将使用过程中遇到的问题,汇总下来以免1个月之后就忘了。程序人生是短暂,新人总会将前人拍倒再沙滩上,只能默默转型,将技术慢慢的移交给年轻人,不从正面竞争,才能保证自己立足之地的稳固。
1 FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Failed to create spark client.
这个问题,是我通过hive on spark,将数据从hive写入到elasticsearch时任务启动时出现的。
在hive-log4j2.properties中查看到hive的日志路径property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name}, 如果hive装在root用户,则
hive on spark 遇到的坑,这篇文章作者认为是hive与spark版本的问题,但是hive2.3.2和spark2.0.2在开发环境是验证通过的,测试环境使用同样的版本,却出现这个问题,我只好猜测是某个配置出了问题。详细异常信息如下:
Warning: Ignoring non-spark config property: hive.spark.client.rpc.threads=8
Warning: Ignoring non-spark config property: hive.spark.client.connect.timeout=1000
Warning: Ignoring non-spark config property: hive.spark.client.secret.bits=256
Warning: Ignoring non-spark config property: hive.spark.client.rpc.max.size=52428800
Running Spark using the REST application submission protocol.
at org.apache.hive.spark.client.rpc.RpcServer.cancelClient(RpcServer.java:212) ~[hive-exec-2.3.2.jar:2.3.2]
at org.apache.hive.spark.client.SparkClientImpl$3.run(SparkClientImpl.java:503) ~[hive-exec-2.3.2.jar:2.3.2]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_151]
2018-04-17T01:39:48,451 WARN [Driver] client.SparkClientImpl: Child process exited with code 137
2018-04-17T01:39:48,578 ERROR [6aceaa43-4b2a-4d69-82a7-1ad2bacd5e5f main] spark.SparkTask: Failed to execute spark task, with exception 'org.apache.hadoop.hive.ql.metadata.HiveException(Failed to create spark client.)'
org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create spark client.
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionImpl.open(SparkSessionImpl.java:64)
at org.apache.hadoop.hive.ql.exec.spark.session.SparkSessionManagerImpl.getSession(SparkSessionManagerImpl.java:115)
at org.apache.hadoop.hive.ql.exec.spark.SparkUtilities.getSparkSession(SparkUtilities.java:126)
at org.apache.hadoop.hive.ql.exec.spark.SparkTask.execute(SparkTask.java:103)
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:199)
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:100)
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:2183)
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1839)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1526)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1237)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1227)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:233)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:184)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:403)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:821)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:759)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:686)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
Caused by: java.lang.RuntimeException: java.util.concurrent.ExecutionException: java.lang.RuntimeException: Cancel client 'a0d9c70c-2852-4fd4-baf8-60164c002394'. Error: Child process exited before connecting back with error log Warning: Ignoring non-spark config property: hive.spark.client.server.connect.timeout=900002 Unsupported major.minor version 51.0
当执行命令./start-all.sh提示下面的异常
Exception in thread "main" java.lang.UnsupportedClassVersionError: org/apache/spark/launcher/Main : Unsupported major.minor version 51.0
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:643)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:277)
at java.net.URLClassLoader.access$000(URLClassLoader.java:73)
at java.net.URLClassLoader$1.run(URLClassLoader.java:212)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:205)
at java.lang.ClassLoader.loadClass(ClassLoader.java:323)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:294)
at java.lang.ClassLoader.loadClass(ClassLoader.java:268)
Could not find the main class: org.apache.spark.launcher.Main. Program will exit.大数据工具:Spark配置遇到的坑,这篇文章分析可能是因为ssh登录导致了java环境的丢失,于是我在spark-env.sh中添加了下面的。
export JAVA_HOME=/usr/java/jdk1.7.0_79这个时候出现新的问题,按照搭建Spark所遇过的坑这篇文章的解决方案
export SPARK_DIST_CLASSPATH=$(hadoop classpath),可以我已经添加了呀,这又是为啥呢?
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/fs/FSDataInputStream
at org.apache.spark.deploy.master.Master$.main(Master.scala:1008)
at org.apache.spark.deploy.master.Master.main(Master.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FSDataInputStream
at java.net.URLClassLoader$1.run(URLClassLoader.java:366)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
... 2 more
这篇文章spark2.0.1使用过程中常见问题汇总讲了spark的java版本与作业编译的java版本不一致,可惜没告诉我们怎么调整一致的。
3 java.lang.IllegalStateException: unread block data
我按照解决:Spark-HBASE Error Caused by: java.lang.IllegalStateException: unread block data,但是问题依旧
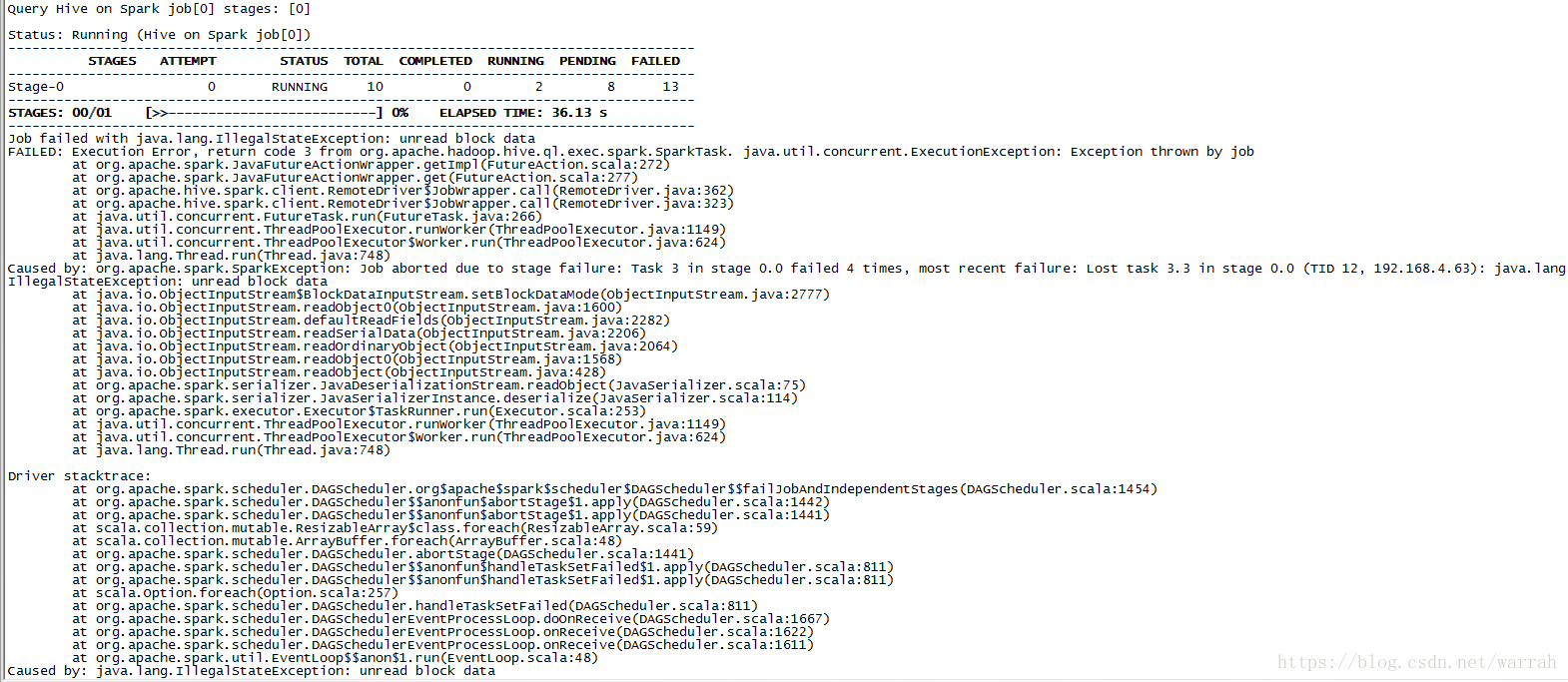
Hive-Spark error - java.lang.IllegalStateException: unread block data
, 这篇文章提供了一些思路,但是他是针对Spark 1.4.1 and Hive 1.2.1,现在的版本中spark-env.sh已经没有SPARK_CLASSPATH的配置项了。
有人说在hive的hive-site.xml中添加,经尝试后,依然无效。
<property>
<name>spark.driver.extraClassPath</name>
<value>$SPARK_HOME/lib/mysql-connector-java-5.1.34.jar:$SPARK_HOME/lib/hbase-annotations-1.1.4.jar:$SPARK_HOME/lib/hbase-client-1.1.4.jar:$SPARK_HOME/lib/hbase-common-1.1.4.jar:$SPARK_HOME/lib/hbase-hadoop2-compat-1.1.4.jar:$SPARK_HOME/lib/hbase-hadoop-compat-1.1.4.jar:$SPARK_HOME/lib/hbase-protocol-1.1.4.jar:$SPARK_HOME/lib/hbase-server-1.1.4.jar:$SPARK_HOME/lib/hive-hbase-handler-2.3.2.jar:$SPARK_HOME/lib/htrace-core-3.1.0-incubating.jar</value>
</property>
<property>
<name>spark.executor.extraClassPath</name>
<value>$SPARK_HOME/lib/mysql-connector-java-5.1.34.jar:$SPARK_HOME/lib/hbase-annotations-1.1.4.jar:$SPARK_HOME/lib/hbase-client-1.1.4.jar:$SPARK_HOME/lib/hbase-common-1.1.4.jar:$SPARK_HOME/lib/hbase-hadoop2-compat-1.1.4.jar:$SPARK_HOME/lib/hbase-hadoop-compat-1.1.4.jar:$SPARK_HOME/lib/hbase-protocol-1.1.4.jar:$SPARK_HOME/lib/hbase-server-1.1.4.jar:$SPARK_HOME/lib/hive-hbase-handler-2.3.2.jar:$SPARK_HOME/lib/htrace-core-3.1.0-incubating.jar</value>
</property>4 Worker: Failed to connect to master master:7077
继续上面的问题,跟踪spark的日志,启动spark的时候,出现下面的异常
18/04/17 19:35:17 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@3eabb48a{/metrics/json,null,AVAILABLE}
18/04/17 19:35:17 WARN worker.Worker: Failed to connect to master master:7077
org.apache.spark.SparkException: Exception thrown in awaitResult
at org.apache.spark.rpc.RpcTimeout$$anonfun$1.applyOrElse(RpcTimeout.scala:77)
at org.apache.spark.rpc.RpcTimeout$$anonfun$1.applyOrElse(RpcTimeout.scala:75)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:36)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59)
at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:59)
at scala.PartialFunction$OrElse.apply(PartialFunction.scala:167)
at org.apache.spark.rpc.RpcTimeout.awaitResult(RpcTimeout.scala:83)
at org.apache.spark.rpc.RpcEnv.setupEndpointRefByURI(RpcEnv.scala:88)
at org.apache.spark.rpc.RpcEnv.setupEndpointRef(RpcEnv.scala:96)
at org.apache.spark.deploy.worker.Worker$$anonfun$org$apache$spark$deploy$worker$Worker$$tryRegisterAllMasters$1$$anon$1.run(Worker.scala:216)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.io.IOException: Failed to connect to master/192.168.4.61:7077
at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:228)
at org.apache.spark.network.client.TransportClientFactory.createClient(TransportClientFactory.java:179)
at org.apache.spark.rpc.netty.NettyRpcEnv.createClient(NettyRpcEnv.scala:197)
at org.apache.spark.rpc.netty.Outbox$$anon$1.call(Outbox.scala:191)
at org.apache.spark.rpc.netty.Outbox$$anon$1.call(Outbox.scala:187)
... 4 more
Caused by: java.net.ConnectException: Connection refused: master/192.168.4.61:7077
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at io.netty.channel.socket.nio.NioSocketChannel.doFinishConnect(NioSocketChannel.java:224)
at io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.finishConnect(AbstractNioChannel.java:289)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:528)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:468)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:382)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:354)
at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:111)
... 1 more
18/04/17 19:35:32 INFO worker.Worker: Retrying connection to master (attempt # 1)
18/04/17 19:35:32 INFO worker.Worker: Connecting to master master:7077...
18/04/17 19:35:32 INFO client.TransportClientFactory: Successfully created connection to master/192.168.4.61:7077 after 1 ms (0 ms spent in bootstraps)
18/04/17 19:35:32 INFO worker.Worker: Successfully registered with master spark://master:7077关于Spark报错不能连接到Server的解决办法(Failed to connect to master master_hostname:7077),这篇文章或许可以解决问题,但是他部署的是standalone模式,而我是yarn模式
这个问题可以在spark-env.sh中设置,在slave节点设置master地址,就可以解决了。
export SPARK_MASTER_HOST=192.168.4.61