一、WaterMark机制引入的背景
前面提到了Time的概念,如果我们使用Processing Time,那么在 Flink 消费数据的时候,它完全不需要关心数据本身的时间,意思也就是说不需要关心数据到底是延迟数据还是乱序数据。因为 Processing Time 只是代表数据在 Flink 被处理时的时间,这个时间是顺序的。
但是如果你使用的是 Event Time 的话,那么你就不得不面临着这么个问题:事件乱序 & 事件延迟。
所以…
为了解决这个问题,Flink中引入了WaterMark机制,即水印的概念。、
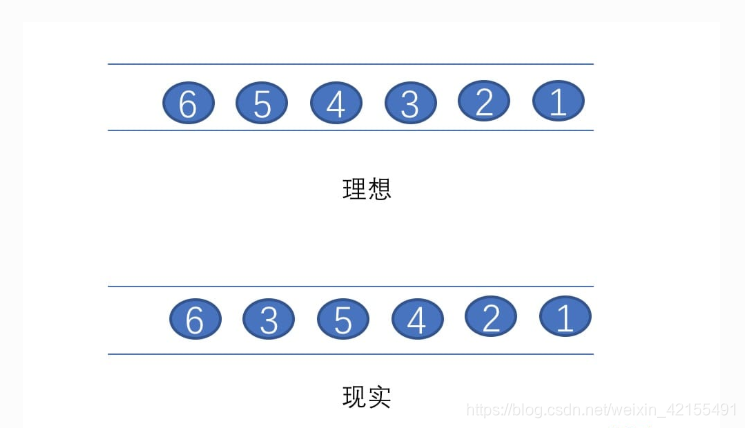
在实际生产中,我们可能遇到这样的问题,Flink 接收到的事件的先后顺序并不是严格的按照事件的 Event Time 顺序排列的(网络的抖动、设备的故障、应用的异常等原因):
然而在有些场景下,尤其是特别依赖于事件时间而不是处理时间,比如:
- 错误日志的时间戳,代表着发生的错误的具体时间,开发们只有知道了这个时间戳,才能去还原那个时间点系统到底发生了什么问题,或者根据那个时间戳去关联其他的事件,找出导致问题触发的罪魁祸首
- 设备传感器或者监控系统实时上传对应时间点的设备周围的监控情况,通过监控大屏可以实时查看,不错漏重要或者可疑的事件
- 比如我做过的充电桩实时报文分析,就必须依赖报文产生的时间,即事件时间
- …
针对上面的问题(事件乱序 & 事件延迟),Flink 引入了 Watermark 机制来解决。
二、Watermark 是什么?
统计 8:00 ~ 9:00 这个时间段打开淘宝 App 的用户数量,Flink 这边可以开个窗口做聚合操作,但是由于网络的抖动或者应用采集数据发送延迟等问题,于是无法保证在窗口时间结束的那一刻窗口中是否已经收集好了在 8:00 ~ 9:00 中用户打开 App 的事件数据,但又不能无限期的等下去?当基于事件时间的数据流进行窗口计算时,最为困难的一点也就是如何确定对应当前窗口的事件已经全部到达。然而实际上并不能百分百的准确判断,因此业界常用的方法就是基于已经收集的消息来估算是否还有消息未到达,这就是 Watermark 的思想。
Watermark 是一种衡量 Event Time 进展的机制,它是数据本身的一个隐藏属性,数据本身携带着对应的 Watermark。Watermark 本质来说就是一个时间戳,代表着比这时间戳早的事件已经全部到达窗口,即假设不会再有比这时间戳还小的事件到达,这个假设是触发窗口计算的基础,只有 Watermark 大于窗口对应的结束时间,窗口才会关闭和进行计算。按照这个标准去处理数据,那么如果后面还有比这时间戳更小的数据,那么就视为迟到的数据,对于这部分迟到的数据,Flink 也有相应的机制(下文会讲)去处理。
比如:
08:00任务开启,设置1分钟的滚动窗口,在08:00:00-08:01:00为第一个窗口,08:01:00-08:02:00为第二个窗口;
现在有一条数据的事件时间是08:00:50,但是这条数据却在08:01:10到达,按照正常的处理,窗口会在结束时间(08:01:00)的时候就触发计算,那么这条数据就会被丢弃;
但是开启WaterMark后,窗口在08:01:00时不会触发;
因为采用的是EventTime,而数据本身时间是08:00:50,所以该条数据肯定会落到第一个窗口;
假设在08:01:10时的WaterMark为08:00:01(WaterMark可以理解为一个时间戳),发现这个WaterMark和第一个窗口的结束时间相等,此时触发第一个窗口的计算操作,此时这条延迟数据正好参与到计算中;
此时只有水印大于或等于窗口结束时间才会触发窗口的关闭和计算;
此时就不会丢数据。
三、WaterMark的设置
注:如果你采用的是事件时间,即你设置了 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
那么你就必须设置获取事件时间的方法,否则会报错(如果是从kafka消费数据,不设置水印的话,默认采用kafka消息自带的时间戳作为事件时间)
数据处理中需要通过调用 DataStream 中的 assignTimestampsAndWatermarks 方法来分配时间和水印,该方法可以传入两种参数,一个是 AssignerWithPeriodicWatermarks,另一个是 AssignerWithPunctuatedWatermarks。
所以设置 Watermark 是有如下两种方式:
- AssignerWithPunctuatedWatermarks:数据流中每一个递增的 EventTime 都会产生一个 Watermark。
- AssignerWithPeriodicWatermarks:周期性的(一定时间间隔或者达到一定的记录条数)产生一个 Watermark。
实际生产中用第二种的比较多,它会周期性产生 Watermark 的方式,但是必须结合时间或者积累条数两个维度,否则在极端情况下会有很大的延时。
下面再分别详细讲下这两种的实现方式。
-
Punctuated Watermark
AssignerWithPunctuatedWatermarks 接口中包含了 checkAndGetNextWatermark 方法,这个方法会在每次 extractTimestamp() 方法被调用后调用,它可以决定是否要生成一个新的水印,返回的水印只有在不为 null 并且时间戳要大于先前返回的水印时间戳的时候才会发送出去,如果返回的水印是 null 或者返回的水印时间戳比之前的小则不会生成新的水印。public class WordPunctuatedWatermark implements AssignerWithPunctuatedWatermarks<Word> { @Nullable @Override public Watermark checkAndGetNextWatermark(Word lastElement, long extractedTimestamp) { return extractedTimestamp % 3 == 0 ? new Watermark(extractedTimestamp) : null; } @Override public long extractTimestamp(Word element, long previousElementTimestamp) { return element.getTimestamp(); } }需要注意的是这种情况下可以为每个事件都生成一个水印,但是因为水印是要在下游参与计算的,所以过多的话会导致整体计算性能下降。
-
Periodic Watermark
public class WordWatermark implements AssignerWithPeriodicWatermarks<Word> { private long currentTimestamp = Long.MIN_VALUE; @Override public long extractTimestamp(Word word, long previousElementTimestamp) { if (word.getTimestamp() > currentTimestamp) { this.currentTimestamp = word.getTimestamp(); } return currentTimestamp; } @Nullable @Override public Watermark getCurrentWatermark() { long maxTimeLag = 5000; return new Watermark(currentTimestamp == Long.MIN_VALUE ? Long.MIN_VALUE : currentTimestamp - maxTimeLag); } }在这个类中,有两个方法 extractTimestamp() 和 getCurrentWatermark()。extractTimestamp() 方法是从数据本身中提取 Event Time,该方法会返回当前时间戳与事件时间进行比较,如果事件的时间戳比 currentTimestamp 大的话,那么就将当前事件的时间戳赋值给 currentTimestamp。getCurrentWatermark() 方法是获取当前的水位线,这里有个 maxTimeLag 参数代表数据能够延迟的时间,上面代码中定义的 long maxTimeLag = 5000; 表示最大允许数据延迟时间为 5s,超过 5s 的话如果还来了之前早的数据,那么 Flink 就会丢弃了,因为 Flink 的窗口中的数据是要触发的,不可能一直在等着这些迟到的数据(由于网络的问题数据可能一直没发上来)而不让窗口触发结束进行计算操作。
通过定义这个时间,可以避免部分数据因为网络或者其他的问题导致不能够及时上传从而不把这些事件数据作为计算的,那么如果在这延迟之后还有更早的数据到来的话,那么 Flink 就会丢弃了,所以合理的设置这个允许延迟的时间也是一门细活,得观察生产环境数据的采集到消息队列再到 Flink 整个流程是否会出现延迟,统计平均延迟大概会在什么范围内波动。这也就是说明了一个事实那就是 Flink 中设计这个水印的根本目的是来解决部分数据乱序或者数据延迟的问题,而不能真正做到彻底解决这个问题,不过这一特性在相比于其他的流处理框架已经算是非常给力了。
AssignerWithPeriodicWatermarks 这个接口有四个实现类,分别如下图:
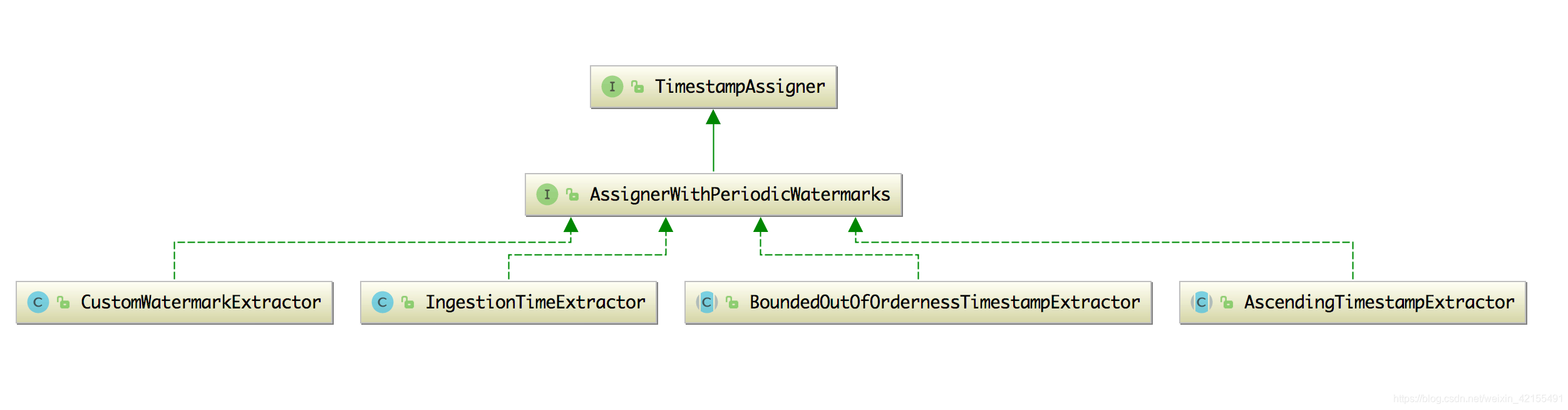 如果你使用周期性水印的话,可以直接自定义水印生成器,实现BoundedOutOfOrdernessTimestampExtractor类,你可以传入一个时间代表着可以允许数据延迟到来的时间是多长。跟我们自己写的类一个意思。
如果你使用周期性水印的话,可以直接自定义水印生成器,实现BoundedOutOfOrdernessTimestampExtractor类,你可以传入一个时间代表着可以允许数据延迟到来的时间是多长。跟我们自己写的类一个意思。
比如按照下面这样使用:
//Time.seconds(10) 代表允许延迟的时间大小
dataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Event>(Time.seconds(10)) {
//重写 BoundedOutOfOrdernessTimestampExtractor 中的 extractTimestamp()抽象方法
@Override
public long extractTimestamp(Event event) {
return event.getTimestamp();
}
})
四、其他注意点:
使用这种方式周期性生成水印的话,你可以通过 env.getConfig().setAutoWatermarkInterval(…); 来设置生成水印的间隔(每隔 n 毫秒)。默认是200ms,可以见env.setStreamTimeCharacteristic(…)的源码:
@PublicEvolving
public void setStreamTimeCharacteristic(TimeCharacteristic characteristic) {
this.timeCharacteristic = Preconditions.checkNotNull(characteristic);
if (characteristic == TimeCharacteristic.ProcessingTime) {
getConfig().setAutoWatermarkInterval(0);
} else {
getConfig().setAutoWatermarkInterval(200);
}
}
这里明确说明了200ms
Watermark 与 Window 结合来处理延迟数据
其实在上文中已经提到的一点是在设置 Periodic Watermark 时,是允许提供一个参数,表示数据最大的延迟时间。其实这个值要结合自己的业务以及数据的情况来设置,如果该值设置的太小会导致数据因为网络或者其他的原因从而导致乱序或者延迟的数据太多,那么最后窗口触发的时候,可能窗口里面的数据量很少,那么这样计算的结果很可能误差会很大,对于有的场景(要求正确性比较高)是不太符合需求的。但是如果该值设置的太大,那么就会导致很多窗口一直在等待延迟的数据,从而一直不触发,这样首先就会导致数据的实时性降低,另外将这么多窗口的数据存在内存中,也会增加作业的内存消耗,从而可能会导致作业发生 OOM 的问题。
综上建议:
- 合理设置允许数据最大延迟时间
- 不太依赖事件时间的场景就不要设置时间策略为 EventTime
五、延迟数据该如何处理(三种方法)
-
丢弃(默认)
在 Flink 中,对这么延迟数据的默认处理方式是丢弃。 -
allowedLateness 再次指定允许数据延迟的时间
allowedLateness 表示允许数据延迟的时间,这个方法是在 WindowedStream 中的,用来设置允许窗口数据延迟的时间,超过这个时间的元素就会被丢弃,这个的默认值是 0,该设置仅针对于以事件时间开的窗口。
该允许延迟的时间是在 Watermark 允许延迟的基础上增加的时间。
那么具体该如何使用 allowedLateness 呢。dataStream.assignTimestampsAndWatermarks(new TestWatermarkAssigner()) .keyBy(new TestKeySelector()) .timeWindow(Time.milliseconds(1), Time.milliseconds(1)) .allowedLateness(Time.milliseconds(2)) //表示允许再次延迟 2 毫秒 .apply(new WindowFunction<Integer, String, Integer, TimeWindow>() { //计算逻辑 }); -
sideOutputLateData 收集迟到的数据
sideOutputLateData 这个方法同样是 WindowedStream 中的方法,该方法会将延迟的数据发送到给定 OutputTag 的 side output 中去,然后你可以通过
SingleOutputStreamOperator.getSideOutput(OutputTag)来获取这些延迟的数据。具体的操作方法如下://定义 OutputTag OutputTag<Integer> lateDataTag = new OutputTag<Integer>("late"){}; SingleOutputStreamOperator<String> windowOperator = dataStream .assignTimestampsAndWatermarks(new TestWatermarkAssigner()) .keyBy(new TestKeySelector()) .timeWindow(Time.milliseconds(1), Time.milliseconds(1)) .allowedLateness(Time.milliseconds(2)) .sideOutputLateData(lateDataTag) //指定 OutputTag .apply(new WindowFunction<Integer, String, Integer, TimeWindow>() { //计算逻辑 }); windowOperator.addSink(resultSink); //通过指定的 OutputTag 从 Side Output 中获取到延迟的数据之后,你可以通过 addSink() 方法存储下来,这样可以方便你后面去排查哪些数据是延迟的。 windowOperator.getSideOutput(lateDataTag) .addSink(lateResultSink);
