数据介绍: 数据为某路口的交通流量监测数据,记录全年小时级别的车流量。
实验目的: 根据已有的数据创建多项式特征,使用岭回归模型代替一般的线性模型,对车流量的信息进行多项式回归。
(本节内容数据见电脑”F:\python数据\test5“或腾讯微云文件”python数据\test5“)
import numpy as np
import pandas as pd
from sklearn.linear_model import Ridge #加载岭回归方法
from sklearn import model_selection #加载交叉验证模块
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
a=pd.read_csv('F:/python数据/test5.csv')
data=np.array(a)
'''
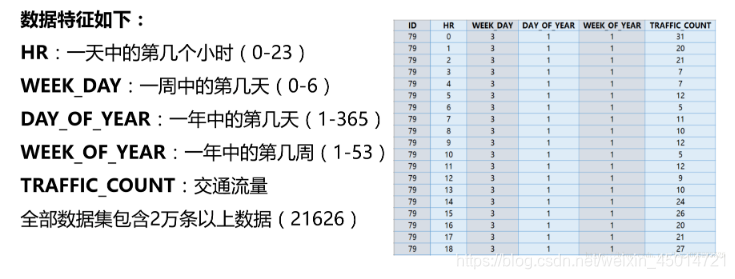
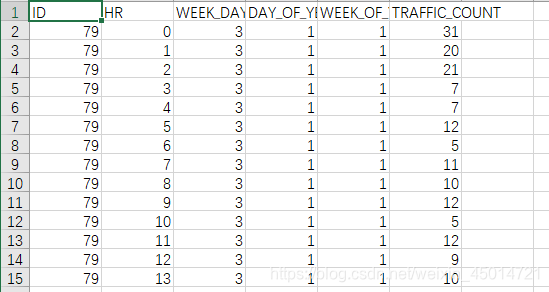
data的样子是:
[[ 79 0 3 1 1 31]
[ 79 1 3 1 1 20]
...
[ 79 22 4 365 53 44]
[ 79 23 4 365 53 32]]
'''
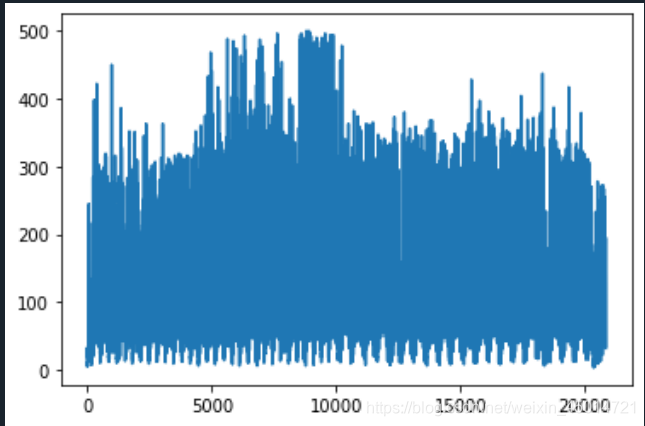
#使用plt展示车流量信息
plt.plot(data[:,5])
plt.show()
#X用于保存0-5维数据,即属性
X=data[:,:5]
#y用于保存第6维数据,即车流量
y=data[:,5]
#用于创建最高次数6次方的的多项式特征,多次试验后决定采用6次
poly =PolynomialFeatures(6)
X=poly.fit_transform(X)
train_set_X,test_set_X,train_set_y,test_set_y=model_selection.train_test_split(X,y,test_size=0.3,random_state=0) #random_state是随机数种子
#创建回归器,并进行训练
clf =Ridge(alpha=1.0,fit_intercept=True)
clf.fit(train_set_X,train_set_y)
clf.score(test_set_X,test_set_y)
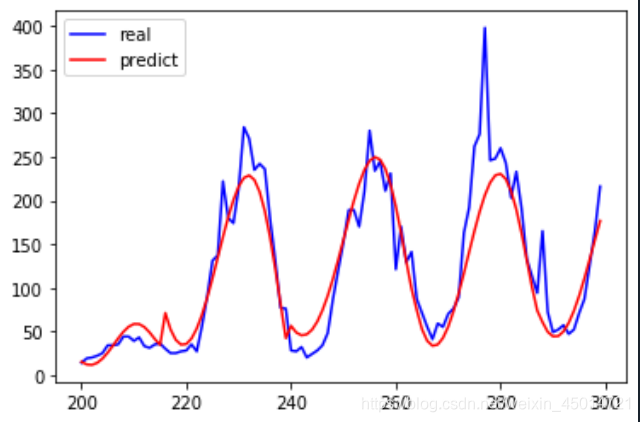
#利用测试集计算回归曲线的拟合优度,clf.score返回值为0.7375拟合优度,
# 用于评价拟合好坏,最大为1,无最小值。
start =200 #花一段200到300范围内的拟合曲线
end =300
y_pre =clf.predict(X) #是调用predict函数的拟合值
time =np.arange(start,end)
plt.plot(time,y[start:end],'b',label="real")
plt.plot(time,y_pre[start:end],'r',label='predict')
plt.legend(loc='upper left')
plt.show()