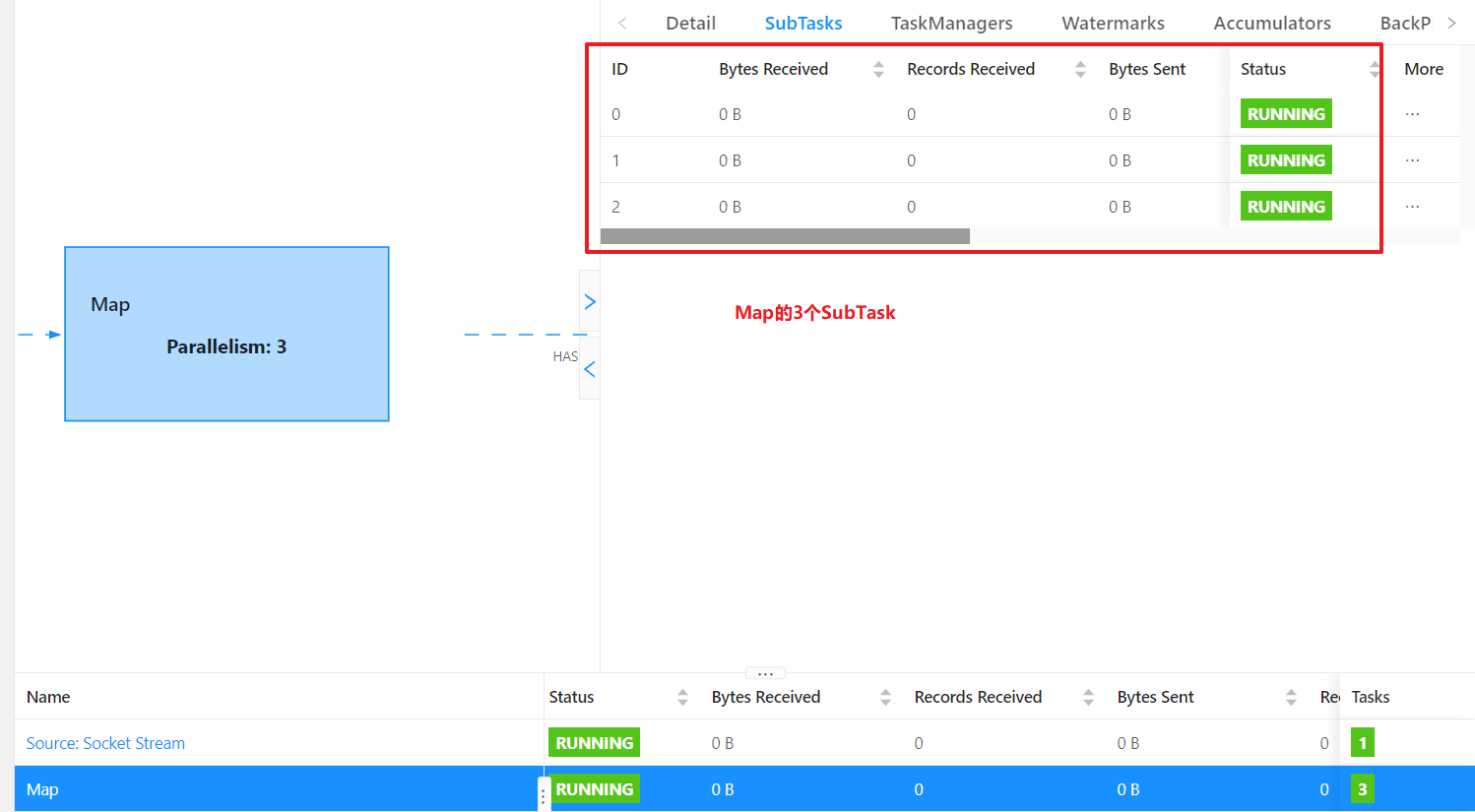
③ 流程序的并行度
流程序的并行度=所有算子中最大的并行度。(一个程序中不同算子可以有不同的并行度)
④ 如何指定并行度?
并行度的优先级:算子指定(代码) > env全局指定(代码) > 提交参数 > 配置文件
方式1:配置文件flink-conf.yaml中配置(默认为1)
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
方式2:提交参数 之 bin/flink run -p 3
# standalone模式:-p 3 会卡住
[atguigu@hadoop102 flink-standalone]$ bin/start-cluster.sh
[atguigu@hadoop102 flink-standalone]$ bin/flink run -m hadoop102:8081 -p 3 -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar
# yarn-per-job模式:-p3 不会卡住, -p5会卡住
[atguigu@hadoop102 flink-yarn]$ bin/flink run -t yarn-per-job -d -p 5 -c com.codejiwei.flink.chapter02.Flink04_WC_UnBoundedStream /opt/module/flink_data/flink-1.0-SNAPSHOT-jar-with-dependencies.jar
方式3:提交参数 之 web页面submit
方式4:代码指定 之 执行环境指定并行度
//环境指定并行度
env.setParallelism(1);
方式5:算子后面指定并行度
//处理数据
inputDS.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String s) throws Exception {
return Tuple2.of(s, 1L);
}
}).setParallelism(3)
⑤ 代码中不指定并行度:会使用主机的总线程数16
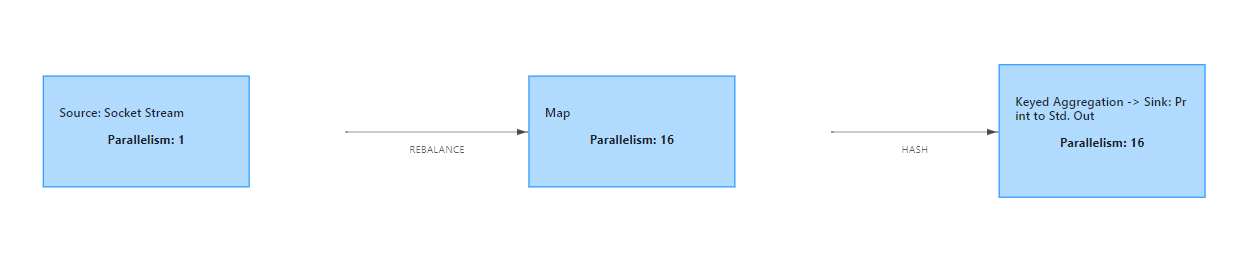
(8)并行度与slot个数关系?
--(如果不是Yarn模式,不会动态申请资源)如果并行度 > 所有的slot数 ,程序会一直处于 create状态,等待足够的资源,才运行
并行度大于solt个数,standalone模式:Flink会卡住
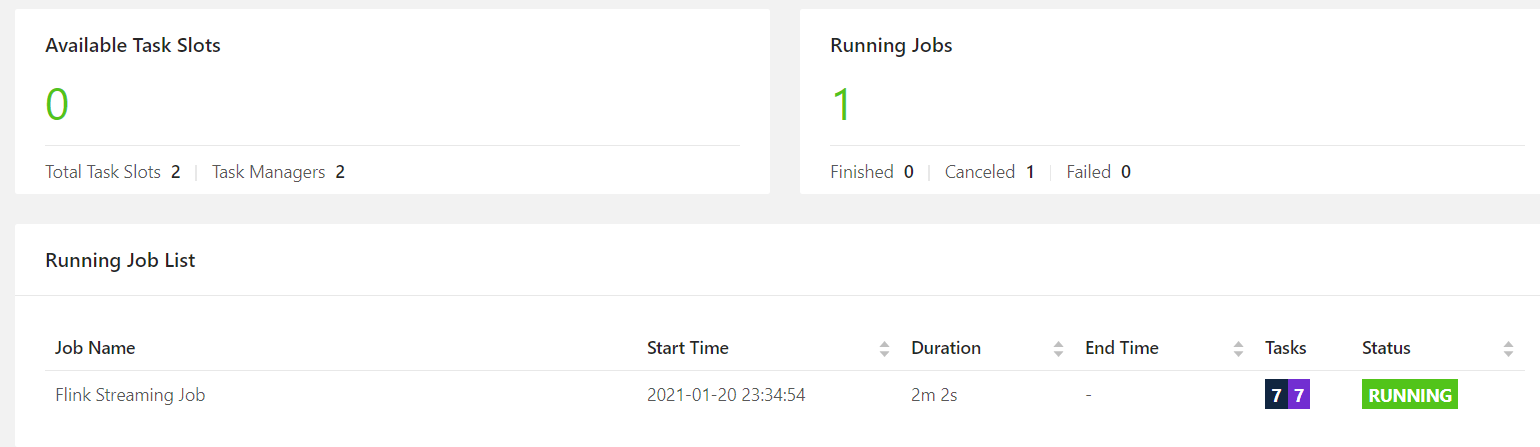
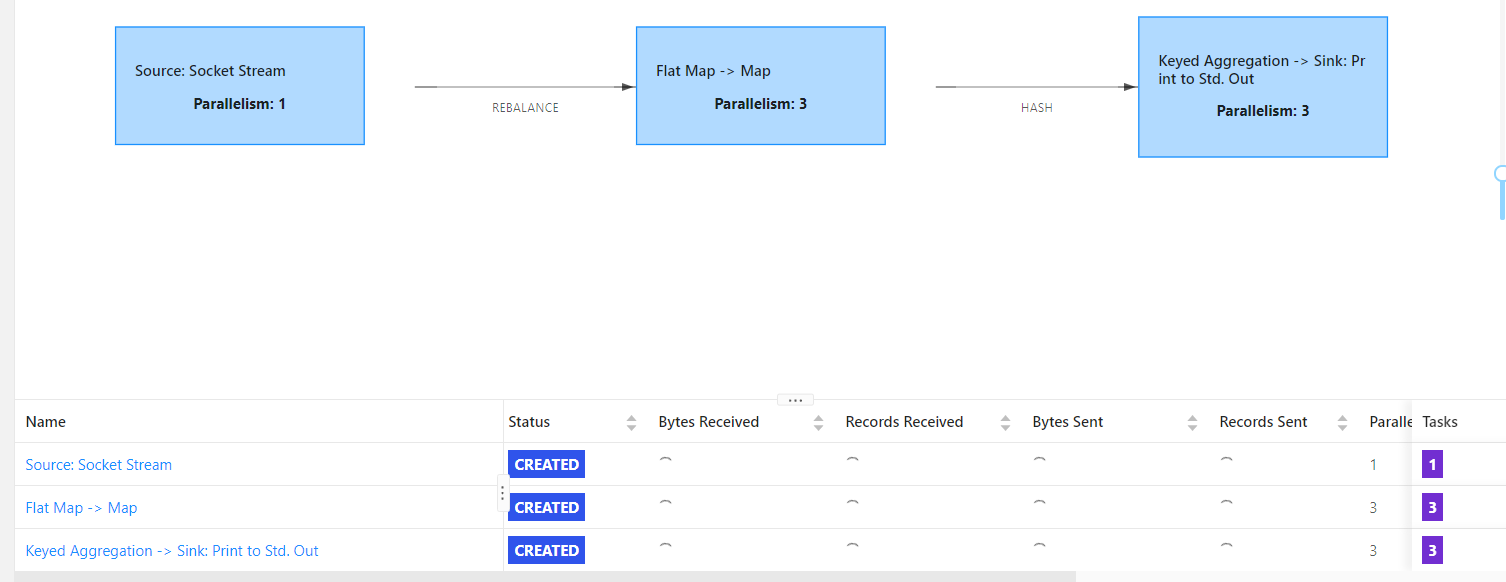
并行度大于solt个数,yarn-per-job模式,动态申请资源,不够了会申请TaskManager
但是如果TaskManager总的solt个数还是小于并行度,那么也会向上面一样卡住。
(9)并行度与task的关系?
Task个数 = 蓝框个个数 * 每个框的并行度
见④一个Job会有多少个Task、需要多少个solt?
(10)Task与SubTask
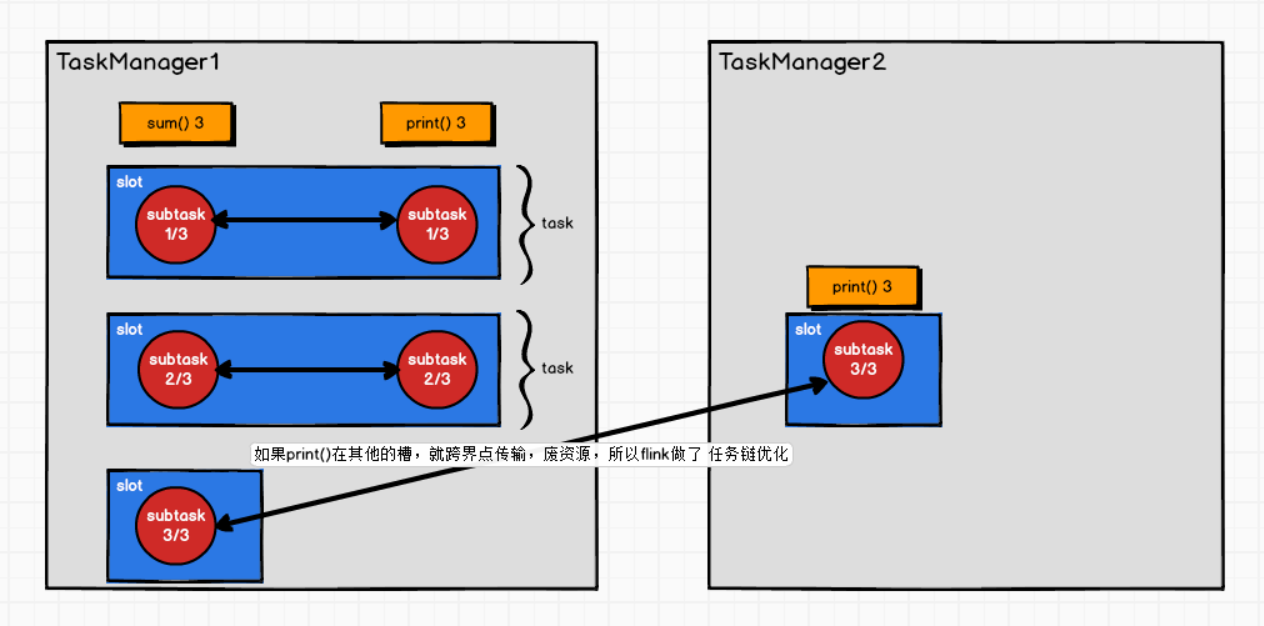
* Task与 subtask: 不同算子的 子任务(subtask) 经过一定的优化,串在一起,形成一个 新的subtask,叫做task
*
* sum算子 print算子 , 并行度都是 3
* ⭕ ⭕
* ⭕ ⭕
* ⭕ ⭕
*
* sum算子 跟 print算子 满足某种不可描述的关系,可以串在一起
* (⭕ ⭕) -> 新的 subtask -> 对 TaskManager来讲,就是一个 Task
* (⭕ ⭕) -> 新的 subtask -> 对 TaskManager来讲,就是一个 Task
* (⭕ ⭕) -> 新的 subtask -> 对 TaskManager来讲,就是一个 Task
(11)算子之间传输形式
①One-to-one
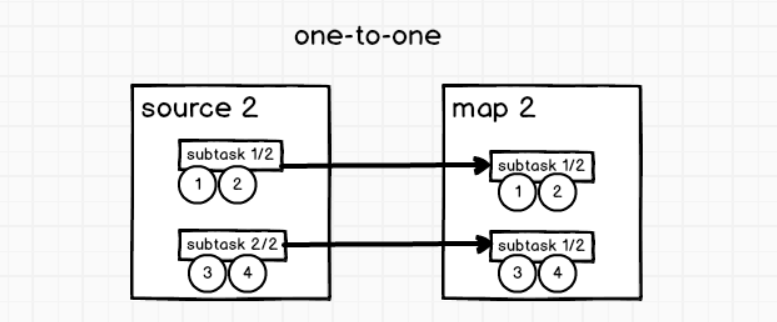
类似于spark中的窄依赖。相同并行度!
stream(比如在source和map operator之间)维护着分区以及元素的顺序。那意味着flatmap 算子的子任务看到的元素的个数以及顺序跟source 算子的子任务生产的元素的个数、顺序相同,map、fliter、flatMap等算子都是one-to-one的对应关系。
②Redistributing

类似于spark中的宽依赖
-
keyBy()基于hashCode重分区
分组,类似于shuffle
-
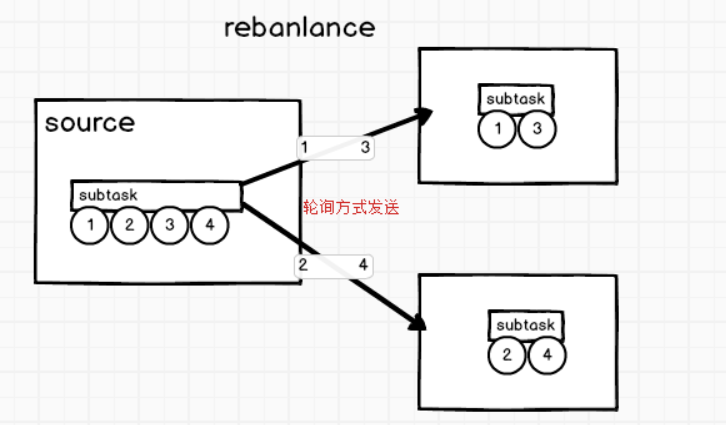
rebalance重分配
原因是并行度不相等,数据轮询的发送给下游subtask
-
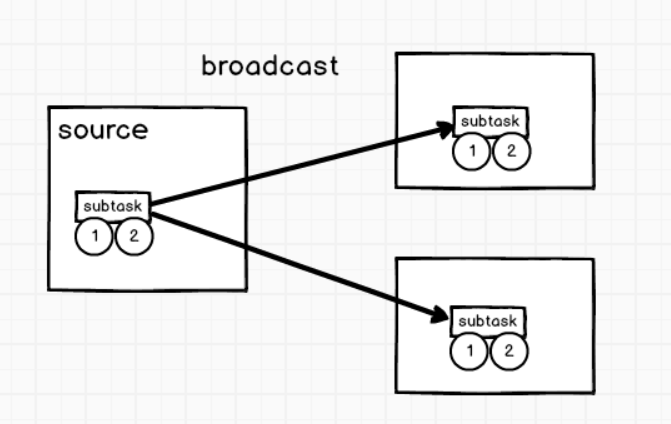
broadcast广播变量
(12)Operator Chains
* 操作链相关API
* 1) 算子.startNewChain() =》 与前面切开
* 2) 算子.disableChaining() =》 与前后都切开
* 3) env.disableOperatorChaining() =》 全局都不串
相同并行度的one to one操作,Flink将这样相连的算子链接在一起形成一个task,原来的算子成为里面的一部分。 每个task被一个线程执行.
优点:
将算子链接成task是非常有效的优化:它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。链接的行为可以在编程API中进行指定。
// 创建执行环境
// StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 为了idea运行直接可以看到 webui,使用如下方式:
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// 全局设置并行度
env.setParallelism(5);
env.disableOperatorChaining(); // 全局禁用操作链
env
.socketTextStream("hadoop102", 9999)
// .socketTextStream("hadoop1", 9999)
.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);
}
}
})
// .disableChaining() // 当前算子不加入任何链条
.map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String value) throws Exception {
return Tuple2.of(value, 1L);
}
})
//.setParallelism(4)
// .startNewChain() // 以当前算子开始,重新开链条
.keyBy(0)
.sum(1)
.print();
// 执行
env.execute();
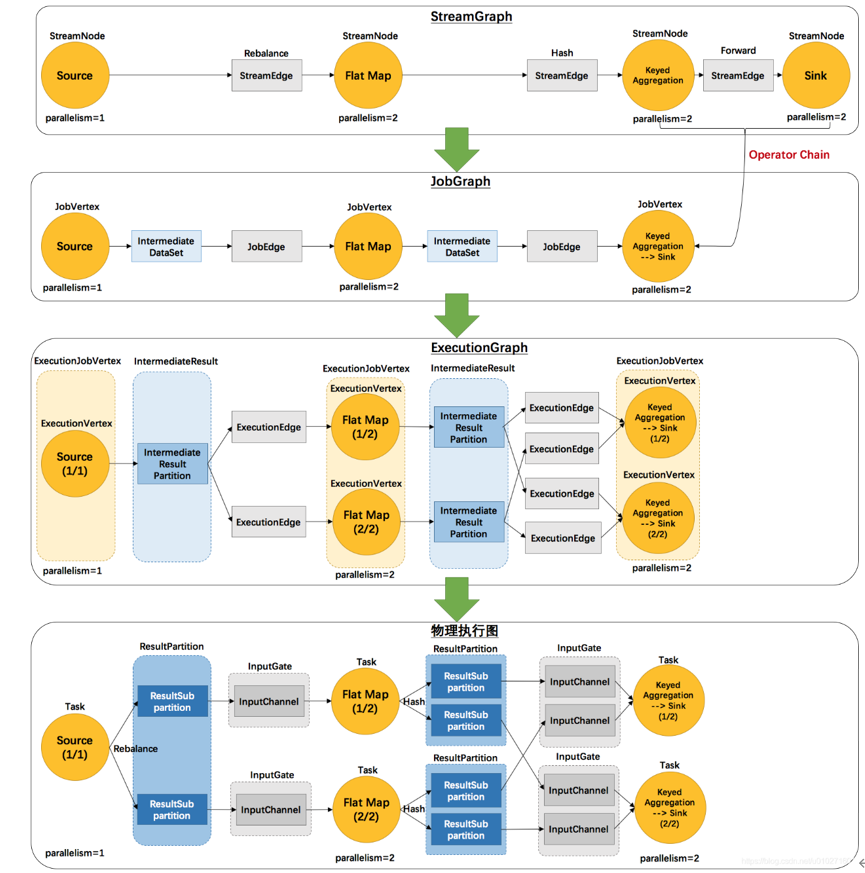
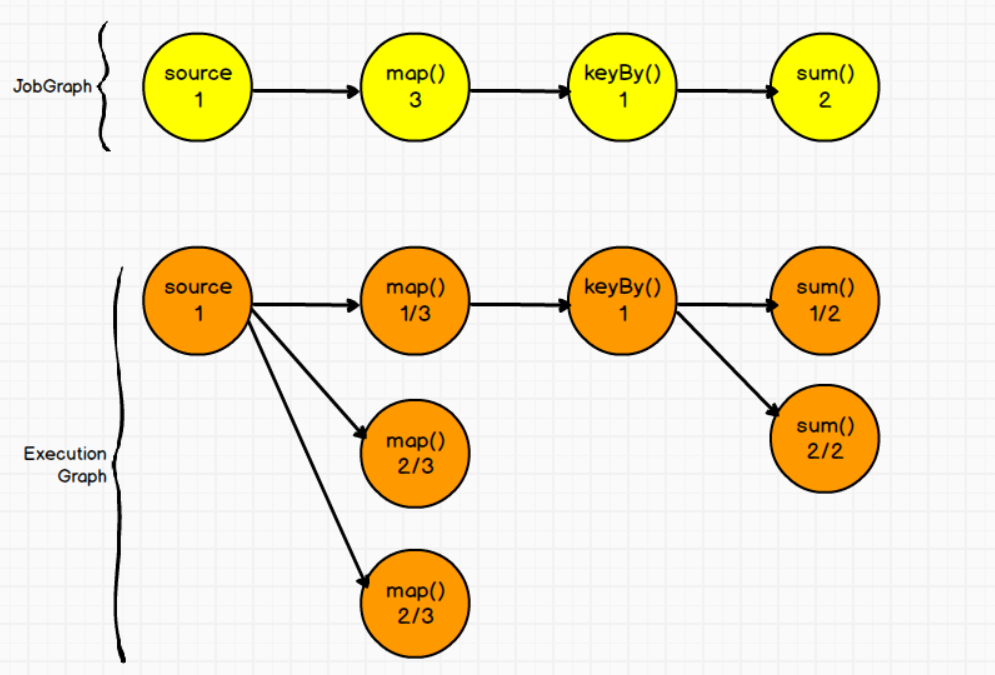
(12)ExecutionGraph(执行图)
Flink中的执行图分为四层:StreamGraph --> JobGraph --> ExecutionGraph --> PhysicalGraph
①StreamGraph(逻辑流程图)
根据用户Stream API编写的代码生成的原始图,生成于Client
②JobGraph(作业图)
对StreamGraph经过优化生成的JobGraph,生成于Client,用来提交给JobManager。就像Web页面的作业流程图

③ExecutionGraph(执行图)
JobManager根据JobGraph生成的ExecutionGraph。用来传给每个TaskManager,是调度层最核心的数据结构
④PhysicalGraph
JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。