前言:第二节课主要讲了三点,切片、字符串、生成器。感觉在实际运用中很重要,起初看深度学习的教程时,一直看不懂生成器和切片的用法。
【注:上下的大标题不太一样,文章的大标题是因为百度课程的命名要求,和为了方便搜索。下面正文的大标题是这份笔记的实在标题】
目录
《百度飞桨领航团零基础Python速成营》 课程笔记 —— 02
笔记依据 / 老师讲义:
课节2: Python编程基础
https://aistudio.baidu.com/aistudio/projectdetail/1520159
一、专业术语:切片
- 切片的语法:[起始:结束:步长] 。注意,起始位是包括的,而结束位是不包括的;
- 这三个参数都有默认值,默认截取方向是从左往右;如果切片步长是负值,截取方向则是从右往左的;
- start:默认值为0; end : 默认值未字符串结尾元素; step : 默认值为1;
# 字符串的切片
string = 'Hello world!'
string[8:2:-1]
# 输出:'row ol'
# 列表的切片
list1 = ['a','b','c','d','e','f']
list1[2:5]
# 输出:['c', 'd', 'e']
#同理可以作用在元组,但不能用于集合,因为'set'对象不可下标
set1= ('a','b','c','d','e','f')
set1[2:5]
# 输出:('c', 'd', 'e')
#注意:集合和字典都不可以切片!
二、字符串的格式化输出
- 昨天简单简述了一下打印输出,今天详细的介绍了几种
Python输出的方式。其中最被程序员受用的为f-string,可读性最好。
1)直接输出
accuracy = 80/123
# C语言这样写不会报错(前提 accuracy 是字符串),但是会没有效果,只能输出第一个字符串。不能同时输出多个字符串。
print('老板!我的模型正确率是', accuracy,'!')
# 输出:老板!我的模型正确率是 0.6504065040650406 !
accuracy = "80/133"
# 加号合并,中间没有空格,但是只能合并字符串。
print('老板!我的模型正确率是'+accuracy+'!')
# 输出:老板!我的模型正确率是80/133!
2)%
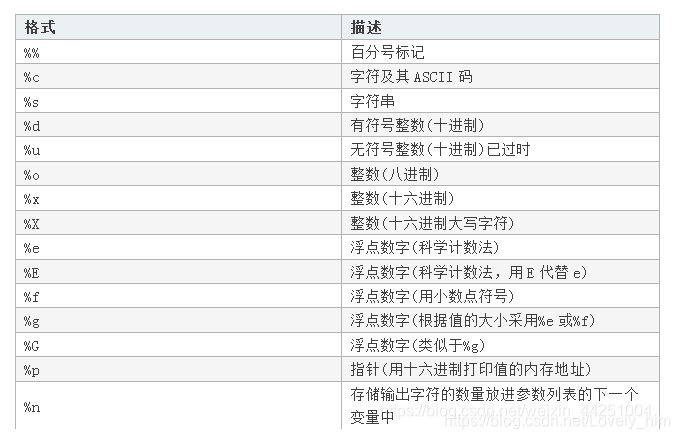
# Python下的
name = 'Molly'
hight = 170.4
score_math = 95
score_english = 89
print('大家好!我叫%s,我的身高是%d cm, 数学成绩%.2f分,英语成绩%d分' % (name, hight, score_math, score_english))
# 输出:大家好!我叫Molly,我的身高是170 cm, 数学成绩95.00分,英语成绩89分
// C#下的,对比一下,字符串只能双引号表示。且有些输出字符不同。
char name[] = "Molly";
const double hight = 170.4;
int score_math = 95;
int score_english = 89;
printf("大家好!我叫%s,我的身高是%f cm, 数学成绩%d分,英语成绩%d分" , name, hight, score_math, score_english);
// 输出:大家好!我叫Molly,我的身高是170.400000 cm, 数学成绩95分,英语成绩89分
3)format
"""
指定了 :s ,则只能传字符串值,如果传其他类型值不会自动转换
当你不指定类型时,你传任何类型都能成功,如无特殊必要,可以不用指定类型
"""
name = 'Molly'
hight = 170.4
score_math = 95
score_english = 89
print('大家好!我叫{},我的身高是{:d} cm, 数学成绩{:.2f}分,英语成绩{}分'.format(name, int(hight), score_math, score_english))
# 输出:大家好!我叫Molly,我的身高是170 cm, 数学成绩95.00分,英语成绩89分
# 可以指定填入的顺序与位置,注意,一个变量可以输出多次或甚至不输出也可以。
'Hello, {0}, 成绩提升了{2:.1f}分,百分比为 {1:.1f}%, 再来个是为了作对比{1:}'\
.format('小明', 6, 17.523)
# 输出:'Hello, 小明, 成绩提升了17.5分,百分比为 6.0%, 再来个是为了作对比6'
# 如果采用这种方式,建议这样写:
print('Hello, {name:}, 成绩提升了{score:.1f}分,百分比为 {percent:.1f}%'\
.format(name='小明',
score=6,
percent = 17.523))
# 输出:Hello, 小明, 成绩提升了6.0分,百分比为 17.5%
4) f-string
- 一种可读性更好的方法(** python3.6版本新加入的形式)
# 最喜欢这个,直接调用已有变量,不用再填来填去了
name = 'Molly'
hight = 170.4
score_math = 95
score_english = 89
print(f"大家好!我叫{name},我的身高是{hight:.3f} cm, 数学成绩{score_math}分,英语成绩{score_english}分")
# 输出:大家好!我叫Molly,我的身高是170.400 cm, 数学成绩95分,英语成绩89分
三、字符串对象的各种内置方法
1)String1.endswith(String2) - 查询结尾
# 如果字符串以'pr'结尾,则打印
list_string = ['apple','banana_pr','orange','cherry_pr']
for fruit in list_string:
if fruit.endswith('pr'):
print(fruit)
# 输出:
# banana_pr
# cherry_pr
2)String1.count(String2) - 计数功能
# String2不需要单独独立,只有含有即算
my_string = 'hello_world'
my_string.count('o')
# 输出:
# 2
3)String1.find(String2) - 查找功能
# 返回从左第一个指定字符的索引,找不到返回-1
my_string = 'hello_world'
my_string.find('o')
# 输出:
# 4
4)String1.index(String2) - 查找,找不到就报错
# 和 find 效果差不多,只是找不到时会报错,而不是返回-1
my_string = 'hello_world'
my_string.index('o')
# 输出:4
# 巧用 in 语法,也有类似效果,找不到返回flase,,否则返回true。
"o" in my_string
5)String1.split (String2) - 字符串的拆分
# 按照指定的内容进行分割
my_string = 'hello_world'
my_string.split('_')
# 输出:['hello', 'world']
6)String1.replace(String2) - 字符串的替换
# 从左到右替换指定的元素,可以指定替换的个数,默认全部替换
my_string = 'hello_world'
# 注意,返回值才是替换后的,不重新赋值的话,原字符串不会改变。其他部分方法也是同理。
my_string = my_string.replace('_',' ',1)
# 输出:'hello world'
7)String1.strip(String2) - 字符串标准化
# 默认去除两边的空格、换行符之类的,去除内容可以指定(常用于去掉开头空格和末尾换行符)
my_string = ' hello world\n'
my_string.strip()
# 输出:'hello world'
8)String1.upper/ lower/ capitalize(String2) - 字符串的变形
# 分别对应,全大写、全小写、首字母大写功能
my_string = 'hello_World'
my_string.upper()
# 输出:'HELLO_WORLD'
my_string.lower()
# 输出:'hello_world'
my_string.capitalize() # 注意,除了首字母外其他都会变小写。
# 输出:'Hello_world'
四、列表对象的各种内置方法
- 这部分就懒得列代码了(太长了),参照上一节类推。
1)list1.append(x) - 在末尾添加元素
2)list1.insert(n,x) - 在指定位置添加元素
- 如果指定的下标不存在,那么就是在末尾添加
3)list1.extend(n,list2) - 合并两个list
- list2中仍有元素,不受影响
4)list1.count(x) - 返回计数
5)list1.index(x) - 查找
- 返回查找的第一个元素的下标
6)list1.pop(n) - 弹出
- 弹出指定下标的元素(list1被改变)(记住,填的是下标)
7)list1.remove(x) - 删除元素
- 删除指定的元素,记住,填的是元素,不是下标。(除非下标和元素值一样)
四点五、字典,集合,元组对象的各种内置方法
1)百度或菜鸟教程(略)
- 这里不啰嗦赘述了。
菜鸟教程 - 集合
https://www.runoob.com/python3/python3-set.html
五、专业术语:列表生成式
- 一种Python的独有语法,直接看代码,清晰明了。还能生成字符串!
1)列表每一项+1
list_1 = [1,2,3,4,5]
# pythonic的方法 完全等效但是非常简洁
[n+1 for n in list_1]
# 输出:[2, 3, 4, 5, 6]
# 1-10之间所有数的平方
[(n+1)**2 for n in range(10)]
# 输出:[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
# 1-10之间所有数的平方 构成的字符串列表
[str((n+1)**2) for n in range(10)]
# 输出:['1', '4', '9', '16', '25', '36', '49', '64', '81', '100']
list1 = ['a','b','a','d','a','f']
['app_%s'%n for n in range(10)]
[f'app_{n}' for n in range(10)] # 或这种表达也可以
"""
输出:
['app_0',
'app_1',
'app_2',
'app_3',
'app_4',
'app_5',
'app_6',
'app_7',
'app_8',
'app_9']
"""
2)列表中的每一个偶数项[过滤]
list_1 = [1,2,3,4,5]
[n for n in list_1 if n%2==0]
# 输出:[2, 4]
# 字符串中所有以'sv'结尾的
list_2 = ['a','b','c_sv','d','e_sv']
[s for s in list_2 if s.endswith('sv')]
# 输出:['c_sv', 'e_sv']
# 取两个list的交集
list_A = [1,3,6,7,32,65,12]
list_B = [2,6,3,5,12]
[i for i in list_A if i in list_B]
# 输出:[3, 6, 12]
- 嵌套循环
#小练习 在list_A 但是不在list_B中
list_A = [1,3,6,7,32,65,12]
list_B = [2,6,3,5,12]
[m + n for m in 'ABC' for n in 'XYZ']
# 输出:['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
六、专业术语:生成器 - yield
- 通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
- 个人理解:生成器其实就是一个函数,这个函数具有列表生成器的功能。而且特点是,调用一次就输出一个值,没输出的值不会占用内容。拥有这种特殊功能的函数。
- 用途:在深度学习中经常用到,因为训练集过大,一次性读入太占内存,则会使用生成器,每训练n次才读n组数据。每次训练完再读取。所以非常重要。
1)第一种方法:类似列表生成式
""" 重点!!
如果用方括号,则代表“列表生成式”,
如果是圆括号,则代表可用next使用的生成器
"""
L = [x * x for x in range(10)]
g = (x * x for x in range(10))
next(g)
# 每次输出一个元素
2)第二种方法:基于函数
# 在IDE里面看得更清晰
def factor(max_num):
# 这是一个函数 用于输出所有小于max_num的质数
factor_list = []
n = 2
while n<max_num:
find = False
for f in factor_list:
# 先看看列表里面有没有能整除它的
if n % f == 0:
find = True
break
if not find:
factor_list.append(n)
yield n
n+=1
# 定义函数后创建对象,然后调用生成器,每次输出一个数
g = factor(10)
# 调用方式一
next(g)
# 调用方式二,在实战中常用,因为就是for循环训练的
for n in g:
print(n)
- 额外练习例子
# 练习 斐波那契数列
def feb(max_num):
n_1 = 1
n_2 = 1
n = 0
while n<max_num:
if n == 0 or n == 1:
yield 1
n += 1
else:
yield n_1 + n_2
new_n_2 = n_1
n_1 = n_1 + n_2
n_2 = new_n_2
n += 1
七、异常与错误处理
1) try / except
以下都是复制粘贴讲义的。有点长,可以看看其他教程,比如
Python3 错误和异常
https://www.runoob.com/python3/python3-errors-execptions.html
- 有的错误是程序编写有问题造成的,比如本来应该输出整数结果输出了字符串,这种错误我们通常称之为bug,bug是必须修复的。
- 有的错误是用户输入造成的,比如让用户输入email地址,结果得到一个空字符串,这种错误可以通过检查用户输入来做相应的处理。
- 异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。
- 一般情况下,在 Python 无法正常处理程序时就会发生一个异常。
- 异常是 Python 对象,表示一个错误。
- 当 Python 脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
# 语法要求
try:
<语句> #运行别的代码
except <名字>:
<语句> #如果在try部份引发了'名字'异常
except <名字>,<数据>:
<语句> #如果引发了'名字'异常,获得附加的数据
else:
<语句> #如果没有异常发生
finally:
<语句> #有没有异常都会执行
- try 的工作原理是,当开始一个 try 语句后,Python 就在当前程序的上下文中作标记,这样当异常出现时就可以回到这里,try 子句先执行,接下来会发生什么依赖于执行时是否出现异常。
- 如果当 try 后的语句执行时发生异常,Python 就跳回到 try 并执行第一个匹配该异常的 except 子句,异常处理完毕,控制流就通过整个 try 语句(除非在处理异常时又引发新的异常)。
- 如果在 try 后的语句里发生了异常,却没有匹配的 except 子句,异常将被递交到上层的 try,或者到程序的最上层(这样将结束程序,并打印缺省的出错信息)。
①单层运用
# 不用异常处理时的思维,把可能出现的异常都用if判断概括
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
if type(list1[i]) != int:
print('有异常发生')
continue
print(list1[i])
list1[i]+=1
# 使用异常处理后,程序总能超出意料范围,所以异常处理还是很有必要的。
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
try:
list1[i]+=1
print(list1[i])
except:
print('有异常发生')
# 两段程序都是输出:
"""
2
3
4
5
有异常发生
7
8
9
"""
- 还可以根据不同的异常类型而选择处理代码段,更多内容查详细教程,这里不列数了。
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
print(i)
try:
list1[i]+=1
print(list1)
except IOError as e:
print(e)
print('输入输出异常')
except:
print('有错误发生')
else:
print('正确执行')
finally:
print('我总是会被执行')
②多层运用 - 错误的层层传递
- 直接看代码,自行理解。其实就是一个函数一个try,然后几个函数,层层调用。
- (1)无检查写法
# 异常的层层处理
def worker(s):
# 这是一个函数 后面我们会详细介绍函数的定义和使用
return 10 / int(s)
def group_leader(s):
return worker(s) * 2
def CTO(s):
return group_leader(s)
CTO('0')
# 输出:报错
- (2)一个try下的情况。
# 异常的层层处理
def worker(s):
# 这是一个函数 后面我们会详细介绍函数如何定义的
try:
rst = 10 / int(s)
except ZeroDivisionError as e:
print(e)
rst = 10 / (float(s)+0.00001)
return rst
def group_leader(s):
return worker(s) * 2
def CTO(s):
return group_leader(s)
CTO('0')
# 输出:
"""
division by zero
1999999.9999999998
"""
CTO('user')
# 输出:报错
# 只有一个检测无法满足
- (3)多个try检测。
# 异常的层层处理
def worker(s):
# 这是一个函数 后面我们会详细介绍函数如何定义的
try:
rst = 10 / int(s)
except ZeroDivisionError as e:
print(e)
rst = 10 / (float(s)+0.00001)
return rst
def group_leader(s):
try:
rst = worker(s) * 2
except ValueError as e:
print(e)
rst = '请修改输入'
return rst
def CTO(s):
return group_leader(s)
CTO('user')
# 输出:
"""
invalid literal for int() with base 10: 'user'
'请修改输入'
"""
2)assert(断言)
- 这个在c语言也有,比较熟系。在python中,类似if判断,条件不成立时触发判断。嵌入式c语言中,条件不成立时会进入硬件中断卡死。
菜鸟教程 - Python3 assert(断言)
https://www.runoob.com/python3/python3-assert.html
# 检查用户的输入
def worker(s):
assert type(s)== int
assert s!=0
rst = 10 / int(s)
return rst
def group_leader(s):
try:
rst = worker(s) * 2
except AssertionError as e:
print('数据类型错误')
rst = -1
return rst
def CTO(s):
return group_leader(s)
CTO('user')
"""
数据类型错误
-1
"""
八、BUG的调试和记录
1)print大法
- 在c语言中我也贼喜欢用打印来调试,特别是在不能在线调试ide或是单片机上。
2)logging
- 日志。这个比较高级,而且涉及较多内容,主要是英语不好,不想看。
3)IDE
- (略)