前言
对于刚入门爬虫的小白来说,对于动态加载网页很是头疼,动态加载是各大网站最基础的一种反扒手段,今天就以百度图片爬取为例,带大家感受一下动态爬虫的关键所在,也就是Ajax请求抓包分析,本文仅供参考学习使用!
以下文章来源于Python代码大全,作者 Python代码狂人
Python爬虫、数据分析、网站开发等案例教程视频免费在线观看
https://space.bilibili.com/523606542 Python学习交流群:1039649593
1.抓取目标:
百度NBA图片
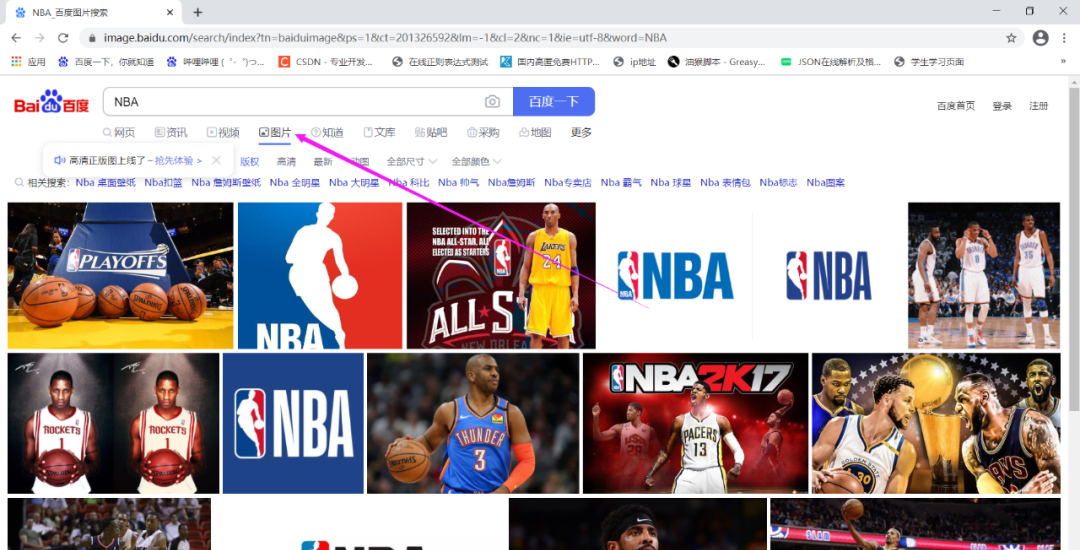
2.抓取结果
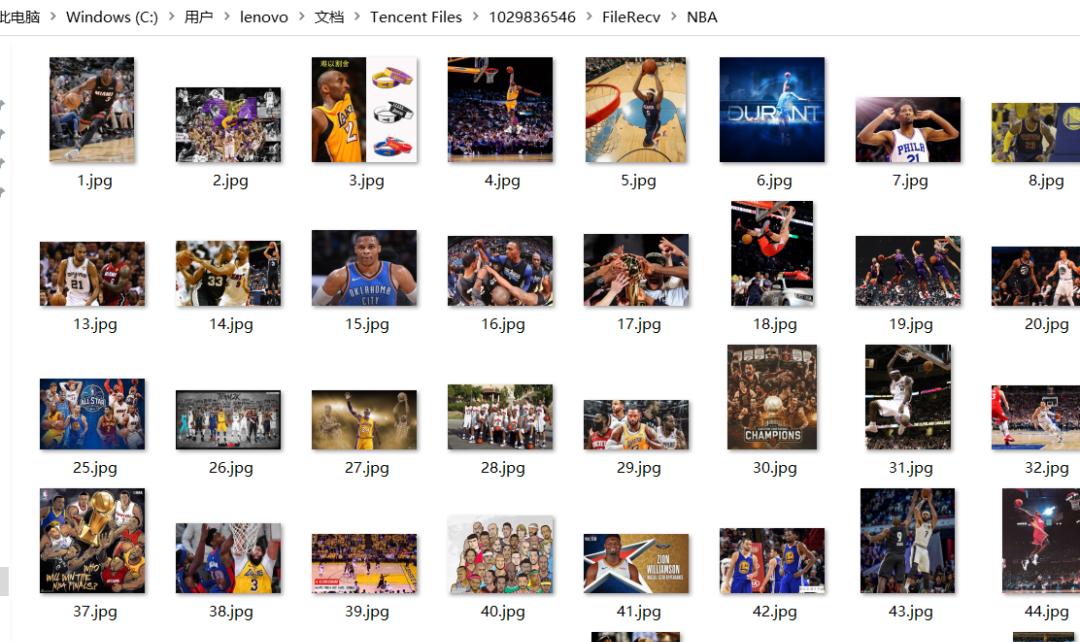
3.详细步骤分析
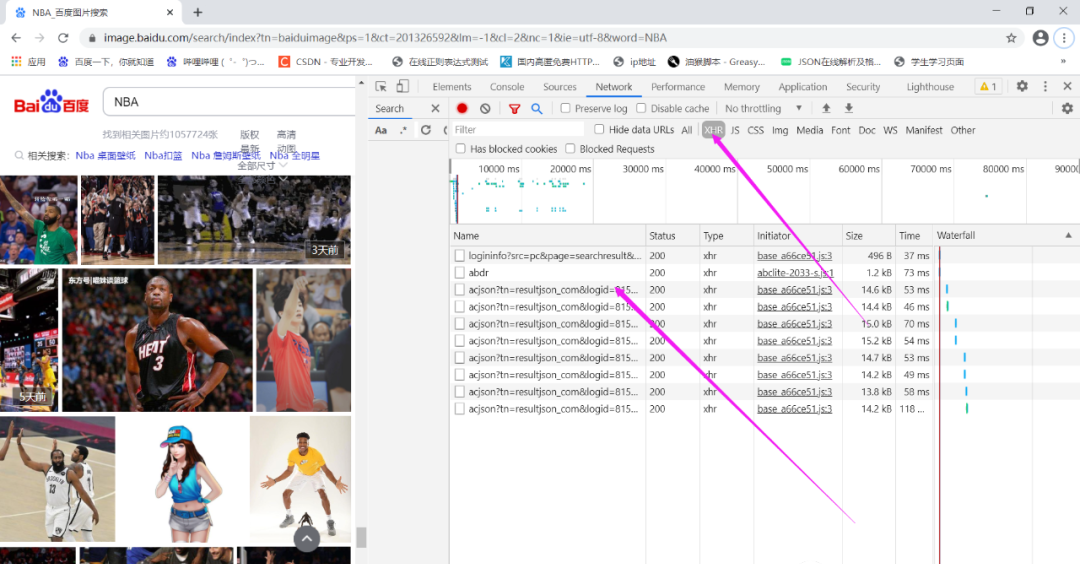
(1)对于分析是不是动态加载关键所在就是当滚动鼠标滑轮的时候,观察XHR里面的包有没有变化,如果说这里面包的数量有所更新,该页面就极有可能是动态请求,经分析的百度图片为动态加载。
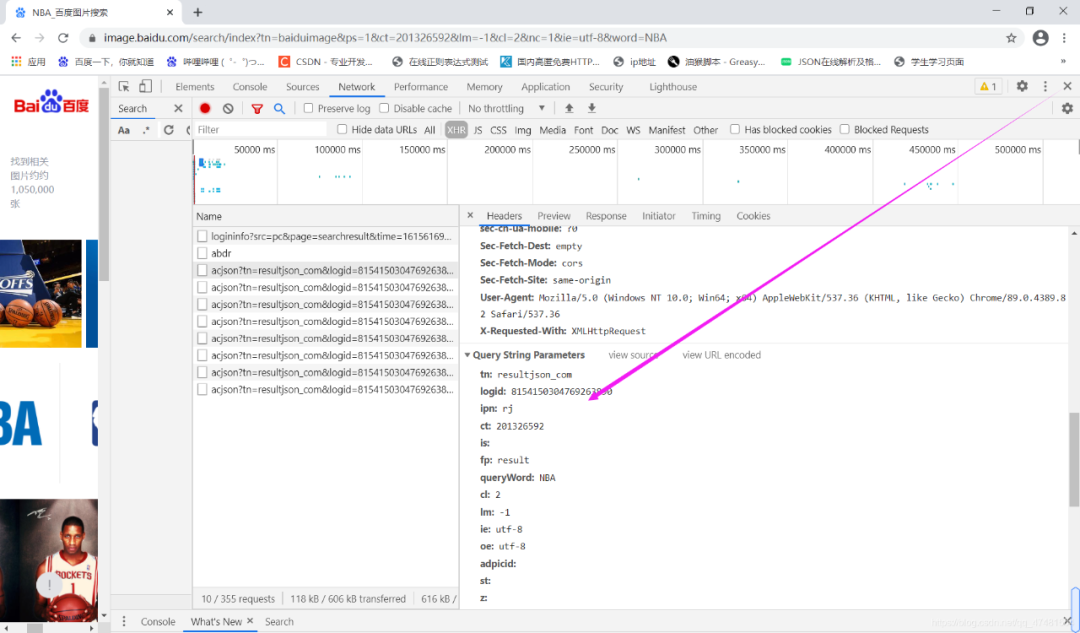
(2)找到动态加载包之后,我们分析该包的请求,其难点就是对查询参数的分析,在这里我建议大家至少找两组关键字进行对比,找出不同包的关键字区别,看出其变化规律(那棵树偷偷提醒一下大家,去寻找一个名为pn的查询参数)整个的动态其实都是他一人在操控。找到包之后进行request请求,在进行数据解析提取出图片url就OK了。(对于图片一定要写入二进制哦!)
4.完整源代码
本次抓取需要用的工具包requests和json
import requests as rq
import json
import time
import os
count = 1
def crawl(page):
global count
if not os.path.exists('E://桌面/NBA'):
os.mkdir('E://桌面/NBA')
url = 'https://image.baidu.com/search/acjson?'
header = {
# 'Referer': 'https://image.baidu.com/search/index?ct=201326592&cl=2&st=-1&lm=-1&nc=1&ie=utf-8&tn=baiduimage&ipn=r&rps=1&pv=&fm=rs4&word',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'
}
param = {
"tn": "resultjson_com",
"logid": "11007362803069082764",
"ipn": "rj",
"ct": "201326592",
"is": "",
"fp": "result",
"queryWord": "NBA",
"cl": "2",
"lm": "-1",
"ie": "utf-8",
"oe": "utf-8",
"adpicid": "",
"st": "-1",
"z": "",
"ic": "",
"hd": "",
"latest": "",
"copyright": "",
"word": "NBA",
"s": "",
"se": "",
"tab": "",
"width": "",
"height": "",
"face": "0",
"istype": "2",
"qc": "",
"nc": "1",
"fr": "",
"expermode": "",
"force": "",
"pn": page,
"rn": "30",
"gsm": "1e",
"1615565977798": "",
}
response = rq.get(url, headers=header, params=param)
result = response.text
# print(response.status_code)
j = json.loads(result)
# print(j)
img_list = []
for i in j['data']:
if 'thumbURL' in i:
# print(i['thumbURL'])
img_list.append(i['thumbURL'])
# print(len(img_list))
for n in img_list:
r = rq.get(n, headers=header)
with open(f'E://桌面/NBA/{count}.jpg', 'wb') as f:
f.write(r.content)
count += 1
if __name__ == '__main__':
for i in range(30, 601, 30):
t1 = time.time()
crawl(i)
t2 = time.time()
t = t2 - t1
print('page {0} is over!!! 耗时{1:.2f}秒!'.format(i//30, t))