新人上路, 老司机们请多多关照, 写的不好的地方, 还请多指教.

在很久很久以前, 我是一个苦逼的90后挨踢空穴老人, 一个人的夜里可是什么事都能干得出来! 这不, 我用我的把老师的图片给抓了过来…
言归正传, 本文介绍如何爬百度图片(滑稽.jpg):
- 输入想要抓取的图片的关键字, 如”苍老师”, 然后输出百度图片搜索苍老师的所有图片
- 采用翻页模式进行爬取
1. 分析网页结构
在浏览器中访问上述网址, 得到如下页面:
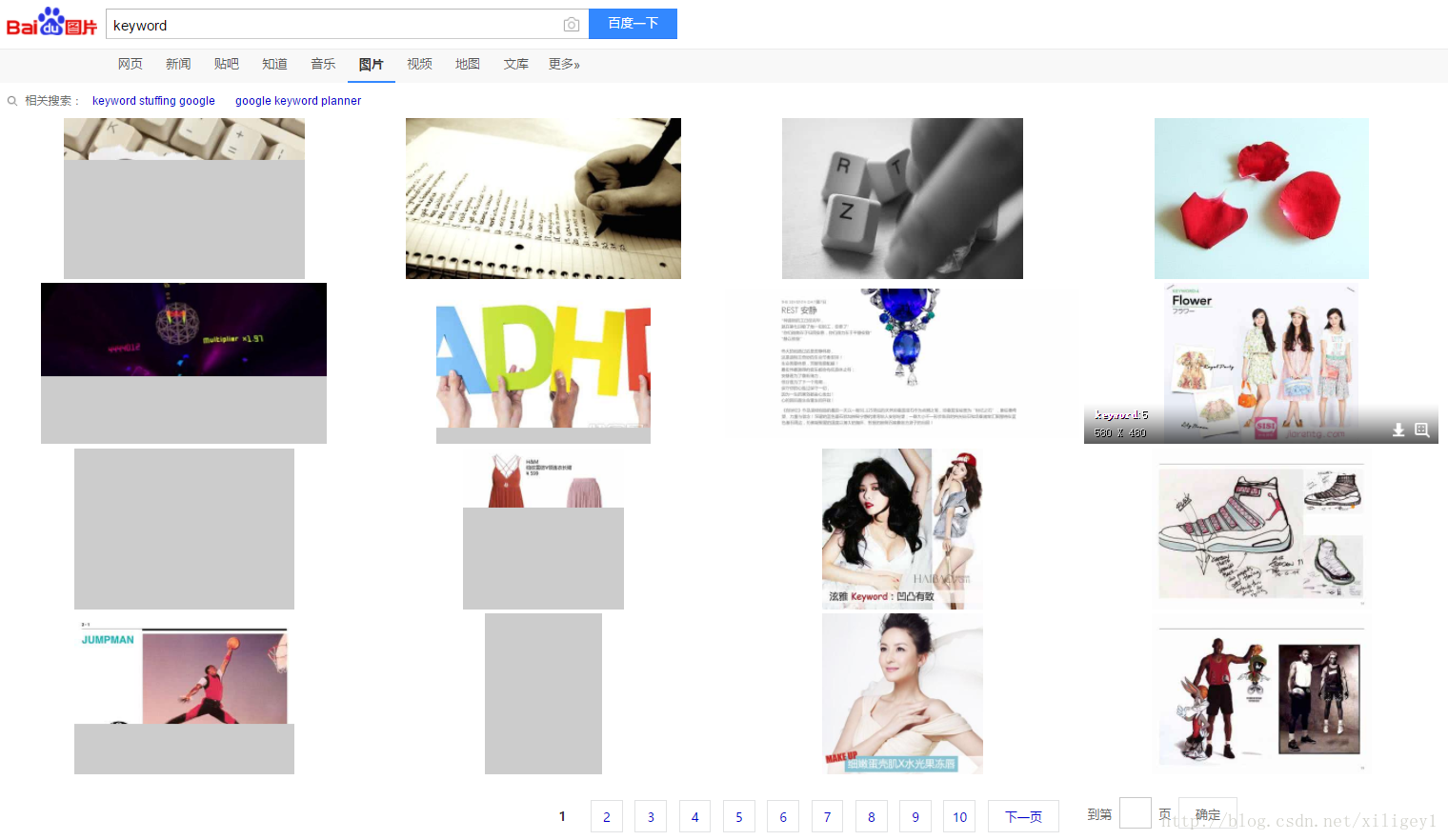
可以看到, 图片是以翻页的形式展现的. 其次, 搜索词”keyword”即为网址最后的word的值. 所以, 如果你想搜什么, 就把”word=”后面的keyword改成对应的词即可, 如”苍老师”(滑稽.jpg)
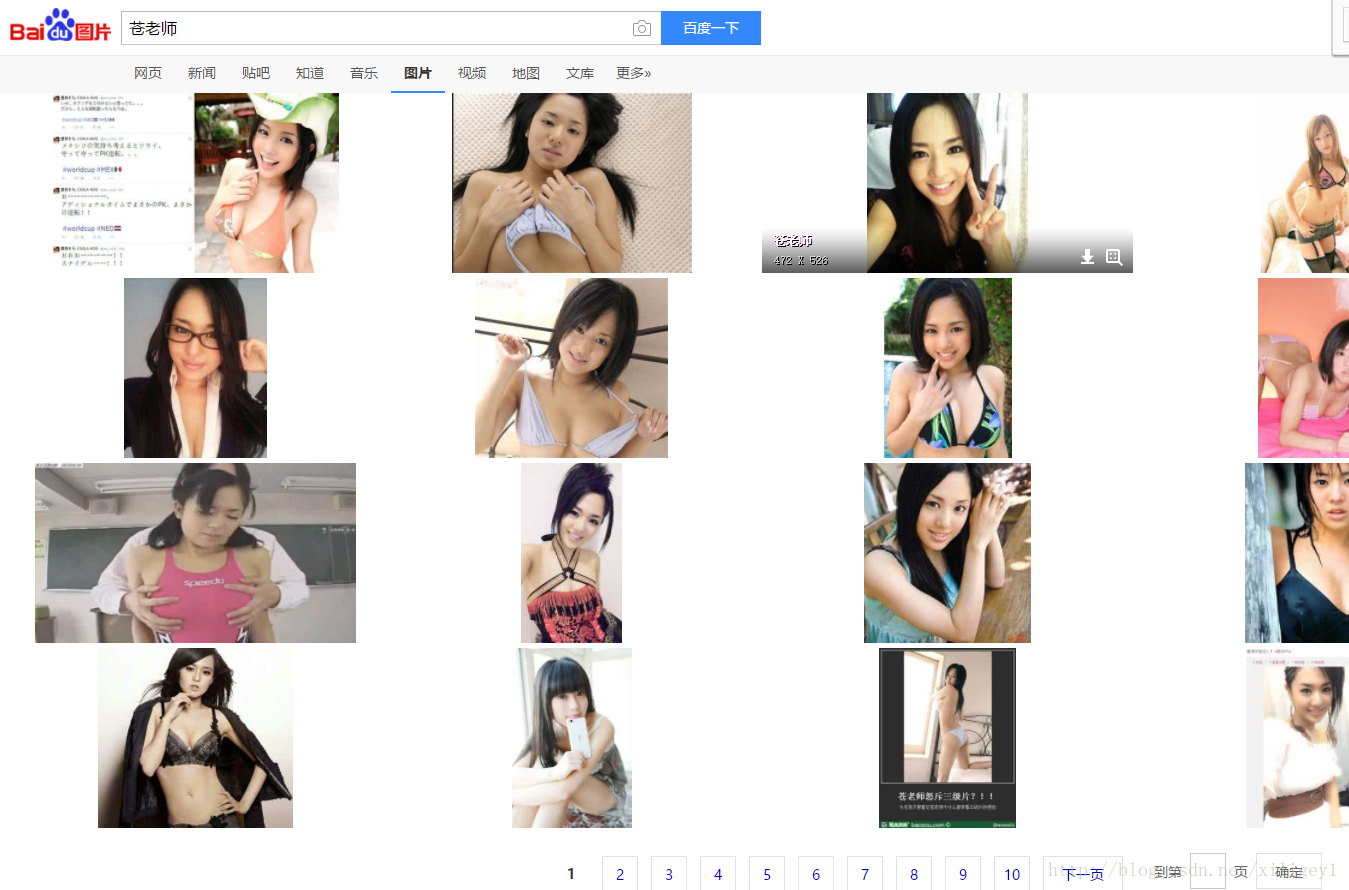
然后看看这个网址是不是和我们之前设想的一样(即keyword=苍老师).
复制过来一看
http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1497576995049_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1497576995049%5E00_1519X735&word=%E8%8B%8D%E8%80%81%E5%B8%88
感觉不对劲, 我要的是”苍老师”, “%E8%8B%8D%E8%80%81%E5%B8%88”是什么鬼?!

原来, 还需要一顿操作:
>>>import urllib
>>>keyword="苍老师"
>>>keyword=urllib.quote(keyword)
>>>keyword
'%E8%8B%8D%E8%80%81%E5%B8%88'
- 1
- 2
- 3
- 4
- 5
现在, 就可以拼接网页了: ....(一大堆) + keyword="你想搜索的关键词"
2. 获取当前页的所有图片的链接
右键查看网页源代码之后, 发现:

图片的网址都是这样的格式: "objURL":"网址", 那就好办了, 直接用正则表达式就能解决
import re
pattern_pic = '"objURL":"(.*?)",'
# 这里的html就是网页的源代码的内容, 此处不介绍, 稍后给出
pic_list = re.findall(pattern_pic, html, re.S) # 存储当前页的所有苍老师的图片的url的列表
- 1
- 2
- 3
- 4
3. 获取当前页的下一页的链接
下一页的链接同理根据正则得出:
pattern_fanye = '<a href="(.*)" class="n">下一页</a>'
fanye_url = re.findall(pattern_fanye, html)[0] # 下一页的链接
- 1
- 2
4. 获取所有页的图片的链接
上面已经根据当前页的url得到了当前页的所有图片的链接, 以及下一页的url.
如此, 循环下去, 即可得到每一页的所有图片的链接.
all_pic_list = [] # 存储所有翻页的所有图片的链接的列表
while 1:
all_pic_list.extend(pic_list)
if 循环完所有翻页:
break
- 1
- 2
- 3
- 4
- 5
5.下载图片
已知了图片链接, 直接下载即可
for i, pic_url in enumerate(all_pic_list):
pic = requests.get(pic_url)
string = str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
- 1
- 2
- 3
- 4
- 5
6.源代码
# coding=utf-8
"""根据搜索词下载百度图片"""
import re
import sys
import urllib
import requests
def get_onepage_urls(onepageurl):
"""获取单个翻页的所有图片的urls+当前翻页的下一翻页的url"""
if not onepageurl:
print('已到最后一页, 结束')
return [], ''
try:
html = requests.get(onepageurl).text
except Exception as e:
print(e)
pic_urls = []
fanye_url = ''
return pic_urls, fanye_url
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
fanye_urls = re.findall(re.compile(r'<a href="(.*)" class="n">下一页</a>'), html, flags=0)
fanye_url = 'http://image.baidu.com' + fanye_urls[0] if fanye_urls else ''
return pic_urls, fanye_url
def down_pic(pic_urls):
"""给出图片链接列表, 下载所有图片"""
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
if __name__ == '__main__':
keyword = '苍老师' # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样
url_init_first = r'http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1497491098685_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1497491098685%5E00_1519X735&word='
url_init = url_init_first + urllib.quote(keyword, safe='/')
all_pic_urls = []
onepage_urls, fanye_url = get_onepage_urls(url_init)
all_pic_urls.extend(onepage_urls)
fanye_count = 0 # 累计翻页数
while 1:
onepage_urls, fanye_url = get_onepage_urls(fanye_url)
fanye_count += 1
print('第%s页' % fanye_count)
if fanye_url == '' and onepage_urls == []:
break
all_pic_urls.extend(onepage_urls)
down_pic(list(set(all_pic_urls)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/markdown_views-ea0013b516.css">
</div>
新人上路, 老司机们请多多关照, 写的不好的地方, 还请多指教.
在很久很久以前, 我是一个苦逼的90后挨踢空穴老人, 一个人的夜里可是什么事都能干得出来! 这不, 我用我的把老师的图片给抓了过来…
言归正传, 本文介绍如何爬百度图片(滑稽.jpg):
- 输入想要抓取的图片的关键字, 如”苍老师”, 然后输出百度图片搜索苍老师的所有图片
- 采用翻页模式进行爬取
1. 分析网页结构
在浏览器中访问上述网址, 得到如下页面:
可以看到, 图片是以翻页的形式展现的. 其次, 搜索词”keyword”即为网址最后的word的值. 所以, 如果你想搜什么, 就把”word=”后面的keyword改成对应的词即可, 如”苍老师”(滑稽.jpg)
然后看看这个网址是不是和我们之前设想的一样(即keyword=苍老师).
复制过来一看
http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1497576995049_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1497576995049%5E00_1519X735&word=%E8%8B%8D%E8%80%81%E5%B8%88
感觉不对劲, 我要的是”苍老师”, “%E8%8B%8D%E8%80%81%E5%B8%88”是什么鬼?!
原来, 还需要一顿操作:
>>>import urllib
>>>keyword="苍老师"
>>>keyword=urllib.quote(keyword)
>>>keyword
'%E8%8B%8D%E8%80%81%E5%B8%88'
- 1
- 2
- 3
- 4
- 5
现在, 就可以拼接网页了: ....(一大堆) + keyword="你想搜索的关键词"
2. 获取当前页的所有图片的链接
右键查看网页源代码之后, 发现:
图片的网址都是这样的格式: "objURL":"网址", 那就好办了, 直接用正则表达式就能解决
import re
pattern_pic = '"objURL":"(.*?)",'
# 这里的html就是网页的源代码的内容, 此处不介绍, 稍后给出
pic_list = re.findall(pattern_pic, html, re.S) # 存储当前页的所有苍老师的图片的url的列表
- 1
- 2
- 3
- 4
3. 获取当前页的下一页的链接
下一页的链接同理根据正则得出:
pattern_fanye = '<a href="(.*)" class="n">下一页</a>'
fanye_url = re.findall(pattern_fanye, html)[0] # 下一页的链接
- 1
- 2
4. 获取所有页的图片的链接
上面已经根据当前页的url得到了当前页的所有图片的链接, 以及下一页的url.
如此, 循环下去, 即可得到每一页的所有图片的链接.
all_pic_list = [] # 存储所有翻页的所有图片的链接的列表
while 1:
all_pic_list.extend(pic_list)
if 循环完所有翻页:
break
- 1
- 2
- 3
- 4
- 5
5.下载图片
已知了图片链接, 直接下载即可
for i, pic_url in enumerate(all_pic_list):
pic = requests.get(pic_url)
string = str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
- 1
- 2
- 3
- 4
- 5
6.源代码
# coding=utf-8
"""根据搜索词下载百度图片"""
import re
import sys
import urllib
import requests
def get_onepage_urls(onepageurl):
"""获取单个翻页的所有图片的urls+当前翻页的下一翻页的url"""
if not onepageurl:
print('已到最后一页, 结束')
return [], ''
try:
html = requests.get(onepageurl).text
except Exception as e:
print(e)
pic_urls = []
fanye_url = ''
return pic_urls, fanye_url
pic_urls = re.findall('"objURL":"(.*?)",', html, re.S)
fanye_urls = re.findall(re.compile(r'<a href="(.*)" class="n">下一页</a>'), html, flags=0)
fanye_url = 'http://image.baidu.com' + fanye_urls[0] if fanye_urls else ''
return pic_urls, fanye_url
def down_pic(pic_urls):
"""给出图片链接列表, 下载所有图片"""
for i, pic_url in enumerate(pic_urls):
try:
pic = requests.get(pic_url, timeout=15)
string = str(i + 1) + '.jpg'
with open(string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(i + 1), str(pic_url)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(i + 1), str(pic_url)))
print(e)
continue
if __name__ == '__main__':
keyword = '苍老师' # 关键词, 改为你想输入的词即可, 相当于在百度图片里搜索一样
url_init_first = r'http://image.baidu.com/search/flip?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1497491098685_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1497491098685%5E00_1519X735&word='
url_init = url_init_first + urllib.quote(keyword, safe='/')
all_pic_urls = []
onepage_urls, fanye_url = get_onepage_urls(url_init)
all_pic_urls.extend(onepage_urls)
fanye_count = 0 # 累计翻页数
while 1:
onepage_urls, fanye_url = get_onepage_urls(fanye_url)
fanye_count += 1
print('第%s页' % fanye_count)
if fanye_url == '' and onepage_urls == []:
break
all_pic_urls.extend(onepage_urls)
down_pic(list(set(all_pic_urls)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/markdown_views-ea0013b516.css">
</div>