说在前面
本实验是大三上机器学习课程中的实习二,现将报告内容转至CSDN。本实验中我按照开源代码,只用VGG网络实现了人脸颜值打分,对于DNN网络和ResNet50方法尚未完全实现,但在本文章中也有呈现,可进行选择性忽略或参考。
项目源地址:你的颜值能打多少分?让飞桨来告诉你
实验数据
数据中包含500张女生图片,分别由70人进行打分,最终取平均值即为该图片的打分情况。
我们在实践中将图片分值设定为1-5。
500张图片中,450张用于训练,50张用于验证。

解决过程
1、Precondition
在进行处理之前,先要对指定的包进行解压,来知道当前数据集名称。
按照以下代码,对压缩包进行处理:
# 查看当前挂载的数据集目录, 该目录下的变更重启环境后会自动还原
# View dataset directory. This directory will be recovered automatically after resetting environment.
!ls /home/aistudio/data
我们可以知道,此项目的数据包名称为data17941。
解压完毕后,便可以进行对指定库的导入。本项目中主要用到的库有以下几类:
(1)paddle自带的库。飞桨paddlepaddle集成了python支持的机器学习模型的库,并予以提供了详细(2)python所支持的可视化图表库。因为本次实验需要绘制曲线、混淆矩阵等图表以支持模型拟合,(3)python所支持的基本库和第三方处理库。
本次实验还需要用到像超参数学习率、分类数、训练轮数等一系列的参数,所以我们可以在开始的时候就定义一个train_parameters对这些参数进行封装。在本项目中,我们将图片大小input_size、分类数class_dim、原始数据集路径src_path、要解压的路径target_path、训练轮数num_epochs、训练时每个批次的大小train_batch_size、超参数学习率定义lr在了train_parameters中,以便后续进行使用。
在对数据包进行解压、相关库的导入以及参数的定义之后,我们便可以开始对数据集进行预处理。
2、Dataset Preparation
在这一部分,我们会定义一个数据集类MyDataset,并对训练集和验证集进行划分。
在定义数据集类的时候,我们需要对image和label进行标识,喂入数据。在解压的数据集中我们可以发现,图片是以“图片得分-编号”的方式来进行命名的,所以我们读取图片,并对名称进行分割,取第一个数字,按照训练集和验证集分开的方式,存入label里。
定义完数据集后,可以构造训练、测试数据提供器。
3、Network Configuration
在这一部分,选择了三个神经网络模型,分别是:VGG网络模型、DNN网络模型和ResNet50网络模型,但是我想要着重讲一下VGG网络模型(包括后面的一系列过程,具体缘由我会在最后进行阐述)。
VGG模型在AlexNet的基础上使用3*3小卷积核,增加网络深度,具有很好的泛化能力。在2014年ImageNet比赛中,获得了定位第1,分类第2的好成绩。VGG的核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。由于每组内卷积层的不同,有11、13、16、19层这几种模型,下图展示一个16层的网络结构。
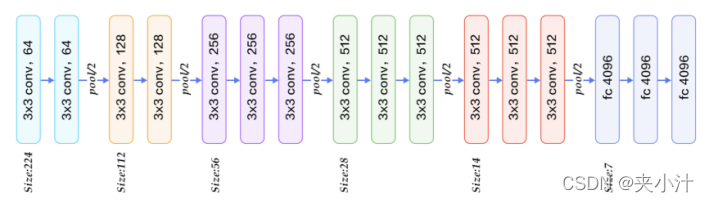
在定义VGG模型时,我们先用fluid.nets.img_conv_group()函数定义一个卷积模块conv_block(),从而通过配置卷积模块组件VGG-16网络结构。卷积模块conv_block()主要用来设定该模块中的输入、池化、卷积、激活函数、以及dropout和bacthnorm。获得了卷积模块后,通过多个卷积模块的组合以及三个全连接层就可以轻松获得一个VGG-16模型。
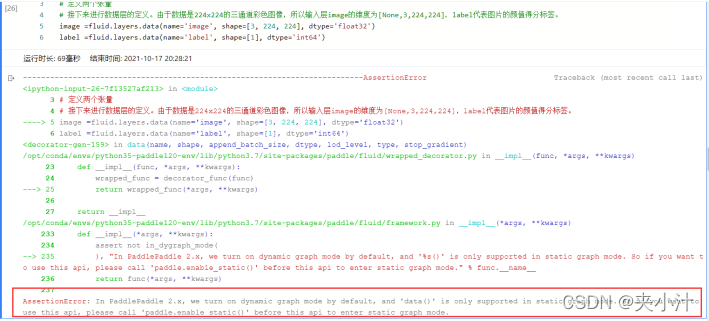
之后对数据层进行定义。由于数据是224x224的三通道彩色图像,所以输入层image的维度为[None,3,224,224],label代表图片的颜值得分标签。此处可能会出现一个错误:
AssertionError:In PaddlePaddle 2.x, we turn on dynamic graph mode by default, and ‘data()’ is only supported in static graph mode. So if you want to use this api, please call ‘paddle.enable_static()’ before this api to enter static graph mode.
PaddlePaddle 2.X时,我们默认打开动态图形模式,而’data()‘仅支持静态图形模式。 # 所以如果你想使用这个api,请在这个api进入静态图形模式之前调用’paddle.enable_static()’。
定义好VGG网络结构以后,我们可以使用其来获取分类器predict,然后定义损失函数和准确率函数。定义损失函数时,我们使用的是交叉熵损失函数,原因是该函数在分类任务上比较常用。因为定义的是一个Batch的损失值,所以在定义了一个损失函数之后,还要对它求平均值。这里定义一个准确率函数,可以在训练的时候输出分类的准确率,也方便后面可视化分析使用。
4、Models Training
定义好VGG网络结构以后,我们便可以开始进行模型的训练。
飞桨paddlepaddle是一个很强大的平台,在部署环境时可以自行选择使用CPU还是GPU进行操作。但是在选择之后,需要在代码里进行说明。
# 在上一步骤中定义好了网络模型,即构造好了两个核心Program,接下来将介绍如何飞桨如何使用Excutor来执行Program:
# 定义使用CPU还是GPU,使用CPU时use_cuda = False,使用GPU时use_cuda = True
# 此时我使用的是飞桨至尊GPU
use_cuda = True
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
我们可以根据fluid库来创建一个实例exe,并在进行网络训练前,对执行参数初始化。定义好以后,执行训练之前,我们需要告知网络传入的数据分为两部分,即我们最开始提到的image、label。
之后就可以进行正式的训练了,本实践中设置训练轮数60。
在Executor的run方法中,feed代表以字典的形式定义了数据传入网络的顺序,feeder在上述代码中已经进行了定义,将data[0]、data[1]分别传给image、label。fetch_list定义了网络的输出。
在每轮训练中,每10个batch,打印一次训练平均误差和准确率。每轮训练完成后,使用验证集进行一次验证。 每轮训练完成后,对模型进行一次保存,使用飞桨提供的函数:fluid.io.save_inference_model()进行模型保存,如果保存路径不存在就自动创建。


5、Models Evaluation
在对模型进行评估时,我最终选择的是绘制准确率、损失率曲线。但其实最开始的时候是使用的训练数据和测试数据的图表输出,比如:
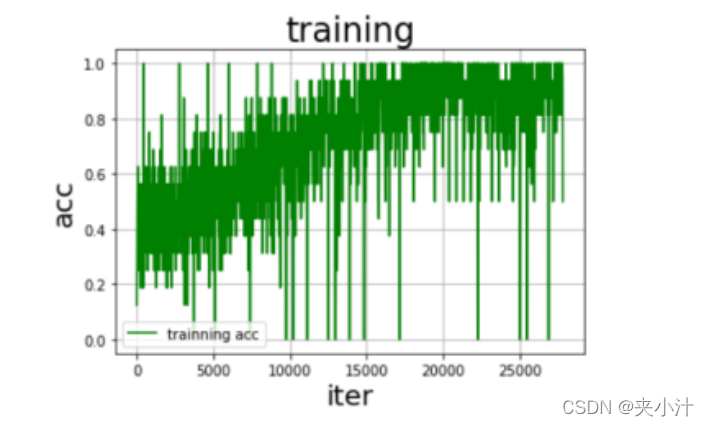
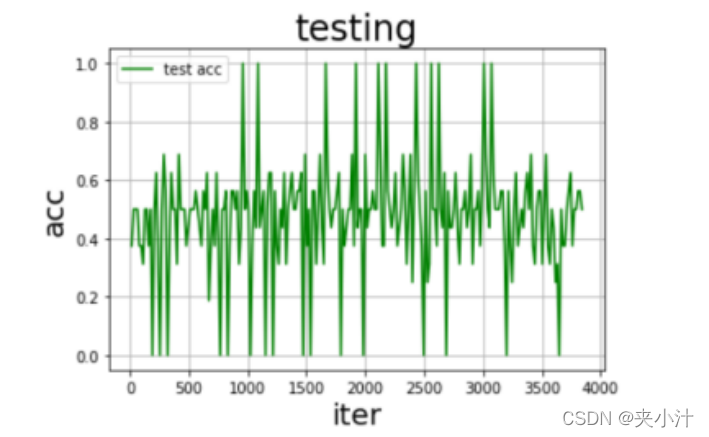
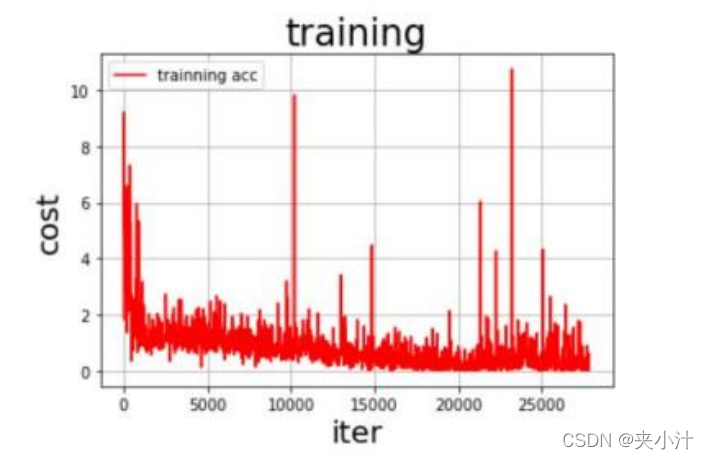
但是后来认为此曲线不能满足我的特定要求,于是代码改正过程为:
# 在这里我们定义了draw_cost_process()和draw_acc_process()函数,用来可视化展示训练过程中的损失和准确率的变化趋势。
# def draw_cost_process(title,iters,costs,label_cost):
# plt.title(title, fontsize=24)
# plt.xlabel("iter", fontsize=20)
# plt.ylabel("cost", fontsize=20)
# plt.plot(iters,costs,color='red',label=label_cost)
# plt.legend()
# plt.grid()
# plt.show()
# def draw_acc_process(title,iters,acc,label_acc):
# plt.title(title, fontsize=24)
# plt.xlabel("iter", fontsize=20)
# plt.ylabel("acc", fontsize=20)
# plt.plot(iters,acc,color='green',label=label_acc)
# plt.legend()
# plt.grid()
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
def draw_process(title,color,iters,data,label):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel(label, fontsize=20)
plt.plot(iters, data,color=color,label=label)
plt.legend()
plt.grid()
plt.show()
# 调用绘制曲线
# 调用draw_acc_process()和draw_cost_process()绘制曲线,方便观察迭代过程中的变化趋势,从而对网络训练结果进行评估。
# 由于此方法调用的不稳定性 所以我选择另择方案
# draw_acc_process("training",all_train_iters, all_train_accs, "trainning acc")
# draw_acc_process("testing",all_test_iters, all_test_accs, "test acc")
# draw_cost_process("training",all_train_iters, all_train_costs, "trainning acc")
# draw_cost_process("testing",all_test_iters, all_test_costs, "test acc")
#调用draw_train_process()和draw_process()绘制曲线,方便观察迭代过程中的变化趋势,从而对网络训练结果进行评估。
draw_train_process("training",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc")
draw_process("trainning loss","red",all_train_iters,all_train_costs,"trainning loss")
draw_process("trainning acc","green",all_train_iters,all_train_accs,"trainning acc")
#执行完:import matplotlib.pyplot as plt后,运行窗口会报错:
# DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated, and in 3.8 it will stop working
# 由于本实验中Python环境为3.7 而且也并未用到此函数,所以选择忽略
最终生成的图像为:
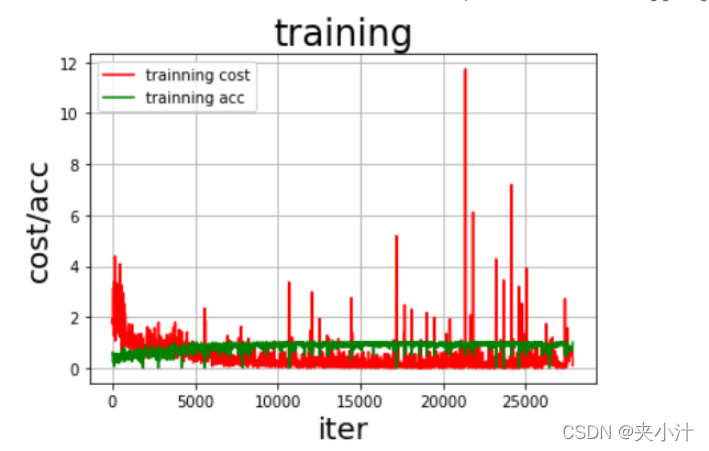
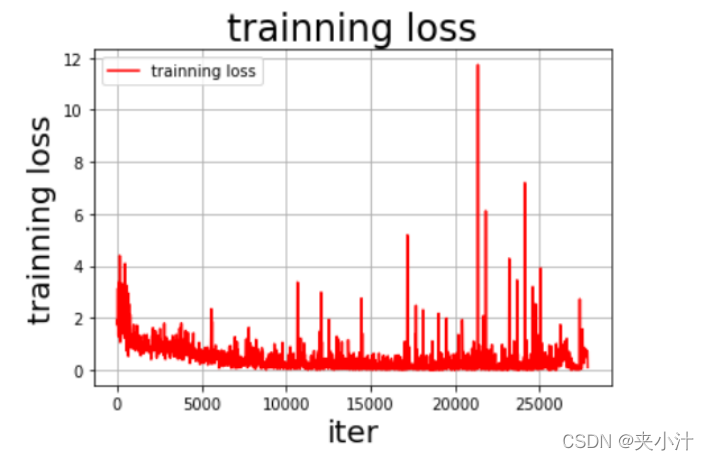
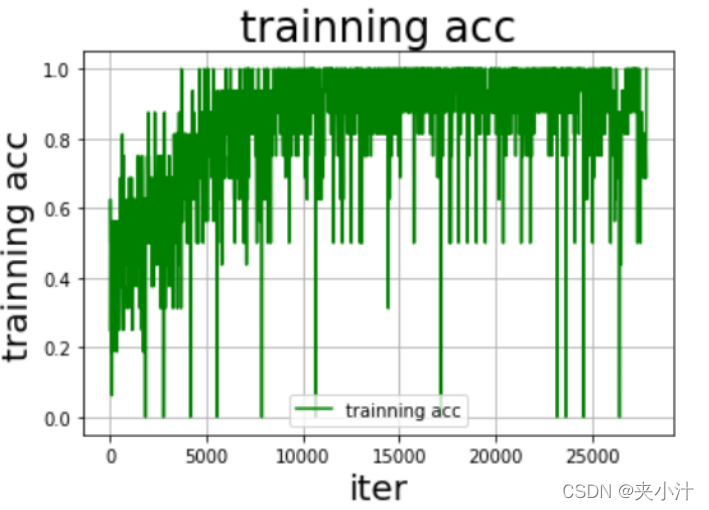
6、Models Prediction
前面已经进行了模型训练,并保存了训练好的模型。接下来就可以使用训练好的模型对手写数字图片进行识别了。预测之前必须要对预测的图像进行预处理,首先对输入的图片进行灰度化,然后压缩图像大小为224x224(其实应该是100*100,但是我发现处理与否不影响结果),接着将图像转换成一维向量,最后对一维向量进行归一化处理。
在加载模型进行预测时,我们首先从指定目录中加载训练好的模型,然后喂入要预测的图片向量,返回模型的输出结果,即为预测概率,这些概率的总和为1。得到各个标签的概率值后,获取概率最大的标签,即为颜值的预测结果。

7、Conclusion
在本次实验中,我所撰写的报告是基于VGG模型的神经网络方法对人脸颜值进行打分,但是在我所给出的源代码一栏内,还包含另外两种模型,以及其他处理曲线的方法。实际上,VGG、DNN、ResNet网络的方法大同小异,所以我只是在使用之后进行了简单对比,但是在总结的时候只选取了一种进行使用。除此之外,在我代码的注释栏内还有绘制混淆矩阵和ROC曲线的方法,在混淆矩阵的过程中,由于我使用VGG网络时读入数据和使用数据方法不当,所呈现出来的矩阵为空,但是使用其他网络则可以,遂没有采取,而ROC曲线是我在阅读他人技术文档的时候所发现的一种可视化方法,由于本实验不太需要ROC曲线,遂也没有采取。
在可视化图表中,我们很容易看出,随着数据量的逐步增加,准确率趋近于1,但是在数据量为某个值的时候,损失率达到了最高值,我猜测是模型的偶然情况。总的来说模型拟合的情况较好,没有出现过拟合的情况。
其实在进行数据预测的时候,我发现预测的准确率不是很理想,一方面是数据集较少,未能达到验证的效果,另一方面是选择的模型问题,没有进行进一步的优化。和其他同学对比之后,发现SVN、随机森林等方法在预测图片分数时效果略优于我目前所建立出来的模型,但是限于时间,我没有继续尝试。
本次实习我是基于百度某一版开源代码上进行的修改,在我改完之后,和另外的开源代码所对比,发现我的代码封装程度不够。
源代码
1、Prediction
from paddle import ParamAttr
from paddle.regularizer import L2Decay
from paddle.nn import CrossEntropyLoss
from paddle.metric import Accuracy
from paddle.fluid.dygraph import Linear
from sklearn.preprocessing import label_binarize
from sklearn.metrics import accuracy_score,recall_score,precision_score,f1_score
from paddle.vision.transforms import Compose,Transpose, BrightnessTransform,Resize,Normalize,RandomHorizontalFlip,RandomRotation,ContrastTransform,RandomCrop
import matplotlib.pyplot as plt
import numpy as np # python基本库,用于科学计算
from PIL import Image # python第三方图像处理库
from PIL import ImageEnhance
import itertools
import zipfile
import random
import json # python标准库中的json模块,提供json数据处理功能
import sys
import cv2
import seaborn as sns
from multiprocessing import cpu_count
from sklearn.metrics import confusion_matrix #生成混淆矩阵函数
# 配置参数
train_parameters = {
"input_size": [3, 224 ,224], #输入图片的shape
"class_dim": 5, #分类数
"src_path":"./data/data17941/face_data_5.zip", #原始数据集路径
"target_path":"./face_data_5", #要解压的路径
"num_epochs": 60, #训练轮数
"train_batch_size": 16, #训练时每个批次的大小
# "readme_path": "/home/aistudio/data/readme.json", #readme.json路径
"learning_strategy": {
#优化函数相关的配置
"lr": 0.001 #超参数学习率
}
}
# 解压数据集
src_path=train_parameters["src_path"] #原始路径
target_path=train_parameters["target_path"] #解压路径
if(not os.path.isdir(target_path)):
z = zipfile.ZipFile(src_path, 'r') # 只读方式进行解压
z.extractall(path=target_path)
z.close()
2、Dataset Preparation
# 解压数据集
src_path=train_parameters["src_path"] #原始路径
target_path=train_parameters["target_path"] #解压路径
if(not os.path.isdir(target_path)):
z = zipfile.ZipFile(src_path, 'r') # 只读方式进行解压
z.extractall(path=target_path)
z.close()
def MyDataset(data):
img, label=data
# 数据集图片中的像素各不相同,所以需要读取图片,并进一步对图像进行变换
img = paddle.dataset.image.load_image(img)
# 将img数组进行归一化处理,得到0到1之间的数值
img=img.flatten().astype('float32')/255.0
return img,int(label)
def data_reader(data_path,buffered_size=512):
print(data_path)
def reader():
for image in os.listdir(data_path):
label=int(image.split('-')[0])-1
img=os.path.join(data_path+'/'+image)
yield img,label
# 创建自定义数据训练集的train_reader
# name 'cpu_count' is not defined-->4
return paddle.reader.xmap_readers(MyDataset, reader, cpu_count(), buffered_size)
#构造训练、测试数据提供器
train_path='./face_data_5/face_image_train'
test_path='./face_data_5/face_image_test'
BATCH_SIZE = train_parameters["train_batch_size"]
train_r = data_reader(data_path=train_path)
train_reader = paddle.batch(paddle.reader.shuffle(reader=train_r,buf_size=128),batch_size=BATCH_SIZE)
test_r= data_reader(data_path=test_path)
test_reader = paddle.batch(test_r, batch_size=BATCH_SIZE)
#print(next(test_reader()))
3、Network Configuration
3.1 VGG Network Model
# 首先用fluid.nets.img_conv_group()函数定义一个卷积模块conv_block(),从而通过配置卷积模块组件VGG-16网络结构。
# 卷积模块conv_block()主要用来设定该模块中的输入、池化、卷积、激活函数、以及dropout和bacthnorm。
# 获得了卷积模块后,通过多个卷积模块的组合以及三个全连接层就可以轻松获得一个VGG-16模型。
def vgg_bn_drop(image, type_size):
def conv_block(ipt, num_filter, groups,dropouts):
return fluid.nets.img_conv_group(
input=ipt, # 具有[N,C,H,W]格式的输入图像
pool_size=2,
pool_stride=2,
conv_num_filter=[num_filter] *groups, # 过滤器个数
conv_filter_size=3, # 过滤器大小
conv_act='relu',
conv_with_batchnorm=True, # 表示在 Conv2d Layer 之后是否使用 BatchNorm
conv_batchnorm_drop_rate=dropouts,#表示 BatchNorm 之后的 Dropout Layer 的丢弃概率
pool_type='max') # 最大池化
conv1 = conv_block(image, 64, 2, [0.0, 0])
conv2 = conv_block(conv1, 128, 2, [0.0, 0])
conv3 = conv_block(conv2, 256, 3, [0.0,0.0, 0])
conv4 = conv_block(conv3, 512, 3, [0.0,0.0, 0])
conv5 = conv_block(conv4, 512, 3, [0.0,0.0, 0])
drop = fluid.layers.dropout(x=conv2,dropout_prob=0.5)
fc1 = fluid.layers.fc(input=drop, size=512,act=None)
bn = fluid.layers.batch_norm(input=fc1, act='relu')
drop2 = fluid.layers.dropout(x=bn,dropout_prob=0.5)
fc2 = fluid.layers.fc(input=drop2, size=1024,act=None)
predict = fluid.layers.fc(input=fc2,size=type_size, act='softmax')
return predict
# 数据层定义
# 定义输入输出层
# 定义两个张量
# 接下来进行数据层的定义。由于数据是224x224的三通道彩色图像,所以输入层image的维度为[None,3,224,224],label代表图片的颜值得分标签。
#AssertionError:In PaddlePaddle 2.x, we turn on dynamic graph mode by default, and 'data()' is only supported in static graph mode. So if you want to use this api,
# please call 'paddle.enable_static()' before this api to enter static graph mode.
# PaddlePaddle 2.X时,我们默认打开动态图形模式,而'data()'仅支持静态图形模式。
# 所以如果你想使用这个api,请在这个api进入静态图形模式之前调用'paddle.enable_static()'。
paddle.enable_static()
image =fluid.layers.data(name='image', shape=[3, 224, 224], dtype='float32')
label =fluid.layers.data(name='label', shape=[1], dtype='int64')
# 获取分类器
# 上面定义好了VGG网络结构,这里我们使用定义好的网络来获取分类器。
predict=vgg_bn_drop(image,5)
# 定义损失函数和准确率函数
# 接着是定义损失函数,这里使用的是交叉熵损失函数,该函数在分类任务上比较常用。
# 定义了一个损失函数之后,还要对它求平均值,因为定义的是一个Batch的损失值。同时还可以定义一个准确率函数,可以在训练的时候输出分类的准确率。
cost =fluid.layers.cross_entropy(input=predict, label=label)
avg_cost =fluid.layers.mean(cost)
accuracy =fluid.layers.accuracy(input=predict, label=label)
#克隆main_program得到test_program,使用参数for_test来区分该程序是用来训练还是用来测试,该api在optimization之前使用.
test_program = fluid.default_main_program().clone(for_test=True)
# 为了区别测试和训练,在这里我们克隆一个test_program()。
# 克隆main_program得到test_program,使用参数for_test来区分该程序是用来训练还是用来测试#注意:该fluid.default_main_program().clone()请在optimization之前使用.test_program =fluid.default_main_program().clone(for_test=True)接着定义优化算法,这里使用的是Adam优化算法,指定学习率为0.002。
# 定义优化方法
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.002)
opts = optimizer.minimize(avg_cost)
3.2 DNN Network Model
# # 定义DNN网络
# class MyDNN(fluid.dygraph.Layer):
# '''
# DNN网络
# '''
# def __init__(self):
# super(MyDNN,self).__init__()
# self.hidden1= Linear(20*20,400,act='relu')
# self.hidden2 = Linear(400,200,act='relu')
# self.hidden3 = Linear(200,100,act='relu')
# self.out = Linear(100,65,act='softmax')
# def forward(self,input): # forward 定义执行实际运行时网络的执行逻辑
# '''前向计算'''
# x = fluid.layers.reshape(input, shape=[-1,20*20]) #-1 表示这个维度的值是从x的元素总数和剩余维度推断出来的,有且只能有一个维度设置为-1
# x = self.hidden1(x)
# x = self.hidden2(x)
# # print('2',x.shape)
# x = self.hidden3(x)
# # print('3',x.shape)
# y = self.out(x)
# # print('4',y.shape)
# return y
3.3 ResNet50 Network Model
# 定义ResNet50网络
# -*- coding:utf-8 -*-
# ResNet模型代码
# ResNet中使用了BatchNorm层,在卷积层的后面加上BatchNorm以提升数值稳定性
# 定义卷积批归一化块
class ConvBNLayer(paddle.nn.Layer):
def __init__(self,
num_channels,
num_filters,
filter_size,
stride=1,
groups=1,
act=None):
"""
num_channels, 卷积层的输入通道数
num_filters, 卷积层的输出通道数
stride, 卷积层的步幅
groups, 分组卷积的组数,默认groups=1不使用分组卷积
"""
super(ConvBNLayer, self).__init__()
# 创建卷积层
self._conv = nn.Conv2D(
in_channels=num_channels,
out_channels=num_filters,
kernel_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
bias_attr=False)
# 创建BatchNorm层
self._batch_norm = paddle.nn.BatchNorm2D(num_filters)
self.act = act
def forward(self, inputs):
y = self._conv(inputs)
y = self._batch_norm(y)
if self.act == 'leaky':
y = F.leaky_relu(x=y, negative_slope=0.1)
elif self.act == 'relu':
y = F.relu(x=y)
return y
# 定义残差块
# 每个残差块会对输入图片做三次卷积,然后跟输入图片进行短接
# 如果残差块中第三次卷积输出特征图的形状与输入不一致,则对输入图片做1x1卷积,将其输出形状调整成一致
class BottleneckBlock(paddle.nn.Layer):
def __init__(self,
num_channels,
num_filters,
stride,
shortcut=True):
super(BottleneckBlock, self).__init__()
# 创建第一个卷积层 1x1
self.conv0 = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters,
filter_size=1,
act='relu')
# 创建第二个卷积层 3x3
self.conv1 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters,
filter_size=3,
stride=stride,
act='relu')
# 创建第三个卷积 1x1,但输出通道数乘以4
self.conv2 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters * 4,
filter_size=1,
act=None)
# 如果conv2的输出跟此残差块的输入数据形状一致,则shortcut=True
# 否则shortcut = False,添加1个1x1的卷积作用在输入数据上,使其形状变成跟conv2一致
if not shortcut:
self.short = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters * 4,
filter_size=1,
stride=stride)
self.shortcut = shortcut
self._num_channels_out = num_filters * 4
def forward(self, inputs):
y = self.conv0(inputs)
conv1 = self.conv1(y)
conv2 = self.conv2(conv1)
# 如果shortcut=True,直接将inputs跟conv2的输出相加
# 否则需要对inputs进行一次卷积,将形状调整成跟conv2输出一致
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = paddle.add(x=short, y=conv2)
y = F.relu(y)
return y
# 定义ResNet模型
class ResNet(paddle.nn.Layer):
def __init__(self, layers=50, class_dim=5):
"""
layers, 网络层数,可以是50, 101或者152
class_dim,分类标签的类别数
"""
super(ResNet, self).__init__()
self.layers = layers
supported_layers = [50, 101, 152]
assert layers in supported_layers, \
"supported layers are {} but input layer is {}".format(supported_layers, layers)
if layers == 50:
#ResNet50包含多个模块,其中第2到第5个模块分别包含3、4、6、3个残差块
depth = [3, 4, 6, 3]
elif layers == 101:
#ResNet101包含多个模块,其中第2到第5个模块分别包含3、4、23、3个残差块
depth = [3, 4, 23, 3]
elif layers == 152:
#ResNet152包含多个模块,其中第2到第5个模块分别包含3、8、36、3个残差块
depth = [3, 8, 36, 3]
# 残差块中使用到的卷积的输出通道数
num_filters = [64, 128, 256, 512]
# ResNet的第一个模块,包含1个7x7卷积,后面跟着1个最大池化层
self.conv = ConvBNLayer(
num_channels=3,
num_filters=64,
filter_size=7,
stride=2,
act='relu')
self.pool2d_max = nn.MaxPool2D(
kernel_size=3,
stride=2,
padding=1)
# ResNet的第二到第五个模块c2、c3、c4、c5
self.bottleneck_block_list = []
num_channels = 64
for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
bottleneck_block = self.add_sublayer(
'bb_%d_%d' % (block, i),
BottleneckBlock(
num_channels=num_channels,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1, # c3、c4、c5将会在第一个残差块使用stride=2;其余所有残差块stride=1
shortcut=shortcut))
num_channels = bottleneck_block._num_channels_out
self.bottleneck_block_list.append(bottleneck_block)
shortcut = True
"""
以全局池化层为界,self.conv_layer用来存放所有卷积层。self.last_layer 用来全局池化层后面的全连接层
"""
self.conv_layer = nn.Sequential(self.conv, self.pool2d_max,*self.bottleneck_block_list)
last_layer = [
paddle.nn.AdaptiveAvgPool2D(output_size=1),
nn.Flatten(1, -1),
nn.Linear(in_features=2048, out_features=class_dim),
]
self.last_layer = nn.Sequential(*last_layer)
"""
这是原来的代码,用以上的代码代替。其实就是单纯组合了一下,没有增加新的层
"""
# 在c5的输出特征图上使用全局池化
# self.pool2d_avg = paddle.nn.AdaptiveAvgPool2D(output_size=1)
# 创建全连接层,输出大小为类别数目,经过残差网络的卷积和全局池化后,
# 卷积特征的维度是[B,2048,1,1],故最后一层全连接的输入维度是2048
# self.out = nn.Linear(in_features=2048, out_features=class_dim)
def forward(self, inputs):
# y = self.conv(inputs)
# y = self.pool2d_max(y)
# for bottleneck_block in self.bottleneck_block_list:
# y = bottleneck_block(y)
# y = self.pool2d_avg(y)
# y = paddle.reshape(y, [y.shape[0], -1])
# y = self.out(y)
"""
上面是原来的代码,用下面的两行代替(就是上面的代码组装起来而已。。。)
"""
conv = self.conv_layer(inputs)
y = self.last_layer(conv)
return y
4、Models Training
4.1 VGG
# VGG网络
# 在上一步骤中定义好了网络模型,即构造好了两个核心Program,接下来将介绍如何飞桨如何使用Excutor来执行Program:
# 定义使用CPU还是GPU,使用CPU时use_cuda = False,使用GPU时use_cuda = True
# 此时我使用的是飞桨至尊GPU
use_cuda = True
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
#创建一个Executor实例exe
exe =fluid.Executor(place)
#正式进行网络训练前,需先执行参数初始化
exe.run(fluid.default_startup_program())
# 定义好网络训练需要的Executor,在执行训练之前,需要告知网络传入的数据分为两部分,第一部分是images值,第二部分是label值:
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
# 之后就可以进行正式的训练了,本实践中设置训练轮数60。
# 在Executor的run方法中,feed代表以字典的形式定义了数据传入网络的顺序,feeder在上述代码中已经进行了定义,将data[0]、data[1]分别传给image、label。fetch_list定义了网络的输出。
# 在每轮训练中,每10个batch,打印一次训练平均误差和准确率。每轮训练完成后,使用验证集进行一次验证。
EPOCH_NUM = 60
#训练过程数据记录
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
#测试过程数据记录
all_test_iter=0
all_test_iters=[]
all_test_costs=[]
all_test_accs=[]
model_save_dir ="/home/aistudio/work"
for pass_id in range(EPOCH_NUM):
train_cost=0
# 开始训练
for batch_id, data in enumerate(train_reader()): #遍历训练集,并为数据加上索引batch_id
train_cost,train_acc =exe.run(program=fluid.default_main_program(),#运行主程序
feed=feeder.feed(data), #喂入一个batch的数据
fetch_list=[avg_cost, accuracy]) #fetch均方误差和准确率
all_train_iter=all_train_iter+BATCH_SIZE
all_train_iters.append(all_train_iter)
all_train_costs.append(train_cost[0])
all_train_accs.append(train_acc[0])
#每10次batch打印一次训练、进行一次测试
if batch_id % 10== 0:
print('Pass:%d, Batch:%d,Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0],train_acc[0]))
# 开始测试
# 每训练一轮 进行一次测试
test_costs = [] #测试的损失值
test_accs = [] #测试的准确率
for batch_id, data in enumerate(test_reader()):
test_cost, test_acc =exe.run(program=test_program, #执行训练程序
feed=feeder.feed(data), #喂入数据
fetch_list=[avg_cost, accuracy]) #fetch 误差、准确率
test_costs.append(test_cost[0]) #记录每个batch的误差
test_accs.append(test_acc[0]) #记录每个batch的准确率
all_test_iter=all_test_iter+BATCH_SIZE
all_test_iters.append(all_test_iter)
all_test_costs.append(test_cost[0])
all_test_accs.append(test_acc[0])
# 求测试结果的平均值
test_cost = (sum(test_costs) /len(test_costs)) #计算误差平均值(误差和/误差的个数)
test_acc = (sum(test_accs) /len(test_accs)) #计算准确率平均值( 准确率的和/准确率的个数)
print('Test:%d, Cost:%0.5f, ACC:%0.5f' %(pass_id, test_cost, test_acc))
# 每轮训练完成后,对模型进行一次保存,使用飞桨提供的fluid.io.save_inference_model()进行模型保存:
# 保存模型
# 如果保存路径不存在就创建
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
print('savemodels to %s' % (model_save_dir))
fluid.io.save_inference_model(model_save_dir, # 保存预测Program的路径
['image'], #预测需要feed的数据
[predict], #保存预测结果
exe) #executor 保存预测模型
print('训练模型保存完成!')
4.2 DNN
# DNN网络
# with fluid.dygraph.guard():
# model=MyDNN() #模型实例化
# model.train() #训练模式
# opt=fluid.optimizer.SGDOptimizer(learning_rate=train_parameters['learning_strategy']['lr'], parameter_list=model.parameters())#优化器选用SGD随机梯度下降,学习率为0.001.
# epochs_num=train_parameters['num_epochs'] #迭代次数
# for pass_num in range(epochs_num):
# for batch_id,data in enumerate(train_reader()):
# images=np.array([x[0].reshape(3,224,224) for x in data],np.float32)
# labels = np.array([x[1] for x in data]).astype('int64')
# labels = labels[:, np.newaxis]
# image=fluid.dygraph.to_variable(images)
# label=fluid.dygraph.to_variable(labels)
# predict=model(image) #数据传入model
# loss=fluid.layers.cross_entropy(predict,label)
# avg_loss=fluid.layers.mean(loss)#获取loss值
# acc=fluid.layers.accuracy(predict,label)#计算精度
# if batch_id!=0 and batch_id%50==0:
# Batch = Batch+50
# Batchs.append(Batch)
# all_train_loss.append(avg_loss.numpy()[0])
# all_train_accs.append(acc.numpy()[0])
# print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
# avg_loss.backward()
# opt.minimize(avg_loss) #优化器对象的minimize方法对参数进行更新
# model.clear_gradients() #model.clear_gradients()来重置梯度
# fluid.save_dygraph(model.state_dict(),'MyDNN')#保存模型
# draw_train_acc(Batchs,all_train_accs)
# draw_train_loss(Batchs,all_train_loss)
4.3 ResNet50
# ResNet网络
# train_transform = Compose([RandomRotation(degrees=10),#随机旋转0到10度
# RandomHorizontalFlip(),#随机翻转
# ContrastTransform(0.1),#随机调整图片的对比度
# BrightnessTransform(0.1),#随机调整图片的亮度
# Resize(size=(240,240)),#调整图片大小为240,240
# RandomCrop(size=(224,224)),#从240大小中随机裁剪出224
# Normalize(mean=[127.5, 127.5, 127.5],std=[127.5, 127.5, 127.5],data_format='HWC'),#归一化
# Transpose()])#对‘HWC’转换成‘CHW’
# val_transform = Compose([
# Resize(size=(224,224)),
# Normalize(mean=[127.5, 127.5, 127.5],std=[127.5, 127.5, 127.5],data_format='HWC'),
# Transpose()])
# 定义DataSet
class FaceDataset(paddle.io.Dataset):
def __init__(self,mode='train'):
super(FaceDataset, self).__init__()
# self.mode = mode
# self.data_list = []
# self.transform = transform
self.data = []
self.label = []
data_path = ''
train_list_path = './face_data_5/face_image_train'
eval_list_path = './face_data_5/face_image_test'
if mode == 'train':
# self.data_list = np.loadtxt(txt_path, dtype='str')
for image in os.listdir(train_list_path):
label = int(image.split('-')[0]) - 1
img_path = os.path.join(train_list_path+ '/' + image)
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((100, 100), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) # HWC to CHW
img = img/255 # 像素值归一化
self.data.append(img)
self.label.append(int(label))
elif mode == 'valid':
# self.data_list = np.loadtxt(txt_path, dtype='str')
for image in os.listdir(eval_list_path):
label = int(image.split('-')[0]) - 1
img_path = os.path.join(eval_list_path+ '/' + image)
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((100, 100), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) # HWC to CHW
img = img/255 # 像素值归一化
self.data.append(img)
self.label.append(int(label))
# def __getitem__(self, idx):
# img_path = self.data_list[idx][0]
# img = cv2.imread(img_path)
# img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# if self.transform:
# img = self.transform(img)
# return img, int(self.data_list[idx][1])
# def __len__(self):
# return self.data_list.shape[0]
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
#返回单一数据和标签
"""
步骤四:实现__len__方法,返回数据集总数目
"""
#返回数据总数
return len(self.data)
# train_txt = 'work/data/train_list.txt'
# val_txt = 'work/data/val_list.txt'
# BATCH_SIZE = 16
# trn_dateset = FaceDateset(train_txt,train_transform, 'train')
# train_loader = DataLoader(trn_dateset, shuffle=True, batch_size=BATCH_SIZE )
# val_dateset = FaceDateset(val_txt, val_transform,'valid')
# valid_loader = DataLoader(val_dateset, shuffle=False, batch_size=BATCH_SIZE)
train_dataset = FaceDataset(mode='train')
eval_dataset = FaceDataset(mode='valid')
BATCH_SIZE = 16
EPOCHS = 60 #训练次数
decay_steps = int(len(train_dataset)/BATCH_SIZE * EPOCHS)
model = paddle.Model(ResNet(class_dim=5))
base_lr = 0.0125
lr = paddle.optimizer.lr.PolynomialDecay(base_lr, power=0.9, decay_steps=decay_steps, end_lr=0.0)
# 定义优化器
optimizer = paddle.optimizer.Momentum(learning_rate=lr,
momentum=0.9,
weight_decay=L2Decay(1e-4),
parameters=model.parameters())
# 进行训练前准备
model.prepare(optimizer, CrossEntropyLoss(), Accuracy(topk=(1, 5)))
# 启动训练
model.fit(train_dataset,
eval_dataset,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
shuffle=True,
verbose=1,
eval_freq = 5,#多少epoch 进行验证
save_freq = 5,#多少epoch 进行模型保存
log_freq = 30,#多少steps 打印训练信息
save_dir='./checkpoint/')
model_save_dir_2='./work2'
model.save('model_save_dir_2')
5、Models Evaluation
# 在这里我们定义了draw_cost_process()和draw_acc_process()函数,用来可视化展示训练过程中的损失和准确率的变化趋势。
# def draw_cost_process(title,iters,costs,label_cost):
# plt.title(title, fontsize=24)
# plt.xlabel("iter", fontsize=20)
# plt.ylabel("cost", fontsize=20)
# plt.plot(iters,costs,color='red',label=label_cost)
# plt.legend()
# plt.grid()
# plt.show()
# def draw_acc_process(title,iters,acc,label_acc):
# plt.title(title, fontsize=24)
# plt.xlabel("iter", fontsize=20)
# plt.ylabel("acc", fontsize=20)
# plt.plot(iters,acc,color='green',label=label_acc)
# plt.legend()
# plt.grid()
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
def draw_process(title,color,iters,data,label):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel(label, fontsize=20)
plt.plot(iters, data,color=color,label=label)
plt.legend()
plt.grid()
plt.show()
# 调用绘制曲线
# 调用draw_acc_process()和draw_cost_process()绘制曲线,方便观察迭代过程中的变化趋势,从而对网络训练结果进行评估。
# 由于此方法调用的不稳定性 所以我选择另择方案
# draw_acc_process("training",all_train_iters, all_train_accs, "trainning acc")
# draw_acc_process("testing",all_test_iters, all_test_accs, "test acc")
# draw_cost_process("training",all_train_iters, all_train_costs, "trainning acc")
# draw_cost_process("testing",all_test_iters, all_test_costs, "test acc")
#调用draw_train_process()和draw_process()绘制曲线,方便观察迭代过程中的变化趋势,从而对网络训练结果进行评估。
draw_train_process("training",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc")
draw_process("trainning loss","red",all_train_iters,all_train_costs,"trainning loss")
draw_process("trainning acc","green",all_train_iters,all_train_accs,"trainning acc")
6、Models Prediction
# 前面已经进行了模型训练,并保存了训练好的模型。接下来就可以使用训练好的模型对手写数字图片进行识别了。
# 预测之前必须要对预测的图像进行预处理,首先对输入的图片进行灰度化,然后压缩图像大小为224x224,接着将图像转换成一维向量,最后对一维向量进行归一化处理。
# 代码实现如下所示:
# 图片预处理
def load_image(file):
im = Image.open(file)
im =im.resize((224, 224), Image.ANTIALIAS) #resize 图像大小为224*224
# 由于本实验中图像通道数为3 所以以下转换代码自动忽略
# if np.array(im).shape[2] == 4 #判断图像通道数,若为4通道,则将其转化为3通道
# im = np.array(im)[:,:,:3]
# im = np.array(im).reshape(1, 3, 224,224).astype(np.float32) #返回新形状的数组,把它变成一个 numpy 数组以匹配数据馈送格式。
# im = im / 255.0 #归一化到[-1~1]之间
im = np.array(im).reshape(1, 3, 224,224).astype(np.float32) #返回新形状的数组,把它变成一个 numpy 数组以匹配数据馈送格式。
im = im / 255.0 #归一化到[-1~1]之间
return im
# 接下来使用训练好的模型对经过预处理的图片进行预测。
# 首先从指定目录中加载训练好的模型,然后喂入要预测的图片向量,返回模型的输出结果,即为预测概率,这些概率的总和为1。
# 加载模型并开始预测
infer_exe =fluid.Executor(place)
infer_img='./face_data_5/face_image_test/4-465.jpg'
#获取训练好的模型
#从指定目录中加载 推理model(inference model)
[inference_program,#预测用的program
feed_target_names,#是一个str列表,它包含需要在推理 Program 中提供数据的变量的名称。
fetch_targets] = fluid.io.load_inference_model(model_save_dir,infer_exe)#fetch_targets:是一个 Variable 列表,从中我们可以得到推断结果。
img =Image.open(infer_img)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
image=load_image(infer_img)
# 开始预测
results =infer_exe.run(
inference_program, #运行预测程序
feed={
feed_target_names[0]: image},#喂入要预测的数据
fetch_list=fetch_targets) #得到推测结果
# 得到各个标签的概率值后,获取概率最大的标签,即为颜值的预测结果
# 获取概率最大的label
print('results',results)
label_list =["1", "2", "3", "4", "5"]
改进设想
本次实习的缺陷我在上述已经提及,我需要改进的几个方面大致如下:
1.优化模型,并进行多次训练;
2.采用其他分类器对数据进行分类;
3.查看VGG网络的模型的使用问题,正确运用数据并查看混淆矩阵的输出情况;
小结
本次实习是我第一次接触百度飞桨paddlepaddle平台,这个平台与kaggle类似,但又不同,不同之处在于此平台结合国内的项目及数据集较多,且自行封装python中的一些函数,通过改进和优化,封装为自己的paddle库,方便用户进行使用。总的来说,此平台较为完善,可使用性高,开源代码参考性强。
这也是我自己第一次真正上手卷积神经网络有关的项目,在这个过程中,我了解到了从数据集的预处理,到训练,到测试的一系列完整过程,在这个过程中,一方面我体会到了机器学习的功能强大和用处广泛,另一方面我发现了自己的很多不足,在今后的学习中,我会多多改正。
机器学习是计算机学科领域中非常重要的一部分,在之后我也会继续了解这方面的有关内容。